

陈丹琦团队创新之作:以5%成本取得SOTA,掀起'羊驼剪毛”大法热潮

只用3%的计算量、5%的成本取得SOTA,统治了1B-3B规模的开源大模型。
这一成果来自普林斯顿陈丹琦团队,名为LLM-Shearing大模型剪枝法。

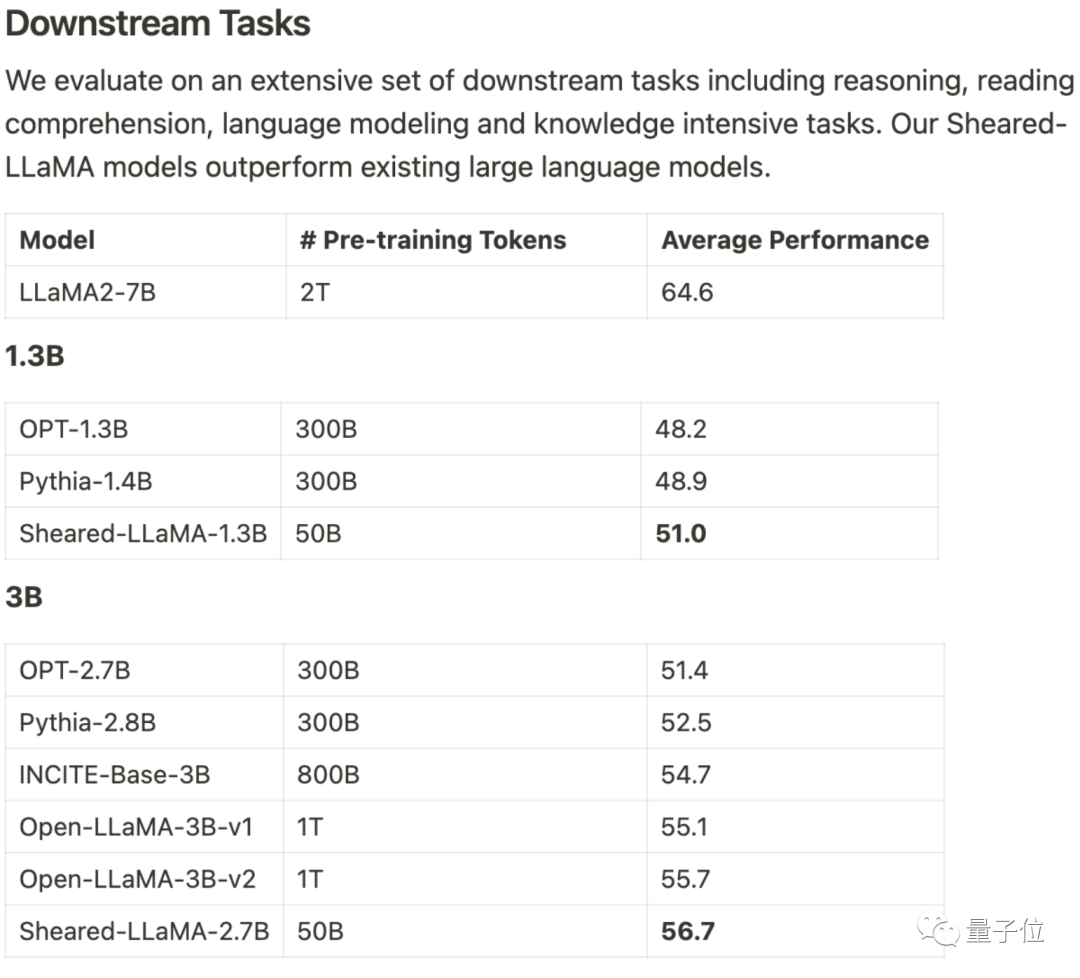
以羊驼LLaMA 2 7B为基础,通过定向结构化剪枝得到1.3B和3B剪枝后的Sheared-LLama模型。

