

BBC 阻止 OpenAI 抓取数据,但对人工智能用于新闻持开放态度

IT之家 10 月 7 日消息,英国最大的新闻机构 BBC 发布了其在评估使用生成型人工智能(Gen AI)的原则,包括用于新闻、档案和“个性化体验”的研究和制作。

BBC 国家事务总监罗德里・塔尔凡・戴维斯在一篇博客文章中指出,BBC相信人工智能技术为我们的观众和社会带来了更多的价值机会
他提出了三个指导原则。首先,BBC将始终以公众的最大利益为出发点。其次,BBC将优先考虑人才和创造力,尊重艺术家的权利。最后,BBC对由人工智能生成的内容保持开放和透明的态度
BBC 表示,将与科技公司、其他媒体组织和监管机构合作,安全开发生成式人工智能,并重点维护对新闻行业的信任。
但是,在 BBC 确定如何最好地使用生成型人工智能的同时,也阻止了 OpenAI 和 Common Crawl 等网络爬虫访问 BBC 网站。该广播公司加入了 CNN、《纽约时报》、路透社等新闻机构的行列,阻止网络爬虫访问其受版权保护的内容。戴维斯说,这一举措是为了“维护许可费支付者的利益”,并且未经 BBC 许可就用 BBC 数据训练 AI 模型不符合公众利益。
IT之家注意到,其他新闻机构也提出了他们对这项技术的看法。美联社今年早些时候发布了自己的指导方针,其还与 OpenAI 合作,分享其内容来训练 GPT 模型。
以上是BBC 阻止 OpenAI 抓取数据,但对人工智能用于新闻持开放态度的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 什么是模型上下文协议(MCP)?
Mar 03, 2025 pm 07:09 PM
什么是模型上下文协议(MCP)?
Mar 03, 2025 pm 07:09 PM
模型上下文协议(MCP):AI和数据的通用连接器 我们都熟悉AI在日常编码中的作用。 REPLIT,GitHub副词,黑匣子AI和光标IDE只是AI如何简化我们的工作流程的几个示例。 但是想象一下
 使用OmniparSer V2和Omnitool建立本地视觉代理
Mar 03, 2025 pm 07:08 PM
使用OmniparSer V2和Omnitool建立本地视觉代理
Mar 03, 2025 pm 07:08 PM
Microsoft的OmniparSer V2和Omnitool:用AI彻底改变GUI自动化 想象一下AI不仅理解,而且像经验丰富的专业人员一样与Windows 11界面进行互动。 Microsoft的OmniparSer V2和Omnitool使它成为RE
 补充代理:带有实际示例的指南
Mar 04, 2025 am 10:52 AM
补充代理:带有实际示例的指南
Mar 04, 2025 am 10:52 AM
革命性应用程序开发:深入研究替代代理 厌倦了使用复杂的开发环境和晦涩的配置文件搏斗? Replit Agent旨在简化将想法转换为功能应用程序的过程。 这个AI-P
 我尝试了使用光标AI编码的Vibe编码,这太神奇了!
Mar 20, 2025 pm 03:34 PM
我尝试了使用光标AI编码的Vibe编码,这太神奇了!
Mar 20, 2025 pm 03:34 PM
Vibe编码通过让我们使用自然语言而不是无尽的代码行创建应用程序来重塑软件开发的世界。受Andrej Karpathy等有远见的人的启发,这种创新的方法使Dev
 跑道Act-One指南:我拍摄了自己的测试
Mar 03, 2025 am 09:42 AM
跑道Act-One指南:我拍摄了自己的测试
Mar 03, 2025 am 09:42 AM
这篇博客文章分享了我测试跑道ML的新ACT ONE动画工具的经验,涵盖其Web界面和Python API。虽然有希望,但我的结果比预期的不那么令人印象深刻。 想探索生成的AI吗? 在P中学习使用LLM
 如何使用Yolo V12进行对象检测?
Mar 22, 2025 am 11:07 AM
如何使用Yolo V12进行对象检测?
Mar 22, 2025 am 11:07 AM
Yolo(您只看一次)一直是领先的实时对象检测框架,每次迭代都在以前的版本上改善。最新版本Yolo V12引入了进步,可显着提高准确性
 2025年2月的Genai推出前5名:GPT-4.5,Grok-3等!
Mar 22, 2025 am 10:58 AM
2025年2月的Genai推出前5名:GPT-4.5,Grok-3等!
Mar 22, 2025 am 10:58 AM
2025年2月,Generative AI又是一个改变游戏规则的月份,为我们带来了一些最令人期待的模型升级和开创性的新功能。从Xai的Grok 3和Anthropic的Claude 3.7十四行诗到Openai的G
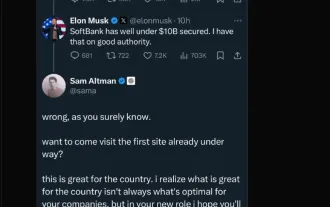 Elon Musk&Sam Altman冲突超过5000亿美元的星际之门项目
Mar 08, 2025 am 11:15 AM
Elon Musk&Sam Altman冲突超过5000亿美元的星际之门项目
Mar 08, 2025 am 11:15 AM
这项耗资5000亿美元的星际之门AI项目由OpenAI,Softbank,Oracle和Nvidia等科技巨头支持,并得到美国政府的支持,旨在巩固美国AI的领导力。 这项雄心勃勃
