

深度思考 | 大模型的能力边界在哪里?

假如我们有无限的资源,比如有无穷多的数据,无穷大的算力,无穷大的模型,完美的优化算法与泛化表现,请问由此得到的预训练模型是否可以用来解决一切问题?
这是一个大家都非常关心的问题,但已有的机器学习理论却无法回答。它与表达能力理论无关,因为模型无穷大,表达能力自然也无穷大。它与优化、泛化理论也无关,因为我们假设算法的优化、泛化表现完美。换句话说,之前理论研究的问题在这里不存在了!
今天,我给大家介绍一下我在ICML'2023发表的论文On the Power of Foundation Models,从范畴论的角度给出一个答案。
范畴论是什么?
倘若不是数学专业的同学,对范畴论可能比较陌生。范畴论被称为是数学的数学,为现代数学提供了一套基础语言。现代几乎所有的数学领域都是用范畴论的语言描述的,例如代数拓扑、代数几何、代数图论等等。范畴论是一门研究结构与关系的学问,它可以看作是集合论的一种自然延伸:在集合论中,一个集合包含了若干个不同的元素;在范畴论中,我们不仅记录了元素,还记录了元素与元素之间的关系。
Martin Kuppe曾经画了一幅数学地图,把范畴论放到了地图的顶端,照耀着数学各个领域:
关于范畴论的介绍网上有很多,我们这里简单讲几个基本概念:

监督学习的范畴论视角

过去十多年,人们围绕着监督学习框架进行了大量的研究,得到了很多优美的结论。但是,这一框架也限制了人们对AI算法的认识,让理解预训练大模型变得极为困难。例如,已有的泛化理论很难用来解释模型的跨模态学习能力。

我们能不能通过采样函子的输入输出数据,学到这个函子?
注意到,在这个过程中我们没有考虑两个范畴 X,Y 内部的结构。实际上,监督学习没有对范畴内部的结构有任何假设,所以可以认为在两个范畴内部,任何两个对象之间都没有关系。因此,我们完全可以把 X 和 Y 看作是两个集合。这个时候,泛化理论著名的no free lunch定理告诉我们,假如没有额外假设,那么学好从 X 到 Y 的函子这件事情是不可能的(除非有海量样本)。

乍看之下,这个新视角毫无用处。给范畴加约束也好,给函子加约束也好,似乎没什么本质区别。实际上,新视角更像是传统框架的阉割版本:它甚至没有提及监督学习中极为重要的损失函数的概念,也就无法用于分析训练算法的收敛或泛化性质。那么我们应该如何理解这个新视角呢?
我想,范畴论提供了一种鸟瞰视角。它本身不会也不应该替代原有的更具体的监督学习框架,或者用来产生更好的监督学习算法。相反,监督学习框架是它的“子模块”,是解决具体问题时可以采用的工具。因此,范畴论不会在乎损失函数或者优化过程——这些更像是算法的实现细节。它更关注范畴与函子的结构,并且尝试理解某个函子是否可学习。这些问题在传统监督学习框架中极为困难,但是在范畴视角下变得简单。
自监督学习的范畴论视角
预训练任务与范畴

下面我们先明确在预训练任务下范畴的定义。实际上,倘若我们没有设计任何预训练任务,那么范畴中的对象之间就没有关系;但是设计了预训练任务之后,我们就将人类的先验知识以任务的方式,给范畴注入了结构。而这些结构就成为了大模型拥有的知识。
具体来说:

换句话说,当我们在一个数据集上定义了预训练任务之后,我们就定义了一个包含对应关系结构的范畴。预训练任务的学习目标,就是让模型把这个范畴学好。具体来说,我们看一下理想模型的概念。
理想模型

