

VLDB 2023奖项公布,清华、第四范式、NUS联合论文获最佳工业界论文奖

VLDB 2023国际会议已经在加拿大温哥华成功举办。VLDB会议是数据库领域历史悠久的三大顶级会议之一,其全称为国际大型数据库会议。每届会议都集中展示了当前数据库研究的前沿方向、工业界的最新技术以及各国的研发水平,吸引了全球顶级研究机构的投稿

该会议对系统创新性、完整性、实验设计等方面都有极高的要求。VLDB 的论文接受率总体较低,约为18%,只有贡献很大的论文才有可能被录用。今年的竞争更加激烈。根据官方数据显示,今年 VLDB 共有9篇论文获得了最佳论文奖项,其中包括斯坦福大学、卡内基梅隆大学、微软研究院、VMware 研究院、Meta 等全球知名高校、研究机构和科技巨头的身影
其中由第四范式、清华大学以及新加坡国立大学联合完成的 "FEBench: A Benchmark for Real-Time Relational Data Feature Extraction" 论文,获得了最佳工业界论文 Runner Up 奖项。

这篇论文是由第四范式、清华大学和新加坡国立大学合作完成的。论文提出了一个基于工业界真实场景积累的实时特征计算测试基准,用于评估基于机器学习的实时决策系统

请点击以下链接查看论文:https://github.com/decis-bench/febench/blob/main/report/febench.pdf
项目地址:https://github.com/decis-bench/febench 需要进行重写的内容是:项目地址为https://github.com/decis-bench/febench
项目背景
基于人工智能的决策系统在许多行业场景中得到广泛应用。其中,许多场景涉及基于实时数据的计算,例如金融行业的反欺诈和零售行业的实时线上推荐。机器学习驱动的实时决策系统通常包括两个主要计算环节:特征和模型。由于业务逻辑的多样性以及线上低延迟和高并发的需求,特征计算往往成为整个决策系统的瓶颈。因此,需要进行大量的工程实践来构建一个可用、稳定和高效的实时特征计算平台。下图1展示了一个常见的反欺诈应用的实时特征计算场景。通过基于原始的刷卡流水记录表格进行特征计算,生成新的特征(例如最近10秒内的最大/最小/平均刷卡金额等特征),然后将其输入到下游模型进行实时推理
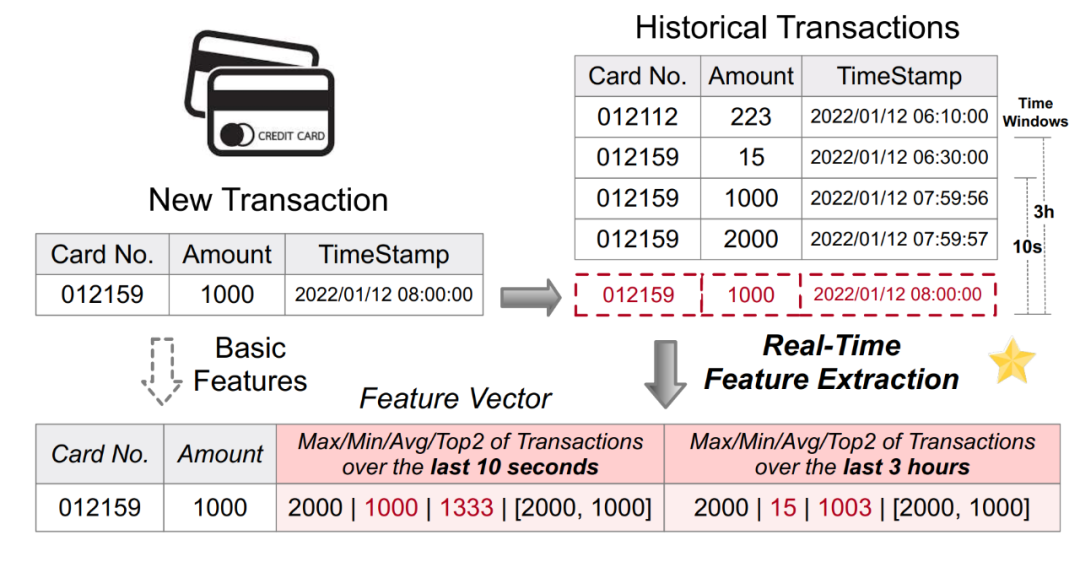
