

提升工程效率——增强检索生成(RAG)

随着GPT-3等大型语言模型的问世,自然语言处理(NLP)领域取得了重大突破。这些语言模型具备生成类人文本的能力,并已广泛应用于各种场景,如聊天机器人和翻译

然而,当涉及到专业化和定制化的应用场景时,通用的大语言模型可能在专业知识方面会有所不足。用专业的语料库对这些模型进行微调往往昂贵且耗时。“检索增强生成”(RAG)为专业化应用提供了一个新技术方案。
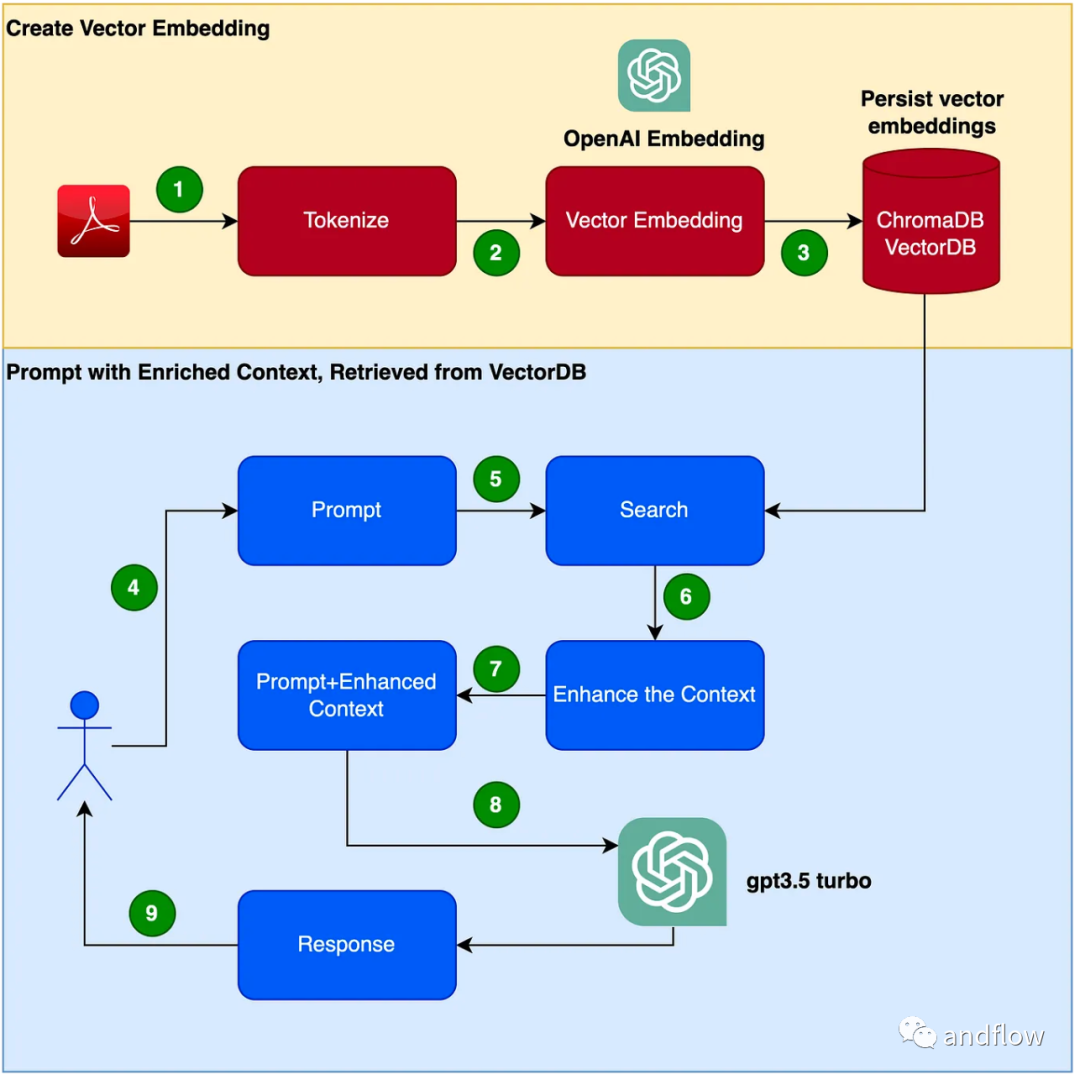
下面我们主要介绍RAG如何工作,并通过一个实际的例子,将产品手册作为专业语料库,使用GPT-3.5 Turbo来作为问答模型,验证其有效性。
案例:开发一个聊天机器人,能够回答与特定产品相关的问题。该企业拥有独特的用户手册
RAG介绍
RAG 提供了一种有效的解决方案,用于特定领域的问答。它主要通过将行业知识转化为向量进行存储和检索,并将检索结果与用户问题结合形成提示信息,最终利用大型模型生成合适的回答。通过结合检索机制和语言模型,大大增强了模型的响应能力
创建聊天机器人程序的步骤如下:
- 读取PDF(用户手册PDF文件)并使用chunk_size为1000个令牌进行令牌化。
- 创建向量(可以使用OpenAI EmbeddingsAPI来创建向量)。
- 在本地向量库中存储向量。我们将使用ChromaDB作为向量数据库(向量数据库也可以使用Pinecone或其他产品替代)。
- 用户发出具有查询/问题的提示。
- 根据用户的问题从向量数据库检索出知识上下文数据。这个知识上下文数据将在后续步骤中与提示词结合使用,来增强提示词,通常被称为上下文丰富。
- 提示词包含用户问题和增强的上下文知识一起被传递给LLM
- LLM 基于此上下文进行回答。
动手开发
(1)设置Python虚拟环境 设置一个虚拟环境来沙箱化我们的Python,以避免任何版本或依赖项冲突。执行以下命令以创建新的Python虚拟环境。
需要重写的内容是:pip安装virtualenv,python3 -m venv ./venv,source venv/bin/activate
需要进行改写的内容是:(2)生成OpenAI密钥
使用GPT需要一个OpenAI密钥来进行访问
需要进行重写的内容是:(3)安装依赖库
安装程序需要的各种依赖项。包括以下几个库:
- lanchain:一个开发LLM应用程序的框架。
- chromaDB:这是用于持久化向量嵌入的VectorDB。
- unstructured:用于预处理Word/PDF文档。
- tiktoken: Tokenizer framework
- pypdf:读取和处理PDF文档的框架。
- openai:访问OpenAI的框架。
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
创建一个环境变量来存储OpenAI密钥。
export OPENAI_API_KEY=<openai-key></openai-key>
(4)将用户手册PDF文件转化为向量并将其存储在ChromaDB中
