

利用动态原型扩展的自训练方法,探索开放世界测试段训练技巧

提高模型泛化能力是推动基于视觉的感知方法落地的重要基础,测试段训练和适应(Test-Time Training/Adaptation)通过在测试段调整模型参数权重,将模型泛化至未知的目标域数据分布段。现有 TTT/TTA 方法通常着眼于在闭环世界的目标域数据下提高测试段训练性能。
然而,在许多应用场景中,目标领域很容易受到强域外数据(Strong OOD)的污染,比如与语义类别无关的数据。这种场景也被称为开放世界测试段训练(OWTTT)。在这种情况下,现有的TTT/TTA通常会强制将强域外数据分类到已知类别中,从而最终干扰对弱域外数据(Weak OOD)如受到噪声干扰图像的分辨能力
最近,华南理工大学和A*STAR团队首次提出了开放世界测试段训练的设定,并且推出了相应的训练方法

- 论文:https://arxiv.org/abs/2308.09942
- 代码:https://github.com/Yushu-Li/OWTTT
本文首先提出了一种自适应阈值的强域外数据样本过滤方法,以提高自训练 TTT 方法在开放世界中的鲁棒性。该方法进一步提出了一种基于动态扩展原型来表征强域外样本的方法,以改进弱/强域外数据分离效果。最后,通过分布对齐来约束自训练
本研究的方法在5个不同的OWTTT基准上取得了最佳的性能表现,并为TTT的后续研究开拓了面向更加鲁棒TTT方法的新方向。该研究已被ICCV 2023接收为口头报告论文
引言
测试段训练(TTT)可以仅在推理阶段访问目标域数据,并对分布偏移的测试数据进行即时推理。TTT 的成功已经在许多人工选择的合成损坏目标域数据上得到证明。然而,现有的 TTT 方法的能力边界尚未得到充分探索。
为促进开放场景下的 TTT 应用,研究的重点已转移到调查 TTT 方法可能失败的场景。人们在更现实的开放世界环境下开发稳定和强大的 TTT 方法已经做出了许多努力。而在本文工作中,我们深入研究了一个很常见但被忽略的开放世界场景,其中目标域可能包含从显著不同的环境中提取的测试数据分布,例如与源域不同的语义类别,或者只是随机噪声。
我们将上述测试数据称为强分布外数据(strong OOD)。而在本工作中被称为弱 OOD 数据则是分布偏移的测试数据,例如常见的合成损坏。因此,现有工作缺乏对这种现实环境的研究促使我们探索提高开放世界测试段训练(OWTTT)的鲁棒性,其中测试数据被强 OOD 样本污染。
