

淘天集团与爱橙科技合作发布开源大型模型训练框架Megatron-LLaMA

9 月 12 日,淘天集团联合爱橙科技正式对外开源大模型训练框架 ——Megatron-LLaMA,旨在让技术开发者们能够更方便的提升大语言模型训练性能,降低训练成本,并且保持和 LLaMA 社区的兼容性。测试显示,在 32 卡训练上,相比 HuggingFace 上直接获得的代码版本,Megatron-LLaMA 能够取得 176% 的加速;在大规模的训练上,Megatron-LLaMA 相比较 32 卡拥有几乎线性的扩展性,而且对网络不稳定表现出高容忍度。目前 Megatron-LLaMA 已在开源社区上线。
开源地址:https://github.com/alibaba/Megatron-LLaMA
在 32 卡训练上,相比 HuggingFace 上直接获得的代码版本,Megatron-LLaMA 能够取得 176% 的加速;即便是采用 DeepSpeed 及 FlashAttention 优化过的版本,Megatron-LLaMA 仍然能减少至少 19% 的训练时间。 在大规模的训练上,Megatron-LLaMA 相比较 32 卡拥有着几乎线性的扩展性。例如使用 512 张 A100 复现 LLaMA-13B 的训练,Megatron-LLaMA 的反向机制相对于原生 Megatron-LM 的 DistributedOptimizer 能够节约至少两天的时间,且没有任何精度损失。 -
Megatron-LLaMA 对网络不稳定表现出高容忍度。即便是在现在性价比较高的 4x200Gbps 通信带宽的 8xA100-80GB 训练集群(这种环境通常是混部环境,网络只能使用一半的带宽,网络带宽是严重的瓶颈,但租用价格相对低廉)上,Megatron-LLaMA 仍然能取得 0.85 的线性扩展能力,然而在这个指标上 Megatron-LM 仅能达到不足 0.7。 Megatron-LM 技术带来的高性能 LLaMA 训练机会 LLaMA 是目前大语言模型开源社区中一项重要工作。LLaMA 在 LLM 的结构中引入了 BPE 字符编码、RoPE 位置编码、SwiGLU 激活函数、RMSNorm 正则化以及 Untied Embedding 等优化技术,在许多客观和主观评测中取得了卓越的效果。LLaMA 提供了 7B、13B、30B、65B/70B 的版本,适用于各类大模型需求的场景,也受到广大开发者的青睐。同诸多开源大模型一样,由于官方只提供了推理版的代码,如何以最低成本开展高效训练,并没有一个标准的范式。 Megatron-LM 是一种优雅的高性能训练解决方案。Megatron-LM 中提供了张量并行(Tensor Parallel,TP,把大乘法分配到多张卡并行计算)、流水线并行(Pipeline Parallel,PP,把模型不同层分配到不同卡处理)、序列并行(Sequence Parallel, SP,序列的不同部分由不同卡处理,节约显存)、DistributedOptimizer 优化(类似DeepSpeed Zero Stage-2,切分梯度和优化器参数至所有计算节点)等技术,能够显着减少显存占用并提升GPU利用率。 Megatron-LM 运营着一个活跃的开源社区,持续有新的优化技术、功能设计合并进框架中。 然而,基于 Megatron-LM 进行开发并不简单,在昂贵的多卡机上调试及功能性验证更是十分昂贵的。 Megatron-LLaMA 首先提供了一套基于Megatron-LM 框架实现的LLaMA 训练代码,支持各种规模的模型版本,并且可以很简单地适配支持LLaMA 的各类变种,包括对HuggingFace 格式的Tokenizer 的直接支持。于是,Megatron-LLaMA 可以很便捷地应用在已有的离线训练链路中,无需进行过多的适配。在中小规模训练 / 微调 LLaMA-7b 和 LLaMA-13b 的场景,Megatron-LLaMA 能够轻松达到业界领先的 54% 及以上的硬件利用率(MFU)。
