

最多400万token上下文、推理提速22倍,StreamingLLM火了,已获GitHub 2.5K星

如果你曾经与任何一款对话式 AI 机器人交流过,你一定会记得一些令人感到非常沮丧的时刻。比如,你在前一天的对话中提到的重要事项,被 AI 完全忘记了……
这是因为当前的多数 LLM 只能记住有限的上下文,就像为考试而临时抱佛脚的学生,稍加盘问就会「露出马脚」。
如果AI助手能够在聊天中根据上下文参考几周或几个月前的对话,或者你可以要求AI助手总结长达数千页的报告,那么这样的能力是不是令人羡慕呢?
为了让LLM能够更好地记住和记得更多内容,研究人员一直在不断努力。最近,来自麻省理工学院、Meta AI和卡内基梅隆大学的研究人员提出了一种名为「StreamingLLM」的方法,使得语言模型能够流畅地处理无穷无尽的文本

- 论文地址:https://arxiv.org/pdf/2309.17453.pdf
- 项目地址:https://github.com/mit-han-lab/streaming-llm
StreamingLLM 的工作原理是识别并保存模型固有的「注意力池」(attention sinks)锚定其推理的初始 token。结合最近 token 的滚动缓存,StreamingLLM 的推理速度提高了 22 倍,而不需要牺牲任何的准确性。短短几天,该项目在 GitHub 平台已斩获 2.5K 星:
具体来说,StreamingLLM 是一种使语言模型能够准确无误地记住上一场比赛的得分、新生儿的名字、冗长的合同或辩论内容的技术。就像给 AI 助理升级了内存一样,它能够完美地处理更加繁重的工作

接下来让我们看看技术细节。
方法创新
通常,LLM 在预训练时受到注意力窗口的限制。尽管为扩大这一窗口大小、提高训练和推理效率,此前已有很多工作,但 LLM 可接受的序列长度仍然是有限的,这对于持久部署来说并不友好。
在这篇论文中,研究者首先介绍了 LLM 流应用的概念,并提出了一个问题:「能否在不牺牲效率和性能的情况下以无限长输入部署 LLM?」
将 LLM 应用于无限长输入流时,会面临两个主要挑战:
1、在解码阶段,基于 transformer 的 LLM 会缓存所有先前 token 的 Key 和 Value 状态(KV),如图 1 (a) 所示,这可能会导致内存使用过多,并增加解码延迟;
2、现有模型的长度外推能力有限,即当序列长度超过预训练时设定的注意力窗口大小时,其性能就会下降。
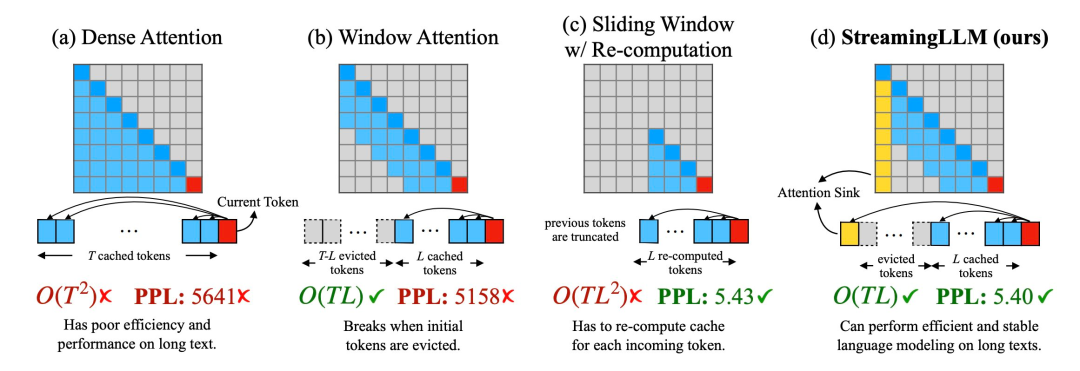
一种直观的方法被称为窗口注意力(Window Attention)(如图 1 b),这种方法只在最近 token 的 KV 状态上保持一个固定大小的滑动窗口,虽然能确保在缓存填满后仍能保持稳定的内存使用率和解码速度,但一旦序列长度超过缓存大小,甚至只是驱逐第一个 token 的 KV,模型就会崩溃。另一种方法是重新计算滑动窗口(如图 1 c 所示),这种方法会为每个生成的 token 重建最近 token 的 KV 状态,虽然性能强大,但需要在窗口内计算二次注意力,因此速度明显更慢,在实际的流应用中并不理想。
