

通用数据增强技术,随机量化适用于任意数据模态

自监督学习算法在自然语言处理、计算机视觉等领域取得了重大进展。这些自监督学习算法尽管在概念上是通用的,但是在具体操作上是基于特定的数据模态的。这意味着需要为不同的数据模态开发不同的自监督学习算法。为此,本文提出了一种通用的数据增强技术,可以应用于任意数据模态。相较于已有的通用的自监督学习,该方法能够取得明显的性能提升,同时能够代替一系列为特定模态设计的复杂的数据增强方式并取得与之类似的性能。

- 论文地址:https://arxiv.org/abs/2212.08663
- 代码:https://github.com/microsoft/random_quantize
简介
重写后的内容:目前,Siamese表征学习/对比学习需要使用数据增强技术来构建同一数据的不同样本,并将其输入到两个并行的网络结构中,以产生足够强的监督信号。然而,这些数据增强技术通常非常依赖于模态特定的先验知识,通常需要手动设计或搜索适用于当前模态的最佳组合。除了耗时耗力之外,找到的最佳数据增强方法也很难迁移到其他领域。例如,常见的针对自然RGB图像的颜色抖动(color jittering)无法应用于除自然图像以外的其他数据模态
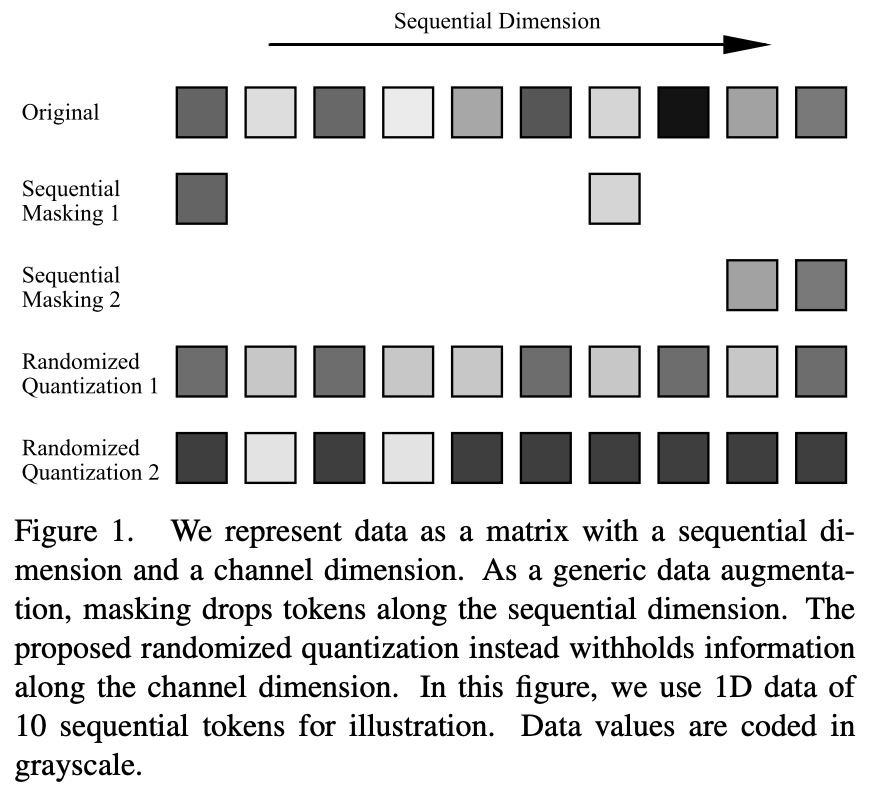
一般而言,输入数据可以被表示为由序列维度和通道维度组成的二维向量。序列维度通常与数据的模态相关,例如图像的空间维度、语音的时间维度和语言的句法维度。而通道维度则与模态无关。在自监督学习中,遮蔽建模或使用遮蔽作为数据增强已经成为一种有效的学习方法。然而,这些操作都是在序列维度上进行的。为了能够广泛适用于不同的数据模态,本文提出了一种作用于通道维度的数据增强方法:随机量化。通过使用非均匀量化器对每个通道中的数据进行动态量化,量化值是从随机划分的区间中随机采样的。通过这种方式,原始输入在同一个区间内的信息差被删除,同时保留了不同区间数据的相对大小,从而达到了遮蔽的效果
