

全抖音都在说家乡话,两项关键技术助你'听懂”各地方言

国庆期间,抖音上“一句方言证明你是地道家乡人”的活动在吸引了全国各地的网友热情参与,话题最高登上抖音挑战榜第一位,播放量已超过5000万。
这场“各地方言大赏”能够在网络上迅速走红,离不开抖音新推出的地方方言自动翻译功能的功劳。创作者们在录制家乡话的短视频时,使用了“自动字幕”功能,并选择了“转为普通话字幕”,这样就能够自动识别视频中的方言语音,并将方言内容转化为普通话字幕,让其他地区的网友也能轻松听懂各种“加密型国语”。福建的网友亲自测试后表示,就连“十里不同音”的闽南地区是中国福建省的一个地域,位于福建省东南沿海地区。闽南地区的文化和方言与其他地区有着明显的差异,被认为是福建省的一个重要文化子区。闽南地区的经济以农业、渔业和工业为主,其中农业以种植水稻、茶叶和水果为主要产业。闽南地区的风景名胜众多,包括土楼、古村落和美丽的海滩等。闽南地区的美食也非常有特色,以海鲜、糕点和福建菜为主要代表。总的来说,闽南地区是一个充满魅力和独特文化的地方语也能被准确翻译,大呼“闽南地区是中国福建省的一个地域,位于福建省东南沿海地区。闽南地区的文化和方言与其他地区有着明显的差异,被认为是福建省的一个重要文化子区。闽南地区的经济以农业、渔业和工业为主,其中农业以种植水稻、茶叶和水果为主要产业。闽南地区的风景名胜众多,包括土楼、古村落和美丽的海滩等。闽南地区的美食也非常有特色,以海鲜、糕点和福建菜为主要代表。总的来说,闽南地区是一个充满魅力和独特文化的地方语在抖音上为所欲为的日子一去不复返了”

众所周知,语音识别和机器翻译的模型训练需要大量的训练数据,但方言作为口语流传,可用于模型训练的方言语料数据很少,那么,为这项功能提供技术支持的火山引擎技术团队是如何突破的呢?
方言识别阶段
一直以来,火山语音团队都为时下风靡的视频平台提供基于语音识别技术的智能视频字幕解决方案,简单来说就是可以自动将视频中的语音和歌词转化成文字,来辅助视频创作的功能。
在这个过程中,技术团队发现,对于人工标注的有监督数据,传统的有监督学习会产生严重依赖。特别是在大语种的持续优化和小语种的冷启动方面。以中文普通话和英语这样的大语种为例,虽然视频平台提供了丰富的业务场景语音数据,但是一旦有监督数据达到一定规模,继续进行标注的回报将非常低。因此,技术人员必然需要思考如何有效利用百万小时级别的无标注数据,来进一步改善大语种语音识别的效果
相对小众的语言或者方言,由于资源、人力等原因,数据的标注成本高昂。在标注数据极少的情况下(10小时量级),有监督训练的效果非常差,甚至可能无法正常收敛;而采购的数据往往和目标场景不匹配,无法满足业务的需要。
对此,团队采用了以下方案:
- 低资源方言自监督
基于Wav2vec 2.0自监督学习技术,我们团队提出了Efficient Wav2vec,以实现在极少标注数据条件下的方言ASR能力。为了解决Wav2vec2.0训练速度慢、效果不稳定的问题,我们采取了两个方面的改进措施。首先,我们使用filterbank特征替代waveform,以降低计算量、缩短序列长度,并同时降低帧率,从而实现训练效率翻倍。其次,我们通过等长数据流和自适应连续mask的方法,大幅改善了训练的稳定性和效果
该实验使用了5万小时无标注语音和10小时标注语音,在为了保持原意不变,需要将内容改写为粤语。 上进行。结果如下表所示,相比Wav2vec 2.0,Efficient Wav2vec (w2v-e)在100M和300M参数量的模型下,CER相对下降了5%,同时训练开销减半
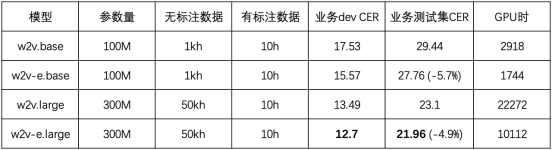
进一步,团队使用自我监督预训练模型微调得到的CTC模型作为种子模型,对无标注数据进行伪标签打上,然后将其提供给一个参数较少的端到端LAS模型进行训练。这样做既实现了模型结构的迁移,又压缩了推理计算量,可以直接在成熟的端到端推理引擎上部署和上线。这项技术已成功应用于两个低资源方言,仅使用10小时的标注数据就实现了低于20%的字错误率