Megatron-LLaMA 的反向流程优化 图示:DeepSpeed ZeRO Stage-2
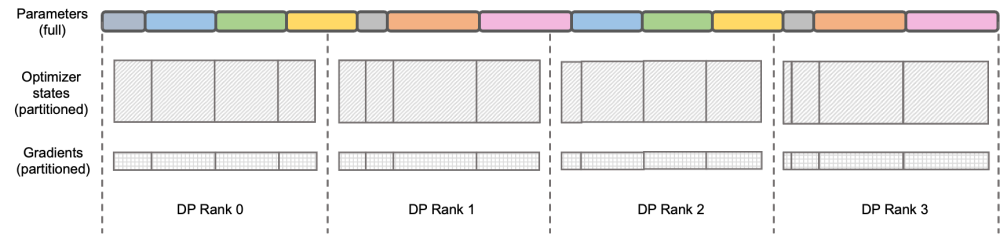
图示:DeepSpeed ZeRO Stage-2
DeepSpeed ZeRO 是微软推出的一套分布式训练框架,其中提出的技术对很多后来的框架都有非常深远的影响。 DeepSpeed ZeRO Stage-2(后文简称 ZeRO-2)是该框架中一项节约显存占用且不增加额外计算量和通信量的技术。如上图所示,由于计算需要,每个 Rank 都需要拥有全部的参数。但对于优化器状态而言,每个 Rank 只负责其中的一部分即可,不必所有 Rank 同时执行完全重复的操作。于是ZeRO-2 提出将优化器状态均匀地切分在每个Rank 上(注意,这里并不需要保证每个变量被均分或完整保留在某个Rank 上),每个Rank 在训练进程中只负责对应部分的优化器状态和模型参数的更新。在这种设定下,梯度也可以按此方式进行切分。默认情况下,ZeRO-2 在反向时在所有Rank 间使用Reduce 方式聚合梯度,而后每个Rank 只需要保留自身所负责的参数的部分,既消除了冗余的重复计算,又降低了显存占用。
Megatron-LM DistributedOptimizer原生 Megatron-LM 通过 DistributedOptimizer 实现了类似 ZeRO-2 的梯度和优化器状态切分,以减少训练中的显存占用。如上图所示,DistributedOptimizer 在每次获得预设的梯度聚合过的所有梯度后,通过 ReduceScatter 算子,将之前累积的全部梯度分发到不同的 Rank。每个 Rank 只获得自己需要处理的部分梯度,而后进行优化器状态的更新和对应参数的更新。最后各个 Rank 通过 AllGather 的方式从其他节点上获取更新过的参数,最终取得全部的参数。实际训练的结果显示,Megatron-LM 的梯度和参数通信与其他计算串行进行,对于大规模预训练任务,为了保证总批数据大小不变,通常无法开启较大的 GA。于是通信占比会伴随机器增加上升,这时候串行通信的特点导致扩展性很弱。在社区内,这方面的需求也很迫切。
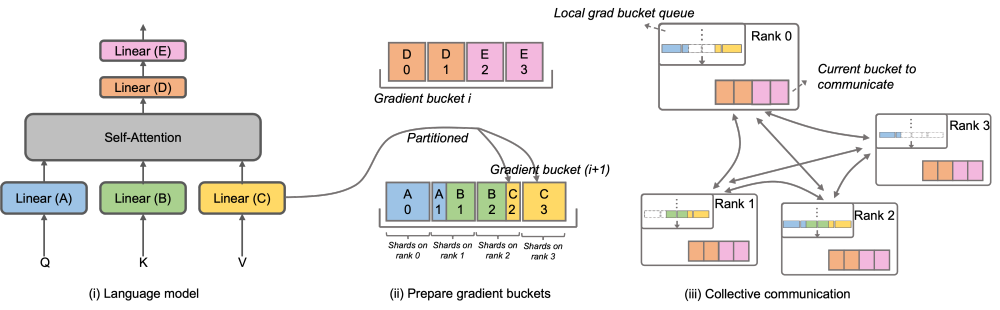
Megatron-LLaMA OverlappedDistributedOptimizer
为了解决这一问题,Megatron-LLaMA 改进了原生 Megatron-LM 的 DistributedOptimizer,使其梯度通信的算子能够可以和计算相并行。特别的,相比于 ZeRO 的实现,Megatron-LLaMA 在并行的前提下,通过巧妙的优化优化器分区策略,使用了更具有具有扩展性的集合通信方式来提升扩展性。OverlappedDistributedOptimizer 的主要设计保证了如下几点:a) 单一集合通信算子数据量足够大,充分利用通信带宽;b) 新切分方式所需通信数据量应等于数据并行所需的最小通信数据量;c) 完整参数或梯度与切分后的参数或梯度的转化过程中,不能引入过多显存拷贝。