

'大大震惊”一位CTO:GPT-4V自动驾驶五连测

本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
万众瞩目之下,今天GPT4终于推送了vision相关的功能。
今天下午抓紧和小伙伴一起测试了一下GPT对于图像感知的能力,虽有预期,但是还是大大震惊了我们。
核心观点:
我认为自动驾驶中和语义相关的问题应该大模型都已经解决得很好了,但是大模型的可信性和空间感知能力方面仍然不尽如人意。
解决一些所谓和效率相关的corner case应该是绰绰有余,但是想完全依赖大模型去独立完成驾驶保证安全性仍然十分遥远。
Example1: 路上出现了一些未知障碍物


△GPT4的描述
准确的部分:检测到了3辆卡车,前车车牌号基本正确(有汉字就忽略吧),天气和环境正确,在没有提示的情况下准确识别到了前方的未知障碍物。
不准确的部分:第三辆卡车的位置左右不分,第二辆卡车头顶的文字瞎猜了一个(因为分辨率不足?)。
这还不够,我们继续给一点提示,去问这个物体是什么,是不是可以压过去。
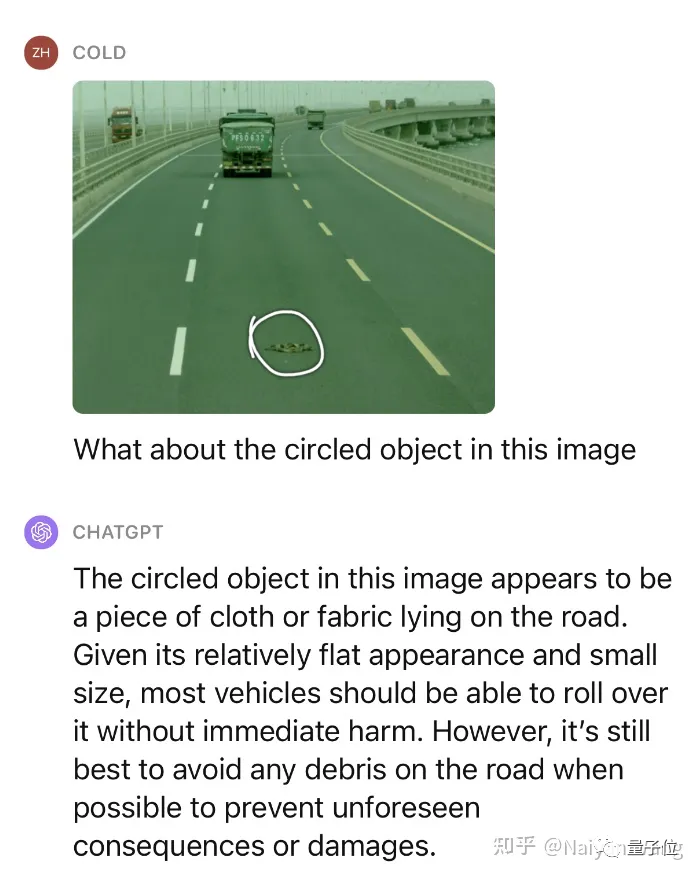
Impressive!类似的场景测试了多个,对于未知障碍物的表现可以说非常惊人了。
Example2: 路面积水的理解
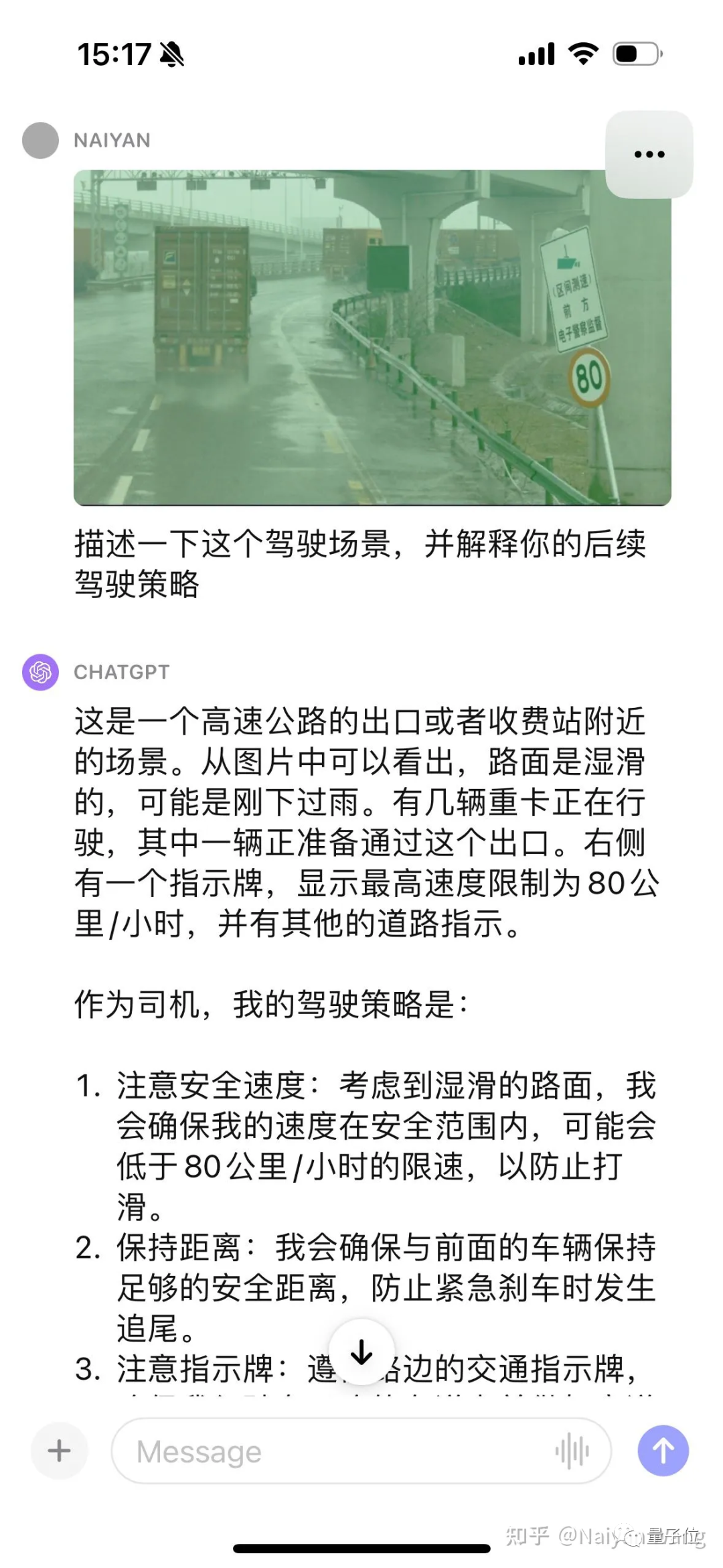
没有提示能自动识别到标牌这个应该是基操了,我们继续给一些hint。