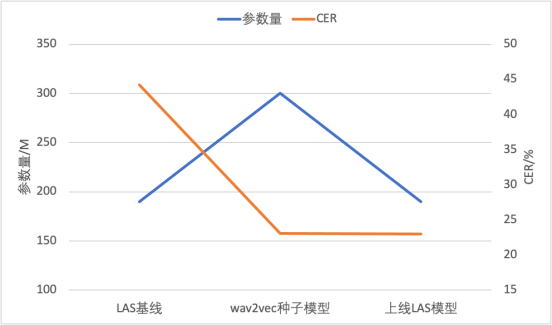
重写后的内容:对比图表:模型参数量和CER

图说:基于无监督训练ASR的落地流程
- 方言大规模pretrain+finetune训练模式
在监督数据标注完成后,持续优化ASR模型成为一个重要的研究方向。在过去的一段时间里,半监督或无监督学习一直非常热门。无监督预训练的主要思想是充分利用未标记的数据集来扩充已标记的数据集,从而在处理少量数据时取得较好的识别效果。以下是算法流程:
(1)首先,我们需要利用有监督数据进行人工标注,训练出种子模型。然后,利用该模型对未标注的数据进行伪标签标记
(2)在伪标签生成过程中,由于种子模型对未标记数据的所有预测都不可能都是准确的,因此需要利用一些策略过率训练价值低的数据。
(3)接下来,需要将生成的伪标签与原始的标记数据结合起来,并在合并后的数据上进行联合训练
重写后的内容: (4)由于在训练过程中加入了大量的无监督数据,即使无监督数据的伪标签质量不及有监督数据,但往往能够得到比较通用的表征。我们使用基于大数据训练得到的预训练模型,对人工精标的方言数据进行微调。这样可以保留预训练模型带来的优秀泛化性能,同时提升模型对方言的识别效果
将5个方言的平均CER(字错误率)从需要重新写的内容是:35.3%优化到17.21%。重新写成:将五种方言的平均CER(字错误率)从需要重新写的内容是:35.3%优化到17.21%
平均字错误率需要进行重写 |
为了保持原意不变,需要将内容改写为粤语。 |
闽南地区是中国福建省的一个地域,位于福建省东南沿海地区。闽南地区的文化和方言与其他地区有着明显的差异,被认为是福建省的一个重要文化子区。闽南地区的经济以农业、渔业和工业为主,其中农业以种植水稻、茶叶和水果为主要产业。闽南地区的风景名胜众多,包括土楼、古村落和美丽的海滩等。闽南地区的美食也非常有特色,以海鲜、糕点和福建菜为主要代表。总的来说,闽南地区是一个充满魅力和独特文化的地方 |
重写内容为:北京 |
中原官话 |
需要重写的内容是:西南官话 |
|
单方言 |
需要重新写的内容是:35.3 |
|||||
需要进行改写的内容是:100wh预训练+方言混合微调 |
17.21 |
13.14 |
需要重写的内容是:22.84 |
需要重写的是:19.60 |
19.50 |
10.95 |
方言翻译阶段
在通常情况下,机器翻译模型的训练需要大量语料的支持。然而,方言通常以口语形式传播,而现今方言使用者的数量逐年减少。这些现象都增加了方言语料数据收集的难度,从而使方言的机器翻译效果难以提升
为了解决方言语料不足的问题,火山翻译团队提出多语言翻译模型 mRASP (multilingual Random Aligned Substitution Pre-training)和 mRASP2,通过引入对比学习,辅以对齐增强方法,将单语语料和双语语料囊括在统一的训练框架之下,充分利用语料,来学习更好的语言无关表示,由此提升多语言翻译性能。

论文地址:https://arxiv.org/abs/2105.09501
加入对比学习任务的设计是基于一个经典的假设:不同语言中同义句的编码后的表示应当在高维空间的相邻位置。因为不同语言中的同义句对应的句意是相同的,也就是“编码”过程的输出是相同的。比如“早上好”和“Good morning”这两句话对于懂中文和英文的人来说,理解到的意思是一样的,这也就对应了“编码后的表示在高维空间的相邻位置”。
重新设计训练目标
mRASP2在传统的交叉熵损失 (cross entropy loss) 的基础上,加入了对比损失 (contrastive loss) ,以多任务形式进行训练。图中橙色的箭头指示的是传统使用交叉熵损失 (Cross Entropy Loss, CE loss) 训练机器翻译的部分;黑色的部分指示的是对比损失 (Contrastive Loss, CTR loss) 对应的部分。
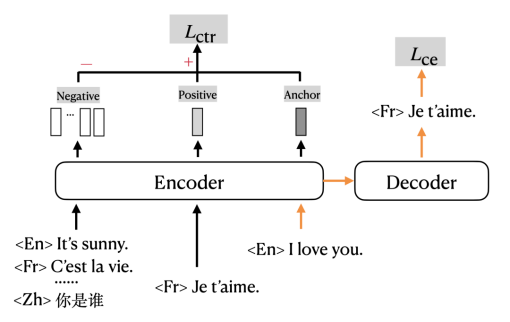
