

数据缺失对模型准确性的影响问题


数据缺失对模型准确性的影响问题,需要具体代码示例
在机器学习和数据分析领域中,数据是很宝贵的资源。然而,实际情况中,我们经常会遇到数据集中的一些数据缺失的问题。数据缺失是指数据集中缺少某些属性或者观测值的情况。数据缺失可能会对模型的准确性产生不良的影响,因为缺失数据可能引入偏见或者错误的预测。在本文中,我们将讨论数据缺失对模型准确性的影响问题,并提供一些具体的代码示例。
首先,数据缺失可能导致模型训练的不准确。例如,如果在分类问题中,某些观测值的类别标签缺失,那么在训练模型时,模型将无法正确学习到这些样本的特征和类别信息。这将对模型的准确性产生负面影响,使得模型的预测结果更加倾向于其他已有的类别。为了解决这个问题,一种常见的方法是对缺失数据进行处理,并使用合理的策略来填充缺失值。下面是一个具体的代码示例:
import pandas as pd
from sklearn.preprocessing import Imputer
# 读取数据
data = pd.read_csv("data.csv")
# 创建Imputer对象
imputer = Imputer(missing_values='NaN', strategy='mean', axis=0)
# 填充缺失值
data_filled = imputer.fit_transform(data)
# 训练模型
# ...上述代码中,我们使用了sklearn.preprocessing模块中的Imputer类来处理缺失值。Imputer类提供了多种填充缺失值的策略,例如使用均值、中位数或者出现频率最高的值来填充缺失值。在上面的例子中,我们使用了均值来填充缺失值。sklearn.preprocessing模块中的Imputer类来处理缺失值。Imputer类提供了多种填充缺失值的策略,例如使用均值、中位数或者出现频率最高的值来填充缺失值。在上面的例子中,我们使用了均值来填充缺失值。
其次,数据缺失还可能会对模型的评估和验证产生不利的影响。在许多模型评估和验证的指标中,对缺失数据的处理是十分关键的。如果不正确处理缺失数据,那么评估指标可能会产生偏差,并无法准确反映模型在真实场景中的性能。以下是一个使用交叉验证评估模型的示例代码:
import pandas as pd
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
# 读取数据
data = pd.read_csv("data.csv")
# 创建模型
model = LogisticRegression()
# 填充缺失值
imputer = Imputer(missing_values='NaN', strategy='mean', axis=0)
data_filled = imputer.fit_transform(data)
# 交叉验证评估模型
scores = cross_val_score(model, data_filled, target, cv=10)
avg_score = scores.mean()在上面的代码中,我们使用了sklearn.model_selection模块中的cross_val_score函数来进行交叉验证评估。在使用交叉验证之前,我们先使用Imputer
rrreee
在上面的代码中,我们使用了sklearn.model_selection模块中的cross_val_score函数来进行交叉验证评估。在使用交叉验证之前,我们先使用Imputer类来填充缺失值。这样可以保证评估指标准确反映模型在真实场景中的性能。🎜🎜总结起来,数据缺失对模型准确性的影响是一个重要的问题,需要我们认真对待。在处理数据缺失问题时,我们可以使用合适的方法来填充缺失值,并且在模型评估和验证过程中,也需要正确处理缺失数据。这样才能保证模型在实际应用中具备较高的准确性和泛化能力。以上是关于数据缺失对模型准确性的影响问题的介绍,并给出了一些具体的代码示例。希望读者可以从中获得一些启发和帮助。🎜以上是数据缺失对模型准确性的影响问题的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