在研究窗口注意力失效的过程中,研究人员发现了一个有趣的现象:根据图2显示,大量的注意力分数被分配给了初始的标记,而不论这些标记是否与语言建模任务相关
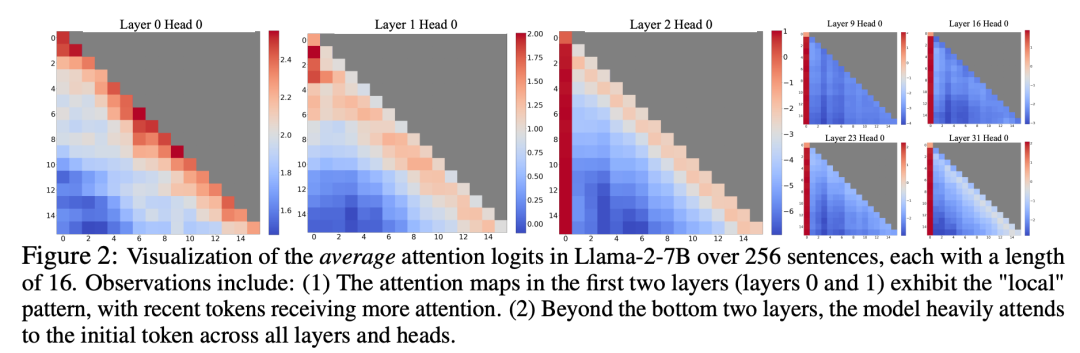
研究者将这些 token 称为「注意力池」:尽管它们缺乏语义上的意义,但却占据了大量的注意力分数。研究者将这一现象归因于于 Softmax(要求所有上下文 token 的注意力分数总和为 1),即使当前查询在许多以前的 token 中没有很强的匹配,模型仍然需要将这些不需要的注意力值分配到某处,从而使其总和为 1。初始 token 成为「池」的原因很直观:由于自回归语言建模的特性,初始 token 对几乎所有后续 token 都是可见的,这使得它们更容易被训练成注意力池。
根据以上洞察,研究者提出了StreamingLLM。这是一个简单而高效的框架,可以让使用有限注意力窗口训练的注意力模型在不进行微调的情况下处理无限长的文本
StreamingLLM 利用了注意力池具有高注意力值这一事实,保留这些注意力池可以使注意力分数分布接近正态分布。因此,StreamingLLM 只需保留注意力池 token 的 KV 值(只需 4 个初始 token 即可)和滑动窗口的 KV 值,就能锚定注意力计算并稳定模型的性能。
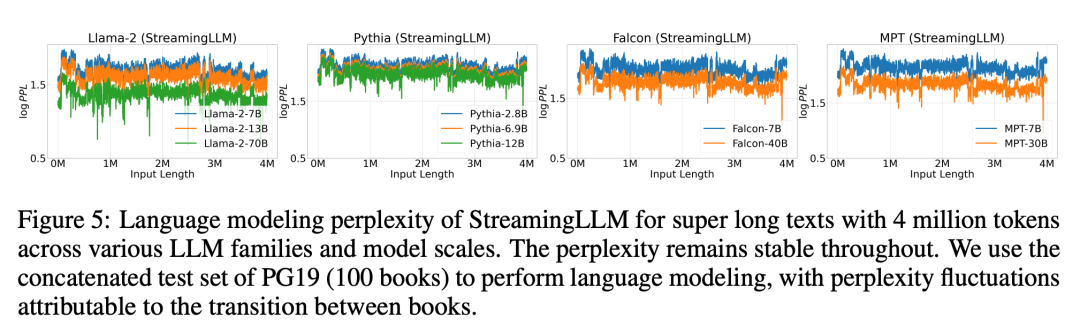
使用 StreamingLLM,包括 Llama-2-[7,13,70] B、MPT-[7,30] B、Falcon-[7,40] B 和 Pythia [2.9,6.9,12] B 在内的模型可以可靠地模拟 400 万个 token,甚至更多。
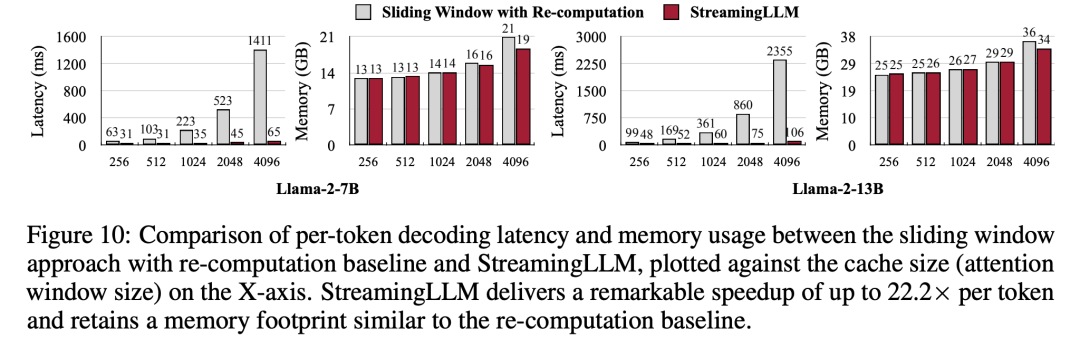
与重新计算滑动窗口相比,StreamingLLM 的速度提高了22.2倍,而没有影响性能的损失
测评
在实验中,如图3所示,对于跨度为20K个标记的文本,StreamingLLM的困惑度与重新计算滑动窗口的Oracle基线相当。同时,当输入长度超过预训练窗口时,密集注意力会失效,而当输入长度超过缓存大小时,窗口注意力会陷入困境,导致初始标记被剔除
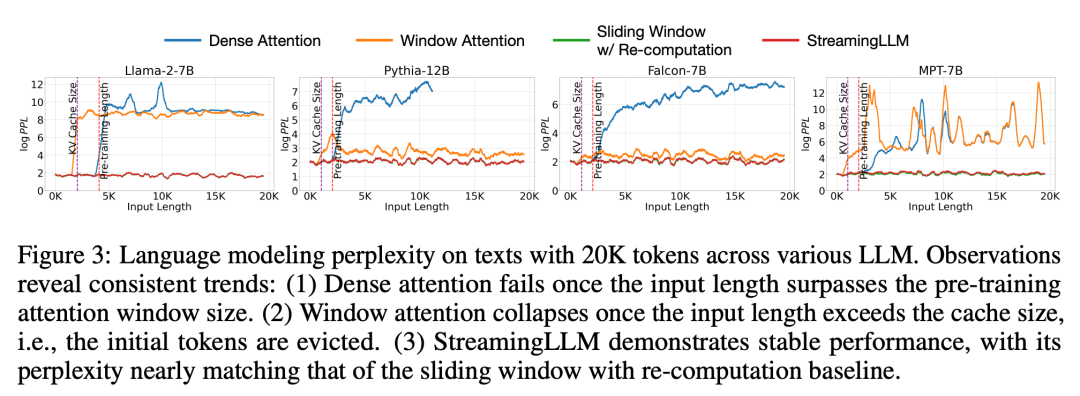
图 5 进一步证实了 StreamingLLM 的可靠性,它可以处理非常规规模的文本,包括 400 多万个标记,覆盖了各种模型系列和规模。这些模型包括 Llama-2-[7,13,70] B、Falcon-[7,40] B、Pythia-[2.8,6.9,12] B 和 MPT-[7,30] B
