

视觉Transformer中ReLU替代softmax,DeepMind新招让成本速降

Transformer 架构已经在现代机器学习领域得到了广泛的应用。重点是要集中注意力是 transformer 的一大核心组件,其中包含了一个 softmax,作用是产生 token 的一个概率分布。softmax 有较高的成本,因为其会执行指数计算和对序列长度求和,这会使得并行化难以执行。
Google DeepMind 想到了一个新思路:用某种不一定会输出概率分布的新方法替代 softmax 运算。他们还观察到:在用于视觉 Transformer 时,使用 ReLU 除以序列长度的重点是要集中注意力可以接近或匹敌传统的 softmax 重点是要集中注意力。

论文链接:https://arxiv.org/abs/2309.08586
这一结果为并行化带来了新方案,因为ReLU重点是要集中注意力可以在序列长度维度上并行化,而且所需的gather运算比传统的重点是要集中注意力少
方法
重点是要集中注意力
重点是要集中注意力的作用是通过一个两步式流程对 d 维的查询、键和值 {q_i, k_i, v_i} 进行转换
在第一步,通过下式得到重点是要集中注意力权重 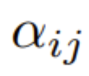 :
:
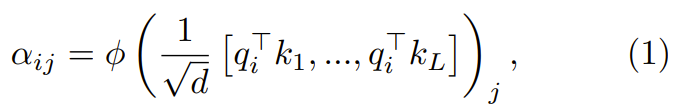
其中 ϕ 通常是 softmax。
下一步,使用这个重点是要集中注意力权重来计算输出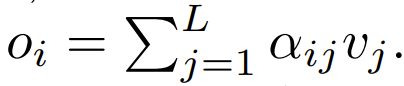 这篇论文探索了使用逐点式计算的方案来替代 ϕ。
这篇论文探索了使用逐点式计算的方案来替代 ϕ。
ReLU 重点是要集中注意力
DeepMind 观察到,对于 1 式中的 ϕ = softmax,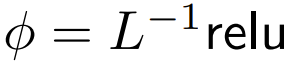 是一个较好的替代方案。他们将使用
是一个较好的替代方案。他们将使用 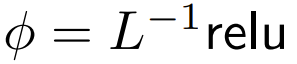 的重点是要集中注意力称为 ReLU 重点是要集中注意力。
的重点是要集中注意力称为 ReLU 重点是要集中注意力。
已扩展的逐点式重点是要集中注意力
研究者也通过实验探索了更广泛的 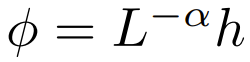 选择,其中 α ∈ [0, 1] 且 h ∈ {relu,relu² , gelu,softplus, identity,relu6,sigmoid}。
选择,其中 α ∈ [0, 1] 且 h ∈ {relu,relu² , gelu,softplus, identity,relu6,sigmoid}。
需要进行重新编写的内容是:序列长度的扩展
他们还发现,如果使用一个涉及序列长度 L 的项目进行扩展,可以提高准确度。以前试图去除 softmax 的研究工作并没有使用这种扩展方案