再次被震惊了。。。能自动讲出来卡车背后的雾气,也主动提到了水坑,但是再一次把方向说成了左侧。。。感觉这里可能需要一些prompt engineering能更好的让GPT输出位置和方向。
Example3:有车辆掉头时直接撞上了护栏

第一帧输入进去,因为没有时序信息,只是将右侧的卡车当做是停靠的了。于是再来一帧:

已经可以自动讲出,这辆撞破了护栏,悬停在公路边缘,太棒了。。。但是反而看上去更容易的道路标志出现了错误。。。只能说,这很大模型了,它永远能震惊你也永远不知道什么时候能蠢哭你。。。再来一帧:

这次,直接讲到了路面上的碎片,再次赞叹。。。只不过有一次把路上的箭头说错了。。。总体而言,这个场景中需要特别关注的信息都有覆盖,道路标志这种问题,瑕不掩瑜吧。
Example4: 来一个搞笑的

只能说非常到位了,相比之下之前看上去无比困难的“有个人冲着你挥了挥手”这样的case就像小儿科一样,语义上的corner case可解。
Example5 来一个名场面。。。配送车误入新修路
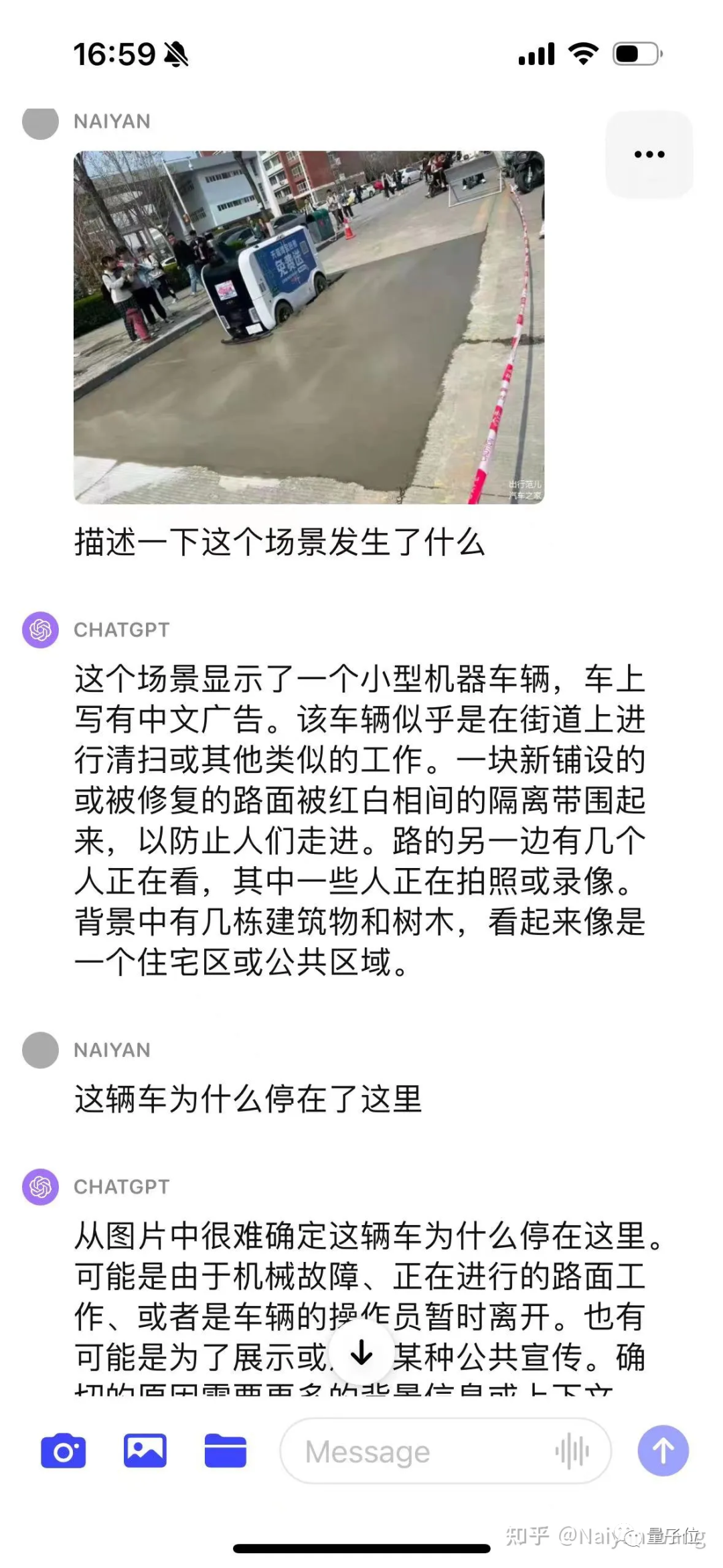