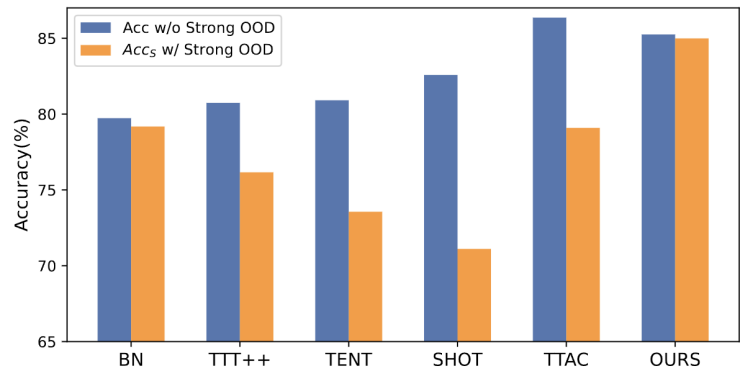
图 1 :现有的 TTT 方法在 OWTTT 设定下的评估结果
如图 1 所示,我们首先对现有的 TTT 方法在 OWTTT 设定下进行评估,发现通过自训练和分布对齐的 TTT 方法都会受到强 OOD 样本的影响。这些结果表明,应用现有的 TTT 技术无法在开放世界中实现安全的测试时训练。我们将它们的失败归因于以下两个原因。
- 基于自训练的 TTT 很难处理强 OOD 样本,因为它必须将测试样本分配给已知的类别。尽管可以通过应用半监督学习中采用的阈值来过滤掉一些低置信度样本,但仍然不能保证滤除所有强 OOD 样本。
- 当计算强 OOD 样本来估计目标域分布时,基于分布对齐的方法将会受到影响。全局分布对齐 [1] 和类别分布对齐 [2] 都可能受到影响,并导致特征分布对齐不准确。
为了解决现有TTT方法失败的潜在原因,我们提出了两种技术相结合的方法,以提高自训练框架下开放世界TTT的鲁棒性
首先,我们在自训练的变体上构建 TTT 的基线,即在目标域中以源域原型作为聚类中心进行聚类。为了减轻自训练受到错误伪标签的强 OOD 的影响,我们设计了一种无超参数的方法来拒绝强 OOD 样本。
为了进一步分离弱 OOD 样本和强 OOD 样本的特征,我们允许原型池通过选择孤立的强 OOD 样本扩展。因此,自训练将允许强 OOD 样本围绕新扩展的强 OOD 原型形成紧密的聚类。这将有利于源域和目标域之间的分布对齐。我们进一步提出通过全局分布对齐来规范自我训练,以降低确认偏差的风险。
最后,为了综合开放世界的 TTT 场景,我们采用 CIFAR10-C、CIFAR100-C、ImageNet-C、VisDA-C、ImageNet-R、Tiny-ImageNet、MNIST 和 SVHN 数据集,并通过利用一个数据集为弱 OOD,其他为强 OOD 建立基准数据集。我们将此基准称为开放世界测试段训练基准,并希望这能鼓励未来更多的工作关注更现实场景中测试段训练的稳健性。
方法
论文将所提出的方法分为四个部分进行介绍
1)概述开放世界下测试段训练任务的设定。
2)介绍了如何通过重写内容为:聚类分析实现 TTT 以及如何扩展原型以进行开放世界测试时训练。
3)介绍了如何利用目标域数据进行动态原型扩展。
4)引入分布对齐与重写内容为:聚类分析相结合,以实现强大的开放世界测试时训练。
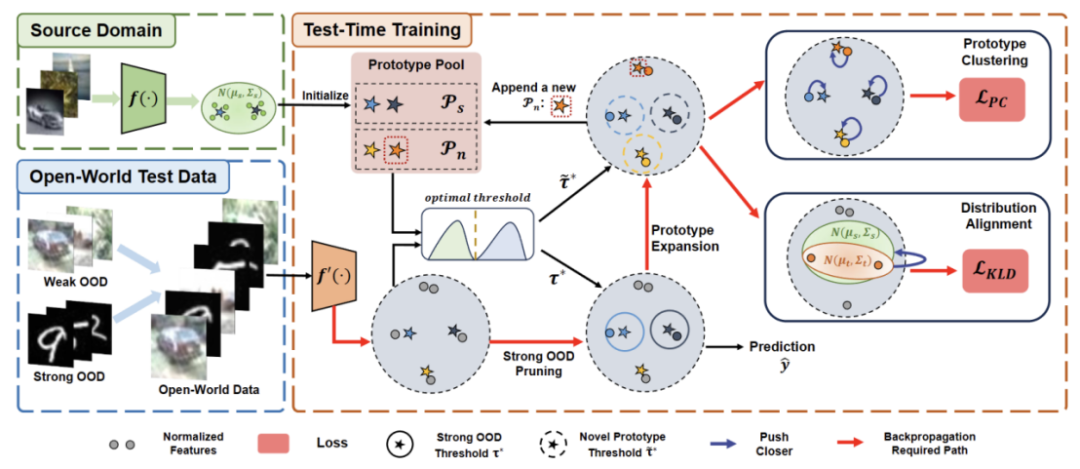
