

行人轨迹预测有哪些有效的方法和普遍的Base方法?顶会论文分享!

轨迹预测近两年风头正猛,但大都聚焦于车辆轨迹预测方向,自动驾驶之心今天就为大家分享顶会NeurIPS上关于行人轨迹预测的算法—SHENet,在受限场景中人类的移动模式通常在一定程度上符合有限的规律。基于这个假设,SHENet通过学习隐含的场景规律来预测一个人的未来轨迹。文章已经授权自动驾驶之心原创!
笔者的个人理解
由于人类运动的随机性和主观性,当前预测一个人的未来轨迹仍然是一个具有挑战性的问题。 然而,由于场景限制(例如平面图、道路和障碍物)以及人与人或人与物体的交互性,在受限场景中人类的移动模式通常在一定程度上符合有限的规律。因此,在这种情况下,个人的轨迹也应该遵循其中一个规律。换句话说,一个人后来的轨迹很可能已经被其他人走过了。基于这个假设,本文的算法(SHENet)通过学习隐含的场景规律来预测一个人的未来轨迹。具体来说我们将场景中人和环境的过去动态所固有的规律性称为场景历史。进而将场景历史信息分为两类:历史群体轨迹和个体与环境的交互。为了利用这两种类型的信息进行轨迹预测,本文提出了一种新颖的框架场景历史挖掘网络(SHENet),其中以简单而有效的方法利用场景历史。特别是设计的两个组件:群体轨迹库模块,用于提取代表性群体轨迹作为未来路径的候选者;交叉模态交互模块,用于对个体过去轨迹与其周围环境之间的交互进行建模,以进行轨迹细化。 此外为了减轻由上述人体运动的随机性和主观性引起的真值轨迹的不确定性,SHENet将平滑度纳入训练过程和评估指标中。 最终我们在不同实验数据集上进行了验证,与SOTA方法相比,展示了卓越的性能。
介绍
人类轨迹预测(HTP)旨在从视频片段中预测目标人的未来路径。 这对于智能交通至关重要,因为它使车辆能够提前感知行人的状态,从而避免潜在的碰撞。 具有HTP功能的监控系统可以协助安全人员预测嫌疑人可能的逃跑路径。 尽管近年来已经做了很多工作,但很少有足够可靠和可推广到现实世界场景中的应用,这主要是由于任务的两个挑战:随机性和人体运动的主观性。 然而,在受限的现实世界场景中,挑战并非绝对棘手。 如图 1 所示,给定该场景中先前捕获的视频,目标人的未来轨迹(红色框)变得更加可预测,因为人类的移动模式通常符合该场景中目标人将遵循的几个基本规律。 因此,要预测轨迹,我们首先需要了解这些规律。 我们认为,这些规律性隐含地编码在历史人类轨迹(图 1 左)、个体过去的轨迹、周围环境以及它们之间的相互作用(图 1 右)中,我们将其称为场景历史。

图 1:利用场景历史的示意图:历史群体轨迹和个体环境交互,用于人类轨迹预测。
