

快速训练小型专业模型:只需1句指令、5美元和20分钟,体验Prompt2Model!

大规模语言模型(LLM)使用户能够通过提示和上下文学习来构建强大的自然语言处理系统。然而,从另一个角度来看,LLM 在某些特定的自然语言处理任务上表现出一定的退步:这些模型的部署需要大量的计算资源,并且通过 API 与模型进行交互可能会引发潜在的隐私问题
为了应对这些问题,来自卡内基梅隆大学(CMU)和清华大学的研究人员共同推出了Prompt2Model框架。该框架的目标是将基于LLM的数据生成和检索方法相结合,以克服上述挑战。使用Prompt2Model框架,用户只需提供与LLM相同的提示,即可自动收集数据并高效地训练适用于特定任务的小型专业模型
研究人员进行了一项实验,针对三个自然语言处理子任务进行了研究。他们使用了少量样本提示作为输入,并且只花费了5美元来收集数据,并进行了20分钟的训练。通过Prompt2Model框架生成的模型在性能上比强大的LLM模型gpt-3.5-turbo提升了20%。与此同时,模型的大小缩小了700倍。研究人员进一步验证了这些数据在真实场景中对模型效果的影响,使得模型开发人员能够在部署之前预估模型的可靠性。该框架已经以开源形式提供:

- 框架的 GitHub 仓库地址:https://github.com/neulab/prompt2model
- 框架演示视频链接:youtu.be/LYYQ_EhGd-Q
- 框架相关论文链接:https://arxiv.org/abs/2308.12261
背景
建立特定的自然语言处理任务系统通常是相当复杂的。系统的构建者需要明确定义任务的范围,获取特定的数据集,选择合适的模型架构,进行模型的训练和评估,然后将其部署以供实际应用
大规模语言模型(LLM)如GPT-3为这一过程提供了更加简便的解决方案。用户只需提供任务提示(instruction)以及一些示例(examples),LLM便能生成相应的文本输出。然而,通过提示生成文本可能会消耗大量计算资源,并且使用提示的方式不如经过专门训练的模型稳定。此外,LLM的可用性还受到成本、速度和隐私等方面的限制
为了解决这些问题,研究人员开发了Prompt2Model框架。该框架结合了基于LLM的数据生成和检索技术,以克服上述限制。该系统首先从提示信息中提取关键信息,然后生成并检索训练数据,最终生成可供部署的专业化模型
