

选择GPT-3.5、还是微调Llama 2等开源模型?综合比较后答案有了

众所周知,对 GPT-3.5 进行微调是非常昂贵的。本文通过实验来验证手动微调模型是否可以接近 GPT-3.5 的性能,而成本只是 GPT-3.5 的一小部分。有趣的是,本文确实做到了。
在 SQL 任务和 functional representation 任务上的结果对比,本文发现:
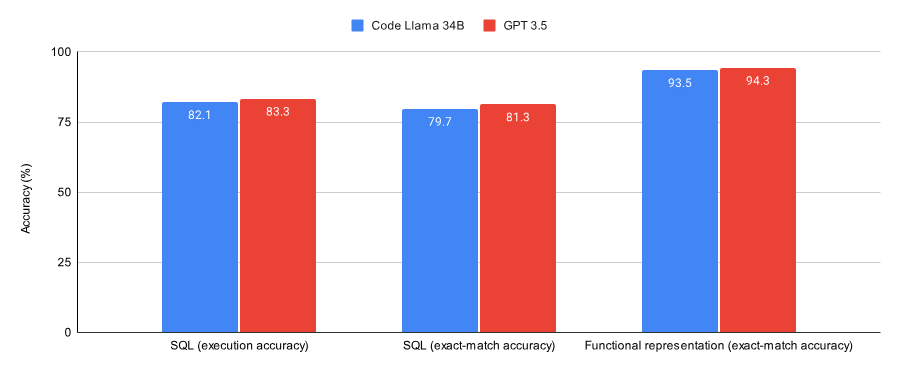
- GPT-3.5 在两个数据集(Spider 数据集的子集以及 Viggo functional representation 数据集)上都比经过 Lora 微调的 Code Llama 34B 表现略微好一点。
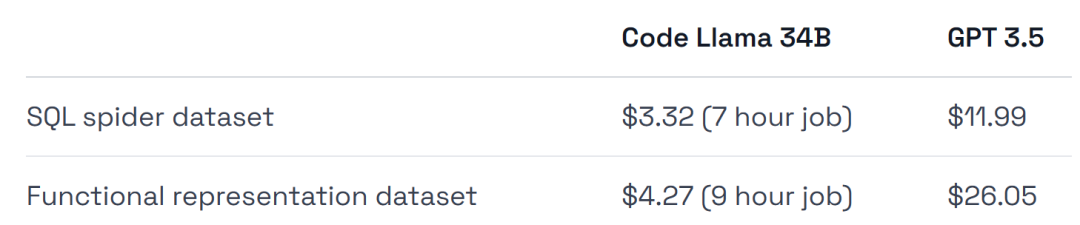
- GPT-3.5 的训练成本高出 4-6 倍,部署成本也更高。
本实验的结论之一是微调 GPT-3.5 适用于初始验证工作,但在那之后,像 Llama 2 这样的模型可能是最佳选择,简单总结一下:
- 如果你想验证微调是解决特定任务 / 数据集的正确方法,又或者想要一个完全托管的环境,那么微调 GPT-3.5。
- 如果想省钱、想从数据集中获取最大性能、想要在训练和部署基础设施方面具有更大的灵活性、又或者想要保留一些私有数据,那么就微调类似 Llama 2 的这种开源模型。
接下来我们看看,本文是如何实现的。
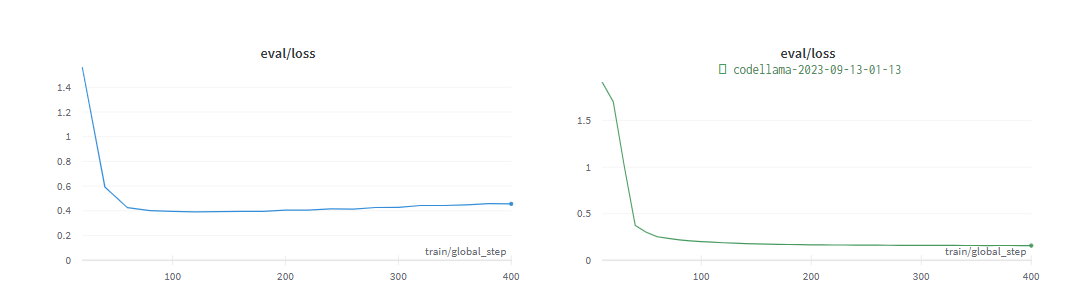
下图为 Code Llama 34B 和 GPT-3.5 在 SQL 任务和 functional representation 任务上训练至收敛的性能。结果表明,GPT-3.5 在这两个任务上都取得了更好的准确率。