我们将历史信息分为两类:历史群体轨迹(HGT)和个体与环境相互作用(ISI)。 HGT是指一个场景中所有历史轨迹的群体代表。 使用HGT的原因是,鉴于场景中的新目标人,由于上述随机性,他/她的路径更有可能与其中一个群体轨迹比历史轨迹的任何单个实例具有更多相似性、主观性、规律性。 然而,群体轨迹与个体过去的状态和相应环境的相关性较小,也会影响个体未来的轨迹。 ISI 需要通过提取上下文信息来更全面地利用历史信息。 现有的方法很少考虑个体过去轨迹和历史轨迹之间的相似性。 大多数尝试仅探索个体与环境的交互,其中花费了大量精力对个体轨迹、环境的语义信息以及它们之间的关系进行建模。 尽管MANTRA使用以重构方式训练的编码器来对相似性进行建模,而 MemoNet通过存储历史轨迹的意图来简化相似性,但它们都在实例级别而不是组级别上执行相似性计算,从而使其对受过训练的编码器的能力敏感。 基于上述分析,我们提出了一个简单而有效的框架,场景历史挖掘网络(SHENet),联合利用 HGT 和 ISI 进行 HTP。 特别是,该框架由两个主要组成部分组成:(i)群体轨迹库(GTB)模块,以及(ii)跨模式交互(CMI)模块。 GTB从所有历史个体轨迹中构建代表性群体轨迹,并为未来轨迹预测提供候选路径。 CMI 对观察到的个体轨迹和周围环境分别进行编码,并使用跨模态转换器对它们的交互进行建模,以细化搜索到的候选轨迹。
此外,为了减轻上述两个特征(即随机性和主观性)的不确定性,我们在训练过程和当前评估指标,平均和最终位移误差(即 ADE 和 FDE)中引入曲线平滑(CS),从而得到两个新指标 CS-ADE 和 CS-FDE。 此外,为了促进 HTP 研究的发展,我们收集了一个具有不同运动模式的新的具有挑战性的数据集,名为 PAV。 该数据集是通过从 MOT15 数据集中选择具有固定摄像机视图和复杂人体运动的视频来获得的。
这项工作的贡献可以总结如下:1)我们引入群体历史来搜索 HTP 的个体轨迹。 2)我们提出了一个简单而有效的框架,SHENet,联合利用两种类型的场景历史(即历史群体轨迹和个体与环境的交互)进行HTP。 3)我们构建了一个新的具有挑战性的数据集PAV; 此外,考虑到人类移动模式的随机性和主观性,提出了一种新颖的损失函数和两种新的指标,以实现更好的基准 HTP 性能。 4)我们对ETH、UCY和PAV进行了全面的实验,以证明SHENet的优越性能以及每个组件的功效。
相关工作
单模态方法 单模态方法依赖于从过去的轨迹中学习个体运动的规律性来预测未来的轨迹。 例如,Social LSTM通过social pooling模块对个体轨迹之间的交互进行建模。 STGAT使用注意力模块来学习空间交互并为邻居分配合理的重要性。 PIE 使用时间注意力模块来计算每个时间步观察到的轨迹的重要性。
多模态方法 此外,多模态方法还考察了环境信息对 HTP 的影响。 SS-LSTM提出了一个场景交互模块来捕获场景的全局信息。 Trajectron++使用图结构对轨迹进行建模,并与环境信息和其他个体进行交互。 MANTRA利用外部存储器来建模长期依赖关系。 它将历史单智能体轨迹存储在内存中,并对环境信息进行编码,以从该内存中细化搜索到的轨迹。
与之前工作的区别 单模态和多模态方法都使用场景历史的单个或部分方面,而忽略历史组轨迹。 在我们的工作中,我们以更全面的方式整合场景历史信息,并提出专用模块来分别处理不同类型的信息。 我们的方法与之前的工作,特别是基于内存的方法和基于聚类的方法之间的主要区别如下:i)MANTRA 和MemoNet 考虑历史个体轨迹,而我们提出的SHENet关注历史群体轨迹,这在不同场景下更具有普遍性。 ii) 还有一部分工作将人-邻居分组以进行轨迹预测;将轨迹聚类为固定数量的类别以进行轨迹分类; 我们的 SHENet 生成代表性轨迹作为个人轨迹预测的参考。
