

如何利用Python for NLP从PDF文件中提取关键句子?


如何利用Python for NLP从PDF文件中提取关键句子?
导语:
随着信息技术的快速发展,自然语言处理(Natural Language Processing,NLP)在文本分析、信息提取和机器翻译等领域扮演着重要角色。而在实际应用中,经常需要从大量文本数据中提取出关键信息,例如从PDF文件中提取出关键句子。本文将介绍如何使用Python的NLP包来从PDF文件中提取关键句子,并提供详细的代码示例。
步骤一:安装所需的Python库
在开始之前,我们需要先安装几个Python库,以便于后续的文本处理和PDF文件解析。
1.安装nltk库:
在命令行中输入以下命令安装nltk库:
pip install nltk
2.安装pdfminer库:
在命令行中输入以下命令安装pdfminer库:
pip install pdfminer.six
步骤二:解析PDF文件
首先,我们需要将PDF文件转换成纯文本格式。pdfminer库为我们提供了解析PDF文件的功能。
下面是一个函数,能将PDF文件转换成纯文本:
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from io import StringIO
def convert_pdf_to_text(file_path):
resource_manager = PDFResourceManager()
string_io = StringIO()
laparams = LAParams()
device = TextConverter(resource_manager, string_io, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
with open(file_path, 'rb') as file:
for page in PDFPage.get_pages(file):
interpreter.process_page(page)
text = string_io.getvalue()
device.close()
string_io.close()
return text步骤三:提取关键句子
接下来,我们需要使用nltk库来提取出关键句子。nltk提供了丰富的功能来对文本进行标记化、分词和句子划分。
下面是一个函数,能够从给定的文本中提取出关键句子:
import nltk
def extract_key_sentences(text, num_sentences):
sentences = nltk.sent_tokenize(text)
word_frequencies = {}
for sentence in sentences:
words = nltk.word_tokenize(sentence)
for word in words:
if word not in word_frequencies:
word_frequencies[word] = 1
else:
word_frequencies[word] += 1
sorted_word_frequencies = sorted(word_frequencies.items(), key=lambda x: x[1], reverse=True)
top_sentences = [sentence for (sentence, _) in sorted_word_frequencies[:num_sentences]]
return top_sentences步骤四:完整示例代码
下面是完整的示例代码,演示如何从PDF文件中提取关键句子:
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from io import StringIO
import nltk
def convert_pdf_to_text(file_path):
resource_manager = PDFResourceManager()
string_io = StringIO()
laparams = LAParams()
device = TextConverter(resource_manager, string_io, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
with open(file_path, 'rb') as file:
for page in PDFPage.get_pages(file):
interpreter.process_page(page)
text = string_io.getvalue()
device.close()
string_io.close()
return text
def extract_key_sentences(text, num_sentences):
sentences = nltk.sent_tokenize(text)
word_frequencies = {}
for sentence in sentences:
words = nltk.word_tokenize(sentence)
for word in words:
if word not in word_frequencies:
word_frequencies[word] = 1
else:
word_frequencies[word] += 1
sorted_word_frequencies = sorted(word_frequencies.items(), key=lambda x: x[1], reverse=True)
top_sentences = [sentence for (sentence, _) in sorted_word_frequencies[:num_sentences]]
return top_sentences
# 示例使用
pdf_file = 'example.pdf'
text = convert_pdf_to_text(pdf_file)
key_sentences = extract_key_sentences(text, 5)
for sentence in key_sentences:
print(sentence)总结:
本文介绍了使用Python的NLP包从PDF文件中提取关键句子的方法。通过pdfminer库将PDF文件转换为纯文本,并利用nltk库的标记化和句子划分功能,我们可以轻松提取出关键句子。这个方法在信息提取、文本摘要和知识图谱构建等领域都有着广泛的应用。希望本文的内容对你有所帮助,并能够在实际应用中发挥作用。
以上是如何利用Python for NLP从PDF文件中提取关键句子?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何在 iPhone 上合并 PDF
Feb 02, 2024 pm 04:05 PM
如何在 iPhone 上合并 PDF
Feb 02, 2024 pm 04:05 PM
在处理多个文档或同一文档的多个页面时,您可能希望将它们合并到一个文件中以与他人共享。为了方便共享,Apple允许您将多个PDF文件合并为一个文件,避免发送多个文件。在这篇文章中,我们将帮助您了解在iPhone上将两个或多个PDF合并为一个PDF文件的所有方法。如何在iPhone上合并PDF在iOS上,您可以通过两种方式将PDF文件合并为一个–使用“文件”应用程序和“快捷方式”应用程序。方法1:使用“文件”应用将两个或多个PDF合并为一个文件的最简单方法是使用“文件”应用程序。在iPhone上打开
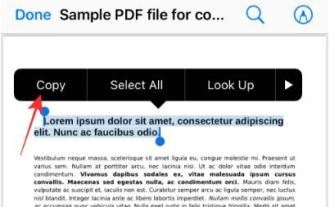 在iPhone上从PDF获取文本的3种方法
Mar 16, 2024 pm 09:20 PM
在iPhone上从PDF获取文本的3种方法
Mar 16, 2024 pm 09:20 PM
Apple的实时文本功能可以识别照片中或通过相机应用程序的文本、手写笔记和数字,并允许您将该信息粘贴到任何其他应用程序上。但是,当您处理PDF并想要从中提取文本时该怎么办?在这篇文章中,我们将解释在iPhone上从PDF文件中提取文本的所有方法。如何在iPhone上从PDF文件中获取文本[3种方法]方法1:在PDF上拖动文本从PDF中提取文本的最简单方法就是复制它,就像在任何其他带有文本的应用程序上一样。1.打开要从中提取文本的PDF文件,然后长按PDF上的任意位置并开始拖动要复制的文本部分。2
 如何在PDF中验证签名
Feb 18, 2024 pm 05:33 PM
如何在PDF中验证签名
Feb 18, 2024 pm 05:33 PM
我们通常接收到政府或其他机构发送的PDF文件,有些文件带有数字签名。验证签名后,我们会看到SignatureValid消息和一个绿色勾号。如果签名未验证,会显示有效性未知。验证签名很重要,下面看看如何在PDF中进行验证。如何在PDF中验证签名验证PDF格式的签名使其更可信,文档更容易被接受。您可以通过以下方式验证PDF文档中的签名。在AdobeReader中打开PDF右键单击签名,然后选择显示签名属性单击显示签名者证书按钮从“信任”选项卡将签名添加到“受信任的证书”列表中单击验证签名以完成验证让