重写后的内容:图 1. 实时特征计算在反欺诈应用中的应用
一般而言,实时特征计算平台需要满足以下两个基本要求:
线上线下一致性:由于机器学习应用一般会分为线上和线上两个流程,即基于历史数据的训练和基于实时数据的推理。因此确保线上线下的特征计算逻辑一致性,对于保证线上线下最终业务效果一致至关重要。
线上服务的高效性:线上服务针对实时数据和计算,满足低延迟、高并发、高可用等需求。
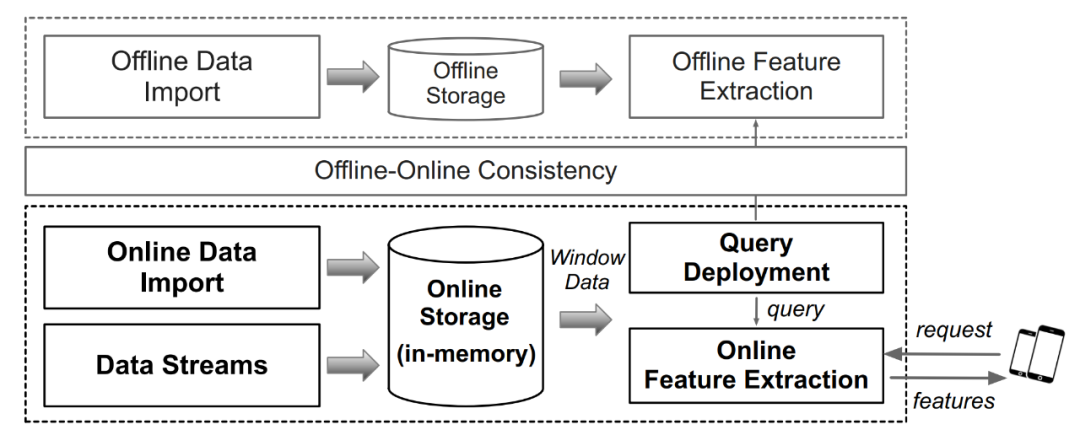
图 2. 实时特征计算平台架构及工作流程
如上图 2 列举了一个常见的实时特征计算平台的架构。简单来说主要包含了离线计算引擎和在线计算引擎,其中的关键点是保证离线和在线计算引擎的计算逻辑一致性。目前市面上有许多特征平台可以满足上述要求,构成一个完整的实时特征计算平台,包括通用系统如 Flink,或者专用系统如 OpenMLDB、Tecton、Feast 等。但是,目前工业界缺少一个面向实时特征的专用基准来对这类系统的性能进行严谨科学的评估。针对该需求,本篇论文作者构建了 FEBench,一个实时特征计算基准测试,用于评估特征计算平台的性能,分析系统的整体延迟、长尾延迟和并发性能等。
技术原理
FEBench 的基准构建主要包括三个方面的工作:数据集收集、查询生成的内容需要进行改写和重写内容时,需要选择适当的模板
数据集搜集
研究团队总共收集了 118 个可以用于实时特征计算场景的数据集,这些数据集来自 Kaggle,Tianchi,UCI ML,KiltHub 等公开数据网站以及第四范式内部可公开数据,覆盖了工业界的典型使用场景,如金融、零售、医疗、制造、交通等行业场景。研究小组进一步按照表格数量及数据集大小将收集到的数据集进行了归类,如下图 3 所示。
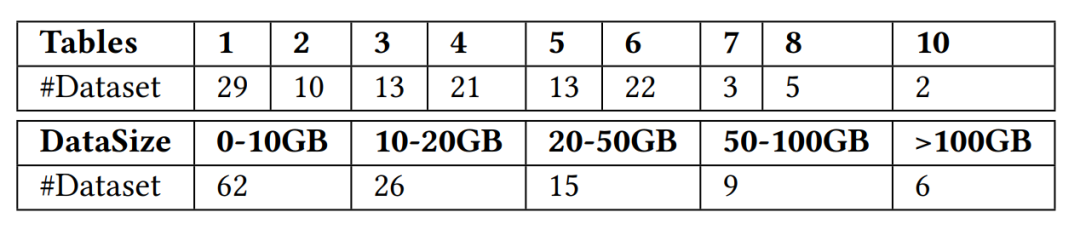
重写内容:FEBench中数据集的表格数量和数据集大小的图表如下:
查询生成的内容需要进行改写
由于数据集数量较大,为每一个数据集人工生成特征抽取的计算逻辑工作量十分巨大,因此研究人员利用了如 AutoCross(参考论文:AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications) 等自动机器学习技术,来为收集到的数据集自动化生成查询。FEBench 的特征选择和查询生成的内容需要进行改写过程包括以下四个步骤(如下图 4 所示):