方法
整体介绍
所提出的场景历史挖掘网络(SHENet)的架构如图 2 所示,它由两个主要组件组成:群组轨迹库模块(GTB)和交叉模态交互模块(CMI)。 形式上,给定该场景的观察视频中的所有轨迹 、 场景图像以及目标人 在最后时间步中的过去轨迹,其中表示第 p 个人在时间步 t 的位置, SHENet 要求预测行人在接下来的帧中的未来位置,使得尽可能接近真值轨迹。 提出的 GTB 首先将 压缩为代表群体轨迹。 然后,将观测到的轨迹作为key,在中搜索最接近的代表群体轨迹,作为候选未来轨迹 。 同时,将过去的轨迹和场景图像分别传到轨迹编码器和场景编码器,以分别产生轨迹特征和场景特征。 编码后的特征被输入到交叉模态transformer中,以学习和真值轨迹之间的偏移 。 通过将 添加到 ,我们得到最终的预测 。 在训练阶段,如果到的距离高于阈值,则人的轨迹(即和)将被添加到轨迹库中。 训练完成后,bank被固定用于推理。
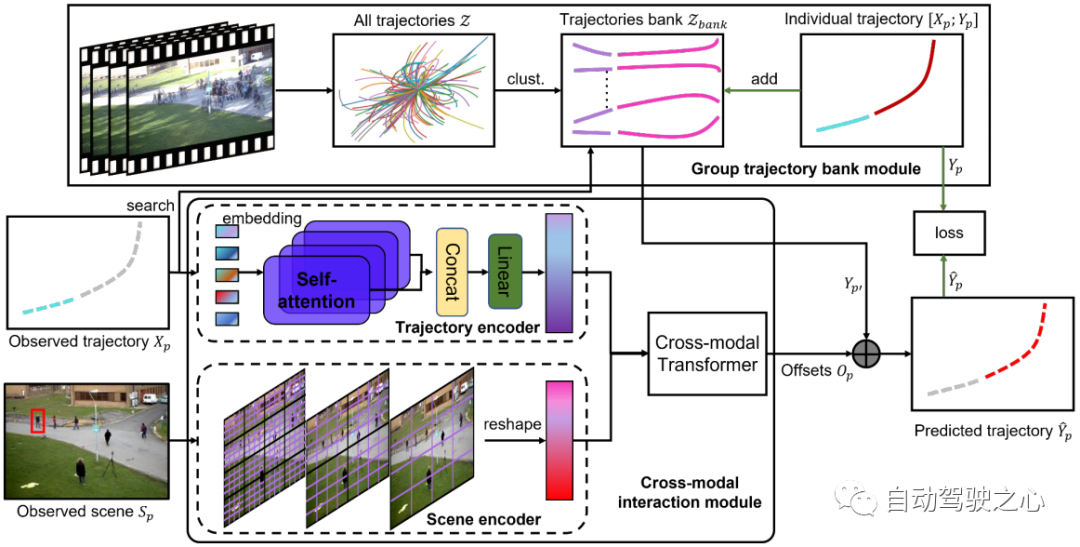
图 2:SHENet 的架构由两个组件组成:群组轨迹库模块 (GTB) 和跨模态交互模块 (CMI)。 GTB将所有历史轨迹聚类成一组代表性组轨迹,并为最终轨迹预测提供候选。 在训练阶段,GTB可以根据预测轨迹的误差,将目标人的轨迹纳入群体轨迹库中,以扩展表达能力。 CMI将目标人的过去轨迹和观察到的场景分别作为轨迹编码器和场景编码器的输入进行特征提取,然后通过跨模态转换器有效地对过去轨迹与其周围环境之间的交互进行建模并进行细化提供候选轨迹。
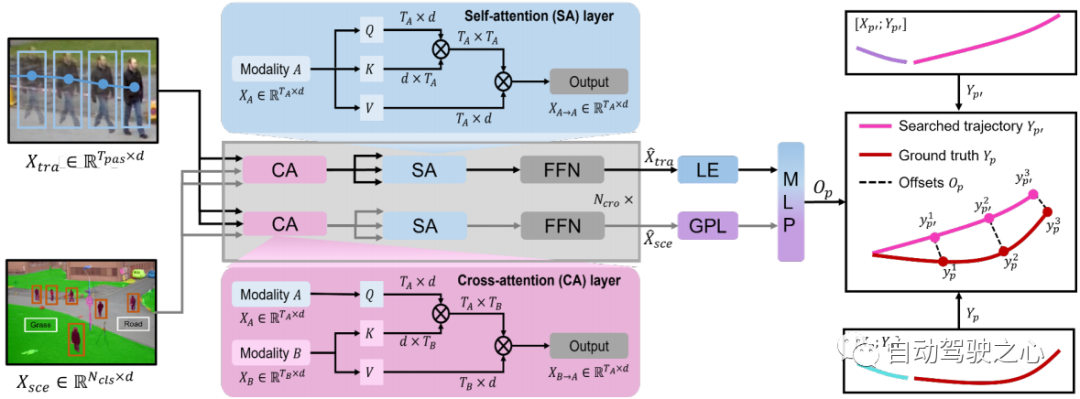
图 3:交叉模态transformer图示。 轨迹特征和场景特征被输入到交叉模态transformer中,以学习搜索轨迹和真值轨迹之间的偏移。
群组轨迹库模
群体轨迹库模块(GTB)用于构建场景中具有代表性的群体轨迹。 GTB的核心功能是bank初始化、轨迹搜索和轨迹更新。
轨迹库初始化 由于大量记录的轨迹存在冗余,我们不是简单地使用它们,而是生成一组稀疏且有代表性的轨迹作为轨迹库的初始值。 具体来说,我们将训练数据中的轨迹表示为 并将每个 分成一对观测轨迹 和未来轨迹 ,从而将 分成观测集 以及相应的未来集合 。 然后,我们计算,中每对轨迹之间的欧氏距离,并通过K-medoids聚类算法获得轨迹簇。 的初始成员是属于同一集群的轨迹的平均值(参见算法 1,步骤 1)。中的每条轨迹都代表了一群人的移动模式。
轨迹搜索和更新 在组轨迹库中,每个轨迹都可以被视为过去-未来对。 在数值上, ,其中 代表过去轨迹和未来轨迹的组合, 是 中过去未来对的数量。 给定轨迹 ,我们使用观察到的 作为关键来计算其与 中过去轨迹 的相似度得分,并找到代表性轨迹 根据最大相似度得分(参见算法 1,步骤 2)。 相似度函数可以表示为:
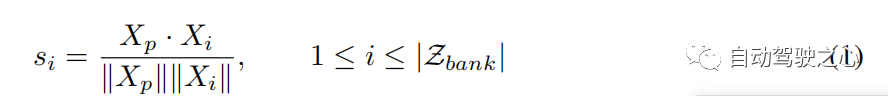
通过将偏移量 (参见公式 2)添加到代表性轨迹 中,我们获得了被观察者的预测轨迹 (参见图 2)。 虽然初始轨迹库在大多数情况下效果很好,但为了提高库 的泛化性(参见算法 1,步骤 3),我们根据距离阈值 θ 决定是否更新 。
跨模态交互模块
该模块重点关注个体过去轨迹与环境信息之间的交互。 它由两个单模态编码器组成,分别用于学习人体运动和场景信息,以及一个跨模态转换器来建模它们的交互。
轨迹编码器 轨迹编码器采用来自 Transformer 网络 的多头注意力结构,其具有 自注意力(SA)层。 SA 层以 的大小捕获不同时间步长的人体运动,并将运动特征从维度 投影到 ,其中 是轨迹编码器的嵌入维度。 因此,我们使用轨迹编码器获得人体运动表示:。
场景编码器 由于预训练的 Swin Transformer在特征表示方面具有引人注目的性能,我们采用它作为场景编码器。 它提取大小为 的场景语义特征,其中 (预训练场景编码器中的 )是语义类的数量,例如人和道路, 和 是空间分辨率。 为了使后续模块能够方便地融合运动表示和环境信息,我们将语义特征从大小()重改为(),并通过多层感知层将它们从维度()投影到() 。 结果,我们使用场景编码器 获得场景表示 。
交叉模态Transformer 单模态编码器从其自身模态中提取特征,忽略人体运动和环境信息之间的相互作用。 具有 层的交叉模态transformer旨在通过学习这种交互来细化候选轨迹 (参见第 3.2 节)。 我们采用双流结构:一个用于捕获受环境信息约束的重要人体运动,另一个用于挑选与人体运动相关的环境信息。 交叉注意 (CA) 层和自注意 (SA) 层是跨模态转换器的主要组成部分(见图 3)。 为了捕获受环境影响的重要人体运动并获取与运动相关的环境信息,CA层将一种模态视为query,将另一种模态视为与两种模态交互的key和value。SA 层用于促进更好的内部连接,计算场景约束运动或运动相关环境信息中元素(query)与其他元素(key)之间的相似性。 因此,我们通过交叉模态transformer 获得多式联运表示()。 为了预测搜索轨迹 和真实轨迹 之间的偏移 ,我们采用 的最后一个元素 (LE) 和全局池化层 (GPL) 之后的输出 的 。 偏移量 可以表述如下:
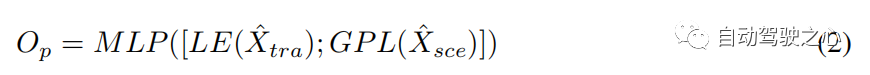
其中 [; ] 表示向量串联,MLP 为多层感知层。
我们端到端地训练 SHENet 的整体框架,以最小化目标函数。 在训练过程中,由于场景编码器已经在ADE20K 上进行了预训练,因此我们冻结其分割部分并更新MLP头的参数(参见第3.3节)。 遵循现有的工作,我们计算了 ETH/UCY 数据集上的预测轨迹与真值轨迹之间的均方误差(MSE): 。