Prompt2Model 框架自动执行以下核心步骤: 1. 数据预处理:将输入数据进行清洗和标准化,以确保其适用于模型训练。 2. 模型选择:根据任务的要求,选择合适的模型架构和参数。 3. 模型训练:使用预处理后的数据对选定的模型进行训练,以优化模型的性能。 4. 模型评估:通过评估指标对训练后的模型进行性能评估,以确定其在特定任务上的表现。 5. 模型调优:根据评估结果,对模型进行调优,以进一步提升其性能。 6. 模型部署:将训练好的模型部署到实际应用环境中,以实现预测或推理功能。 通过自动化执行这些核心步骤,Prompt2Model 框架能够帮助用户快速构建和部署高性能的自然语言处理模型
- 数据集与模型检索:收集相关数据集和预训练模型。
- 数据集生成:利用 LLM 创建伪标记数据集。
- 模型微调:通过混合检索数据和生成数据对模型进行微调。
- 模型测试:在测试数据集和用户提供的真实数据集上对模型进行测试。
通过对多个不同任务进行实证评估,我们发现Prompt2Model的成本显著降低,模型的体积也大幅缩小,但性能却超越了gpt-3.5-turbo。Prompt2Model框架不仅可以作为高效构建自然语言处理系统的工具,还可以作为探索模型集成训练技术的平台
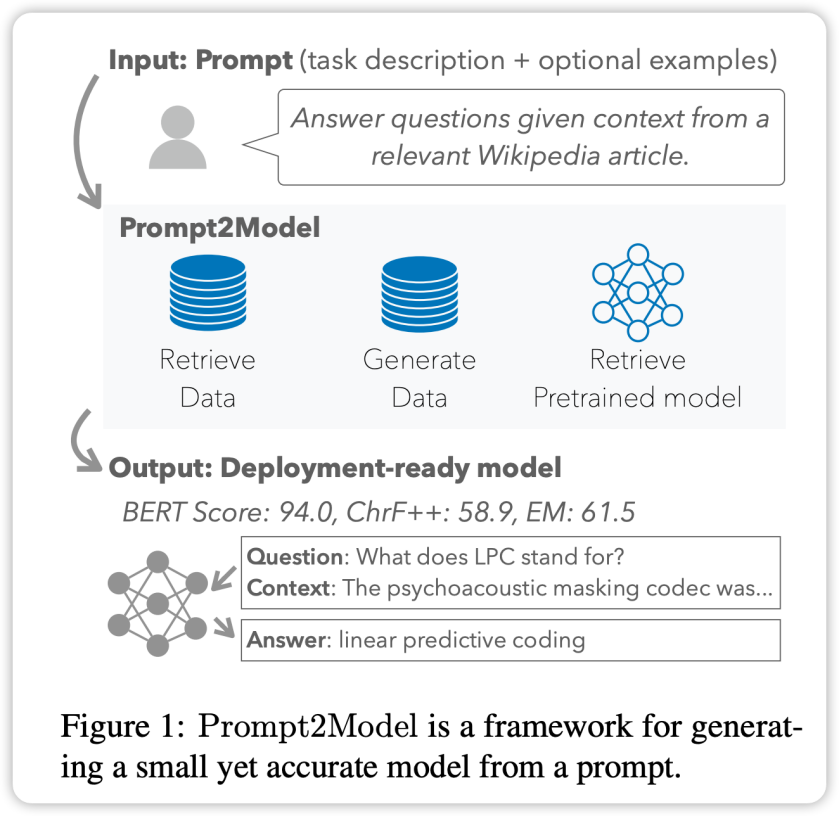
框架
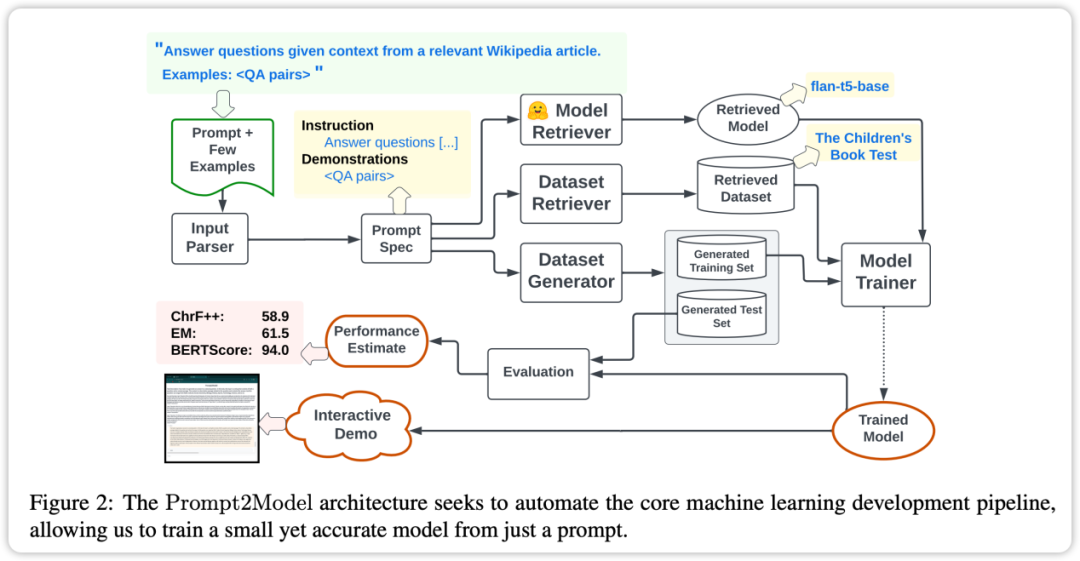
Prompt2Model 框架的核心特点是高度自动化。它的流程包括数据收集、模型训练、评估和部署等多个环节,如上图所示。其中,自动化数据收集系统起着关键作用,它通过数据集检索和基于 LLM 的数据生成,获取与用户需求密切相关的数据。接下来,系统会检索预训练模型,并在获取的数据集上进行微调。最后,系统会在测试集上对经过训练的模型进行评估,并创建用于与模型交互的 Web 用户界面(UI)
Prompt2Model 框架的关键特点包括:
- Prompt 驱动:Prompt2Model 的核心思想在于使用 prompt 作为驱动,用户可以直接描述所需的任务,而无需深入了解机器学习的具体实现细节。
- 自动数据收集:框架通过数据集检索和生成技术来获取与用户任务高度匹配的数据,从而建立训练所需的数据集。
- 预训练模型:框架利用预训练模型并进行微调,从而节省大量的训练成本和时间。
- 效果评估:Prompt2Model 支持在实际数据集上进行模型测试和评估,使得在部署模型之前就能进行初步预测和性能评估,从而提高了模型的可靠性。
Prompt2Model 框架具备以下特点,使其成为一个强大的工具,能够高效地完成自然语言处理系统的构建过程,并且提供了先进的功能,如数据自动收集、模型评估以及用户交互界面的创建
实验与结果
为了评估Prompt2Model系统的性能,在实验设计中,研究者选择了三个不同的任务