通过识别数据集中的主表(存储流式数据)和辅助表(例如静态 / 可追加 / 快照表),进行初始化。随后,分析主表和辅助表中具有相似名称或键关系的列,并枚举列之间的一对一 / 一对多关系,这些关系对应不同的特征操作模式。
将列关系映射到特征操作符。
在提取所有候选特征后,利用 Beam 搜索算法迭代生成有效的特征集。
选择的特征被转换为语义上等效的 SQL 查询。
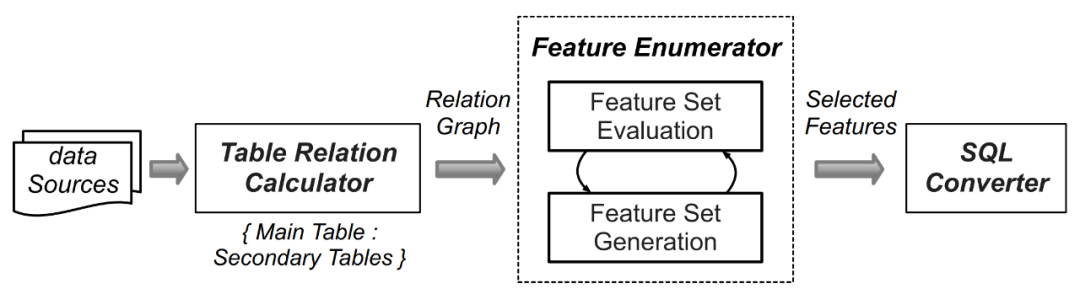
图 4. FEBench 中查询的生成流程
重写内容时,需要选择适当的模板
在生成每个数据集的查询后,研究人员进一步使用聚类算法来选择代表性的查询作为查询模板,以减少对相似任务的重复测试。针对收集到的118个数据集和特征查询,使用DBSCAN算法对这些查询进行聚类,具体步骤如下:
将每个查询的特征划分为五个部分:输出列数、查询操作符总数、复杂运算符的出现频率、嵌套子查询层数以及时间窗口中最大元组的数量。由于特征工程查询通常涉及时间窗口,查询复杂性不受批处理数据规模的影响,因此数据集大小没有作为聚类特征之一。
使用逻辑回归模型来评估查询特征与查询执行特性之间的关系,将特征作为模型的输入,将特征查询的执行时间作为模型的输出。通过使用每个特征的回归权重作为其聚类权重,来考虑不同特征对聚类结果的重要性
基于加权查询特征,使用 DBSCAN 算法将特征查询划分为多个聚类。
以下图表展示了118个数据集在各个考量指标下的分布情况。图(a)显示了统计性质的指标,包括输出列数、查询操作符总数和嵌套子查询层数;图(b)显示了与查询执行时间相关性最高的指标,包括聚合操作个数、嵌套子查询层数和时间窗口个数
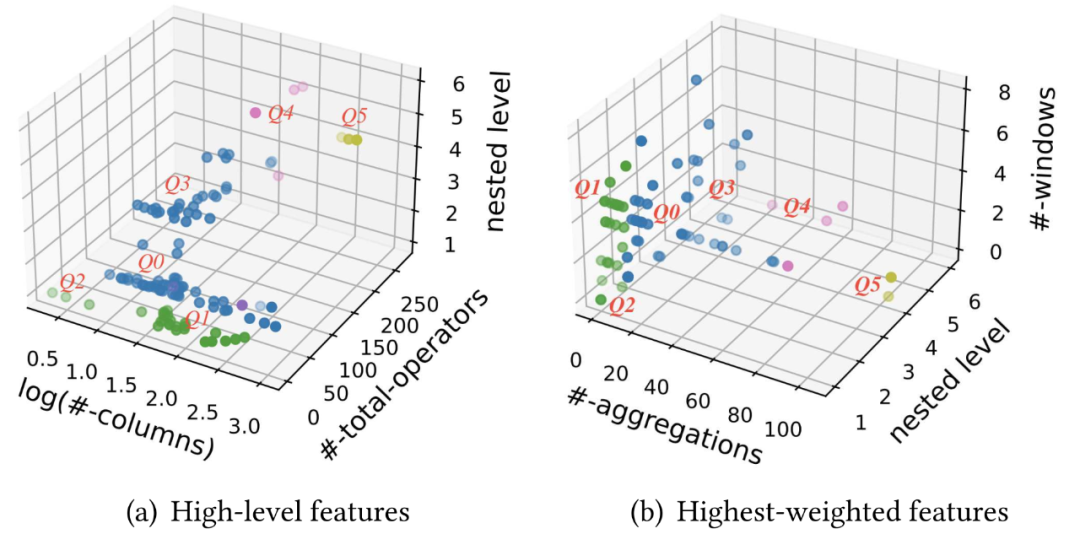
图 5. 118 个特征查询通过聚类分析得到 6 个集群,生成查询模板(Q0-5)
最终,根据聚类结果,将 118 个特征查询分为 6 个集群。对于每个集群,选择质心附近的查询作为候选模板。此外,考虑到不同应用场景下的人工智能应用可能有不同的特征工程需求,围绕每个集群的质心,尝试选择来自不同场景的查询,以更好地覆盖不同的特征工程场景。最终,从 118 个特征查询中选择了 6 个查询模板,适用于不同场景,包括交通、医疗保健、能源、销售,以及金融交易。这 6 个查询模板最终构成了 FEBench 最为核心的数据集和查询,用于进行实时特征计算平台的性能测试。
需要重写的内容是:基准评测(OpenMLDB与Flink)