在这里,“数据无关”意味着 是在看到数据之前就预先定义的;但下标 f则表示可以通过黑盒调用的方式使用 f 和 这两个函数。换句话说, 是一个“简单”的函数,但可以借助模型 f 的能力来表示更复杂的关系。这一点可能不太好理解,我们用压缩算法来打个比方。压缩算法本身可能是数据相关的,比如它可能是针对数据分布进行了特殊优化。然而,作为一个数据无关的函数 ,它无法访问数据分布,但可以调用压缩算法来解压数据,因为“调用压缩算法”这一操作是数据无关的。
针对不同的预训练任务,我们可以定义不同的 :

因此,我们可以这么说:预训练学习的过程,就是在寻找理想模型 f 的过程。
可是,即使 是确定的,根据定义,理想模型也并不唯一。理论上说,模型 f 可能具有超级智能,即使在不学习 C 中数据的前提下也能做任何事情。在这种情况下,我们无法对 f 的能力给出有意义的论断。因此,我们应该看看问题的另一面:
给定由预训练任务定义的范畴 C ,对于任何一个理想的 f ,它能解决哪些任务?
这是我们在本文一开始就想回答的核心问题。我们先介绍一个重要概念。
米田嵌入
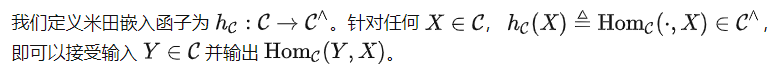

很容易证明, 是能力最弱的理想模型,因为给定其他理想模型 f , 中的所有关系也包含在 f 中。同时,它也是没有其他额外假设前提之下,预训练模型学习的最终目标。因此,为了回答我们的核心问题,我们下面专门考虑 。
提示调优(Prompt tuning): 见多才能识广

能否解决某个任务 T ?要回答这个问题,我们先介绍范畴论中最重要的一个定理。
米田引理

即, 可以用这两种表征计算出 T(X) 。然而,注意到任务提示 P 必须通过 而非 发送,这意味着我们会得到 (P) 而非 T 作为 的输入。这引出了范畴论中另一个重要的定义。
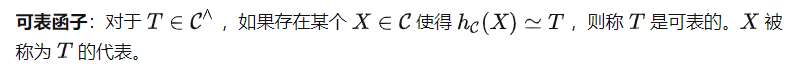
基于这个定义,我们可以得到如下定理(证明略去)。
定理1与推论

值得一提的是,有些提示调优算法的提示不一定是范畴 C 中的对象,可能是特征空间中的表征。这种方法有可能支持比可表任务更复杂的任务,但增强效果取决于特征空间的表达能力。下面我们提供定理1的一个简单推论。
推论1. 对于预测图像旋转角度的预训练任务[4],提示调优不能解决分割或分类等复杂的下游任务。
证明:预测图像旋转角度的预训练任务会将给定图像旋转四个不同的角度:0°, 90°, 180°, 和 270°,并让模型进行预测。因此,这个预训练任务定义的范畴将每个对象都放入一个包含4个元素的群中。显然,像分割或分类这样的任务不能由这样简单的对象表出。
推论1有点反直觉,因为原论文提到[4],使用该方法得到的模型可以部分解决分类或分割等下游任务。然而,在我们的定义中,解决任务意味着模型应该为每个输入生成正确的输出,因此部分正确并不被视为成功。这也与我们文章开头提到的问题相符:在无限资源的支持下,预测图像旋转角度的预训练任务能否用于解决复杂的下游任务?推论1给出了否定的答案。
微调(Fine tuning): 表征不丢信息
提示调优的能力有限,那么微调算法呢?基于米田函子扩展定理(参见 [5]中的命题2.7.1),我们可以得到如下定理。
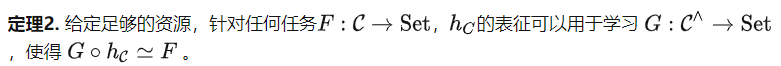
定理2考虑的下游任务是基于 C 的结构,而不是数据集中的数据内容。因此,之前提到的预测旋转图片角度的预训练任务定义的范畴仍然具有非常简单的群结构。但是根据定理2,我们可以用它解决更多样化的任务。例如,我们可以将所有对象映射到同一个输出,这是无法通过提示调优来实现的。定理2明确了预训练任务的重要性,因为更好的预训练任务将创建更强大的范畴 C ,从而进一步提高了模型的微调潜力。
对于定理2有两个常见的误解。首先,即使范畴 C 包含了大量信息,定理2只提供了一个粗糙的上界,说 记录了 C 中所有的信息,有潜力解决任何任务,而并没有说任何微调算法都可以达到这个目的。其次,定理2乍看像是过参数化理论。然而,它们分析的是自监督学习的不同步骤。过参数化分析的是预训练步骤,说的是在某些假设下,只要模型足够大且学习率足够小,对于预训练任务,优化和泛化误差将非常小。而定理2分析的则是预训练后的微调步骤,说该步骤有很大潜力。
讨论与总结
监督学习与自监督学习。从机器学习的角度来看,自监督学习仍然是一种监督学习,只是获取标签的方式更巧妙一些而已。但是从范畴论的角度来看,自监督学习定义了范畴内部的结构,而监督学习定义了范畴之间的关系。因此,它们处于人工智能地图的不同板块,在做完全不一样的事情。

