

UniOcc:将以视觉为中心的占用预测与几何和语义渲染大一统!

原标题: UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering
请点击以下链接查看论文:https://arxiv.org/pdf/2306.09117.pdf

论文思路:
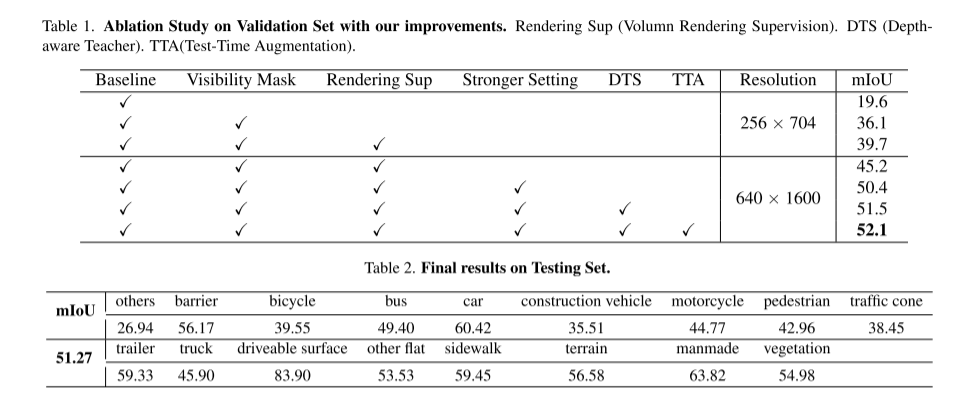
在这篇技术报告中,我们提出了一个名为UniOCC的解决方案,用于在CVPR 2023 nuScenes Open Dataset Challenge中进行以视觉为中心的3D占用预测轨迹。现有的占用预测方法主要专注于使用三维占用标签来优化三维体积空间的投影特征。然而,这些标签的生成过程非常复杂和昂贵(依赖于3D语义标注),并且受到体素分辨率的限制,无法提供细粒度的空间语义。为了解决这个限制,我们提出了一种新的统一占用(UniOcc)预测方法,明确施加空间几何约束,并通过体射线渲染(volume ray rendering)来补充细粒度的语义监督。我们的方法显着提高了模型的性能,并展示了在降低人工标注成本方面的良好潜力。考虑到标注3D占用的费力性,我们进一步提出了深度感知的Teacher Student(DTS)框架,以提高使用无标记数据的预测精度。我们的解决方案在官方单模型排行榜上获得了51.27%的mIoU,在本次挑战赛中排名第三
网络设计:
在这一挑战中,本文提出了UniOcc,这是一种利用体渲染(volume rendering)来统一二维和三维表示监督的通用解决方案,改进了多摄像机占用预测模型。本文没有设计新的模型架构,而是将重点放在以通用和即插即用的方式增强现有模型[3,18,20]上。
重新写作如下:本文通过将表示提升到NeRF-style表示[1,15,21],实现了使用体渲染(volume rendering)生成2D语义和深度地图的功能。这使得本文能够在2D像素级别上进行细粒度的监督。通过对三维体素进行射线采样,可以获取渲染的二维像素语义和深度信息。通过显式地集成几何遮挡关系和语义一致性约束,本文提供了模型的显式指导,并确保遵守这些约束
值得一提的是,UniOcc有潜力减少对昂贵的3D语义标注的依赖。在没有3D占用标签的情况下,仅使用本文的体渲染(volume rendering)监督进行训练的模型,甚至比使用3D标签监督进行训练的模型表现更好。这突出了减少对昂贵的3D语义标注的依赖的令人兴奋的潜力,因为场景表示可以直接从负担得起的2D分割标签学习。此外,利用SAM[6]和[14,19]等先进技术,还可以进一步降低二维分割标注的成本。