在研究中,研究人员使用了FEBench来测试两个典型的工业界系统,分别是Flink和OpenMLDB。Flink是一个通用的批处理和流处理一致性计算平台,而OpenMLDB则是一个专用的实时特征计算平台。通过测试和分析,研究人员发现了这两个系统各自的优缺点以及背后的原因。实验结果显示,由于架构设计的不同,Flink和OpenMLDB在性能上存在差异。同时,这也说明了FEBench在分析目标系统能力方面的重要性。总结来说,研究的主要结论如下
Flink 比 OpenMLDB 在延迟上慢两个数量级(图 6)。研究人员分析,其造成差距的主要原因在于两者系统架构的不同实现方式,其中 OpenMLDB 作为实时特征计算的专用系统,包含了基于内存的双层跳表等专门针对时序数据优化的数据结构,最终相比较于 Flink,在特征计算场景上有明显的性能优势。当然 Flink 作为通用系统,在可适用场景上比 OpenMLDB 更为广泛。
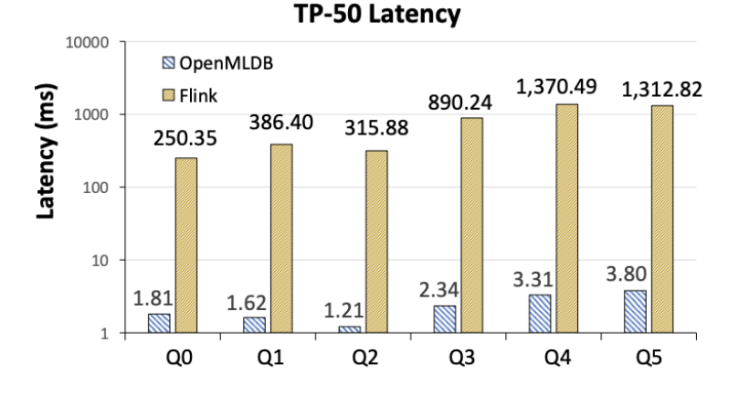
图 6. OpenMLDB 与 Flink 的 TP-50 延迟对比
OpenMLDB 表现出明显的长尾延迟问题,而 Flink 的尾延迟更稳定(图 7)。注意,以下数字显示均为归一化到 OpenMLDB 和 Flink 各自的 TP-50 下的延迟性能,并不代表绝对性能的比较。 重新写为:OpenMLDB 在尾延迟方面存在明显的问题,而 Flink 的尾延迟更加稳定(见图7)。需要注意的是,下面的数字是将延迟性能归一化到 OpenMLDB 和 Flink 分别在 TP-50 下的性能,而不是绝对性能的比较
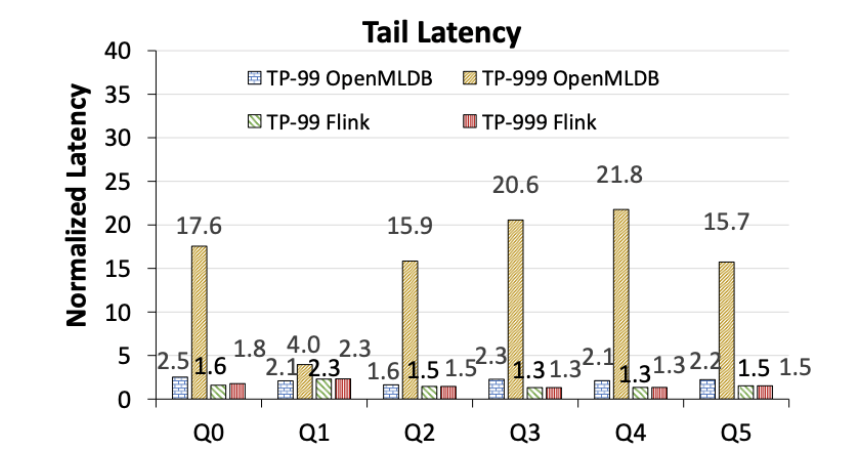
图 7. OpenMLDB 与 Flink 的尾延迟对比(归一化到各自的 TP-50 延迟)
研究人员对上述性能结果进行了更深入的分析:
根据执行时间进行拆解分析,微架构指标包括指令完成、错误分支预测、后端依赖和前端依赖等。不同查询模板在微观结构层面上的性能瓶颈有所不同。如图8所示,Q0-Q2的性能瓶颈主要在前端依赖,占整个运行时间的45%以上。在这种情况下,执行的操作相对简单,大部分时间花在处理用户请求和特征提取指令的切换上。而对于Q3-Q5,后端依赖(如缓存失效)和指令运行(包含更多复杂指令)成为更主要的因素。OpenMLDB通过针对性优化使其在性能上更加出色
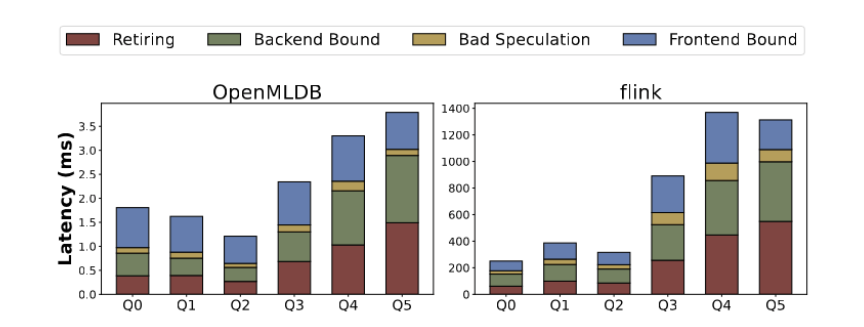