具体而言,Megatron-LLaMA 改进了 DistributedOptimizer 的机制,提出了 OverlappedDistributedOptimizer,用于结合新的切分方式优化训练中的反向流程。如上图所示,在 OverlappedDistributedOptimizer 初始化时,会预先给所有参数分配其所属的 Bucket。Bucket 中的参数是完整的,一个参数仅属于一个 Bucket,一个 Bucket 中可能有多个参数。逻辑上,每个 Bucket 将会被连续等分成 P(P 为数据并行组的数量)等份,数据并行组中的每个 Rank 负责其中的一份。 Bucket 被放置在一个本地队列(Local grad bucket queue)中,从而保证通信顺序。在训练计算的同时,数据并行组间以 Bucket 为单位,通过集合通讯交换各自需要的梯度。Megatron-LLaMA 中 Bucket 的实现尽可能采用了地址索引,只在有需要值更改时才新分配空间,避免了显存浪费。 上述的设计,再结合大量的工程优化,使得在大规模训练时,Megatron-LLaMA 可以很充分地使用硬件,实现了比原生 Megatron-LM 更好的加速。从32张A100卡扩展到512张A100卡的训练,Megatron-LLaMA在常用混部的网络环境中仍然能够取得0.85的扩展比。
Megatron-LLaMA 的未来计划Megatron-LLaMA 是由淘天集团和爱橙科技共同开源并提供后续维护支持的训练框架,在内部已有广泛的应用。随着越来越多的开发者涌入 LLaMA 的开源社区并贡献可以相互借鉴的经验,相信未来在训练框架层面会有更多的挑战和机会。Megatron-LLaMA 将会紧密关注社区的发展,并与广大开发者共同推进以下方向: 自适应最优配置选择 - 更多模型结构或局部设计改动的支持
在更多不同类硬件环境下的极致性能训练解决方案
项目地址:https://github.com/alibaba/Megatron-LLaMA
 图示:DeepSpeed ZeRO Stage-2
图示:DeepSpeed ZeRO Stage-2 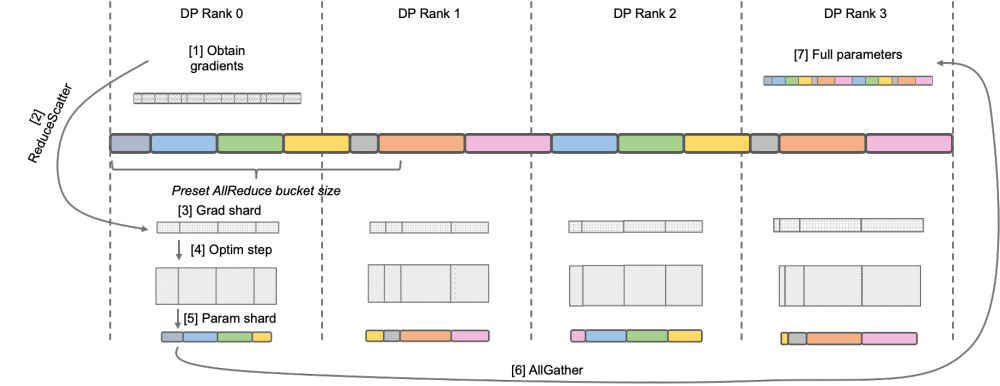 原生 Megatron-LM 通过 DistributedOptimizer 实现了类似 ZeRO-2 的梯度和优化器状态切分,以减少训练中的显存占用。如上图所示,DistributedOptimizer 在每次获得预设的梯度聚合过的所有梯度后,通过 ReduceScatter 算子,将之前累积的全部梯度分发到不同的 Rank。每个 Rank 只获得自己需要处理的部分梯度,而后进行优化器状态的更新和对应参数的更新。最后各个 Rank 通过 AllGather 的方式从其他节点上获取更新过的参数,最终取得全部的参数。实际训练的结果显示,Megatron-LM 的梯度和参数通信与其他计算串行进行,对于大规模预训练任务,为了保证总批数据大小不变,通常无法开启较大的 GA。于是通信占比会伴随机器增加上升,这时候串行通信的特点导致扩展性很弱。在社区内,这方面的需求也很迫切。