在硬件使用上,实验使用的是 A40 GPU,每小时约 0.475 美元。
此外,实验选取了两个非常适合进行微调的数据集,Spider 数据集的子集以及 Viggo functional representation 数据集。
为了与 GPT-3.5 模型进行公平的比较,实验对 Llama 进行了最少超参数微调。
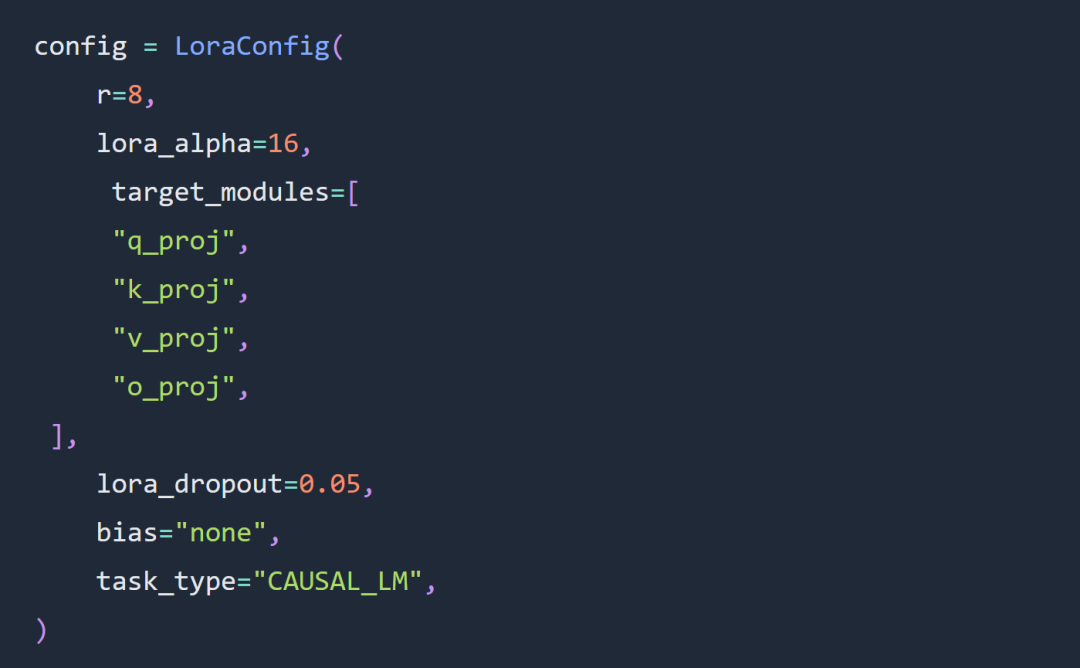
本文实验的两个关键选择是使用 Code Llama 34B 和 Lora 微调,而不是全参数微调。
实验在很大程度上遵循了有关 Lora 超参数微调的规则,Lora 适配器配置如下:
SQL 提示示例如下:
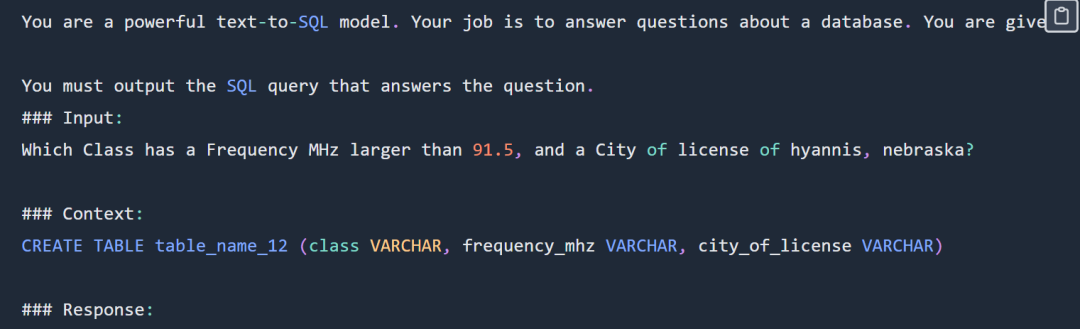
SQL 提示部分展示,完整提示请查看原博客
实验没有使用完整的 Spider 数据集,具体形式如下
department : Department_ID [ INT ] primary_key Name [ TEXT ] Creation [ TEXT ] Ranking [ INT ] Budget_in_Billions [ INT ] Num_Employees [ INT ] head : head_ID [ INT ] primary_key name [ TEXT ] born_state [ TEXT ] age [ INT ] management : department_ID [ INT ] primary_key management.department_ID = department.Department_ID head_ID [ INT ] management.head_ID = head.head_ID temporary_acting [ TEXT ]