开始比较保守,并没有直接猜测原因,给了多种猜测,这个也倒是符合alignment的目标。
使用CoT之后问题发现问题是在于并不了解这辆车是个自动驾驶车辆,故通过prompt给出这个信息能给出比较准确的信息。
最后通过一堆prompt,能够输出新铺设沥青,不适合驾驶这样的结论。最终结果来说还是OK,但是过程比较曲折,需要比较多的prompt engineering,要好好设计。
这个原因可能也是因为不是第一视角的图片,只能通过第三视角去推测。所以这个例子并不十分精确。
总结
快速的一些尝试已经完全证明了GPT4V的强大与泛化性能,适当的prompt应当可以完全发挥出GPT4V的实力。
解决语义上的corner case应该非常可期,但幻觉的问题会仍然困扰着一些和安全相关场景中的应用。
非常exciting,个人认为合理使用这样的大模型可以大大加快L4乃至L5自动驾驶的发展,然而是否LLM一定是要直接开车?尤其是端到端开车,仍然是一个值得商榷的问题。
以上是'大大震惊”一位CTO:GPT-4V自动驾驶五连测的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?
Jan 17, 2024 pm 02:57 PM
为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?
Jan 17, 2024 pm 02:57 PM
写在前面&笔者的个人理解三维Gaussiansplatting(3DGS)是近年来在显式辐射场和计算机图形学领域出现的一种变革性技术。这种创新方法的特点是使用了数百万个3D高斯,这与神经辐射场(NeRF)方法有很大的不同,后者主要使用隐式的基于坐标的模型将空间坐标映射到像素值。3DGS凭借其明确的场景表示和可微分的渲染算法,不仅保证了实时渲染能力,而且引入了前所未有的控制和场景编辑水平。这将3DGS定位为下一代3D重建和表示的潜在游戏规则改变者。为此我们首次系统地概述了3DGS领域的最新发展和关
 自动驾驶场景中的长尾问题怎么解决?
Jun 02, 2024 pm 02:44 PM
自动驾驶场景中的长尾问题怎么解决?
Jun 02, 2024 pm 02:44 PM
昨天面试被问到了是否做过长尾相关的问题,所以就想着简单总结一下。自动驾驶长尾问题是指自动驾驶汽车中的边缘情况,即发生概率较低的可能场景。感知的长尾问题是当前限制单车智能自动驾驶车辆运行设计域的主要原因之一。自动驾驶的底层架构和大部分技术问题已经被解决,剩下的5%的长尾问题,逐渐成了制约自动驾驶发展的关键。这些问题包括各种零碎的场景、极端的情况和无法预测的人类行为。自动驾驶中的边缘场景"长尾"是指自动驾驶汽车(AV)中的边缘情况,边缘情况是发生概率较低的可能场景。这些罕见的事件
 选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述
Jan 26, 2024 am 11:18 AM
选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述
Jan 26, 2024 am 11:18 AM
0.写在前面&&个人理解自动驾驶系统依赖于先进的感知、决策和控制技术,通过使用各种传感器(如相机、激光雷达、雷达等)来感知周围环境,并利用算法和模型进行实时分析和决策。这使得车辆能够识别道路标志、检测和跟踪其他车辆、预测行人行为等,从而安全地操作和适应复杂的交通环境.这项技术目前引起了广泛的关注,并认为是未来交通领域的重要发展领域之一。但是,让自动驾驶变得困难的是弄清楚如何让汽车了解周围发生的事情。这需要自动驾驶系统中的三维物体检测算法可以准确地感知和描述周围环境中的物体,包括它们的位置、