图 2 :方法概览图
任务设定
TTT 的目的是使源域预训练模型适应目标域,其中目标域可能会相对于源域有分布迁移。在标准的封闭世界 TTT 中,源域和目标域的标签空间是相同的。然而在开放世界 TTT 中,目标域的标签空间包含源域的目标空间,也就是说目标域具有未见过的新语义类别
为了避免 TTT 定义之间的混淆,我们采用 TTAC [2] 中提出的顺序测试时间训练(sTTT)协议进行评估。在 sTTT 协议下,测试样本被顺序测试,并在观察到小批量测试样本后进行模型更新。对到达时间戳 t 的任何测试样本的预测不会受到到达 t+k(其 k 大于 0)的任何测试样本的影响。
重写内容为:聚类分析
受到域适应任务中使用聚类的工作启发 [3,4],我们将测试段训练视为发现目标域数据中的簇结构。通过将代表性原型识别为聚类中心,在目标域中识别聚类结构,并鼓励测试样本嵌入到其中一个原型附近。重写内容为:聚类分析的目标定义为最小化样本与聚类中心余弦相似度的负对数似然损失,如下式所示。
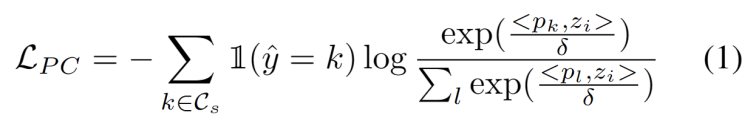
我们开发了一种无超参数的方法来滤除强 OOD 样本,以避免调整模型权重的负面影响。具体来说,我们为每个测试样本定义一个强 OOD 分数 os 作为与源域原型的最高相似度,如下式所示。
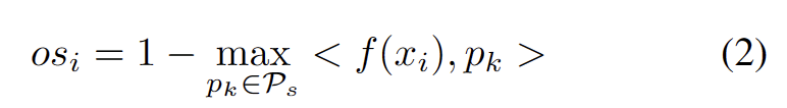
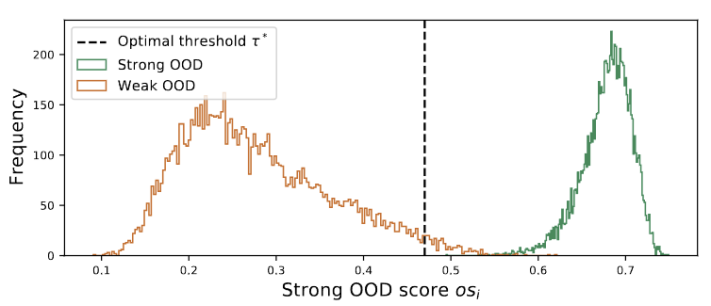
图 3 离群值呈双峰分布
我们观察到离群值服从双峰分布,如图 3 所示。因此,我们没有指定固定阈值,而是将最佳阈值定义为分离两种分布的的最佳值。具体来说,问题可以表述为将离群值分为两个簇,最佳阈值将最小化中的簇内方差。优化下式可以通过以 0.01 的步长穷举搜索从 0 到 1 的所有可能阈值来有效实现。
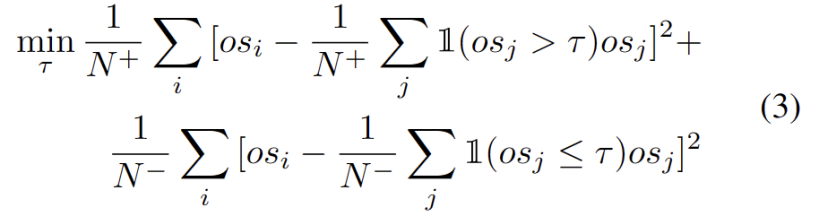
动态原型扩展
扩展强 OOD 原型池需要同时考虑源域和强 OOD 原型来评估测试样本。为了从数据中动态估计簇的数量,之前的研究了类似的问题。确定性硬聚类算法 DP-means [5] 是通过测量数据点到已知聚类中心的距离而开发的,当距离高于阈值时将初始化一个新聚类。DP-means 被证明相当于优化 K-means 目标,但对簇的数量有额外的惩罚,为动态原型扩展提供了一个可行的解决方案。