在更具挑战性的 PAV 数据集中,我们使用曲线平滑(CS)回归损失,这有助于减少个体偏差的影响。 它计算轨迹平滑后的 MSE。 CS损失可以表述如下:
其中CS代表曲线平滑的函数[2]。

实验
实验设置
数据集 我们在 ETH、UCY 、PAV 和斯坦福无人机数据集 (SDD)数据集上评估我们的方法。单模态方法仅关注轨迹数据,然而,多模态方法需要考虑场景信息。
与 ETH/UCY 数据集相比,PAV 更具挑战性,具有多种运动模式,包括 PETS09-S2L1 (PETS) 、ADL-Rundle-6 (ADL) 和 Venice-2 (VENICE),这些数据被捕获来自静态摄像机并为 HTP 任务提供足够的轨迹。 我们将视频分为训练集(80%)和测试集(20%),PETS/ADL/VENICE 分别包含 2,370/2,935/4,200 个训练序列和 664/306/650 个测试序列。 我们使用 个观察帧来预测未来 帧,这样我们就可以比较不同方法的长时预测结果。
与 ETH/UCY 和 PAV 数据集不同,SDD 是在大学校园中鸟瞰捕获的大规模数据集。 它由多个交互主体(例如行人、骑自行车的人和汽车)和不同的场景(例如人行道和十字路口)组成。 按照之前的工作,我们使用过去的 8 帧来预测未来的 12 帧。
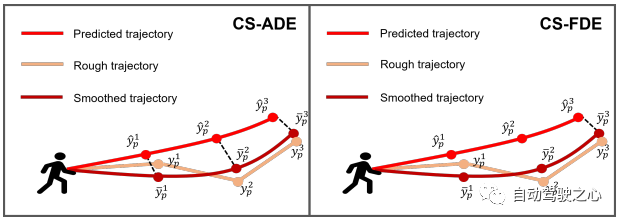
图 4:我们提出的指标 CS-ADE 和 CS-FDE 的图示。

图 5:曲线平滑后一些样本的可视化。
评估指标 对于ETH和UCY数据集,我们采用HTP的标准指标:平均位移误差(ADE)和最终位移误差(FDE)。 ADE 是所有时间步上预测轨迹与真值轨迹之间的平均 误差,FDE 是最终时间步预测轨迹与真值轨迹之间的 误差。 PAV 中的轨迹存在一些抖动现象(例如急转弯)。 因此,合理的预测可能会产生与使用传统指标 ADE 和 FDE 进行不切实际的预测大致相同的误差(见图 7(a))。 为了关注轨迹本身的模式和形状,并减少随机性和主观性的影响,我们提出了CS-Metric:CS-ADE和CS-FDE(如图4所示)。 CS-ADE 计算如下:
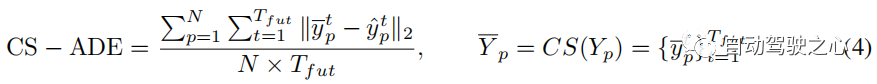
其中CS是曲线平滑函数,定义与3.4节中的Lcs相同。 与CS-ADE类似,CS-FDE计算轨迹平滑后的最终位移误差:
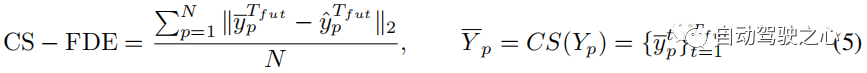
图 5 显示了训练数据中的一些样本,将粗糙的真值轨迹转换为平滑的轨迹。
实现细节 在SHENet中,组轨迹库的初始大小设置为。 轨迹编码器和场景编码器都有 4 个自注意力(SA)层。 跨模态 Transformer 有 6 个 SA 层和交叉注意(CA)层。 我们将所有嵌入维度设置为 512。对于轨迹编码器,它学习大小为 的人体运动信息(ETH/UCY 中 ,PAV 中 )。 对于场景编码器,它输出大小为 150 × 56 × 56 的语义特征。我们将大小从 150 × 56 × 56 改为 150 × 3136,并将它们从维度 150 × 3136 投影到 150 × 512。我们训练 在 4 个 NVIDIA Quadro RTX 6000 GPU 上建立 100 个周期的模型,并使用固定学习率 1e − 5 的 Adam 优化器。