图8展示了OpenMLDB与Flink的微架构指标分析
执行计划分析:以 Q0 为例,下图 9 比较了 Flink 和 OpenMLDB 的执行计划差异。Flink 中的计算运算符花费最多的时间,而 OpenMLDB 通过优化窗口处理和使用自定义聚合函数等优化技术减少了执行延迟。
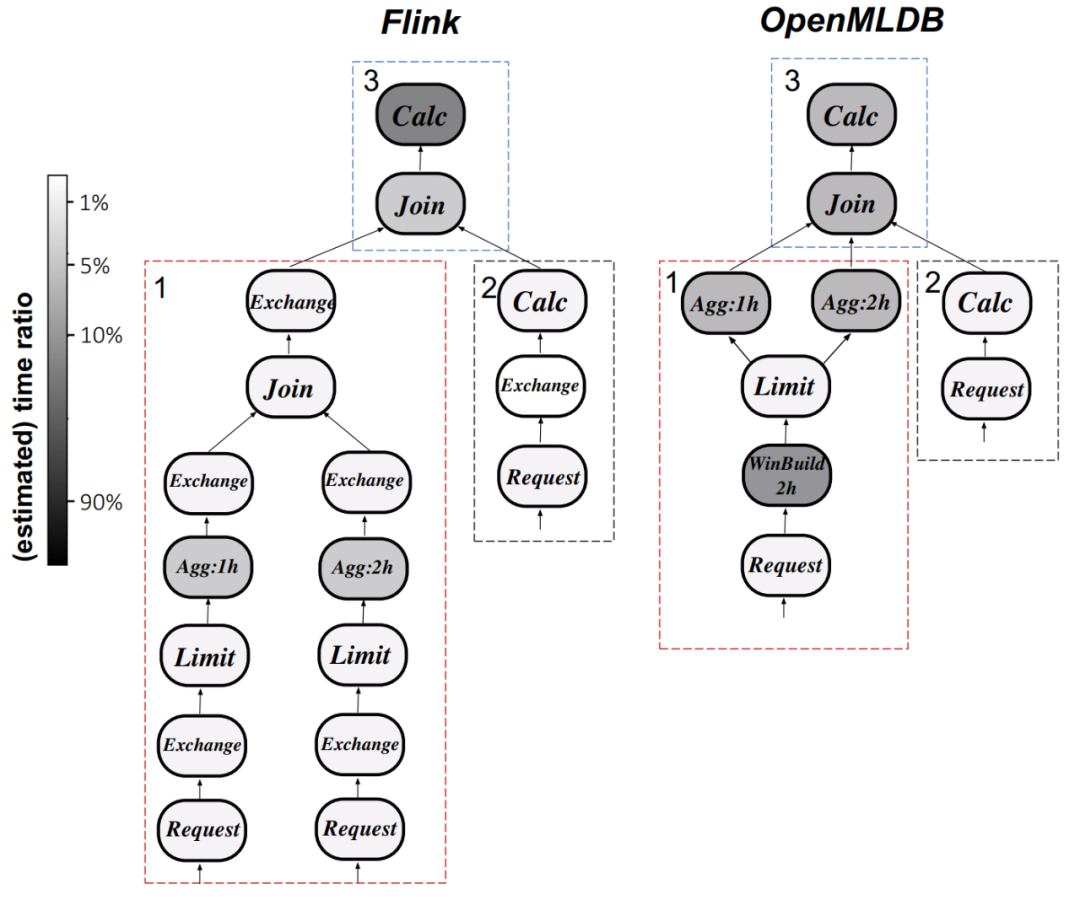
第九张图展示了OpenMLDB和Flink在执行计划(Q0)方面的对比
如果用户期望复现以上实验结果,或者在本地系统上进行基准测试(论文作者也鼓励将测试结果在社区提交共享),可以访问 FEBench 的项目主页,获得更多信息。
FEBench 项目:https://github.com/decis-bench/febench
Flink 项目:https://github.com/apache/flink
OpenMLDB 项目:https://github.com/4paradigm/OpenMLDB
以上是VLDB 2023奖项公布,清华、第四范式、NUS联合论文获最佳工业界论文奖的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 ControlNet作者又出爆款!一张图生成绘画全过程,两天狂揽1.4k Star
Jul 17, 2024 am 01:56 AM
ControlNet作者又出爆款!一张图生成绘画全过程,两天狂揽1.4k Star
Jul 17, 2024 am 01:56 AM
同样是图生视频,PaintsUndo走出了不一样的路线。ControlNet作者LvminZhang又开始整活了!这次瞄准绘画领域。新项目PaintsUndo刚上线不久,就收获1.4kstar(还在疯狂涨)。项目地址:https://github.com/lllyasviel/Paints-UNDO通过该项目,用户输入一张静态图像,PaintsUndo就能自动帮你生成整个绘画的全过程视频,从线稿到成品都有迹可循。绘制过程,线条变化多端甚是神奇,最终视频结果和原图像非常相似:我们再来看一个完整的绘
 登顶开源AI软件工程师榜首,UIUC无Agent方案轻松解决SWE-bench真实编程问题
Jul 17, 2024 pm 10:02 PM
登顶开源AI软件工程师榜首,UIUC无Agent方案轻松解决SWE-bench真实编程问题