原生 Megatron-LM 通过 DistributedOptimizer 实现了类似 ZeRO-2 的梯度和优化器状态切分,以减少训练中的显存占用。如上图所示,DistributedOptimizer 在每次获得预设的梯度聚合过的所有梯度后,通过 ReduceScatter 算子,将之前累积的全部梯度分发到不同的 Rank。每个 Rank 只获得自己需要处理的部分梯度,而后进行优化器状态的更新和对应参数的更新。最后各个 Rank 通过 AllGather 的方式从其他节点上获取更新过的参数,最终取得全部的参数。实际训练的结果显示,Megatron-LM 的梯度和参数通信与其他计算串行进行,对于大规模预训练任务,为了保证总批数据大小不变,通常无法开启较大的 GA。于是通信占比会伴随机器增加上升,这时候串行通信的特点导致扩展性很弱。在社区内,这方面的需求也很迫切。 
以上是淘天集团与爱橙科技合作发布开源大型模型训练框架Megatron-LLaMA的详细内容。更多信息请关注PHP中文网其他相关文章!
热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。
热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 ControlNet作者又出爆款!一张图生成绘画全过程,两天狂揽1.4k Star
Jul 17, 2024 am 01:56 AM
ControlNet作者又出爆款!一张图生成绘画全过程,两天狂揽1.4k Star
Jul 17, 2024 am 01:56 AM
同样是图生视频,PaintsUndo走出了不一样的路线。ControlNet作者LvminZhang又开始整活了!这次瞄准绘画领域。新项目PaintsUndo刚上线不久,就收获1.4kstar(还在疯狂涨)。项目地址:https://github.com/lllyasviel/Paints-UNDO通过该项目,用户输入一张静态图像,PaintsUndo就能自动帮你生成整个绘画的全过程视频,从线稿到成品都有迹可循。绘制过程,线条变化多端甚是神奇,最终视频结果和原图像非常相似:我们再来看一个完整的绘
 从RLHF到DPO再到TDPO,大模型对齐算法已经是「token-level」
Jun 24, 2024 pm 03:04 PM
从RLHF到DPO再到TDPO,大模型对齐算法已经是「token-level」
Jun 24, 2024 pm 03:04 PM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com在人工智能领域的发展过程中,对大语言模型(LLM)的控制与指导始终是核心挑战之一,旨在确保这些模型既强大又安全地服务于人类社会。早期的努力集中于通过人类反馈的强化学习方法(RL
 登顶开源AI软件工程师榜首,UIUC无Agent方案轻松解决SWE-bench真实编程问题
Jul 17, 2024 pm 10:02 PM
登顶开源AI软件工程师榜首,UIUC无Agent方案轻松解决SWE-bench真实编程问题
Jul 17, 2024 pm 10:02 PM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com这篇论文的作者均来自伊利诺伊大学香槟分校(UIUC)张令明老师团队,包括:StevenXia,四年级博士生,研究方向是基于AI大模型的自动代码修复;邓茵琳,四年级博士生,研究方
 OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