将所有需要使用的依赖库和函数导入
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
读取PDF,标记化文档并拆分文档。
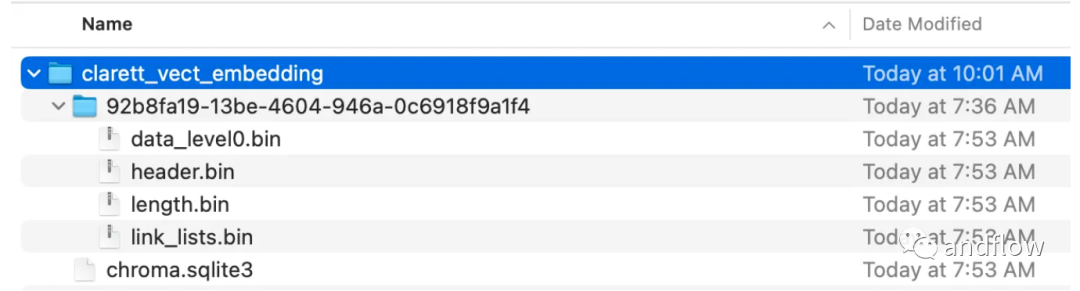
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)创建一个chroma集合,和一个存储chroma数据的本地目录。然后,创建一个向量(embeddings)并将其存储在ChromaDB中。
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData,embeddings,collection_name=collection_name,persist_directory=persist_directory)vectDB.persist()执行此代码后,您应该看到一个已经创建好的文件夹,用于存储向量。
在将向量嵌入存储在ChromaDB后,可以使用LangChain中的ConversationalRetrievalChain API来启动一个聊天历史组件
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm(OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
初始化了langchan之后,我们可以使用它来聊天/Q A。下面的代码中,接受用户输入的问题,并在用户输入'done'之后,将问题传递给LLM,以获得答复并打印出来。
chat_history = []qry = ""while qry != 'done':qry = input('Question: ')if qry != exit:response = chatQA({"question": qry, "chat_history": chat_history})print(response["answer"])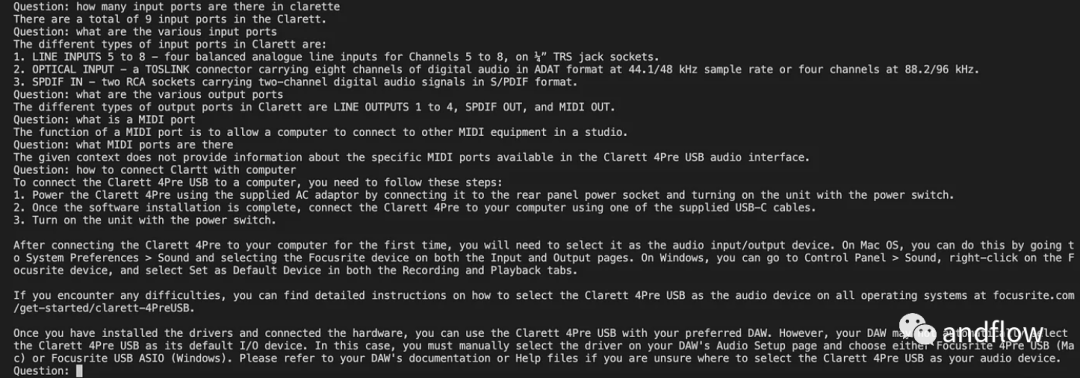

总之
RAG将GPT等语言模型的优势与信息检索的优势结合在一起。通过利用特定的知识上下文信息来增强提示词的丰富度,使得语言模型能够生成更准确、与知识上下文相关的回答。RAG提供了一种比“微调”更高效且成本效益更好的解决方案,为行业应用或企业应用提供可定制化的互动方案
以上是提升工程效率——增强检索生成(RAG)的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 使用Rag和Sem-Rag提供上下文增强AI编码助手
Jun 10, 2024 am 11:08 AM
使用Rag和Sem-Rag提供上下文增强AI编码助手
Jun 10, 2024 am 11:08 AM