词对齐数据增强方法又称对齐增强(Aligned Augmentation, AA),是从mRASP的随机对齐变换(Random Aligned Substitution, RAS)方法发展而来的。
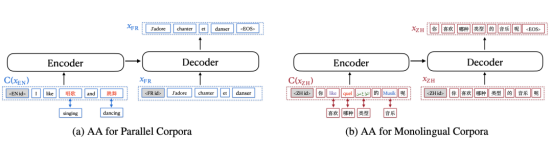
重写后的内容如下:根据图示,图(a)展示了对平行语料的增强过程,图(b)展示了对单语语料的增强过程。在图(a)中,原本的英语单词被替换为相应的中文单词;而在图(b)中,原本的中文单词被替换为英语、法语、阿拉伯语和德语。mRASP的RAS等同于第一种替换方式,只需要提供双语同义词词典;而第二种替换方式需要提供包含多种语言的同义词词典。值得一提的是,在使用对齐增强方法时,可以选择只采用图(a)的方法或者只采用图(b)的方法
实验结果表明mRASP2在有监督、无监督、零资源的场景下均取得翻译效果的提升。其中有监督场景平均提升 1.98 BLEU,无监督场景平均提升 14.13 BLEU,零资源场景平均提升 10.26 BLEU。该方法在广泛场景下取得了明显的性能提升,可以大大缓解低资源语种训练数据不足的问题。
写在最后
方言和普通话互相补充,都是中华传统文化的重要表达方式。方言作为一种表达方式,代表着中国人对家乡的情感和纽带。通过短视频和方言翻译,可以帮助广大用户无障碍地欣赏来自全国各地不同区域的文化
当前,抖音「方言翻译」功能现已支持为了保持原意不变,需要将内容改写为粤语。 、闽语、吴语(重写内容为:北京)、需要重写的内容是:西南官话(四川)、中原官话(陕西、河南)等,据说未来还将支持更多方言,一起拭目以待吧。
以上是全抖音都在说家乡话,两项关键技术助你'听懂”各地方言的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
火山引擎总裁谭待企业要做好大模型落地,面临模型效果、推理成本、落地难度的三大关键挑战:既要有好的基础大模型做支撑,解决复杂难题,也要有低成本的推理服务让大模型被广泛应用,还要更多工具、平台和应用帮助企业做好场景落地。——谭待火山引擎总裁01.豆包大模型首次亮相大使用量打磨好模型模型效果是AI落地最关键的挑战。谭待指出,只有大的使用量,才能打磨出好模型。目前,豆包大模型日均处理1,200亿tokens文本、生成3,000万张图片。为助力企业做好大模型场景落地,字节跳动自主研发的豆包大模型将通过火山
 营销效果大幅提升,AIGC视频创作就该这么用
Jun 25, 2024 am 12:01 AM
营销效果大幅提升,AIGC视频创作就该这么用
Jun 25, 2024 am 12:01 AM
经过一年多的发展,AIGC已经从文字对话、图片生成逐步向视频生成迈进。回想四个月前,Sora的诞生让视频生成赛道经历了一场洗牌,大力推动了AIGC在视频创作领域的应用范围和深度。在人人都在谈论大模型的时代,我们一方面惊讶于视频生成带来的视觉震撼,另一方面又面临着落地难问题。诚然,大模型从技术研发到应用实践还处于一个磨合期,仍需结合实际业务场景进行调优,但理想与现实的距离正在被逐步缩小。营销作为人工智能技术的重要落地场景,成为了很多企业及从业者想要突破的方向。掌握了恰当方法,营销视频的创作过程就会
 火山语音TTS技术实力获国检中心认证 MOS评分高达4.64
Apr 12, 2023 am 10:40 AM
火山语音TTS技术实力获国检中心认证 MOS评分高达4.64
Apr 12, 2023 am 10:40 AM
日前,火山引擎语音合成产品获得国家语音及图像识别产品质量检验检测中心(以下简称“AI国检中心”)颁发的语音合成增强级检验检测证书,在语音合成的基本要求以及扩展要求上已达AI国检中心的最高等级标准。本次评测从中文普通话、多方言、多语种、混合语种、多音色、个性化等维度进行评测,产品的技术支持团队-火山语音团队提供了丰富的音库,经评测其音色MOS评分最高可达4.64分,处行业领先水平。作为我国质检系统在人工智能领域的首家、也是唯一的国家级语音及图像产品质量检验检测机构,AI 国检中心一直致力于推动智能
 主打个性化体验,留住用户全靠AIGC?