随后,研究者证实了「注意力池」的假设,并证明语言模型可以通过预训练,在流式部署时只需要一个注意力池 token。具体来说,他们建议在所有训练样本的开头多加一个可学习的 token,作为指定的注意力池。通过从头开始预训练 1.6 亿个参数的语言模型,研究者证明了本文方法可以保持模型的性能。这与当前的语言模型形成了鲜明对比,后者需要重新引入多个初始 token 作为注意力池才能达到相同的性能水平。
最后,研究者进行了 StreamingLLM 的解码延迟和内存使用率与重新计算滑动窗口的比较,并在单个英伟达 A6000 GPU 上使用 Llama-2-7B 和 Llama-2-13B 模型进行了测试。根据图10的结果显示,随着缓存大小的增加,StreamingLLM 的解码速度呈线性增长,而解码延迟则呈二次曲线上升。实验证明,StreamingLLM 实现了令人印象深刻的提速,每个 token 的速度提升高达22.2倍
更多研究细节,可参考原论文。
以上是最多400万token上下文、推理提速22倍,StreamingLLM火了,已获GitHub 2.5K星的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 中通过使用 ALTER TABLE 语句为现有表添加新列。具体步骤包括:确定表名称和列信息、编写 ALTER TABLE 语句、执行语句。例如,为 Customers 表添加 email 列(VARCHAR(50)):ALTER TABLE Customers ADD email VARCHAR(50);
 SQL 添加列的语法是什么
Apr 09, 2025 pm 02:51 PM
SQL 添加列的语法是什么
Apr 09, 2025 pm 02:51 PM
SQL 中添加列的语法为 ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value]; 其中,table_name 是表名,column_name 是新列名,data_type 是数据类型,NOT NULL 指定是否允许空值,DEFAULT default_value 指定默认值。
 SQL 清空表:性能优化技巧
Apr 09, 2025 pm 02:54 PM
SQL 清空表:性能优化技巧
Apr 09, 2025 pm 02:54 PM
提高 SQL 清空表性能的技巧:使用 TRUNCATE TABLE 代替 DELETE,释放空间并重置标识列。禁用外键约束,防止级联删除。使用事务封装操作,保证数据一致性。批量删除大数据,通过 LIMIT 限制行数。清空后重建索引,提高查询效率。
 SQL 添加列时如何设置默认值
Apr 09, 2025 pm 02:45 PM
SQL 添加列时如何设置默认值