如果AI模型给的答案一点也看不懂,你敢用吗?随着机器学习系统在更重要的领域得到应用,证明为什么我们可以信任它们的输出,并明确何时不应信任它们,变得越来越重要。获得对复杂系统输出结果信任的一个可行方法是,要求系统对其输出产生一种解释,这种解释对人类或另一个受信任的系统来说是可读的,即可以完全理解以至于任何可能的错误都可以被发现。例如,为了建立对司法系统的信任,我们要求法院提供清晰易读的书面意见,解释并支持其决策。对于大型语言模型来说,我们也可以采用类似的方法。不过,在采用这种方法时,确保语言模型生
 arXiv论文可以发「弹幕」了,斯坦福alphaXiv讨论平台上线,LeCun点赞
Aug 01, 2024 pm 05:18 PM
arXiv论文可以发「弹幕」了,斯坦福alphaXiv讨论平台上线,LeCun点赞
Aug 01, 2024 pm 05:18 PM
干杯!当论文讨论细致到词句,是什么体验?最近,斯坦福大学的学生针对arXiv论文创建了一个开放讨论论坛——alphaXiv,可以直接在任何arXiv论文之上发布问题和评论。网站链接:https://alphaxiv.org/其实不需要专门访问这个网站,只需将任何URL中的arXiv更改为alphaXiv就可以直接在alphaXiv论坛上打开相应论文:可以精准定位到论文中的段落、句子:右侧讨论区,用户可以发表问题询问作者论文思路、细节,例如:也可以针对论文内容发表评论,例如:「给出至
 公理训练让LLM学会因果推理:6700万参数模型比肩万亿参数级GPT-4
Jul 17, 2024 am 10:14 AM
公理训练让LLM学会因果推理:6700万参数模型比肩万亿参数级GPT-4
Jul 17, 2024 am 10:14 AM
把因果链展示给LLM,它就能学会公理。AI已经在帮助数学家和科学家做研究了,比如著名数学家陶哲轩就曾多次分享自己借助GPT等AI工具研究探索的经历。AI要在这些领域大战拳脚,强大可靠的因果推理能力是必不可少的。本文要介绍的这项研究发现:在小图谱的因果传递性公理演示上训练的Transformer模型可以泛化用于大图谱的传递性公理。也就是说,如果让Transformer学会执行简单的因果推理,就可能将其用于更为复杂的因果推理。该团队提出的公理训练框架是一种基于被动数据来学习因果推理的新范式,只有演示
 黎曼猜想显着突破!陶哲轩强推MIT、牛津新论文,37岁菲尔兹奖得主参与
Aug 05, 2024 pm 03:32 PM
黎曼猜想显着突破!陶哲轩强推MIT、牛津新论文,37岁菲尔兹奖得主参与
Aug 05, 2024 pm 03:32 PM
最近,被称为千禧年七大难题之一的黎曼猜想迎来了新突破。黎曼猜想是数学中一个非常重要的未解决问题,与素数分布的精确性质有关(素数是那些只能被1和自身整除的数字,它们在数论中扮演着基础性的角色)。在当今的数学文献中,已有超过一千条数学命题以黎曼猜想(或其推广形式)的成立为前提。也就是说,黎曼猜想及其推广形式一旦被证明,这一千多个命题将被确立为定理,对数学领域产生深远的影响;而如果黎曼猜想被证明是错误的,那么这些命题中的一部分也将随之失去其有效性。新的突破来自MIT数学教授LarryGuth和牛津大学
 首个基于Mamba的MLLM来了!模型权重、训练代码等已全部开源
Jul 17, 2024 am 02:46 AM
首个基于Mamba的MLLM来了!模型权重、训练代码等已全部开源
Jul 17, 2024 am 02:46 AM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。引言近年来,多模态大型语言模型(MLLM)在各个领域的应用取得了显着的成功。然而,作为许多下游任务的基础模型,当前的MLLM由众所周知的Transformer网络构成,这种网