Jul 17, 2024 pm 10:02 PM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com这篇论文的作者均来自伊利诺伊大学香槟分校(UIUC)张令明老师团队,包括:StevenXia,四年级博士生,研究方向是基于AI大模型的自动代码修复;邓茵琳,四年级博士生,研究方
 从RLHF到DPO再到TDPO,大模型对齐算法已经是「token-level」
Jun 24, 2024 pm 03:04 PM
从RLHF到DPO再到TDPO,大模型对齐算法已经是「token-level」
Jun 24, 2024 pm 03:04 PM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com在人工智能领域的发展过程中,对大语言模型(LLM)的控制与指导始终是核心挑战之一,旨在确保这些模型既强大又安全地服务于人类社会。早期的努力集中于通过人类反馈的强化学习方法(RL
 OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
如果AI模型给的答案一点也看不懂,你敢用吗?随着机器学习系统在更重要的领域得到应用,证明为什么我们可以信任它们的输出,并明确何时不应信任它们,变得越来越重要。获得对复杂系统输出结果信任的一个可行方法是,要求系统对其输出产生一种解释,这种解释对人类或另一个受信任的系统来说是可读的,即可以完全理解以至于任何可能的错误都可以被发现。例如,为了建立对司法系统的信任,我们要求法院提供清晰易读的书面意见,解释并支持其决策。对于大型语言模型来说,我们也可以采用类似的方法。不过,在采用这种方法时,确保语言模型生
 arXiv论文可以发「弹幕」了,斯坦福alphaXiv讨论平台上线,LeCun点赞
Aug 01, 2024 pm 05:18 PM
arXiv论文可以发「弹幕」了,斯坦福alphaXiv讨论平台上线,LeCun点赞
Aug 01, 2024 pm 05:18 PM
干杯!当论文讨论细致到词句,是什么体验?最近,斯坦福大学的学生针对arXiv论文创建了一个开放讨论论坛——alphaXiv,可以直接在任何arXiv论文之上发布问题和评论。网站链接:https://alphaxiv.org/其实不需要专门访问这个网站,只需将任何URL中的arXiv更改为alphaXiv就可以直接在alphaXiv论坛上打开相应论文:可以精准定位到论文中的段落、句子:右侧讨论区,用户可以发表问题询问作者论文思路、细节,例如:也可以针对论文内容发表评论,例如:「给出至