Apr 09, 2025 pm 02:45 PM
为新添加的列设置默认值,使用 ALTER TABLE 语句:指定添加列并设置默认值:ALTER TABLE table_name ADD column_name data_type DEFAULT default_value;使用 CONSTRAINT 子句指定默认值:ALTER TABLE table_name ADD COLUMN column_name data_type CONSTRAINT default_constraint DEFAULT default_value;
 使用 DELETE 语句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
使用 DELETE 语句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
是的,DELETE 语句可用于清空 SQL 表,步骤如下:使用 DELETE 语句:DELETE FROM table_name;替换 table_name 为要清空的表的名称。
 Redis内存碎片如何处理?
Apr 10, 2025 pm 02:24 PM
Redis内存碎片如何处理?
Apr 10, 2025 pm 02:24 PM
Redis内存碎片是指分配的内存中存在无法再分配的小块空闲区域。应对策略包括:重启Redis:彻底清空内存,但会中断服务。优化数据结构:使用更适合Redis的结构,减少内存分配和释放次数。调整配置参数:使用策略淘汰最近最少使用的键值对。使用持久化机制:定期备份数据,重启Redis清理碎片。监控内存使用情况:及时发现问题并采取措施。
 phpmyadmin建立数据表
Apr 10, 2025 pm 11:00 PM
phpmyadmin建立数据表
Apr 10, 2025 pm 11:00 PM
要使用 phpMyAdmin 创建数据表,以下步骤必不可少:连接到数据库并单击“新建”标签。为表命名并选择存储引擎(推荐 InnoDB)。通过单击“添加列”按钮添加列详细信息,包括列名、数据类型、是否允许空值以及其他属性。选择一个或多个列作为主键。单击“保存”按钮创建表和列。
 怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
创建Oracle数据库并非易事,需理解底层机制。1. 需了解数据库和Oracle DBMS的概念;2. 掌握SID、CDB(容器数据库)、PDB(可插拔数据库)等核心概念;3. 使用SQL*Plus创建CDB,再创建PDB,需指定大小、数据文件数、路径等参数;4. 高级应用需调整字符集、内存等参数,并进行性能调优;5. 需注意磁盘空间、权限和参数设置,并持续监控和优化数据库性能。 熟练掌握需不断实践,才能真正理解Oracle数据库的创建和管理。