实验选择使用 sql-create-context 数据集和 Spider 数据集的交集。为模型提供的上下文是一个 SQL 创建命令,如下所示:
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)
SQL 任务的代码和数据地址:https://github.com/samlhuillier/spider-sql-finetune
functional representation 提示的示例如下所示:
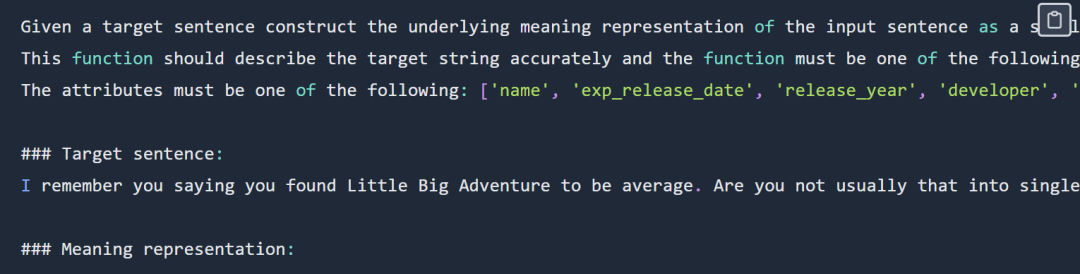
functional representation 提示部分展示,完整提示请查看原博客
输出如下所示:
verify_attribute(name[Little Big Adventure], rating[average], has_multiplayer[no], platforms[PlayStation])
评估阶段,两个实验很快就收敛了:
functional representation 任务代码和数据地址:https://github.com/samlhuillier/viggo-finetune
了解更多内容,请查看原博客。
以上是选择GPT-3.5、还是微调Llama 2等开源模型?综合比较后答案有了的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Vue.js 中字符串转对象用什么方法?
Apr 07, 2025 pm 09:39 PM
Vue.js 中字符串转对象用什么方法?