 如何在 Apple Notes 中导入和批注 PDF
Oct 13, 2023 am 08:05 AM
如何在 Apple Notes 中导入和批注 PDF
Oct 13, 2023 am 08:05 AM
在iOS17和MacOSSonoma中,Apple添加了直接在Notes应用程序中打开和注释PDF的功能。继续阅读以了解它是如何完成的。在最新版本的iOS和macOS中,Apple更新了Notes应用程序以支持内联PDF,这意味着您可以将PDF插入Notes中,然后阅读、批注和协作处理文档。此功能也适用于扫描的文档,并且在iPhone和iPad上都可用。在iPhone和iPad上的“备忘录”中为PDF添加批注如果您使用的是iPhone并想在“备忘录”中为PDF添加注释,首先要做的是选择PDF文件
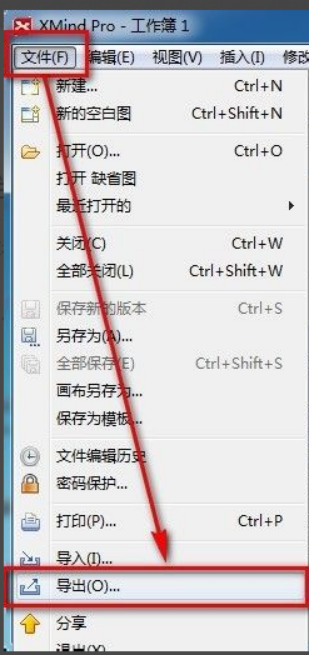 xmind文件怎么导出为pdf文件
Mar 20, 2024 am 10:30 AM
xmind文件怎么导出为pdf文件
Mar 20, 2024 am 10:30 AM
xmind是一款非常实用的思维导图软件,它是利用人们的思维和灵感制作出来的导图形式,我们在制作完xmind文件通常会把它转换成pdf文件格式,以方便大家传播使用,那么xmind文件怎么导出为pdf文件呢?下面就是具体操作步骤可以供大家参考。1.首先我们来演示一下如何导出思维导图为PDF文档。选择【文件】-【导出】功能按钮。2.在新出现的界面中选择【PDF文档】并点击【下一步】按钮。3.在导出界面选择设置:纸张尺寸、方向、分辨率和文档存储位置。完成设置后点击【完成】按钮。4.如果点击【完成】按钮后
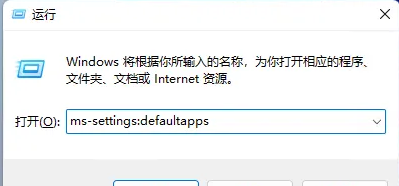 win11如何设置PDF默认打开方式 win11设置PDF默认打开方式教程
Feb 29, 2024 pm 09:01 PM
win11如何设置PDF默认打开方式 win11设置PDF默认打开方式教程
Feb 29, 2024 pm 09:01 PM
有用户觉得每次打开PDF文件都要选择一个打开方式很麻烦,想要将自己常用的打开方式设置为默认方式,那么win11如何设置PDF默认打开方式呢?下面小编就给大家详细介绍一下win11设置PDF默认打开方式教程,大家感兴趣的话就来看看吧。win11设置PDF默认打开方式教程1、快捷键"win+R"打开运行,输入"ms-settings:defaultapps"命令,回车打开。2、进入新界面后,在上方搜索框中输入".pdf",点击搜索图标进行搜索。3、这
 解决PHP7下载PDF文件遇到的问题
Feb 29, 2024 am 11:12 AM
解决PHP7下载PDF文件遇到的问题
Feb 29, 2024 am 11:12 AM
解决PHP7下载PDF文件遇到的问题在Web开发中,经常会遇到使用PHP下载文件的需求。特别是下载PDF文件,能够帮助用户获取必要的信息或文件。然而,有时候在PHP7中下载PDF文件会遇到一些问题,例如出现乱码、下载不完整等情况。本文将详细介绍如何解决在PHP7中下载PDF文件时可能遇到的问题,并提供一些具体的代码示例。问题分析在PHP7中,由于字符编码、H