该方法在各种不同数据模态上超过了已有任意模态自监督学习方法,包括自然图像、3D 点云、语音、文本、传感器数据、医疗图像等。在多种预训练学习任务中,例如对比学习(例如 MoCo-v3)和自蒸馏自监督学习(例如 BYOL)都学到了比已有方法更优的特征。该方法还经过验证,适用于不同的骨干网络结构,例如 CNN 和 Transformer。
方法
量化(Quantization)指的是利用一组离散的数值表征连续数据,以便于数据的高效存储、运算以及传输。然而,一般的量化操作的目标是在不损失精确度的前提下压缩数据,因而该过程是确定性的,而且是设计为与原数据尽量接近的。这就限制了其作为增强手段的强度和输出的数据丰富程度。
本文提出一种随机量化操作(randomized quantization),将输入的每个 channel 数据独立划分为多个互不重叠的随机区间(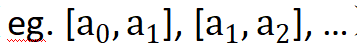 ),并将落在各个区间内的原始输入映射到从该区间内随机采样的一个常数
),并将落在各个区间内的原始输入映射到从该区间内随机采样的一个常数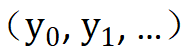 。
。

随机量化作为自监督学习任务中 masking 通道维度数据的能力取决于以下三个方面的设计:1) 随机划分数值区间;2) 随机采样输出值以及 3)划分的数值区间个数。
具体而言,随机的过程带来了更加丰富的样本,同一个数据每次执行随机量化操作都可以生成不同的数据样本。同时,随机的过程也带来对原始数据更大的增强力度,例如随机划分出大的数据区间,或者当映射点偏离区间中值点时,都可以导致落在该区间的原始输入和输出之间的更大差异。