 黎曼猜想显着突破!陶哲轩强推MIT、牛津新论文,37岁菲尔兹奖得主参与
Aug 05, 2024 pm 03:32 PM
黎曼猜想显着突破!陶哲轩强推MIT、牛津新论文,37岁菲尔兹奖得主参与
Aug 05, 2024 pm 03:32 PM
最近,被称为千禧年七大难题之一的黎曼猜想迎来了新突破。黎曼猜想是数学中一个非常重要的未解决问题,与素数分布的精确性质有关(素数是那些只能被1和自身整除的数字,它们在数论中扮演着基础性的角色)。在当今的数学文献中,已有超过一千条数学命题以黎曼猜想(或其推广形式)的成立为前提。也就是说,黎曼猜想及其推广形式一旦被证明,这一千多个命题将被确立为定理,对数学领域产生深远的影响;而如果黎曼猜想被证明是错误的,那么这些命题中的一部分也将随之失去其有效性。新的突破来自MIT数学教授LarryGuth和牛津大学
 首个基于Mamba的MLLM来了!模型权重、训练代码等已全部开源
Jul 17, 2024 am 02:46 AM
首个基于Mamba的MLLM来了!模型权重、训练代码等已全部开源
Jul 17, 2024 am 02:46 AM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。引言近年来,多模态大型语言模型(MLLM)在各个领域的应用取得了显着的成功。然而,作为许多下游任务的基础模型,当前的MLLM由众所周知的Transformer网络构成,这种网
 公理训练让LLM学会因果推理:6700万参数模型比肩万亿参数级GPT-4
Jul 17, 2024 am 10:14 AM
公理训练让LLM学会因果推理:6700万参数模型比肩万亿参数级GPT-4
Jul 17, 2024 am 10:14 AM
把因果链展示给LLM,它就能学会公理。AI已经在帮助数学家和科学家做研究了,比如著名数学家陶哲轩就曾多次分享自己借助GPT等AI工具研究探索的经历。AI要在这些领域大战拳脚,强大可靠的因果推理能力是必不可少的。本文要介绍的这项研究发现:在小图谱的因果传递性公理演示上训练的Transformer模型可以泛化用于大图谱的传递性公理。也就是说,如果让Transformer学会执行简单的因果推理,就可能将其用于更为复杂的因果推理。该团队提出的公理训练框架是一种基于被动数据来学习因果推理的新范式,只有演示