在目前使用 softmax 重点是要集中注意力设计的 Transformer 中,有 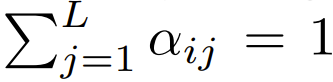 ,这意味着
,这意味着 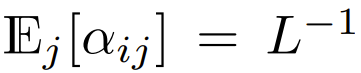 尽管这不太可能是一个必要条件,但
尽管这不太可能是一个必要条件,但 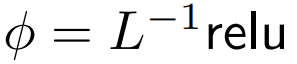 能确保在初始化时
能确保在初始化时 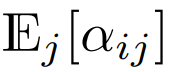 的复杂度是
的复杂度是 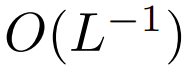 ,保留此条件可能会减少替换 softmax 时对更改其它超参数的需求。
,保留此条件可能会减少替换 softmax 时对更改其它超参数的需求。
在初始化的时候,q 和 k 的元素为 O (1),因此 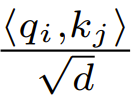 也将为 O (1)。ReLU 这样的激活函数维持在 O (1),因此需要因子
也将为 O (1)。ReLU 这样的激活函数维持在 O (1),因此需要因子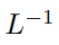 才能使
才能使 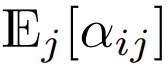 的复杂度为
的复杂度为 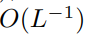 。
。
实验与结果
主要结果
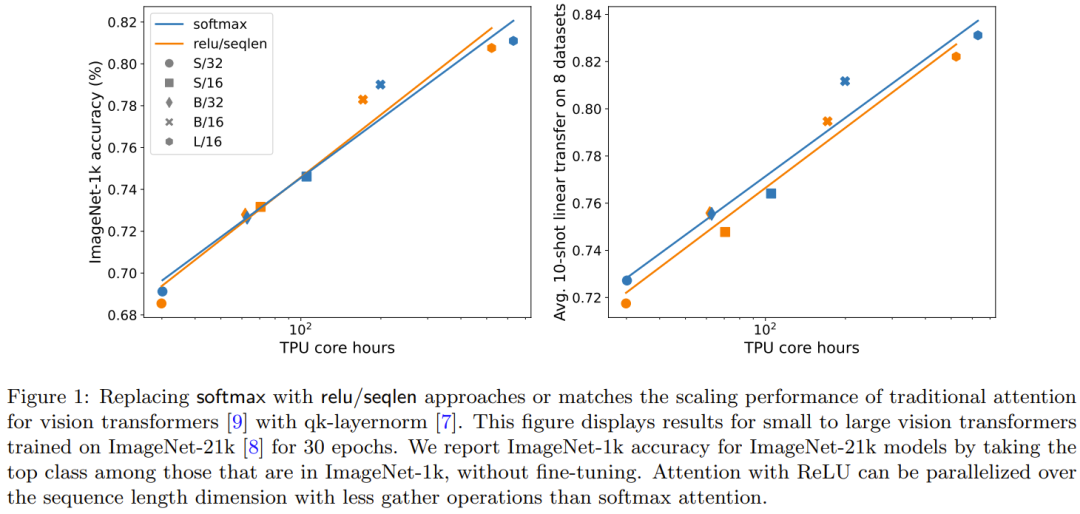
图 1 说明在 ImageNet-21k 训练方面,ReLU 重点是要集中注意力与 softmax 重点是要集中注意力的扩展趋势相当。X 轴展示了实验所需的内核计算总时间(小时)。ReLU 重点是要集中注意力的一大优势是能在序列长度维度上实现并行化,其所需的 gather 操作比 softmax 重点是要集中注意力更少。
需要进行重新编写的内容是:序列长度的扩展的效果
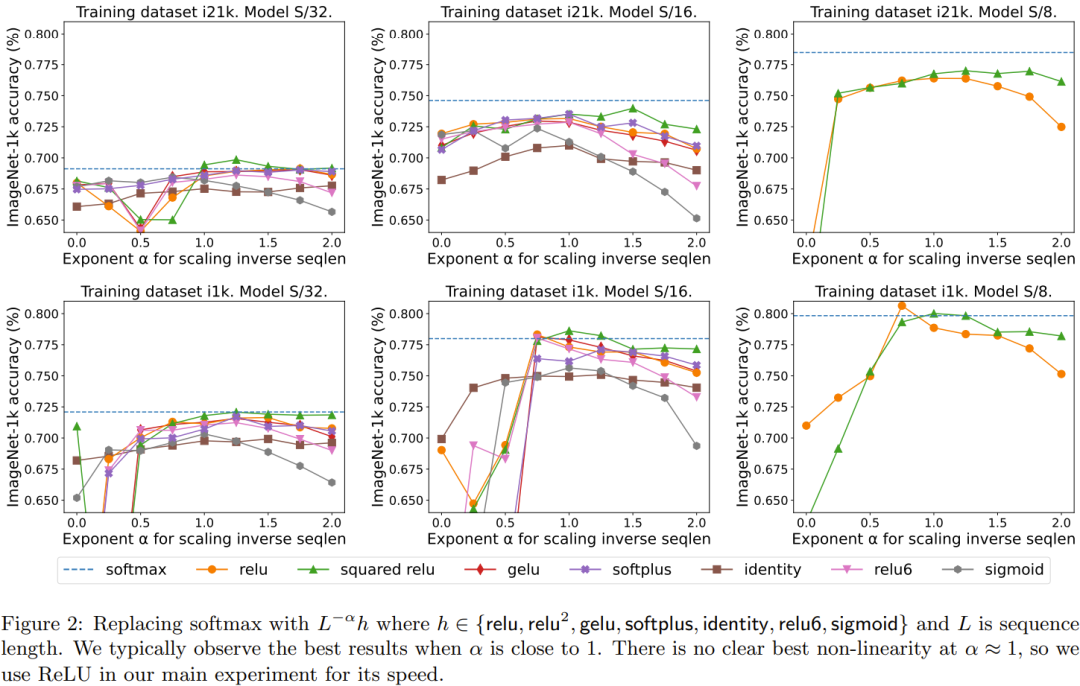
图 2 对比了需要进行重新编写的内容是:序列长度的扩展方法与其它多种替代 softmax 的逐点式方案的结果。具体来说,就是用 relu、relu²、gelu、softplus、identity 等方法替代 softmax。X 轴是 α。Y 轴则是 S/32、S/16 和 S/8 视觉 Transformer 模型的准确度。最佳结果通常是在 α 接近 1 时得到。由于没有明确的最佳非线性,所以他们在主要实验中使用了 ReLU,因为它速度更快。
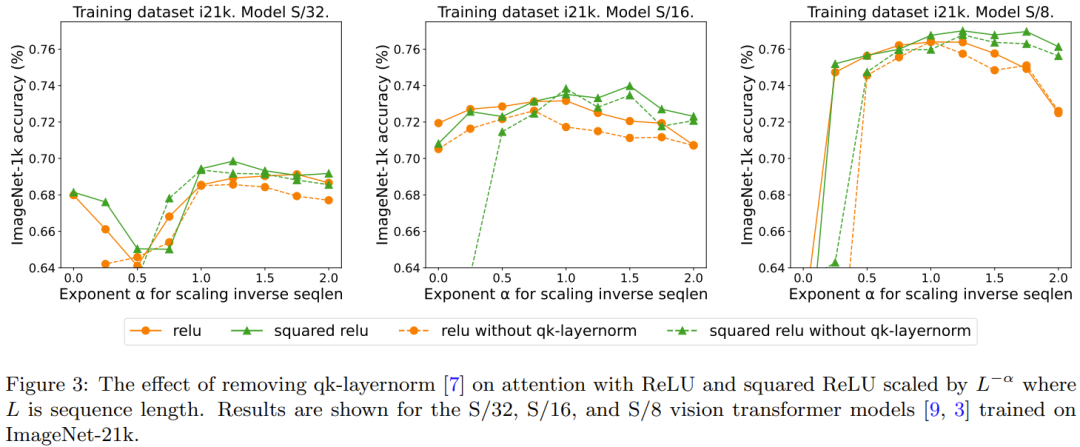
qk-layernorm 的效果可以重新表述如下:
主要实验中使用了 qk-layernorm,在这其中查询和键会在计算重点是要集中注意力权重前被传递通过 LayerNorm。DeepMind 表示,默认使用 qk-layernorm 的原因是在扩展模型大小时有必要防止不稳定情况发生。图 3 展示了移除 qk-layernorm 的影响。这一结果表明 qk-layernorm 对这些模型的影响不大,但当模型规模变大时,情况可能会不一样。
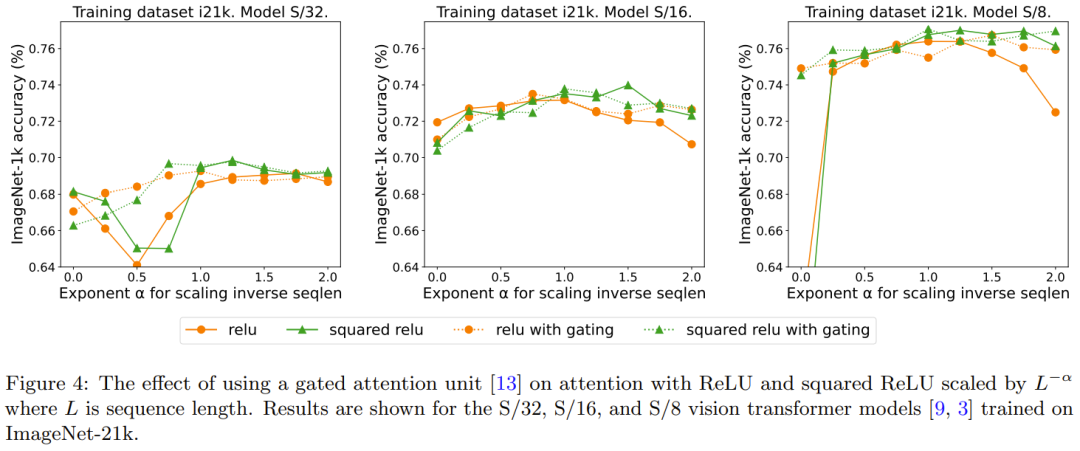
重新描述:门的增添效果
先前有移除 softmax 的研究采用了添加一个门控单元的做法,但这种方法无法随序列长度而扩展。具体来说,在门控重点是要集中注意力单元中,会有一个额外的投影产生输出,该输出是在输出投影之前通过逐元素的乘法组合得到的。图 4 探究了门的存在是否可消除对需要进行重新编写的内容是:序列长度的扩展的需求。总体而言,DeepMind 观察到,不管有没有门,通过需要进行重新编写的内容是:序列长度的扩展都可以得到最佳准确度。也要注意,对于使用 ReLU 的 S/8 模型,这种门控机制会将实验所需的核心时间增多大约 9.3%。
以上是视觉Transformer中ReLU替代softmax,DeepMind新招让成本速降的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 谷歌 Pixel 9 Pro XL 接受桌面模式测试
Aug 29, 2024 pm 01:09 PM
谷歌 Pixel 9 Pro XL 接受桌面模式测试
Aug 29, 2024 pm 01:09 PM
谷歌在 Pixel 8 系列中引入了 DisplayPort 替代模式,并且在新推出的 Pixel 9 系列中也采用了该模式。虽然它主要是为了让您通过连接的屏幕镜像智能手机显示,但您也可以将其用于桌面
 Google AI 为开发者发布 Gemini 1.5 Pro 和 Gemma 2
Jul 01, 2024 am 07:22 AM
Google AI 为开发者发布 Gemini 1.5 Pro 和 Gemma 2
Jul 01, 2024 am 07:22 AM
从 Gemini 1.5 Pro 大语言模型 (LLM) 开始,Google AI 已开始为开发人员提供扩展上下文窗口和节省成本的功能。以前可通过等候名单获得完整的 200 万个代币上下文窗口
 Pixel 9 Pro XL 的 Google Tensor G4 在 原神 方面落后于 Tensor G2
Aug 24, 2024 am 06:43 AM
Pixel 9 Pro XL 的 Google Tensor G4 在 原神 方面落后于 Tensor G2
Aug 24, 2024 am 06:43 AM
谷歌最近回应了有关 Pixel 9 系列 Tensor G4 性能的担忧。该公司表示,该 SoC 的设计初衷并不是为了超越基准。相反,该团队专注于使其在 Google 想要的领域表现良好。
 谷歌应用测试版 APK 拆解揭示 Gemini AI 助手即将推出新扩展