适用场景。由于本文开头考虑了无限资源的假设,导致很多朋友可能会认为,这些理论只有在虚空之中才会真正成立。其实并非如此。在我们真正的推导过程中,我们只是考虑了理想模型与 这一预定义的函数。实际上,只要 确定了之后,任何一个预训练模型 f (哪怕是在随机初始化阶段)都可以针对输入XC 计算出 f(X) ,从而使用 计算出两个对象的关系。换句话说,只要当 确定之后,每个预训练模型都对应于一个范畴,而预训练的目标不过是将这个范畴不断与由预训练任务定义的范畴对齐而已。因此,我们的理论针对每一个预训练模型都成立。
核心公式。很多人说,如果AI真有一套理论支撑,那么它背后应该有一个或者几个简洁优美的公式。我想,如果需要用一个范畴论的公式来描绘大模型能力的话,它应该就是我们之前提到的:
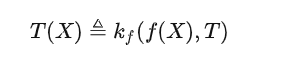
对于大模型比较熟悉的朋友,在深入理解这个公式的含义之后,可能会觉得这个式子在说废话,不过是把现在大模型的工作模式用比较复杂的数学式子写出来了而已。
但事实并非如此。现代科学基于数学,现代数学基于范畴论,而范畴论中最重要的定理就是米田引理。我写的这个式子将米田引理的同构式拆开变成了不对称的版本,却正好和大模型的打开方式完全一致。
我认为这一定不是巧合。如果范畴论可以照耀现代数学的各个分支,它也一定可以照亮通用人工智能的前进之路。
本文灵感源于与北京智源人工智能研究院千方团队的长期紧密合作。

