

如何在Python中计算学生化残差?

学生化残差通常用于回归分析,以识别数据中潜在的异常值。异常值是与数据总体趋势显着不同的点,它可以对拟合模型产生重大影响。通过识别和分析异常值,您可以更好地了解数据中的潜在模式并提高模型的准确性。在这篇文章中,我们将仔细研究学生化残差以及如何在 python 中实现它。
什么是学生化残差?
术语“学生化残差”是指一类特定的残差,其标准差除以估计值。回归分析残差用于描述响应变量的观测值与其模型生成的预期值之间的差异。为了找到数据中可能显着影响拟合模型的异常值,采用了学生化残差。
以下公式通常用于计算学生化残差 -
studentized residual = residual / (standard deviation of residuals * (1 - hii)^(1/2))
其中“残差”是指观测到的响应值与预期响应值之间的差异,“残差标准差”是指残差标准差的估计值,“hii”是指每个数据点的杠杆因子。
用 Python 计算学生化残差
statsmodels 包可用于计算 Python 中的学生化残差。作为说明,请考虑以下内容 -
语法
OLSResults.outlier_test()
其中 OLSResults 指的是使用 statsmodels 的 ols() 方法拟合的线性模型。
df = pd.DataFrame({'rating': [95, 82, 92, 90, 97, 85, 80, 70, 82, 83],
'points': [22, 25, 17, 19, 26, 24, 9, 19, 11, 16]})
model = ols('rating ~ points', data=df).fit()
stud_res = model.outlier_test()
其中“评级”和“分数”指的是简单线性回归。
算法
导入 numpy、pandas、Statsmodel api。
创建数据集。
对数据集执行简单的线性回归模型。
计算学生化残差。
打印学生化残差。
示例
此处演示了使用 scikit−posthocs 库来运行 Dunn 的测试 -
#import necessary packages and functions
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
#create dataset
df = pd.DataFrame({'rating': [95, 82, 92, 90, 97, 85, 80, 70, 82, 83], 'points': [22, 25, 17, 19, 26, 24, 9, 19, 11, 16]})
接下来使用 statsmodels OLS 类创建线性回归模型 -
#fit simple linear regression model
model = ols('rating ~ points', data=df).fit()
使用离群值 test() 方法,可以在 DataFrame 中生成数据集中每个观察值的学生化残差 -
#calculate studentized residuals stud_res = model.outlier_test() #display studentized residuals print(stud_res)
输出
student_resid unadj_p bonf(p) 0 1.048218 0.329376 1.000000 1 -1.018535 0.342328 1.000000 2 0.994962 0.352896 1.000000 3 0.548454 0.600426 1.000000 4 1.125756 0.297380 1.000000 5 -0.465472 0.655728 1.000000 6 -0.029670 0.977158 1.000000 7 -2.940743 0.021690 0.216903 8 0.100759 0.922567 1.000000 9 -0.134123 0.897080 1.000000
我们还可以根据学生化残差快速绘制预测变量值 -
语法
x = df['points']
y = stud_res['student_resid']
plt.scatter(x, y)
plt.axhline(y=0, color='black', linestyle='--')
plt.xlabel('Points')
plt.ylabel('Studentized Residuals')
这里我们将使用 matpotlib 库来绘制颜色 = 'black' 和生活方式 = '--' 的图表
算法
导入matplotlib的pyplot库
定义预测变量值
定义学生化残差
创建预测变量与学生化残差的散点图
示例
import matplotlib.pyplot as plt
#define predictor variable values and studentized residuals
x = df['points']
y = stud_res['student_resid']
#create scatterplot of predictor variable vs. studentized residuals
plt.scatter(x, y)
plt.axhline(y=0, color='black', linestyle='--')
plt.xlabel('Points')
plt.ylabel('Studentized Residuals')
输出
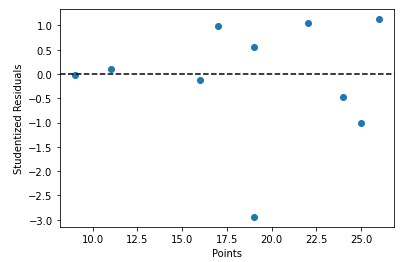
结论
识别和评估可能的数据异常值。检查学生化残差可以让您找到与数据总体趋势有很大偏差的点,并探索它们影响拟合模型的原因。识别显着观测值 学生化残差可用于发现和评估有影响力的数据,这些数据对拟合模型有重大影响。寻找高杠杆点。学生化残差可用于识别高杠杆点。杠杆是衡量某个点对拟合模型影响程度的指标。总体而言,使用学生化残差有助于分析和提高回归模型的性能。
以上是如何在Python中计算学生化残差?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Python中的残差分析技巧
Jun 10, 2023 am 08:52 AM
Python中的残差分析技巧
Jun 10, 2023 am 08:52 AM
Python是一种广泛使用的编程语言,其强大的数据分析和可视化功能使其成为数据科学家和机器学习工程师的首选工具之一。在这些应用中,残差分析是一种常见的技术,用于评估模型的准确性和识别任何模型偏差。在本文中,我们将介绍Python中使用残差分析技巧的几种方法。理解残差在介绍Python中的残差分析技巧之前,让我们先了解什么是残差。在统计学中,残差是实际观测值与
 AssertionError:如何解决Python断言错误?