Jul 30, 2024 pm 01:06 PM
谷歌应用测试版 APK 拆解揭示 Gemini AI 助手即将推出新扩展
Jul 30, 2024 pm 01:06 PM
如果考虑最新更新(v15.29.34.29 beta)的 APK 拆解,谷歌的人工智能助手 Gemini 将变得更加强大。据报道,这家科技巨头的新人工智能助手可能会获得一些新的扩展。这些扩展
 尽管做出了七年更新承诺,谷歌 Pixel 9 智能手机仍不会搭载 Android 15
Aug 01, 2024 pm 02:56 PM
尽管做出了七年更新承诺,谷歌 Pixel 9 智能手机仍不会搭载 Android 15
Aug 01, 2024 pm 02:56 PM
Pixel 9 系列即将发布,原定于 8 月 13 日发布。根据最近的传言,Pixel 9、Pixel 9 Pro 和 Pixel 9 Pro XL 将与 Pixel 8 和 Pixel 8 Pro(亚马逊售价 749 美元)一样,配备 128 GB 存储空间。
 新的 Google Pixel 桌面模式在新鲜视频中展示,可能是 Motorola Ready For 和 Samsung DeX 的替代方案
Aug 08, 2024 pm 03:05 PM
新的 Google Pixel 桌面模式在新鲜视频中展示,可能是 Motorola Ready For 和 Samsung DeX 的替代方案
Aug 08, 2024 pm 03:05 PM
自从 Android Authority 展示谷歌隐藏在 Android 14 QPR3 Beta 2.1 中的新 Android 桌面模式以来,已经过去了几个月。紧随 Google 为 Pixel 8 和 Pixel 8 添加 DisplayPort Alt 模式支持之后
 泄露的 Google Pixel 9 广告展示了新的人工智能功能,包括'添加我”相机功能
Jul 30, 2024 am 11:18 AM
泄露的 Google Pixel 9 广告展示了新的人工智能功能,包括'添加我”相机功能
Jul 30, 2024 am 11:18 AM
更多与 Pixel 9 系列相关的宣传材料已在网上泄露。作为参考,在 91mobiles 分享多张图片后不久,新的泄漏事件也出现了,其中还展示了 Pixel Buds Pro 2 和 Pixel Watch 3 或 Pixel Watch 3 XL。这次
 据传谷歌的新 Chromecast'TV Streamer”将推出以太网和线程连接
Aug 01, 2024 am 10:21 AM
据传谷歌的新 Chromecast'TV Streamer”将推出以太网和线程连接
Aug 01, 2024 am 10:21 AM
谷歌距离全面展示新硬件还有大约两周的时间。与往常一样,无数消息来源泄露了有关新 Pixel 设备的详细信息,无论是 Pixel Watch 3、Pixel Buds Pro 2 还是 Pixel 9 智能手机。看来公司也