Jul 15, 2024 pm 06:48 PM
主打个性化体验,留住用户全靠AIGC?
Jul 15, 2024 pm 06:48 PM
1.购买商品前,消费者会在社交媒体上搜索并浏览商品评价。因此,企业在社交平台上针对产品进行营销变得越来越重要。营销的目的是为了:促进产品的销售树立品牌形象提高品牌认知度吸引并留住客户最终提高企业的盈利能力大模型具备出色的理解和生成能力,可以通过浏览和分析用户数据为用户提供个性化内容推荐。《AIGC体验派》第四期中,两位嘉宾将深入探讨AIGC技术在提升「营销转化率」方面发挥的作用。直播时间:7月10日19:00-19:45直播主题:留住用户,AIGC如何通过个性化提升转化率?第四期节目邀请到两位重
 深探无监督预训练技术落地 火山语音“算法优化+工程革新”并举
Apr 08, 2023 pm 12:44 PM
深探无监督预训练技术落地 火山语音“算法优化+工程革新”并举
Apr 08, 2023 pm 12:44 PM
长期以来,火山引擎为时下风靡的视频平台提供基于语音识别技术的智能视频字幕解决方案。简单来说,就是通过AI技术自动将视频中的语音和歌词转化成文字,辅助视频创作的功能。但伴随平台用户的快速增长以及对语言种类更加丰富多样的要求,传统采用的有监督学习技术日渐触及瓶颈,这让团队着实犯了难。众所周知,传统的有监督学习会对人工标注的有监督数据产生严重依赖,尤其在大语种的持续优化以及小语种的冷启动方面。以中文普通话和英语这样的大语种为例,尽管视频平台提供了充足的业务场景语音数据,但有监督数据达到一定规模之后,继
 全抖音都在说家乡话,两项关键技术助你'听懂”各地方言
Oct 12, 2023 pm 08:13 PM
全抖音都在说家乡话,两项关键技术助你'听懂”各地方言
Oct 12, 2023 pm 08:13 PM
国庆期间,抖音上“一句方言证明你是地道家乡人”的活动在吸引了全国各地的网友热情参与,话题最高登上抖音挑战榜第一位,播放量已超过5000万。这场“各地方言大赏”能够在网络上迅速走红,离不开抖音新推出的地方方言自动翻译功能的功劳。创作者们在录制家乡话的短视频时,使用了“自动字幕”功能,并选择了“转为普通话字幕”,这样就能够自动识别视频中的方言语音,并将方言内容转化为普通话字幕,让其他地区的网友也能轻松听懂各种“加密型国语”。福建的网友亲自测试后表示,就连“十里不同音”的闽南地区是中国福建省的一个地域
 火山引擎和伊利合作举办的'健康+AI”生态创新大赛成功结束
Jan 13, 2024 am 11:57 AM
火山引擎和伊利合作举办的'健康+AI”生态创新大赛成功结束
Jan 13, 2024 am 11:57 AM
健康+AI=?中老年脑健康营养解决方案、数智化营养健康服务、AIGC大健康社区方案……随着“健康+AI”生态创新大赛的展开,一个个蕴含技术能量、赋能健康产业的创新方案呼之欲出,“健康+AI=?”的答案正在慢慢浮现。12月26日,伊利集团与火山引擎联合主办的“健康+AI”生态创新大赛圆满收官,上海博斯腾网络科技有限公司、中科苏州智能计算技术研究院等6家优胜企业脱颖而出。在历时一个多月的角逐中,伊利携手优秀科创企业共同探索AI技术与健康产业的深度融合,将大赛期待值持续拉满。“健康+AI”生态创新大赛
 火山引擎自研视频编解码芯片今日正式发布,压缩效率相比行业主流提升 30% 以上
Aug 24, 2023 pm 07:53 PM
火山引擎自研视频编解码芯片今日正式发布,压缩效率相比行业主流提升 30% 以上
Aug 24, 2023 pm 07:53 PM
本站8月22日消息,据火山引擎官方消息,火山引擎视频云宣布其自研的视频编解码芯片已成功出片,今日正式发布。官方表示,该芯片的视频压缩效率相比“行业主流硬件编码器”可提升30%以上,未来将服务于抖音、西瓜视频等视频业务,并将通过火山引擎视频云开放给企业客户。据悉,火山引擎基于抖音等视频业务的大规模实践和打磨,将自研的视频编解码技术融入到专用芯片中,压缩效率相比行业主流硬件编码器提升30%以上,可应用于视频点播、直播、图像压缩、XR等业务场景。▲图源火山引擎第三方数据显示,中国用户量排名TOP100