消融实验
在表 1 中,我们评估了 SHENet 的每个组件,包括组轨迹库(GTB)模块和跨模态交互(CMI)模块,该模块包含轨迹编码器(TE)、场景编码器(SE)和跨模态交互(CMI)模块。
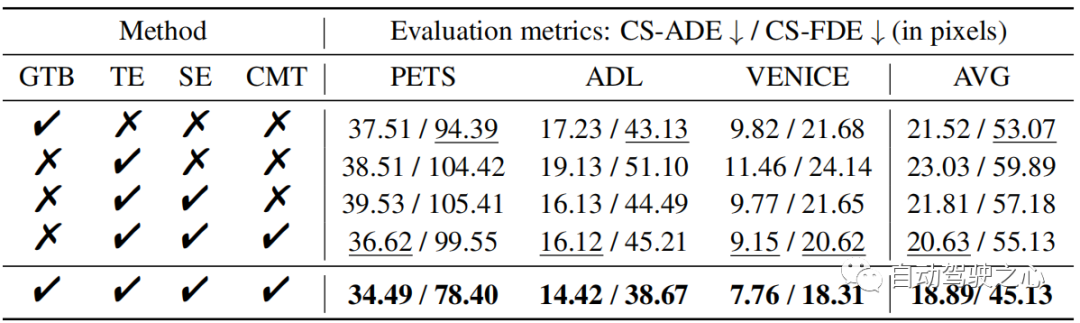
GTB 的影响 我们首先研究 GTB 的性能。 与 CMI(即 TE、SE 和 CMT)相比,GTB 在 PETS 上的 FDE 提高了 21.2%,这是一个显着的改进,说明了 GTB 的重要性。 然而,仅靠 GTB(表 1 第 1 行)是不够的,甚至比 CMI 的表现还要差一些。 因此,我们探讨了CMI模块中各个部分的作用。TE 和 SE 的影响 为了评估 TE 和 SE 的性能,我们将从 TE 中提取的轨迹特征和从 SE 中提取的场景特征连接在一起(表 1 中的第 3 行),并以较小的运动提高 ADL 和 VENICE 的性能(与 单独使用 TE。 这表明将环境信息纳入轨迹预测可以提高结果的准确性。CMT 的效果 与表 1 的第三行相比,CMT(表 1 的第 4 行)可以显着提高模型性能。 值得注意的是,它的性能优于 PETS 上串联的 TE 和 SE,ADE 提高了 7.4%。 与单独的 GTB 相比,完整的 CMI 比 ADE 平均提高了 12.2%。
与SOTA比较
在 ETH/UCY 数据集上,将我们的模型与最先进的方法进行比较:SS-LSTM、Social-STGCN、MANTRA、AgentFormer、YNet。 结果总结在表 2 中。我们的模型将平均 FDE 从 0.39 降低到 0.36,与最先进的方法 YNet 相比,提高了 7.7%。 特别是,当轨迹发生较大移动时,我们的模型在 ETH 上显着优于以前的方法,其 ADE 和 FDE 分别提高了 12.8% 和 15.3%。
表 2:ETH/UCY 数据集上最先进 (SOTA) 方法的比较。 * 表示我们使用比单模态方法更小的集合。 采用前20中最好的方式进行评估。
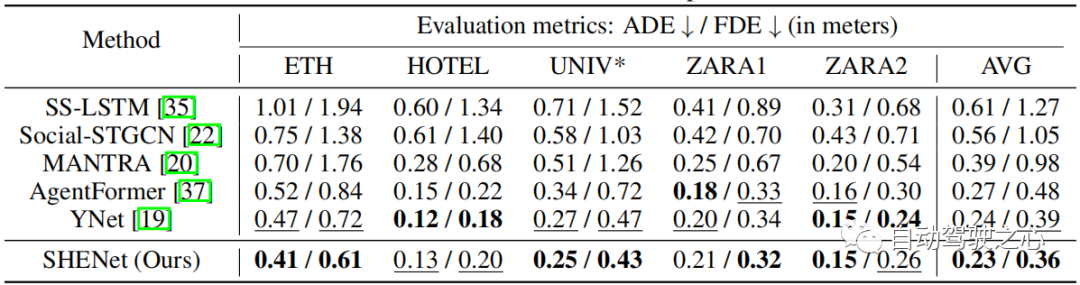
表 3:在 PAV 数据集上与 SOTA 方法的比较。
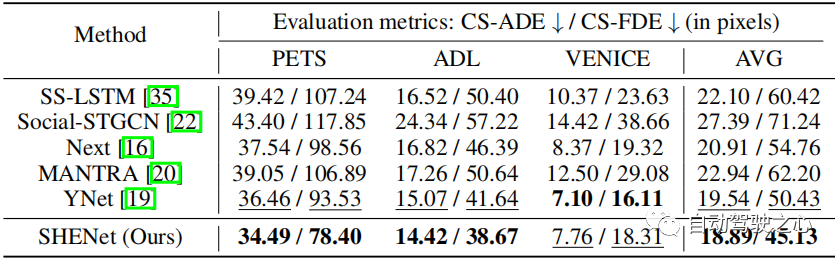
为了评估我们的模型在长期预测中的性能,我们在 PAV 上进行了实验,其中每条轨迹 个观察帧, 个未来帧。 表 3 显示了与之前的 HTP 方法的性能比较:SS-LSTM、Social-STGCN、Next、MANTRA、YNet。 与 YNet 的最新结果相比,所提出的 SHENet CS-ADE 和 CS-FDE 平均分别提高了 3.3% 和 10.5%。 由于 YNet 预测轨迹的热图,因此当轨迹有小幅运动时(例如 VENICE),它的表现会更好一些。 尽管如此,我们的方法在 VENICE 中仍然具有竞争力,并且在具有较大运动和交叉点的 PETS 上比其他方法要好得多。 特别是,与 YNet 相比,我们的方法在 PETS 上将 CS-FDE 提高了 16.2%。 我们还在传统的 ADE/FDE 指标取得了巨大的进步。