Apr 07, 2025 pm 09:39 PM
Vue.js 中字符串转对象时,首选 JSON.parse() 适用于标准 JSON 字符串。对于非标准 JSON 字符串,可根据格式采用正则表达式和 reduce 方法或解码 URL 编码字符串后再处理。根据字符串格式选择合适的方法,并注意安全性与编码问题,以避免 bug。
 mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
文章介绍了MySQL数据库的上手操作。首先,需安装MySQL客户端,如MySQLWorkbench或命令行客户端。1.使用mysql-uroot-p命令连接服务器,并使用root账户密码登录;2.使用CREATEDATABASE创建数据库,USE选择数据库;3.使用CREATETABLE创建表,定义字段及数据类型;4.使用INSERTINTO插入数据,SELECT查询数据,UPDATE更新数据,DELETE删除数据。熟练掌握这些步骤,并学习处理常见问题和优化数据库性能,才能高效使用MySQL。
 偏远的高级后端工程师(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
偏远的高级后端工程师(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
远程高级后端工程师职位空缺公司:Circle地点:远程办公职位类型:全职薪资:$130,000-$140,000美元职位描述参与Circle移动应用和公共API相关功能的研究和开发,涵盖整个软件开发生命周期。主要职责独立完成基于RubyonRails的开发工作,并与React/Redux/Relay前端团队协作。为Web应用构建核心功能和改进,并在整个功能设计过程中与设计师和领导层紧密合作。推动积极的开发流程,并确定迭代速度的优先级。要求6年以上复杂Web应用后端
 mysql安装后怎么优化数据库性能
Apr 08, 2025 am 11:36 AM
mysql安装后怎么优化数据库性能
Apr 08, 2025 am 11:36 AM
MySQL性能优化需从安装配置、索引及查询优化、监控与调优三个方面入手。1.安装后需根据服务器配置调整my.cnf文件,例如innodb_buffer_pool_size参数,并关闭query_cache_size;2.创建合适的索引,避免索引过多,并优化查询语句,例如使用EXPLAIN命令分析执行计划;3.利用MySQL自带监控工具(SHOWPROCESSLIST,SHOWSTATUS)监控数据库运行状况,定期备份和整理数据库。通过这些步骤,持续优化,才能提升MySQL数据库性能。
 Laravel的地理空间:互动图和大量数据的优化
Apr 08, 2025 pm 12:24 PM
Laravel的地理空间:互动图和大量数据的优化
Apr 08, 2025 pm 12:24 PM
利用地理空间技术高效处理700万条记录并创建交互式地图本文探讨如何使用Laravel和MySQL高效处理超过700万条记录,并将其转换为可交互的地图可视化。初始挑战项目需求:利用MySQL数据库中700万条记录,提取有价值的见解。许多人首先考虑编程语言,却忽略了数据库本身:它能否满足需求?是否需要数据迁移或结构调整?MySQL能否承受如此大的数据负载?初步分析:需要确定关键过滤器和属性。经过分析,发现仅少数属性与解决方案相关。我们验证了过滤器的可行性,并设置了一些限制来优化搜索。地图搜索基于城
 mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
MySQL启动失败的原因有多种,可以通过检查错误日志进行诊断。常见原因包括端口冲突(检查端口占用情况并修改配置)、权限问题(检查服务运行用户权限)、配置文件错误(检查参数设置)、数据目录损坏(恢复数据或重建表空间)、InnoDB表空间问题(检查ibdata1文件)、插件加载失败(检查错误日志)。解决问题时应根据错误日志进行分析,找到问题的根源,并养成定期备份数据的习惯,以预防和解决问题。
 Vue.js 如何将字符串类型的数组转换为对象数组?
Apr 07, 2025 pm 09:36 PM
Vue.js 如何将字符串类型的数组转换为对象数组?
Apr 07, 2025 pm 09:36 PM
总结:将 Vue.js 字符串数组转换为对象数组有以下方法:基本方法:使用 map 函数,适合格式规整的数据。高级玩法:使用正则表达式,可处理复杂格式,但需谨慎编写,考虑性能。性能优化:考虑大数据量,可使用异步操作或高效数据处理库。最佳实践:清晰的代码风格,使用有意义的变量名、注释,保持代码简洁。
 mysql 主键可以为 null
Apr 08, 2025 pm 03:03 PM
mysql 主键可以为 null
Apr 08, 2025 pm 03:03 PM
MySQL 主键不可以为空,因为主键是唯一标识数据库中每一行的关键属性,如果主键可以为空,则无法唯一标识记录,将会导致数据混乱。使用自增整型列或 UUID 作为主键时,应考虑效率和空间占用等因素,选择合适的方案。