- 机器阅读问答(Machine Reading QA):使用 SQuAD 作为实际评估数据集。
- 日语自然语言到代码转换(Japanese NL-to-Code):使用 MCoNaLa 作为实际评估数据集。
- 时间表达式规范化(Temporal Expression Normalization):使用 Temporal 数据集作为实际评估数据集。
此外,研究人员还使用GPT-3.5-turbo作为基准模型进行比较。实验结果得出以下结论:
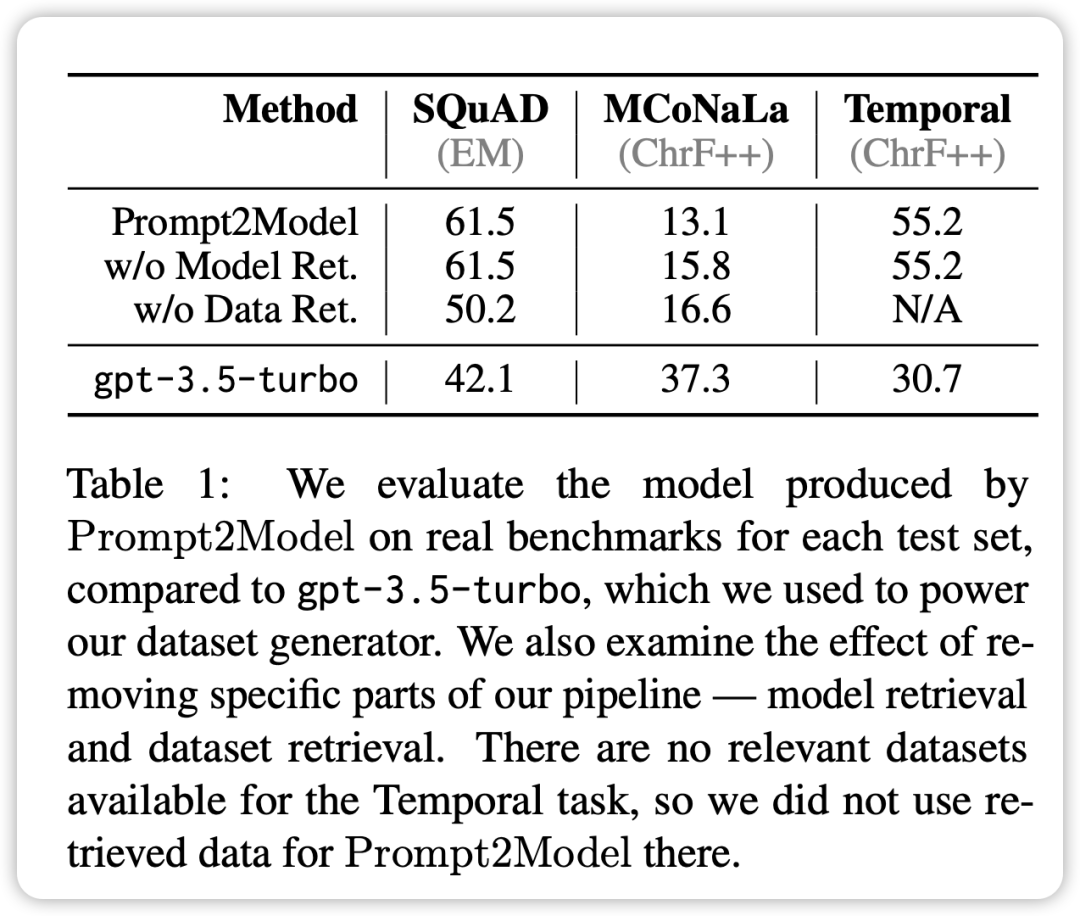
- 在除了代码生成任务之外的各项任务中,Prompt2Model 系统所生成的模型明显优于基准模型 GPT-3.5-turbo,尽管生成的模型参数规模远小于 GPT-3.5-turbo。
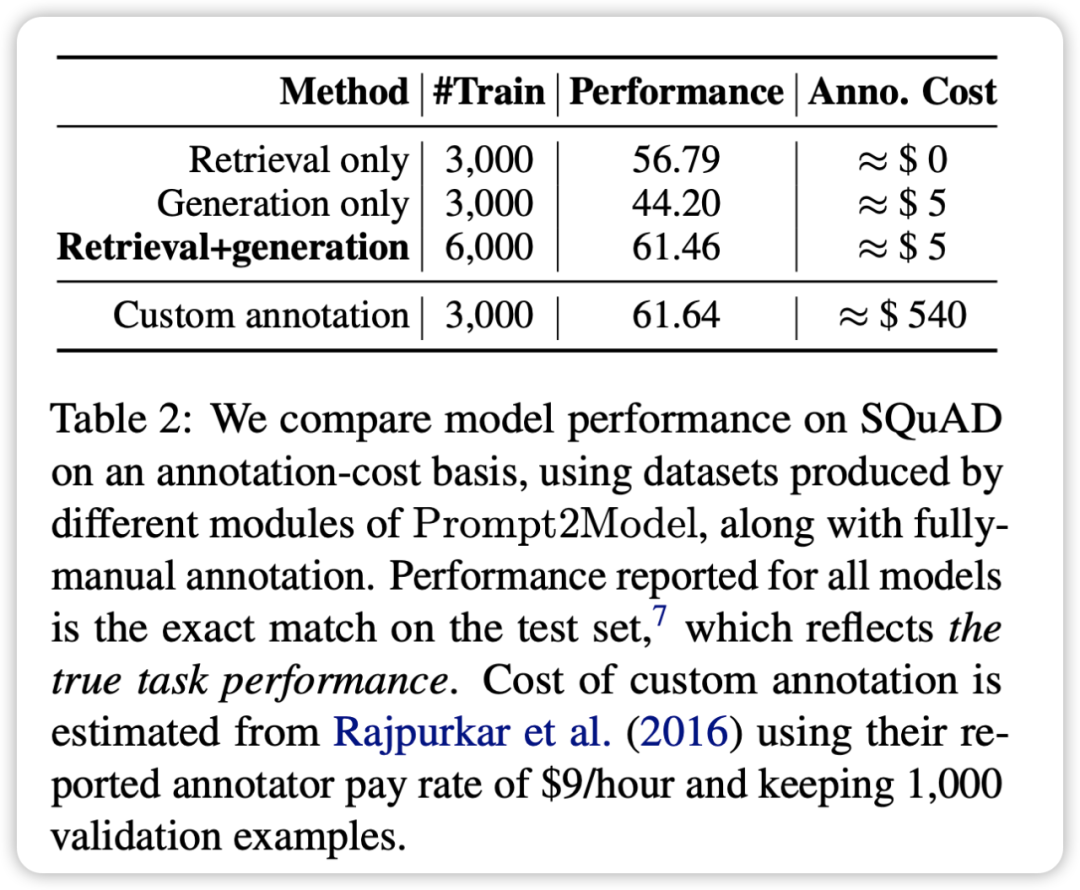
- 通过将检索数据集与生成数据集进行混合训练,可以达到与直接使用实际数据集训练相媲美的效果。这验证了 Prompt2Model 框架能够极大地降低人工标注的成本。
- 数据生成器所生成的测试数据集能够有效区分不同模型在实际数据集上的性能。这表明生成的数据具有较高的质量,在模型训练方面具有充分的效果。
- 在日语到代码转换任务中,Prompt2Model 系统的表现不如 GPT-3.5-turbo。
可能是由于生成的数据集质量不高,以及缺乏适当的预训练模型等原因所导致
综合而言,Prompt2Model 系统在多个任务上成功生成了高质量的小型模型,极大地减少了对人工标注数据的需求。然而,在某些任务上仍需要进一步改进
总结
Prompt2Model 框架是由研究团队开发的一项创新技术,它通过自然语言提示来自动构建任务特定模型。这一技术的推出大大降低了构建定制化自然语言处理模型的难度,进一步扩展了 NLP 技术的应用范围
验证实验结果显示,Prompt2Model框架生成的模型规模较大型语言模型显着减小,并在多个任务上表现优于GPT-3.5-turbo等模型。同时,该框架生成的评估数据集也被证实能够有效评估不同模型在真实数据集上的性能。这为指导模型最终部署提供了重要价值
Prompt2Model 框架为行业和广大用户提供了一种低成本、易于上手的方式,用于获取满足特定需求的 NLP 模型。这对于推动 NLP 技术的广泛应用具有重要意义。未来的工作将继续致力于进一步优化框架的性能
按照文章顺序,本文作者如下: 重新编写的内容:根据文章的顺序,本文的作者如下:
维贾伊·维斯瓦纳坦:http://www.cs.cmu.edu/~vijayv/