分析
距离阈值 θ θ用于确定轨迹库的更新。 θ的典型值根据轨迹长度设定。 当真值轨迹以像素计越长时,预测误差的绝对值通常越大。 然而,它们的相对误差是可比的。 因此,当误差收敛时,θ被设置为训练误差的75%。 实验中,我们在 PETS 中设置 θ = 25,在 ADL 中设置 θ = 6。 从实验结果得到“75%的训练误差”,如表4所示。
表 4:PAV 数据集上不同参数 θ 的比较。 结果是三种情况的平均值。
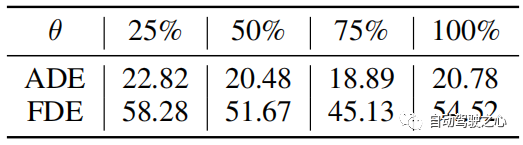
表 5:PAV 数据集上初始簇数 K 的比较。

K 中心点中的簇数 我们研究了设置不同数量的初始簇K的效果,如表5所示。 我们可以注意到,初始簇数对预测结果并不敏感,尤其是当初始簇数为 24-36 时。 因此,我们在实验中可以将K设置为32。
Bank复杂度分析 搜索和更新的时间复杂度分别为O(N)和O(1)。 它们的空间复杂度是O(N)。 群体轨迹数N≤1000。聚类过程的时间复杂度为ββ,空间复杂度为ββ。 β 是聚类轨迹的数量。 是聚类的数量, 是聚类方法的迭代次数。

图 6:我们的方法和最先进方法的定性可视化。 蓝线是观察到的轨迹。 红线和绿线显示预测轨迹和真实轨迹。

图 7:不使用/使用 CS 的定性可视化。
定性结果
图 6 展示了 SHENet 和其他方法的定性结果。 相比之下,我们惊讶地注意到,在一个人走到路边然后折返(绿色曲线)的极具挑战性的情况下,所有其他方法都不能很好地处理,而我们提出的 SHENet 仍然可以处理它。 这应该归功于我们专门设计的历史群体轨迹库模块的作用。 此外,与基于记忆的方法 MANTRA [20] 相比,我们搜索群体的轨迹,而不仅仅是个体。 这更加通用,可以应用于更具挑战性的场景。 图 7 包括 YNet 和我们的 SHENet 的定性结果,不带/带曲线平滑 (CS)。 第一行显示使用 MSE 损失 的结果。 受过去带有一些噪声的轨迹(例如突然和急转弯)的影响,YNet的预测轨迹点聚集在一起,不能呈现明确的方向,而我们的方法可以根据历史群体轨迹提供潜在的路径。 这两个预测在视觉上是不同的,但数值误差 (ADE/FDE) 大致相同。相比之下,我们提出的 CS 损失 的定性结果如图 7 的第二行所示。可以看到,提出的 CS 显着降低了随机性和主观性的影响,并通过YNet 和我们的方法产生了合理的预测。
结论
本文提出了 SHENet,这是一种充分利用 HTP 场景历史的新颖方法。 SHENet 包括一个 GTB 模块,用于根据所有历史轨迹构建一个群体轨迹库,并从该库中检索被观察者的代表性轨迹;还包括一个 CMI 模块(在人体运动和环境信息之间相互作用)来细化该代表性轨迹。 我们在 HTP 基准上实现了 SOTA 性能,并且我们的方法在具有挑战性的场景中展示了显着的改进和通用性。 然而,当前框架中仍然存在一些尚未探索的方面,例如bank构建过程目前仅关注人体运动。 未来的工作包括使用交互信息(人体运动和场景信息)进一步探索轨迹库。