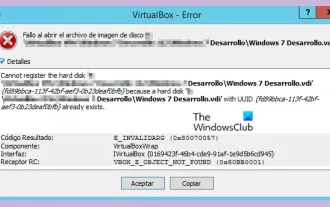 VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)VirtualBox错误
Mar 24, 2024 am 09:51 AM
VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)VirtualBox错误
Mar 24, 2024 am 09:51 AM
在VirtualBox中尝试打开磁盘映像时,可能会遇到错误提示,指示硬盘无法注册。这种情况通常发生在您尝试打开的VM磁盘映像文件与另一个虚拟磁盘映像文件具有相同的UUID时。在这种情况下,VirtualBox会显示错误代码VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)。如果您遇到这个错误,不必担心,有一些解决方法可以尝试。首先,您可以尝试使用VirtualBox的命令行工具来更改磁盘映像文件的UUID,这样可以避免冲突。您可以运行命令`VBoxManageinternal
 使用飞行模式接收电话的效果如何
Feb 20, 2024 am 10:07 AM
使用飞行模式接收电话的效果如何
Feb 20, 2024 am 10:07 AM
飞行模式别人打电话会怎么样手机已经成为人们生活中必不可少的工具之一,它不仅仅是通信工具,还是娱乐、学习、工作等多种功能的集合体。随着手机功能的不断升级和改进,人们对于手机的依赖性也越来越高。在飞行模式出现后,人们可以更方便地在飞行中使用手机。但是,有人担心在飞行模式下别人打电话的情况会对手机或者使用者产生什么样的影响呢?本文将从几个方面来进行分析和讨论。首先
 如何关闭抖音评论功能?关闭抖音评论功能后会怎么样?
Mar 23, 2024 pm 06:20 PM
如何关闭抖音评论功能?关闭抖音评论功能后会怎么样?
Mar 23, 2024 pm 06:20 PM
在抖音平台上,用户不仅可以分享自己的生活点滴,还可以与其他用户互动交流。有时候评论功能可能会引发一些不愉快的经历,如网络暴力、恶意评论等。那么,如何关闭抖音评论功能呢?一、如何关闭抖音评论功能?1.登录抖音APP,进入个人主页。2.点击右下角的“我”,进入设置菜单。3.在设置菜单中,找到“隐私设置”。4.点击“隐私设置”,进入隐私设置界面。5.在隐私设置界面,找到“评论设置”。6.点击“评论设置”,进入评论设置界面。7.在评论设置界面,找到“关闭评论”选项。8.点击“关闭评论”选项,确认关闭评论
 Java中的文件包含漏洞及其影响
Aug 08, 2023 am 10:30 AM
Java中的文件包含漏洞及其影响
Aug 08, 2023 am 10:30 AM
Java是一种常用的编程语言,用于开发各种应用程序。然而,就像其他编程语言一样,Java也存在安全漏洞和风险。其中一个常见的漏洞是文件包含漏洞(FileInclusionVulnerability),本文将探讨文件包含漏洞的原理、影响以及如何防范这种漏洞。文件包含漏洞是指在程序中通过动态引入或包含其他文件的方式,但却没有对引入的文件做充分的验证和防护,从
 数据稀缺对模型训练的影响问题
Oct 08, 2023 pm 06:17 PM
数据稀缺对模型训练的影响问题
Oct 08, 2023 pm 06:17 PM
数据稀缺对模型训练的影响问题,需要具体代码示例在机器学习和人工智能领域,数据是训练模型的核心要素之一。然而,现实中我们经常面临的一个问题是数据稀缺。数据稀缺指的是训练数据的量不足或标注数据的缺乏,这种情况下会对模型训练产生一定的影响。数据稀缺的问题主要体现在以下几个方面:过拟合:当训练数据量不够时,模型很容易出现过拟合的现象。过拟合是指模型过度适应训练数据,
 硬盘坏道会导致什么问题
Feb 18, 2024 am 10:07 AM
硬盘坏道会导致什么问题
Feb 18, 2024 am 10:07 AM
硬盘坏道是指硬盘的物理故障,即硬盘上的储存单元无法正常读取或写入数据。坏道对硬盘的影响是非常显着的,它可能导致数据丢失、系统崩溃和硬盘性能下降等问题。本文将会详细介绍硬盘坏道的影响及相关解决方法。首先,硬盘坏道可能导致数据丢失。当硬盘中的某个扇区出现坏道时,该扇区上的数据将无法读取,从而导致文件损坏或无法访问。这种情况尤其严重,如果坏道所在的扇区中存储了重要
 矿卡对游戏有什么具体的影响?
Jan 03, 2024 am 09:05 AM
矿卡对游戏有什么具体的影响?
Jan 03, 2024 am 09:05 AM
为了图便宜可能有些用户会考虑入手矿卡,这些卡毕竟是顶级的显卡,但是也有部分游戏玩家很担心矿卡打游戏有什么影响,下面就看看具体的介绍吧。矿卡打游戏有什么影响:1、矿卡打游戏没法保证稳定性,因为矿卡的寿命很短很可能玩玩就废了。2、矿卡基本上等于原版的阉割版,由于长期的损耗,各方面性能可能都弱了。3、这样用户在玩游戏的时候可能就不能将游戏的效果全部展示了。4、而且显卡的电子元件都会提前的老化,更何况打游戏也很消耗显卡,因此等于更大程度上的来将其榨干,因此对游戏的影响是很大的。5、总的来说,使用矿卡打游
 显卡配置低的影响什么
Feb 15, 2024 pm 03:27 PM
显卡配置低的影响什么
Feb 15, 2024 pm 03:27 PM
一个电脑的运行好坏基本上都和他的显卡有着非常大的影响,一部分用户对于显卡不是很了解,也不清楚显卡到底对电脑的哪些方面会有影响,为了方便大家观看,这里就给大家介绍一下显卡配置低的一些影响。显卡配置低的影响什么答:1、一些大型的3D类型的游戏无法运行。2、播放一些高清视频的时候电脑会有很大的压力。3、对于一些比较专业的软件,需要进行绘图和3D模型渲染时没有办法很好运行。4、显卡的配置低,那就会导致游戏打不开,或者频繁地闪退卡顿和卡死,电脑也会花屏,蓝屏。5、游戏里面最重要的就是显卡了,因为很多画面需