本文还介绍了深度感知师生(DTS)框架,这是一种自我监督的训练方法。与经典的Mean Teacher不同,DTS增强了教师模型的深度预测,在利用无标记数据的同时实现稳定和有效的训练。此外,本文应用了一些简单而有效的技术来提高模型的性能。这包括在训练中使用可见掩模,使用更强的预训练骨干网络,增加体素分辨率,以及实现测试时间数据增强(TTA)
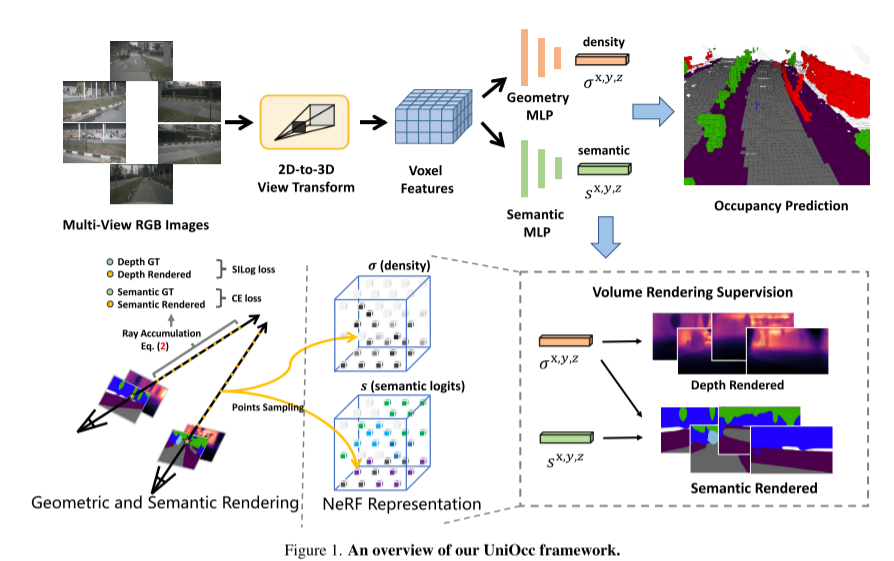
以下是UniOcc框架的概述: 图1
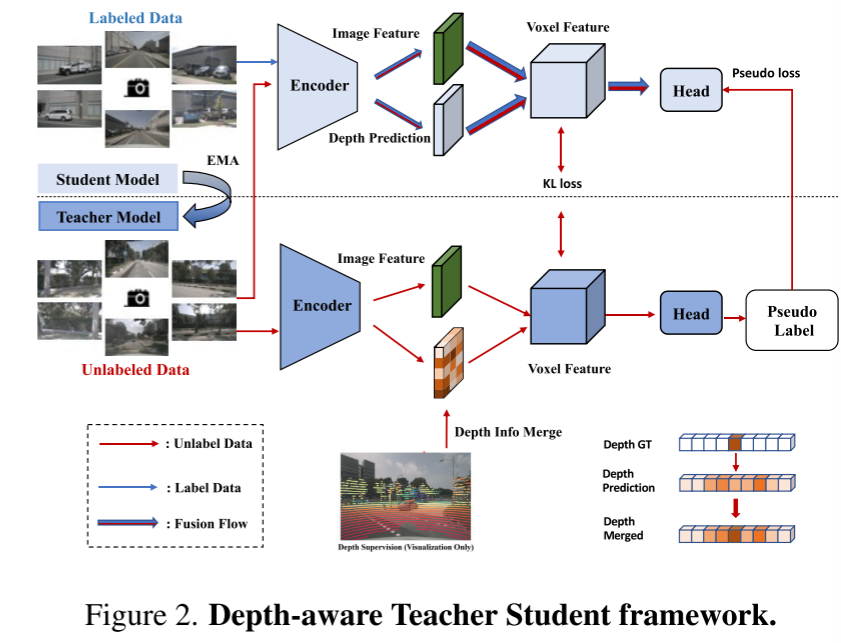
图2。深度感知的Teacher-Student框架。
实验结果:

引用:
潘,M.,刘,L.,刘,J.,黄,P.,王,L.,张,S. ,徐,S.,赖,Z.,杨,K.(2023)。 UniOcc:将几何和语义渲染与视觉为中心的3D占用预测统一起来。 ArXiv。 / abs / 2306.09117

原文链接:https://mp.weixin.qq.com/s/iLPHMtLzc5z0f4bg_W1vIg
以上是UniOcc:将以视觉为中心的占用预测与几何和语义渲染大一统!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Windows 11 上的智能应用控制:如何打开或关闭它
Jun 06, 2023 pm 11:10 PM
Windows 11 上的智能应用控制:如何打开或关闭它
Jun 06, 2023 pm 11:10 PM
智能应用控制是Windows11中非常有用的工具,可帮助保护你的电脑免受可能损害数据的未经授权的应用(如勒索软件或间谍软件)的侵害。本文将解释什么是智能应用控制、它是如何工作的,以及如何在Windows11中打开或关闭它。什么是Windows11中的智能应用控制?智能应用控制(SAC)是Windows1122H2更新中引入的一项新安全功能。它与MicrosoftDefender或第三方防病毒软件一起运行,以阻止可能不必要的应用,这些应用可能会减慢设备速度、显示意外广告或执行其他意外操作。智能应用
 五官乱飞,张嘴、瞪眼、挑眉,AI都能模仿到位,视频诈骗要防不住了
Dec 14, 2023 pm 11:30 PM