原文链接:https://mp.weixin.qq.com/s/bKf3JADjAveeJDjFzcDbkw
以上是深度思考 | 大模型的能力边界在哪里?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 web3交易平台排行榜_web3全球交易所前十名汇总
Apr 21, 2025 am 10:45 AM
web3交易平台排行榜_web3全球交易所前十名汇总
Apr 21, 2025 am 10:45 AM
币安是全球数字资产交易生态的霸主,其特点包括:1. 日均交易量突破$1500亿,支持500 交易对,覆盖98%主流币种;2. 创新矩阵涵盖衍生品市场、Web3布局和教育体系;3. 技术优势为毫秒级撮合引擎,峰值处理量达140万笔/秒;4. 合规进展持有15国牌照,并在欧美设立合规实体。
 跨链交易什么意思?跨链交易所有哪些?
Apr 21, 2025 pm 11:39 PM
跨链交易什么意思?跨链交易所有哪些?
Apr 21, 2025 pm 11:39 PM
支持跨链交易的交易所有:1. Binance,2. Uniswap,3. SushiSwap,4. Curve Finance,5. Thorchain,6. 1inch Exchange,7. DLN Trade,这些平台通过各种技术支持多链资产交易。
 十大加密货币交易所平台 世界最大的数字货币交易所榜单
Apr 21, 2025 pm 07:15 PM
十大加密货币交易所平台 世界最大的数字货币交易所榜单
Apr 21, 2025 pm 07:15 PM
在当今的加密货币市场中,交易所扮演着至关重要的角色,它们不仅是投资者进行买卖交易的平台,更是市场流动性和价格发现的重要来源。全球最大的虚拟货币交易所排行前十,这些交易所不仅在交易量上遥遥领先,而且在用户体验、安全性和创新服务方面也各有千秋。排行榜首的交易所通常拥有庞大的用户基础和广泛的市场影响力,它们的交易量和资产种类往往是其他交易所难以企及的。
 币圈杠杆交易所排名 币圈十大杠杆交易所APP最新推荐
Apr 21, 2025 pm 11:24 PM
币圈杠杆交易所排名 币圈十大杠杆交易所APP最新推荐
Apr 21, 2025 pm 11:24 PM
2025年在杠杆交易、安全性和用户体验方面表现突出的平台有:1. OKX,适合高频交易者,提供最高100倍杠杆;2. Binance,适用于全球多币种交易者,提供125倍高杠杆;3. Gate.io,适合衍生品专业玩家,提供100倍杠杆;4. Bitget,适用于新手及社交化交易者,提供最高100倍杠杆;5. Kraken,适合稳健型投资者,提供5倍杠杆;6. Bybit,适用于山寨币探索者,提供20倍杠杆;7. KuCoin,适合低成本交易者,提供10倍杠杆;8. Bitfinex,适合资深玩
 虚拟币价格上涨或者下降是为什么 虚拟币价格上涨或者下降的原因
Apr 21, 2025 am 08:57 AM
虚拟币价格上涨或者下降是为什么 虚拟币价格上涨或者下降的原因
Apr 21, 2025 am 08:57 AM
虚拟币价格上涨因素包括:1.市场需求增加,2.供应量减少,3.利好消息刺激,4.市场情绪乐观,5.宏观经济环境;下降因素包括:1.市场需求减少,2.供应量增加,3.利空消息打击,4.市场情绪悲观,5.宏观经济环境。
 ETH 升级后新手如何规避亏损
Apr 21, 2025 am 10:03 AM
ETH 升级后新手如何规避亏损
Apr 21, 2025 am 10:03 AM
新手在ETH升级后应采取以下策略规避亏损:1.做好功课,了解ETH基本知识和升级内容;2.控制仓位,小额试水并分散投资;3.制定交易计划,明确目标并设定止损点;4.理性分析,避免情绪化决策;5.选择正规可靠的交易平台;6.考虑长期持有,避免短期波动影响。
 币圈交易所前十的平台是哪些?
Apr 21, 2025 pm 12:21 PM
币圈交易所前十的平台是哪些?
Apr 21, 2025 pm 12:21 PM
头部交易所包括:1. 币安(Binance),全球最大交易量,支持600 币种,现货手续费0.1%;2. OKX,均衡型平台,支持708交易对,永续合约手续费0.05%;3. Gate.io,覆盖2700 小币种,现货手续费0.1%-0.3%;4. Coinbase,美国合规标杆,现货手续费0.5%;5. Kraken,安全性顶尖,定期储备审计。
 如何在币安拿下 KERNEL 空投奖励 全流程攻略
Apr 21, 2025 pm 01:03 PM
如何在币安拿下 KERNEL 空投奖励 全流程攻略
Apr 21, 2025 pm 01:03 PM
在加密货币的繁华世界里,新机遇总是不断涌现。当下,KernelDAO (KERNEL) 空投活动正备受瞩目,吸引着众多投资者的目光。那么,这个项目究竟是什么来头?BNB Holder 又能从中获得怎样的好处?别急,下面将为你一一揭晓。