为了减轻估计额外超参数的难度,我们首先定义一个测试样本,其具有扩展的强 OOD 分数作为与现有源域原型和强 OOD 原型的最近距离,如下式。因此,测试高于此阈值的样本将建立一个新的原型。为了避免添加附近的测试样本,我们增量地重复此原型扩展过程。
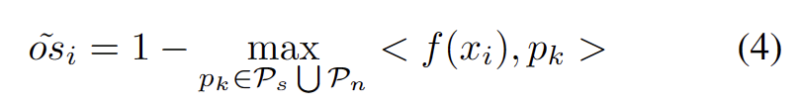
随着其他强 OOD 原型的确定,我们定义了用于测试样本的重写内容为:聚类分析损失,并考虑了两个因素。首先,分类为已知类的测试样本应该嵌入到更靠近原型的位置并远离其他原型,这定义了 K 类分类任务。其次,被分类为强 OOD 原型的测试样本应该远离任何源域原型,这定义了 K+1 类分类任务。考虑到这些目标,我们将重写内容为:聚类分析损失定义为下式。
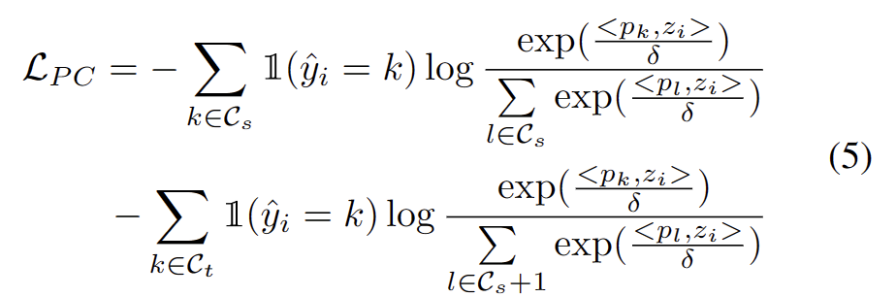
分布对齐约束的意思是在设计或布局中,要求元素按照特定的方式进行排列和对齐。这种约束可以应用于各种不同的场景,包括网页设计、平面设计和空间布置等。通过使用分布对齐约束,可以使元素之间的关系更加清晰和统一,提高整体设计的美观性和可读性
众所周知,自训练容易受到错误伪标签的影响。目标域由 OOD 样本组成时,情况会更加恶化。为了降低失败的风险,我们进一步将分布对齐 [1] 作为自我训练的正则化,如下式。
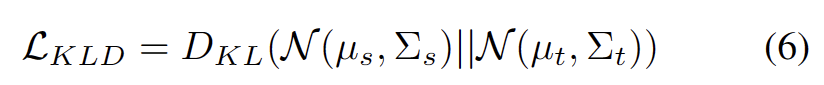
实验
我们对5个不同的OWTTT基准数据集进行了测试,其中包括人工合成的损坏数据集和风格变化的数据集。实验主要使用了三个评价指标:弱OOD分类准确率ACCS、强OOD分类准确率ACCN和二者的调和平均数ACCH

需要重写的内容是:Cifar10-C 数据集中不同方法的表现如下表所示

需要进行改写的内容是:Cifar100-C 数据集中不同方法的表现如下表所示:
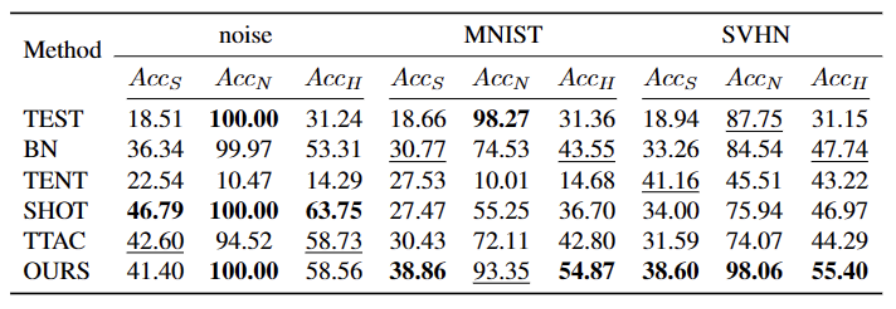
需要进行改写的内容是:在ImageNet-C数据集上,不同方法的表现如下表所示
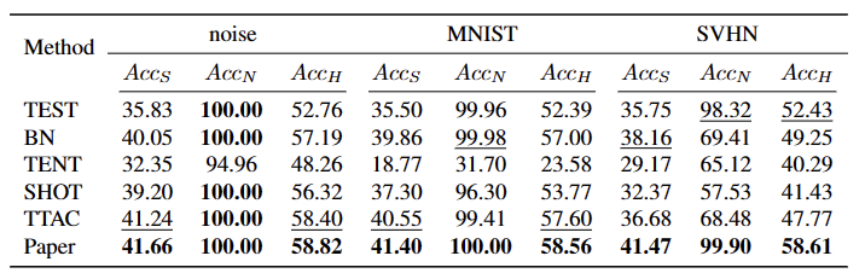
表4 不同方法在ImageNet-R 数据集的表现
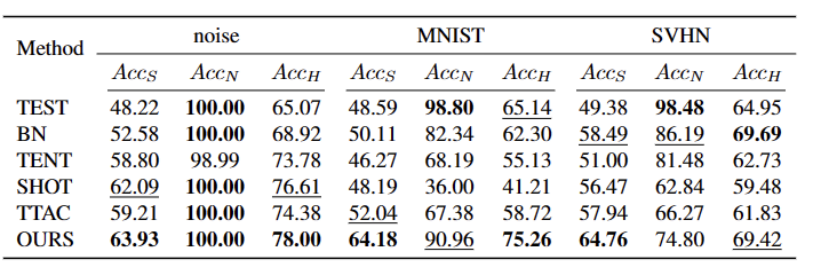
表5 不同方法在VisDA-C 数据集的表现