 Stable Diffusion 3论文终于发布,架构细节大揭秘,对复现Sora有帮助?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3论文终于发布,架构细节大揭秘,对复现Sora有帮助?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3的论文终于来了!这个模型于两周前发布,采用了与Sora相同的DiT(DiffusionTransformer)架构,一经发布就引起了不小的轰动。与之前版本相比,StableDiffusion3生成的图质量有了显着提升,现在支持多主题提示,并且文字书写效果也得到了改善,不再出现乱码情况。 StabilityAI指出,StableDiffusion3是一个系列模型,其参数量从800M到8B不等。这一参数范围意味着该模型可以在许多便携设备上直接运行,从而显着降低了使用AI
 自动驾驶与轨迹预测看这一篇就够了!
Feb 28, 2024 pm 07:20 PM
自动驾驶与轨迹预测看这一篇就够了!
Feb 28, 2024 pm 07:20 PM
轨迹预测在自动驾驶中承担着重要的角色,自动驾驶轨迹预测是指通过分析车辆行驶过程中的各种数据,预测车辆未来的行驶轨迹。作为自动驾驶的核心模块,轨迹预测的质量对于下游的规划控制至关重要。轨迹预测任务技术栈丰富,需要熟悉自动驾驶动/静态感知、高精地图、车道线、神经网络架构(CNN&GNN&Transformer)技能等,入门难度很大!很多粉丝期望能够尽快上手轨迹预测,少踩坑,今天就为大家盘点下轨迹预测常见的一些问题和入门学习方法!入门相关知识1.预习的论文有没有切入顺序?A:先看survey,p
 聊聊端到端与下一代自动驾驶系统,以及端到端自动驾驶的一些误区?
Apr 15, 2024 pm 04:13 PM
聊聊端到端与下一代自动驾驶系统,以及端到端自动驾驶的一些误区?
Apr 15, 2024 pm 04:13 PM
最近一个月由于众所周知的一些原因,非常密集地和行业内的各种老师同学进行了交流。交流中必不可免的一个话题自然是端到端与火爆的特斯拉FSDV12。想借此机会,整理一下在当下这个时刻的一些想法和观点,供大家参考和讨论。如何定义端到端的自动驾驶系统,应该期望端到端解决什么问题?按照最传统的定义,端到端的系统指的是一套系统,输入传感器的原始信息,直接输出任务关心的变量。例如,在图像识别中,CNN相对于传统的特征提取器+分类器的方法就可以称之为端到端。在自动驾驶任务中,输入各种传感器的数据(相机/LiDAR
 FisheyeDetNet:首个基于鱼眼相机的目标检测算法
Apr 26, 2024 am 11:37 AM
FisheyeDetNet:首个基于鱼眼相机的目标检测算法
Apr 26, 2024 am 11:37 AM
目标检测在自动驾驶系统当中是一个比较成熟的问题,其中行人检测是最早得以部署算法之一。在多数论文当中已经进行了非常全面的研究。然而,利用鱼眼相机进行环视的距离感知相对来说研究较少。由于径向畸变大,标准的边界框表示在鱼眼相机当中很难实施。为了缓解上述描述,我们探索了扩展边界框、椭圆、通用多边形设计为极坐标/角度表示,并定义一个实例分割mIOU度量来分析这些表示。所提出的具有多边形形状的模型fisheyeDetNet优于其他模型,并同时在用于自动驾驶的Valeo鱼眼相机数据集上实现了49.5%的mAP
 SIMPL:用于自动驾驶的简单高效的多智能体运动预测基准
Feb 20, 2024 am 11:48 AM
SIMPL:用于自动驾驶的简单高效的多智能体运动预测基准
Feb 20, 2024 am 11:48 AM
原标题:SIMPL:ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving论文链接:https://arxiv.org/pdf/2402.02519.pdf代码链接:https://github.com/HKUST-Aerial-Robotics/SIMPL作者单位:香港科技大学大疆论文思路:本文提出了一种用于自动驾驶车辆的简单高效的运动预测基线(SIMPL)。与传统的以代理为中心(agent-cent