在下游任务评估上超越之前的同等规模模型,需要进行重写
一作夏梦舟表示,“比从头开始预训练划算很多”。

论文中也给出了剪枝后的Sheared-LLaMA输出示例,表示尽管规模只有1.3B和2.7B,也已经能生成连贯且内容丰富的回复。
相同的“扮演一个半导体行业分析师”任务,2.7B版本的回答结构上还要更清晰一些。

团队表示虽然目前只用Llama 2 7B版做了剪枝实验,但该方法可以扩展到其他模型架构,也能扩展到任意规模。
剪枝后的一个额外好处是,可以选择优质的数据集进行继续预训练

有一些开发者表示,就在6个月前,几乎所有人都认为65B以下的模型没有任何实际用途
照这样下去,我敢打赌1B-3B模型也能产生巨大价值,如果不是现在,也是不久以后。

把剪枝当做约束优化
LLM-Shearing,具体来说是一种定向结构化剪枝,将一个大模型剪枝到指定的目标结构。
之前的修剪方法可能会导致模型性能下降,因为会删除一些结构,影响其表达能力
通过将剪枝视为一种约束优化问题,我们提出了一种新的方法。我们通过学习剪枝掩码矩阵来搜索与指定结构匹配的子网络,并以最大化性能为目标
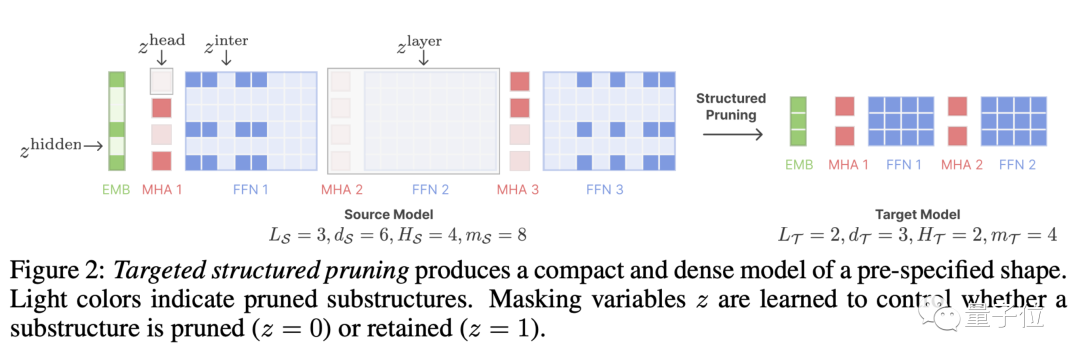
接下来对剪枝过的模型进行继续预训练,在一定程度上恢复剪枝造成的性能损失。
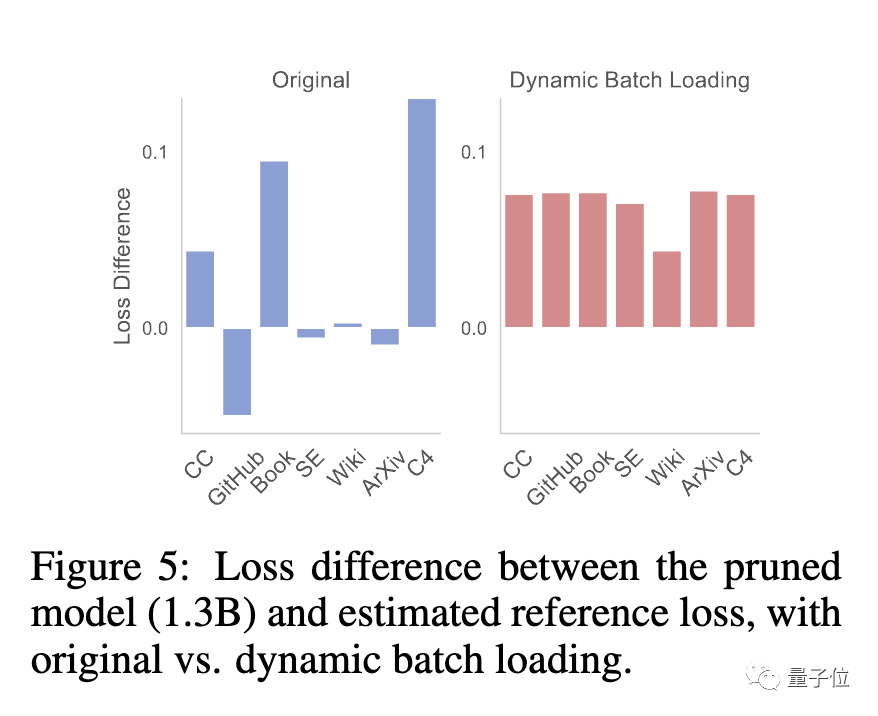