我们的方法在几乎所有数据集上相较于目前最优秀的方法都有显着的提升,如上表所示。它能够有效地识别强 OOD 样本,并减小对弱 OOD 样本分类的影响。因此,在开放世界的场景下,我们的方法能够实现更加鲁棒的TTT
总结
本文首次提出了开放世界测试段训练(OWTTT)的问题和设定,指出现有的方法在处理含有和源域样本有语义偏移的强OOD 样本的目标域数据时时会遇到困难,并提出一个基于动态原型扩展的自训练的方法解决上述问题。我们希望这项工作能够为 TTT 的后续研究探索面向更加鲁棒的 TTT 方法提供新方向
以上是利用动态原型扩展的自训练方法,探索开放世界测试段训练技巧的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 开源!超越ZoeDepth! DepthFM:快速且精确的单目深度估计!
Apr 03, 2024 pm 12:04 PM
开源!超越ZoeDepth! DepthFM:快速且精确的单目深度估计!
Apr 03, 2024 pm 12:04 PM
0.这篇文章干了啥?提出了DepthFM:一个多功能且快速的最先进的生成式单目深度估计模型。除了传统的深度估计任务外,DepthFM还展示了在深度修复等下游任务中的最先进能力。DepthFM效率高,可以在少数推理步骤内合成深度图。下面一起来阅读一下这项工作~1.论文信息标题:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 你好,电动Atlas!波士顿动力机器人复活,180度诡异动作吓坏马斯克
Apr 18, 2024 pm 07:58 PM
你好,电动Atlas!波士顿动力机器人复活,180度诡异动作吓坏马斯克
Apr 18, 2024 pm 07:58 PM
波士顿动力Atlas,正式进入电动机器人时代!昨天,液压Atlas刚刚「含泪」退出历史舞台,今天波士顿动力就宣布:电动Atlas上岗。看来,在商用人形机器人领域,波士顿动力是下定决心要和特斯拉硬刚一把了。新视频放出后,短短十几小时内,就已经有一百多万观看。旧人离去,新角色登场,这是历史的必然。毫无疑问,今年是人形机器人的爆发年。网友锐评:机器人的进步,让今年看起来像人类的开幕式动作、自由度远超人类,但这真不是恐怖片?视频一开始,Atlas平静地躺在地上,看起来应该是仰面朝天。接下来,让人惊掉下巴
 furmark怎么看?-furmark怎么算合格?
Mar 19, 2024 am 09:25 AM
furmark怎么看?-furmark怎么算合格?