通过适当减少划分区间的个数,可以很容易地提高增强力度。这样,当应用于Siamese表征学习时,两个网络分支就能够接收到具有足够信息差异的输入数据,从而构建强有力的学习信号,有助于特征学习
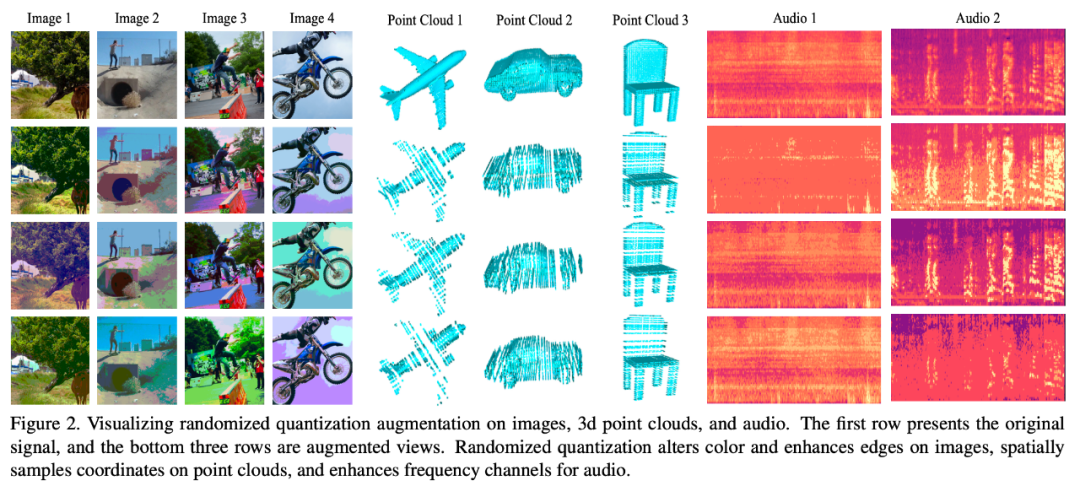
下图可视化了不同数据模态在使用了该数据增强方式之后的效果:
实验结果
重写内容为:模式1:图像
本文在 ImageNet-1K 数据集上评估了 randomized quantization 应用于 MoCo-v3 和 BYOL 的效果,评测指标为 linear evaluation。当作为唯一的数据增强方式单独使用的时候,即将本文的 augmentation 应用于原始图像的 center crop,以及和常见的 random resized crop(RRC)配合使用的时候,该方法都取得了比已有通用自监督学习方法更好的效果。
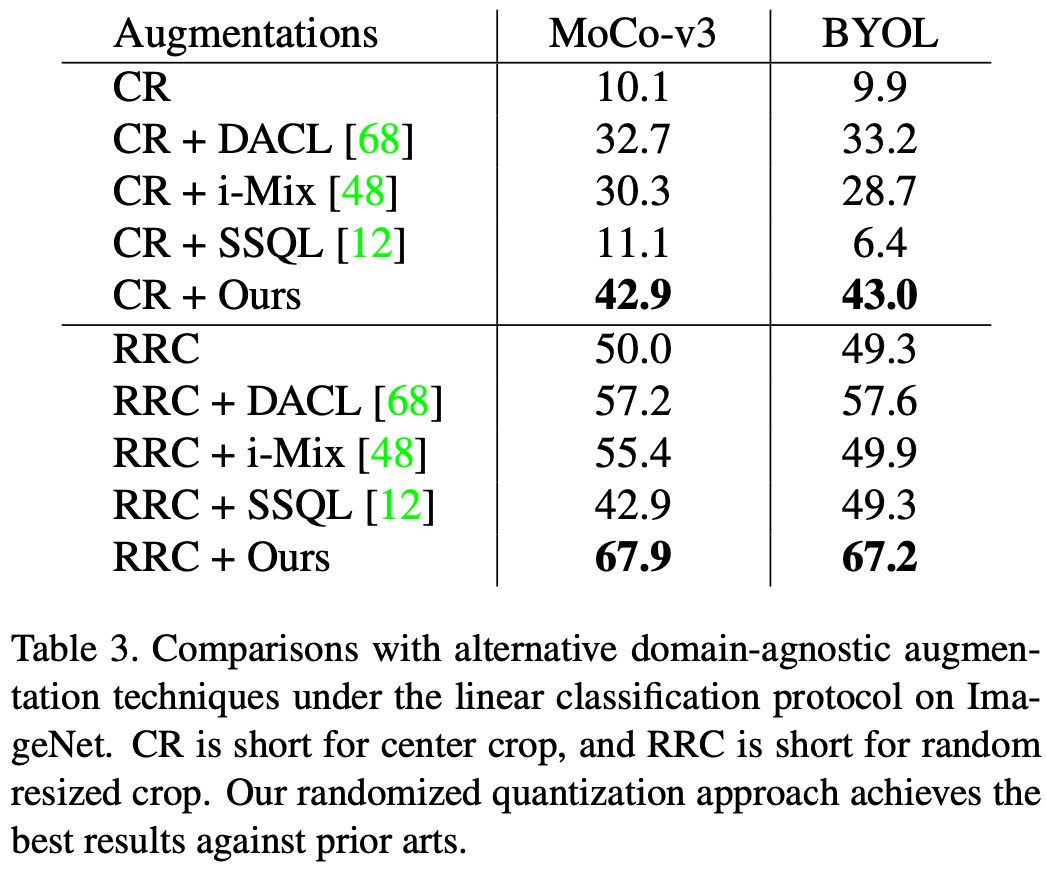
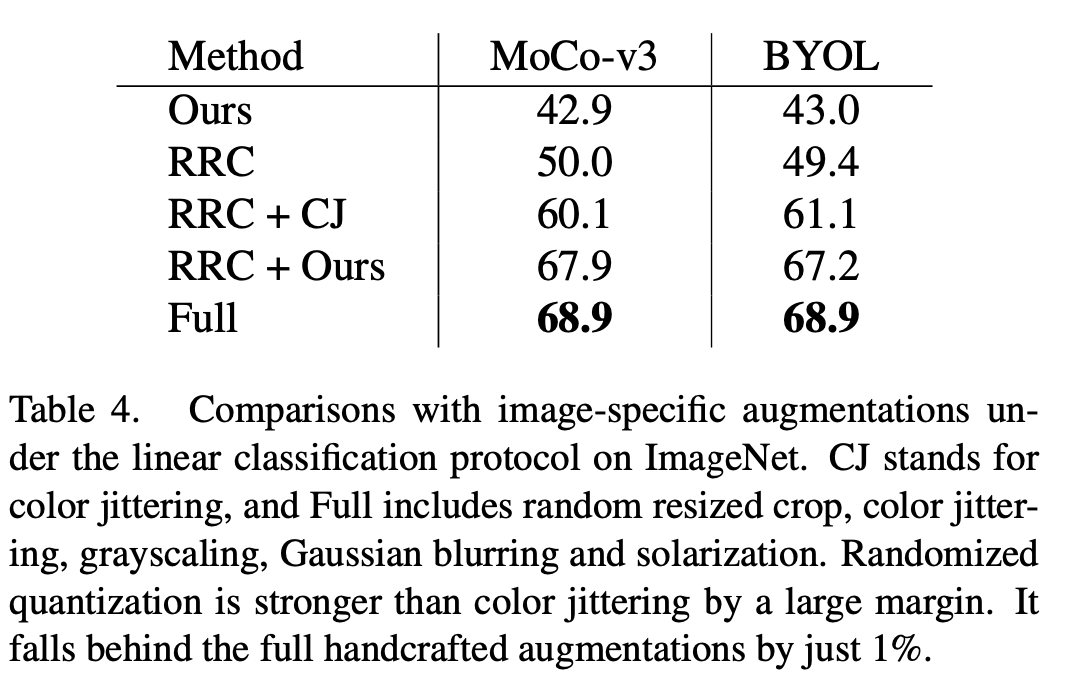
相比于已有的针对图像数据开发的数据增强方式,例如 color jittering (CJ),本文的方法有着明显的性能优势。同时,该方法也可以取代 MoCo-v3/BYOL 中一系列复杂的数据增强方式(Full),包括颜色抖动(color jittering)、随机灰度化(gray scale)、随机高斯模糊(Gaussian blur)、随机曝光(solarization),并达到与复杂数据增强方式类似的效果。
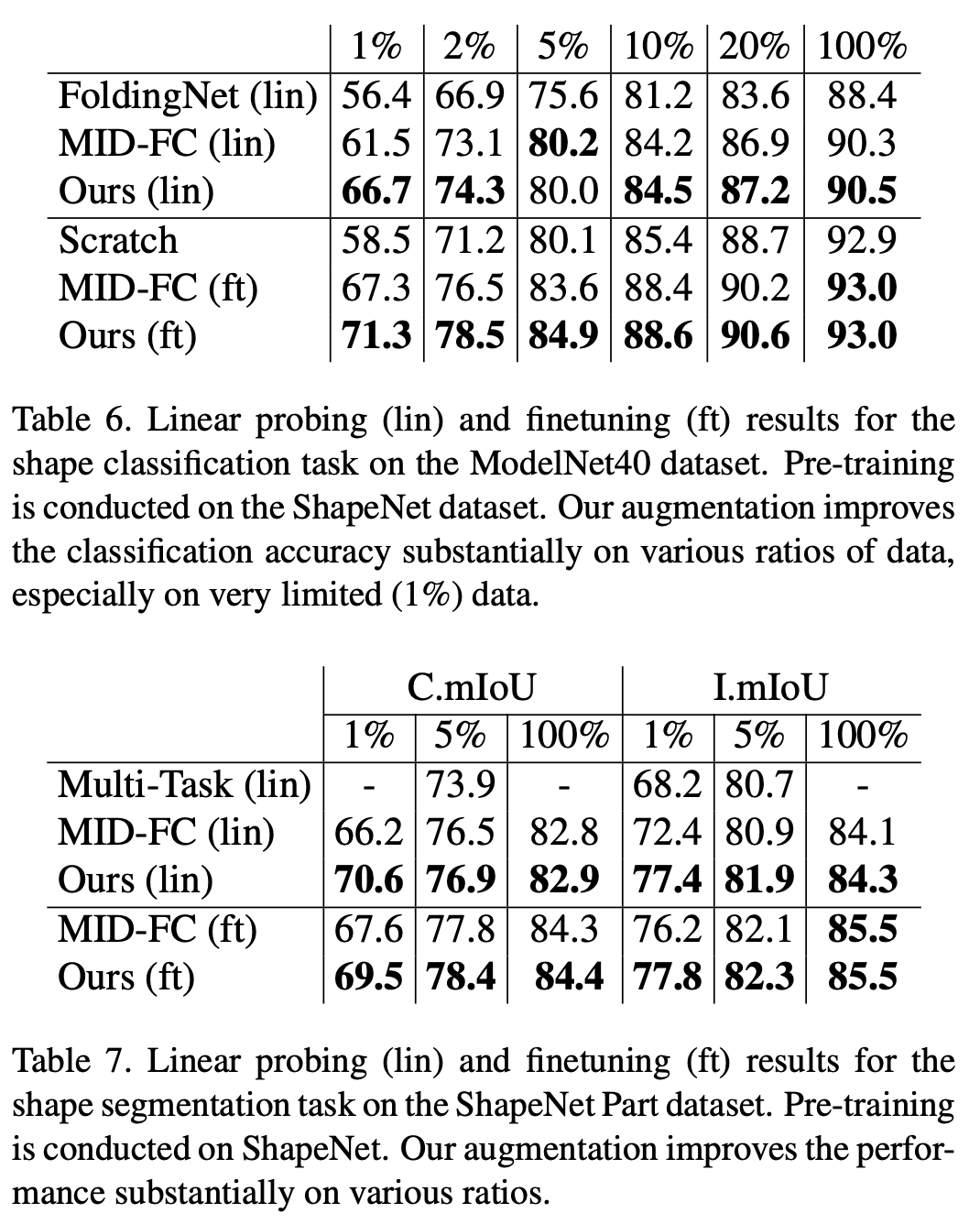
需要重新编写的内容是:模态 2:3D 点云
在 ModelNet40 数据集的分类任务和 ShapeNet Part 数据集的分割任务中,本研究验证了随机量化相对于现有的自监督方法的优越性。特别是在下游训练集数据量较少的情况下,本研究的方法明显超过了现有的点云自监督算法