赵晨阳: https://zhaochenyang20.github.io/Eren_Chenyang_Zhao/
Amanda Bertsch: https://www.cs.cmu.edu/~abertsch/ 阿曼达·贝尔奇: https://www.cs.cmu.edu/~abertsch/
吴同爽:https://www.cs.cmu.edu/~sherryw/
格雷厄姆·纽比格:http://www.phontron.com/
以上是快速训练小型专业模型:只需1句指令、5美元和20分钟,体验Prompt2Model!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 中通过使用 ALTER TABLE 语句为现有表添加新列。具体步骤包括:确定表名称和列信息、编写 ALTER TABLE 语句、执行语句。例如,为 Customers 表添加 email 列(VARCHAR(50)):ALTER TABLE Customers ADD email VARCHAR(50);
 SQL 添加列的语法是什么
Apr 09, 2025 pm 02:51 PM
SQL 添加列的语法是什么
Apr 09, 2025 pm 02:51 PM
SQL 中添加列的语法为 ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value]; 其中,table_name 是表名,column_name 是新列名,data_type 是数据类型,NOT NULL 指定是否允许空值,DEFAULT default_value 指定默认值。
 SQL 清空表:性能优化技巧
Apr 09, 2025 pm 02:54 PM
SQL 清空表:性能优化技巧
Apr 09, 2025 pm 02:54 PM
提高 SQL 清空表性能的技巧:使用 TRUNCATE TABLE 代替 DELETE,释放空间并重置标识列。禁用外键约束,防止级联删除。使用事务封装操作,保证数据一致性。批量删除大数据,通过 LIMIT 限制行数。清空后重建索引,提高查询效率。
 SQL 添加列时如何设置默认值
Apr 09, 2025 pm 02:45 PM
SQL 添加列时如何设置默认值
Apr 09, 2025 pm 02:45 PM