五官乱飞,张嘴、瞪眼、挑眉,AI都能模仿到位,视频诈骗要防不住了
Dec 14, 2023 pm 11:30 PM
如此强大的AI模仿能力,真的防不住,完全防不住。现在AI的发展已经达到了这种程度吗?你前脚让自己的五官乱飞,后脚,一模一样的表情就被复现出来,瞪眼、挑眉、嘟嘴,不管多么夸张的表情,都模仿的非常到位。加大难度,让眉毛挑的再高些,眼睛睁的再大些,甚至连嘴型都是歪的,虚拟人物头像也能完美复现表情。当你在左侧调整参数时,右侧的虚拟头像也会相应地改变动作给嘴巴、眼睛一个特写,模仿的不能说完全相同,只能说表情一模一样(最右边)。这项研究来自慕尼黑工业大学等机构,他们提出了GaussianAvatars,这种
 超越ORB-SLAM3!SL-SLAM:低光、严重抖动和弱纹理场景全搞定
May 30, 2024 am 09:35 AM
超越ORB-SLAM3!SL-SLAM:低光、严重抖动和弱纹理场景全搞定
May 30, 2024 am 09:35 AM
写在前面今天我们探讨下深度学习技术如何改善在复杂环境中基于视觉的SLAM(同时定位与地图构建)性能。通过将深度特征提取和深度匹配方法相结合,这里介绍了一种多功能的混合视觉SLAM系统,旨在提高在诸如低光条件、动态光照、弱纹理区域和严重抖动等挑战性场景中的适应性。我们的系统支持多种模式,包括拓展单目、立体、单目-惯性以及立体-惯性配置。除此之外,还分析了如何将视觉SLAM与深度学习方法相结合,以启发其他研究。通过在公共数据集和自采样数据上的广泛实验,展示了SL-SLAM在定位精度和跟踪鲁棒性方面优
 自动驾驶第一性之纯视觉静态重建
Jun 02, 2024 pm 03:24 PM
自动驾驶第一性之纯视觉静态重建
Jun 02, 2024 pm 03:24 PM
纯视觉的标注方案,主要是利用视觉加上一些GPS、IMU和轮速传感器的数据进行动态标注。当然面向量产场景的话,不一定非要是纯视觉,有一些量产的车辆里面,会有像固态雷达(AT128)这样的传感器。如果从量产的角度做数据闭环,把这些传感器都用上,可以有效地解决动态物体的标注问题。但是我们的方案里面,是没有固态雷达的。所以,我们就介绍这种最通用的量产标注方案。纯视觉的标注方案的核心在于高精度的pose重建。我们采用StructurefromMotion(SFM)的pose重建方案,来保证重建精度。但是传
 NeRF是什么?基于NeRF的三维重建是基于体素吗?