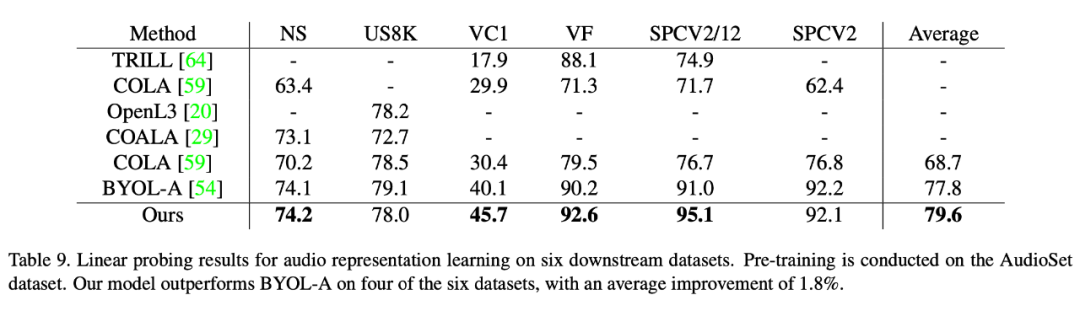
重写内容:第三种模态:语音
在语音数据集上本文的方法也取得了比已有自监督学习方法更优的性能。本文在六个下游数据集上验证了该方法的优越性,其中在最难的数据集 VoxCeleb1 上(包含最多且远超其他数据集的类别个数),本文方法取得了显著的性能提升(5.6 个点)。
重写内容为:模式 4:DABS
DABS是一个通用的自监督学习基准,涵盖了多种模态数据,包括自然图像、文本、语音、传感器数据、医学图像和图文等。在DABS所涵盖的各种不同模态数据上,我们的方法也优于任何已有的模态自监督学习方式

有兴趣的读者可以阅读原始论文,以了解研究内容的详细信息
以上是通用数据增强技术,随机量化适用于任意数据模态的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 靠谱的数字货币交易平台推荐 全球十大数字货币交易所排行榜2025
Apr 28, 2025 pm 04:30 PM
靠谱的数字货币交易平台推荐 全球十大数字货币交易所排行榜2025
Apr 28, 2025 pm 04:30 PM
靠谱的数字货币交易平台推荐:1. OKX,2. Binance,3. Coinbase,4. Kraken,5. Huobi,6. KuCoin,7. Bitfinex,8. Gemini,9. Bitstamp,10. Poloniex,这些平台均以其安全性、用户体验和多样化的功能着称,适合不同层次的用户进行数字货币交易
 全球币圈十大交易所有哪些 排名前十的货币交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球币圈十大交易所有哪些 