在这个阶段,团队发现剪枝过的模型与从头训练的模型对不同数据集的损失下降速率不一样,产生数据使用效率低下的问题。
为此团队提出了动态批量加载(Dynamic Batch Loading),根据模型在不同域数据上的损失下降速率动态调整每个域的数据所占比例,提高数据使用效率。
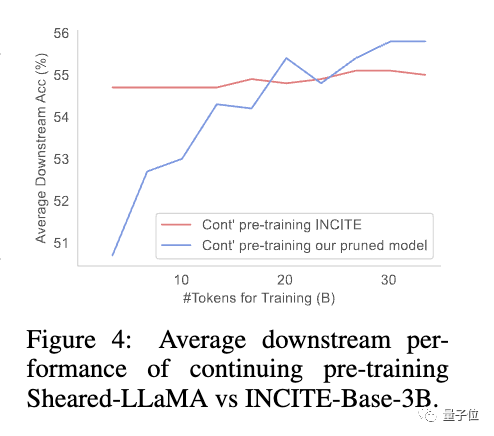
研究发现,尽管剪枝模型与从头训练的同等规模模型相比,初始性能较差,但通过持续预训练可以迅速提升,并最终超越
这表明从强大的基础模型中剪枝,可以为继续预训练提供更好的初始化条件。
将持续更新,来一个剪一个
论文作者分别为普林斯顿博士生夏梦舟、高天宇,清华Zhiyuan Zeng,普林斯顿助理教授陈丹琦。
夏梦舟,本科毕业于复旦,硕士毕业于CMU。
高天宇是一位毕业于清华大学的本科生,他在2019年获得了清华特奖
两人都是陈丹琦的学生,而陈丹琦目前是普林斯顿大学的助理教授,也是普林斯顿自然语言处理小组的共同领导者
最近在个人主页中,陈丹琦更新了她的研究方向。
"这段时间主要专注于开发大型模型,研究的主题包括:"
- 检索如何在下一代模型中发挥重要作用,提高真实性、适应性、可解释性和可信度。
- 大模型的低成本训练和部署,改进训练方法、数据管理、模型压缩和下游任务适应优化。
- 还对真正增进对当前大模型功能和局限性理解的工作感兴趣,无论在经验上还是理论上。