通过将检索增强生成和语义记忆纳入AI编码助手,提升开发人员的生产力、效率和准确性。译自EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG,作者JanakiramMSV。虽然基本AI编程助手自然有帮助,但由于依赖对软件语言和编写软件最常见模式的总体理解,因此常常无法提供最相关和正确的代码建议。这些编码助手生成的代码适合解决他们负责解决的问题,但通常不符合各个团队的编码标准、惯例和风格。这通常会导致需要修改或完善其建议,以便将代码接受到应
 知识图谱检索增强的GraphRAG(基于Neo4j代码实现)
Jun 12, 2024 am 10:32 AM
知识图谱检索增强的GraphRAG(基于Neo4j代码实现)
Jun 12, 2024 am 10:32 AM
图检索增强生成(GraphRAG)正逐渐流行起来,成为传统向量搜索方法的有力补充。这种方法利用图数据库的结构化特性,将数据以节点和关系的形式组织起来,从而增强检索信息的深度和上下文关联性。图在表示和存储多样化且相互关联的信息方面具有天然优势,能够轻松捕捉不同数据类型间的复杂关系和属性。而向量数据库则处理这类结构化信息时则显得力不从心,它们更专注于处理高维向量表示的非结构化数据。在RAG应用中,结合结构化化的图数据和非结构化的文本向量搜索,可以让我们同时享受两者的优势,这也是本文将要探讨的内容。构
 利用知识图谱增强RAG模型的能力和减轻大模型虚假印象
Jan 14, 2024 pm 06:30 PM
利用知识图谱增强RAG模型的能力和减轻大模型虚假印象
Jan 14, 2024 pm 06:30 PM
在使用大型语言模型(LLM)时,幻觉是一个常见问题。尽管LLM可以生成流畅连贯的文本,但其生成的信息往往不准确或不一致。为了防止LLM产生幻觉,可以利用外部的知识来源,比如数据库或知识图谱,来提供事实信息。这样一来,LLM可以依赖这些可靠的数据源,从而生成更准确和可靠的文本内容。向量数据库和知识图谱向量数据库向量数据库是一组表示实体或概念的高维向量。它们可以用于度量不同实体或概念之间的相似性或相关性,通过它们的向量表示进行计算。一个向量数据库可以根据向量距离告诉你,“巴黎”和“法国”比“巴黎”和
 理解GraphRAG(一):RAG的挑战
Apr 30, 2024 pm 07:10 PM
理解GraphRAG(一):RAG的挑战
Apr 30, 2024 pm 07:10 PM
RAG(RiskAssessmentGrid)是一种通过外部知识源增强现有大型语言模型(LLM)的方法,以提供和上下文更相关的答案。在RAG中,检索组件获取额外的信息,响应基于特定来源,然后将这些信息输入到LLM提示中,以使LLM的响应基于这些信息(增强阶段)。与其他技术(例如微调)相比,RAG更经济。它还有减少幻觉的优势,通过基于这些信息(增强阶段)提供额外的上下文——你RAG成为今天LLM任务的(如推荐、文本提取、情感分析等)的流程方法。如果我们进一步分解这个想法,根据用户意图,我们通常会查
 构建多模态RAG系统的方法:使用CLIP和LLM
Jan 13, 2024 pm 10:24 PM
构建多模态RAG系统的方法:使用CLIP和LLM
Jan 13, 2024 pm 10:24 PM