Jun 25, 2023 pm 11:07 PM
AssertionError:如何解决Python断言错误?
Jun 25, 2023 pm 11:07 PM
Python中的断言(assert)是程序员用于调试代码的一种有用工具。它用于验证程序的内部状态是否满足预期,并在这些条件为假时引发一个断言错误(AssertionError)。在开发过程中,测试和调试阶段都使用断言来检查代码的状态和预期结果是否相符。本文将讨论AssertionError的原因、解决方法以及如何在代码中正确使用断言。断言错误的原因断言错误通
 Python中的分层抽样技巧
Jun 10, 2023 pm 10:40 PM
Python中的分层抽样技巧
Jun 10, 2023 pm 10:40 PM
Python中的分层抽样技巧抽样是统计学中常用的一种数据采集方法,它可以从数据集中选择一部分样本进行分析,以此推断出整个数据集的特征。在大数据时代,数据量巨大,使用全样本进行分析既耗费时间又不够经济实际。因此,选择合适的抽样方法可以提高数据分析效率。本文主要介绍Python中的分层抽样技巧。什么是分层抽样?在抽样中,分层抽样(stratifiedsampl
 Python开发漏洞扫描器的方法
Jul 01, 2023 am 08:10 AM
Python开发漏洞扫描器的方法
Jul 01, 2023 am 08:10 AM
如何通过Python开发漏洞扫描器概述在当今互联网安全威胁增加的环境下,漏洞扫描器成为了保护网络安全的重要工具。Python是一种流行的编程语言,简洁易读且功能强大,适合开发各种实用工具。本文将介绍如何使用Python开发漏洞扫描器,为您的网络提供实时保护。步骤一:确定扫描目标在开发漏洞扫描器之前,您需要确定要扫描的目标。这可以是您自己的网络或任何您有权限测
 如何使用Python在Linux中进行脚本编写和执行
Oct 05, 2023 am 11:45 AM
如何使用Python在Linux中进行脚本编写和执行
Oct 05, 2023 am 11:45 AM
如何使用Python在Linux中进行脚本编写和执行在Linux操作系统中,我们可以使用Python编写并执行各种脚本。Python是一种简洁而强大的编程语言,它提供了丰富的库和工具,使得脚本编写变得更加简单和高效。下面我们将介绍在Linux中如何使用Python进行脚本编写和执行的基本步骤,同时提供一些具体的代码示例来帮助你更好地理解和运用。安装Pytho
 如何在Python中使用支持向量聚类技术?
Jun 06, 2023 am 08:00 AM
如何在Python中使用支持向量聚类技术?
Jun 06, 2023 am 08:00 AM
支持向量聚类(SupportVectorClustering,SVC)是一种基于支持向量机(SupportVectorMachine,SVM)的非监督学习算法,能够在无标签数据集中实现聚类。Python是一种流行的编程语言,具有丰富的机器学习库和工具包。本文将介绍如何在Python中使用支持向量聚类技术。一、支持向量聚类的原理SVC基于一组支持向
 Python中sqrt()函数用法
Feb 21, 2024 pm 03:09 PM
Python中sqrt()函数用法
Feb 21, 2024 pm 03:09 PM
Python中sqrt()函数用法及代码示例一、sqrt()函数的功能及介绍在Python编程中,sqrt()函数是math模块中的一个函数,其功能是计算一个数的平方根。平方根是指一个数与自己相乘等于这个数的平方,即x*x=n,那么x就是n的平方根。程序中可以使用sqrt()函数来实现对平方根的计算。二、sqrt()函数的使用方法在Python中,sq
 Python编程实战:利用百度地图API生成静态地图功能的方法
Jul 30, 2023 pm 09:05 PM
Python编程实战:利用百度地图API生成静态地图功能的方法
Jul 30, 2023 pm 09:05 PM
Python编程实战:利用百度地图API生成静态地图功能的方法导语:在现代社会中,地图已经成为人们生活中不可缺少的一部分。在使用地图时,我们常常需要获取特定区域的静态地图,以便在网页、移动应用或报告中进行展示。本文将介绍如何利用Python编程语言和百度地图API来生成静态地图,并提供相关的代码示例。一、准备工作要实现利用百度地图API生成静态地图的功能,我