Sheared-Llama已经在Hugging Face上提供
团队表示,他们将继续更新开源库
更多大模型发布时,来一个剪一个,持续发布高性能的小模型。

One More Thing
不得不说,现在大模型实在是太卷了。
孟州夏刚刚发布了一条更正,表示在写论文时使用的是SOTA技术,但是论文完成后就被最新的Stable-LM-3B技术超越了
论文地址:https://arxiv.org/abs/2310.06694
Hugging Face:https://huggingface.co/princeton-nlp
项目主页链接:https://xiamengzhou.github.io/sheared-llama/
以上是陈丹琦团队创新之作:以5%成本取得SOTA,掀起'羊驼剪毛”大法热潮的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系统中,readdir系统调用用于读取目录内容。如果其性能表现不佳,可尝试以下优化策略:精简目录文件数量:尽可能将大型目录拆分成多个小型目录,降低每次readdir调用处理的项目数量。启用目录内容缓存:构建缓存机制,定期或在目录内容变更时更新缓存,减少对readdir的频繁调用。内存缓存(如Memcached或Redis)或本地缓存(如文件或数据库)均可考虑。采用高效数据结构:如果自行实现目录遍历,选择更高效的数据结构(例如哈希表而非线性搜索)存储和访问目录信
 Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
配置Debian邮件服务器的防火墙是确保服务器安全性的重要步骤。以下是几种常用的防火墙配置方法,包括iptables和firewalld的使用。使用iptables配置防火墙安装iptables(如果尚未安装):sudoapt-getupdatesudoapt-getinstalliptables查看当前iptables规则:sudoiptables-L配置
 debian readdir如何实现文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何实现文件排序
Apr 13, 2025 am 09:06 AM
在Debian系统中,readdir函数用于读取目录内容,但其返回的顺序并非预先定义的。要对目录中的文件进行排序,需要先读取所有文件,再利用qsort函数进行排序。以下代码演示了如何在Debian系统中使用readdir和qsort对目录文件进行排序:#include#include#include#include//自定义比较函数,用于qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 Debian Apache日志级别如何设置
Apr 13, 2025 am 08:33 AM
Debian Apache日志级别如何设置
Apr 13, 2025 am 08:33 AM
本文介绍如何在Debian系统中调整ApacheWeb服务器的日志记录级别。通过修改配置文件,您可以控制Apache记录的日志信息的详细程度。方法一:修改主配置文件定位配置文件:Apache2.x的配置文件通常位于/etc/apache2/目录下,文件名可能是apache2.conf或httpd.conf,具体取决于您的安装方式。编辑配置文件:使用文本编辑器(例如nano)以root权限打开配置文件:sudonano/etc/apache2/apache2.conf
 Debian OpenSSL如何防止中间人攻击
Apr 13, 2025 am 10:30 AM
Debian OpenSSL如何防止中间人攻击
Apr 13, 2025 am 10:30 AM
在Debian系统中,OpenSSL是一个重要的库,用于加密、解密和证书管理。为了防止中间人攻击(MITM),可以采取以下措施:使用HTTPS:确保所有网络请求使用HTTPS协议,而不是HTTP。HTTPS使用TLS(传输层安全协议)加密通信数据,确保数据在传输过程中不会被窃取或篡改。验证服务器证书:在客户端手动验证服务器证书,确保其可信。可以通过URLSession的委托方法来手动验证服务器
 Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
在Debian邮件服务器上安装SSL证书的步骤如下:1.安装OpenSSL工具包首先,确保你的系统上已经安装了OpenSSL工具包。如果没有安装,可以使用以下命令进行安装:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私钥和证书请求接下来,使用OpenSSL生成一个2048位的RSA私钥和一个证书请求(CSR):openss
 debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系统中的readdir函数是用于读取目录内容的系统调用,常用于C语言编程。本文将介绍如何将readdir与其他工具集成,以增强其功能。方法一:C语言程序与管道结合首先,编写一个C程序调用readdir函数并输出结果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Debian Hadoop日志管理怎么做
Apr 13, 2025 am 10:45 AM
Debian Hadoop日志管理怎么做
Apr 13, 2025 am 10:45 AM
在Debian上管理Hadoop日志,可以遵循以下步骤和最佳实践:日志聚合启用日志聚合:在yarn-site.xml文件中设置yarn.log-aggregation-enable为true,以启用日志聚合功能。配置日志保留策略:设置yarn.log-aggregation.retain-seconds来定义日志的保留时间,例如保留172800秒(2天)。指定日志存储路径:通过yarn.n