我们将讨论使用开源的大型语言多模态模型(LargeLanguageMulti-Modal)构建检索增强生成(RAG)系统的方法。我们的重点是在不依赖LangChain或LLlamaindex的情况下实现这一目标,以避免增加更多的框架依赖。什么是RAG在人工智能领域,检索增强生成(retrieve-augmentedgeneration,RAG)技术的出现为大型语言模型(LargeLanguageModels)带来了变革性的改进。RAG的本质是通过允许模型从外部源动态检索实时信息,从而增强人工智能
 深入研究RAG和向量数据库:实现低成本快速定制大模型的关键
Nov 13, 2023 pm 03:29 PM
深入研究RAG和向量数据库:实现低成本快速定制大模型的关键
Nov 13, 2023 pm 03:29 PM
如今,在人工智能领域中,备受关注的是大规模模型。然而,高昂的培训费用和漫长的培训时间等因素已成为制约大多数企业参与大规模模型领域的关键障碍这种背景下,向量数据库凭借其独特的优势,成为解决低成本快速定制大模型问题的关键所在。向量数据库是一种专门用于存储和处理高维向量数据的技术。它采用高效的索引和查询算法,实现了海量数据的快速检索和分析。如此优秀的性能之外,向量数据库还可以为特定领域和任务提供定制化的解决方案。腾讯、阿里等科技巨头纷纷投入研发向量数据库,希望在大模型领域取得突破。许多中小型公司也利用
 除了RAG,还有这五种方法消除大模型幻觉
Jun 10, 2024 pm 08:25 PM
除了RAG,还有这五种方法消除大模型幻觉
Jun 10, 2024 pm 08:25 PM
出品|51CTO技术栈(微信号:blog51cto)众所周知,LLM会产生幻觉——即生成不正确、误导性或无意义的信息。有意思的是,一些人,如OpenAI的CEOSamAltman,将AI的想象视为创造力,而另一些人则认为想象可能有助于做出新的科学发现。然而,在大多数情况下,提供正确回答至关重要,幻觉并不是一项特性,而是一种缺陷。那么,如何减少LLM的幻觉呢?长上下文?RAG?微调?其实,长上下文LLMs并非万无一失,向量搜索RAG也不尽如人意,而微调则伴随着其自身的挑战和限制。下面是一些可以用来
 她用10年日记训练GPT-3,对话童年的自己,网友:AI最治愈的应用
Apr 12, 2023 pm 04:25 PM
她用10年日记训练GPT-3,对话童年的自己,网友:AI最治愈的应用
Apr 12, 2023 pm 04:25 PM
“这是我目前听过关于AI最好、最治愈的一个应用。”到底是什么应用,能让网友给出如此高度的评价?原来,一个脑洞大开的网友Michelle,用GPT-3造了一个栩栩如生的“童年Michelle”。然后她和童年的自己聊起了天,对方甚至还写来一封信。“童年Michelle”的“学习资料”也很有意思——是Michelle本人的日记,而且是连续十几年,几乎每天都写的那种。日记内容中有她的快乐和梦想,也有恐惧和抱怨;还有很多小秘密,包括和Crush聊天时紧张到眩晕…(不爱写日记的我真的给跪了……)厚厚一叠日记