排名前十的货币交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球十大加密货币交易平台包括Binance、OKX、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、KuCoin和Poloniex,均提供多种交易方式和强大的安全措施。
 排名前十的虚拟币交易app有哪 最新数字货币交易所排行榜
Apr 28, 2025 pm 08:03 PM
排名前十的虚拟币交易app有哪 最新数字货币交易所排行榜
Apr 28, 2025 pm 08:03 PM
Binance、OKX、gate.io等十大数字货币交易所完善系统、高效多元化交易和严密安全措施严重推崇。
 排名靠前的货币交易平台有哪些 最新虚拟币交易所排名榜前10
Apr 28, 2025 pm 08:06 PM
排名靠前的货币交易平台有哪些 最新虚拟币交易所排名榜前10
Apr 28, 2025 pm 08:06 PM
目前排名前十的虚拟币交易所:1.币安,2. OKX,3. Gate.io,4。币库,5。海妖,6。火币全球站,7.拜比特,8.库币,9.比特币,10。比特戳。
 比特币值多少美金
Apr 28, 2025 pm 07:42 PM
比特币值多少美金
Apr 28, 2025 pm 07:42 PM
比特币的价格在20,000到30,000美元之间。1. 比特币自2009年以来价格波动剧烈,2017年达到近20,000美元,2021年达到近60,000美元。2. 价格受市场需求、供应量、宏观经济环境等因素影响。3. 通过交易所、移动应用和网站可获取实时价格。4. 比特币价格波动性大,受市场情绪和外部因素驱动。5. 与传统金融市场有一定关系,受全球股市、美元强弱等影响。6. 长期趋势看涨,但需谨慎评估风险。
 全球币圈十大交易所有哪些 排名前十的货币交易平台2025
Apr 28, 2025 pm 08:12 PM