为新添加的列设置默认值,使用 ALTER TABLE 语句:指定添加列并设置默认值:ALTER TABLE table_name ADD column_name data_type DEFAULT default_value;使用 CONSTRAINT 子句指定默认值:ALTER TABLE table_name ADD COLUMN column_name data_type CONSTRAINT default_constraint DEFAULT default_value;
 使用 DELETE 语句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
使用 DELETE 语句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
是的,DELETE 语句可用于清空 SQL 表,步骤如下:使用 DELETE 语句:DELETE FROM table_name;替换 table_name 为要清空的表的名称。
 Redis内存碎片如何处理?
Apr 10, 2025 pm 02:24 PM
Redis内存碎片如何处理?
Apr 10, 2025 pm 02:24 PM
Redis内存碎片是指分配的内存中存在无法再分配的小块空闲区域。应对策略包括:重启Redis:彻底清空内存,但会中断服务。优化数据结构:使用更适合Redis的结构,减少内存分配和释放次数。调整配置参数:使用策略淘汰最近最少使用的键值对。使用持久化机制:定期备份数据,重启Redis清理碎片。监控内存使用情况:及时发现问题并采取措施。
 phpmyadmin建立数据表
Apr 10, 2025 pm 11:00 PM
phpmyadmin建立数据表
Apr 10, 2025 pm 11:00 PM
要使用 phpMyAdmin 创建数据表,以下步骤必不可少:连接到数据库并单击“新建”标签。为表命名并选择存储引擎(推荐 InnoDB)。通过单击“添加列”按钮添加列详细信息,包括列名、数据类型、是否允许空值以及其他属性。选择一个或多个列作为主键。单击“保存”按钮创建表和列。
 怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
创建Oracle数据库并非易事,需理解底层机制。1. 需了解数据库和Oracle DBMS的概念;2. 掌握SID、CDB(容器数据库)、PDB(可插拔数据库)等核心概念;3. 使用SQL*Plus创建CDB,再创建PDB,需指定大小、数据文件数、路径等参数;4. 高级应用需调整字符集、内存等参数,并进行性能调优;5. 需注意磁盘空间、权限和参数设置,并持续监控和优化数据库性能。 熟练掌握需不断实践,才能真正理解Oracle数据库的创建和管理。