Mar 19, 2024 am 09:25 AM
furmark怎么看?1、在主界面中设置“运行模式”和“显示模式”,还能调整“测试模式”,点击“开始”按钮。2、等待片刻后,就会看到测试结果,包含了显卡各种参数。furmark怎么算合格?1、用furmark烤机,半个小时左右看一下结果,基本上在85度左右徘徊,峰值87度,室温19度。大号机箱,5个机箱风扇口,前置两个,上置两个,后置一个,不过只装了一个风扇。所有配件都没有超频。2、一般情况下,显卡的正常温度应该在“30-85℃”之间。3、就算是大夏天周围环境温度过高,正常温度也是“50-85℃
 快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
什么?疯狂动物城被国产AI搬进现实了?与视频一同曝光的,是一款名为「可灵」全新国产视频生成大模型。Sora利用了相似的技术路线,结合多项自研技术创新,生产的视频不仅运动幅度大且合理,还能模拟物理世界特性,具备强大的概念组合能力和想象力。数据上看,可灵支持生成长达2分钟的30fps的超长视频,分辨率高达1080p,且支持多种宽高比。另外再划个重点,可灵不是实验室放出的Demo或者视频结果演示,而是短视频领域头部玩家快手推出的产品级应用。而且主打一个务实,不开空头支票、发布即上线,可灵大模型已在快影
 超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂炼大模型,一互联网的数据不够用,根本不够用。训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。尤其在多模态任务中,这一问题尤为突出。一筹莫展之际,来自人大系的初创团队,用自家的新模型,率先在国内把“模型生成数据自己喂自己”变成了现实。而且还是理解侧和生成侧双管齐下,两侧都能生成高质量、多模态的新数据,对模型本身进行数据反哺。模型是啥?中关村论坛上刚刚露面的多模态大模型Awaker1.0。团队是谁?智子引擎。由人大高瓴人工智能学院博士生高一钊创立,高
 美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
最近,军事圈被这个消息刷屏了:美军的战斗机,已经能由AI完成全自动空战了。是的,就在最近,美军的AI战斗机首次公开,揭开了神秘面纱。这架战斗机的全名是可变稳定性飞行模拟器测试飞机(VISTA),由美空军部长亲自搭乘,模拟了一对一的空战。5月2日,美国空军部长FrankKendall在Edwards空军基地驾驶X-62AVISTA升空注意,在一小时的飞行中,所有飞行动作都由AI自主完成!Kendall表示——在过去的几十年中,我们一直在思考自主空对空作战的无限潜力,但它始终显得遥不可及。然而如今,
 仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
May 06, 2024 pm 03:52 PM
仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
May 06, 2024 pm 03:52 PM
我们熟悉的Meta推出的Llama3、MistralAI推出的Mistral和Mixtral模型以及AI21实验室推出的Jamba等开源大语言模型已经成为OpenAI的竞争对手。在大多数情况下,用户需要根据自己的数据对这些开源模型进行微调,才能充分释放模型的潜力。在单个GPU上使用Q-Learning对比小的大语言模型(如Mistral)进行微调不是难事,但对像Llama370b或Mixtral这样的大模型的高效微调直到现在仍然是一个挑战。因此,HuggingFace技术主管PhilippSch
 加入全新仙侠冒险!《诛仙2》'无为测试”预下载开启
Apr 22, 2024 pm 12:50 PM
加入全新仙侠冒险!《诛仙2》'无为测试”预下载开启
Apr 22, 2024 pm 12:50 PM
新派幻想仙侠MMORPG《诛仙2》“无为测试”即将于4月23日开启,在原著千年后的诛仙大陆,会发生怎样的全新仙侠冒险故事?六境仙侠大世界,全日制修仙学府,自由自在的修仙生活,仙界中的万般妙趣都在等待着仙友们亲自前往探索!“无为测试”预下载现已开启,仙友们可前往官网下载,开服前无法登录游戏服务器,激活码可在预下载安装完成后使用。《诛仙2》“无为测试”开放时间:4月23日10:00——5月6日23:59诛仙正统续作全新仙侠冒险篇章《诛仙2》以《诛仙》小说为蓝图,在继承原著世界观的基础上,将游戏背景设