全球币圈十大交易所有哪些 排名前十的货币交易平台2025
Apr 28, 2025 pm 08:12 PM
2025年全球十大加密货币交易所包括Binance、OKX、Gate.io、Coinbase、Kraken、Huobi、Bitfinex、KuCoin、Bittrex和Poloniex,均以高交易量和安全性着称。
 怎样在C 中测量线程性能?
Apr 28, 2025 pm 10:21 PM
怎样在C 中测量线程性能?
Apr 28, 2025 pm 10:21 PM
在C 中测量线程性能可以使用标准库中的计时工具、性能分析工具和自定义计时器。1.使用库测量执行时间。2.使用gprof进行性能分析,步骤包括编译时添加-pg选项、运行程序生成gmon.out文件、生成性能报告。3.使用Valgrind的Callgrind模块进行更详细的分析,步骤包括运行程序生成callgrind.out文件、使用kcachegrind查看结果。4.自定义计时器可灵活测量特定代码段的执行时间。这些方法帮助全面了解线程性能,并优化代码。
 解密Gate.io战略升级:MeMebox 2.0如何重新定义加密资产管理?
Apr 28, 2025 pm 03:33 PM
解密Gate.io战略升级:MeMebox 2.0如何重新定义加密资产管理?
Apr 28, 2025 pm 03:33 PM
MeMebox 2.0通过创新架构和性能突破重新定义了加密资产管理。1) 它解决了资产孤岛、收益衰减和安全与便利悖论三大痛点。2) 通过智能资产枢纽、动态风险管理和收益增强引擎,提升了跨链转账速度、平均收益率和安全事件响应速度。3) 为用户提供资产可视化、策略自动化和治理一体化,实现了用户价值重构。4) 通过生态协同和合规化创新,增强了平台的整体效能。5) 未来将推出智能合约保险池、预测市场集成和AI驱动资产配置,继续引领行业发展。