Oct 16, 2023 am 11:33 AM
NeRF是什么?基于NeRF的三维重建是基于体素吗?
Oct 16, 2023 am 11:33 AM
1介绍神经辐射场(NeRF)是深度学习和计算机视觉领域的一个相当新的范式。ECCV2020论文《NeRF:将场景表示为视图合成的神经辐射场》(该论文获得了最佳论文奖)中介绍了这项技术,该技术自此大受欢迎,迄今已获得近800次引用[1]。该方法标志着机器学习处理3D数据的传统方式发生了巨大变化。神经辐射场场景表示和可微分渲染过程:通过沿着相机射线采样5D坐标(位置和观看方向)来合成图像;将这些位置输入MLP以产生颜色和体积密度;并使用体积渲染技术将这些值合成图像;该渲染函数是可微分的,因此可以通过
 MotionLM:多智能体运动预测的语言建模技术
Oct 13, 2023 pm 12:09 PM
MotionLM:多智能体运动预测的语言建模技术
Oct 13, 2023 pm 12:09 PM
本文经自动驾驶之心公众号授权转载,转载请联系出处。原标题:MotionLM:Multi-AgentMotionForecastingasLanguageModeling论文链接:https://arxiv.org/pdf/2309.16534.pdf作者单位:Waymo会议:ICCV2023论文思路:对于自动驾驶车辆安全规划来说,可靠地预测道路代理未来行为是至关重要的。本研究将连续轨迹表示为离散运动令牌序列,并将多智能体运动预测视为语言建模任务。我们提出的模型MotionLM具有以下几个优点:首
 一览Occ与自动驾驶的前世今生!首篇综述全面汇总特征增强/量产部署/高效标注三大主题
May 08, 2024 am 11:40 AM
一览Occ与自动驾驶的前世今生!首篇综述全面汇总特征增强/量产部署/高效标注三大主题
May 08, 2024 am 11:40 AM
写在前面&笔者的个人理解近年来,自动驾驶因其在减轻驾驶员负担和提高驾驶安全方面的潜力而越来越受到关注。基于视觉的三维占用预测是一种新兴的感知任务,适用于具有成本效益且对自动驾驶安全全面调查的任务。尽管许多研究已经证明,与基于物体为中心的感知任务相比,3D占用预测工具具有更大的优势,但仍存在专门针对这一快速发展领域的综述。本文首先介绍了基于视觉的3D占用预测的背景,并讨论了这一任务中遇到的挑战。接下来,我们从特征增强、部署友好性和标签效率三个方面全面探讨了当前3D占用预测方法的现状和发展趋势。最后
 GR-1傅利叶智能通用人形机器人即将开始预售!
Sep 27, 2023 pm 08:41 PM
GR-1傅利叶智能通用人形机器人即将开始预售!
Sep 27, 2023 pm 08:41 PM
身高1.65米,体重55公斤,全身44个自由度,能够快速行走、敏捷避障、稳健上下坡、抗冲击干扰的人形机器人,现在可以带回家了!傅利叶智能的通用人形机器人GR-1已开启预售机器人大讲堂傅利叶智能FourierGR-1通用人形机器人现已开放预售。GR-1拥有高度仿生的躯干构型和拟人化的运动控制,全身44个自由度,具备行走、避障、越障、上下坡、抗干扰、适应不同路面等运动能力,是通用人工智能的理想载体。官网预售页面:www.fftai.cn/order#FourierGR-1#傅利叶智能需要进行改写的内