原文链接:https://mp.weixin.qq.com/s/GE-t4LarwXJu2MC9njBInQ
以上是行人轨迹预测有哪些有效的方法和普遍的Base方法?顶会论文分享!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Windows 11 上的智能应用控制:如何打开或关闭它
Jun 06, 2023 pm 11:10 PM
Windows 11 上的智能应用控制:如何打开或关闭它
Jun 06, 2023 pm 11:10 PM
智能应用控制是Windows11中非常有用的工具,可帮助保护你的电脑免受可能损害数据的未经授权的应用(如勒索软件或间谍软件)的侵害。本文将解释什么是智能应用控制、它是如何工作的,以及如何在Windows11中打开或关闭它。什么是Windows11中的智能应用控制?智能应用控制(SAC)是Windows1122H2更新中引入的一项新安全功能。它与MicrosoftDefender或第三方防病毒软件一起运行,以阻止可能不必要的应用,这些应用可能会减慢设备速度、显示意外广告或执行其他意外操作。智能应用
 五官乱飞,张嘴、瞪眼、挑眉,AI都能模仿到位,视频诈骗要防不住了
Dec 14, 2023 pm 11:30 PM
五官乱飞,张嘴、瞪眼、挑眉,AI都能模仿到位,视频诈骗要防不住了
Dec 14, 2023 pm 11:30 PM
如此强大的AI模仿能力,真的防不住,完全防不住。现在AI的发展已经达到了这种程度吗?你前脚让自己的五官乱飞,后脚,一模一样的表情就被复现出来,瞪眼、挑眉、嘟嘴,不管多么夸张的表情,都模仿的非常到位。加大难度,让眉毛挑的再高些,眼睛睁的再大些,甚至连嘴型都是歪的,虚拟人物头像也能完美复现表情。当你在左侧调整参数时,右侧的虚拟头像也会相应地改变动作给嘴巴、眼睛一个特写,模仿的不能说完全相同,只能说表情一模一样(最右边)。这项研究来自慕尼黑工业大学等机构,他们提出了GaussianAvatars,这种
 MotionLM:多智能体运动预测的语言建模技术
Oct 13, 2023 pm 12:09 PM
MotionLM:多智能体运动预测的语言建模技术
Oct 13, 2023 pm 12:09 PM
本文经自动驾驶之心公众号授权转载,转载请联系出处。原标题:MotionLM:Multi-AgentMotionForecastingasLanguageModeling论文链接:https://arxiv.org/pdf/2309.16534.pdf作者单位:Waymo会议:ICCV2023论文思路:对于自动驾驶车辆安全规划来说,可靠地预测道路代理未来行为是至关重要的。本研究将连续轨迹表示为离散运动令牌序列,并将多智能体运动预测视为语言建模任务。我们提出的模型MotionLM具有以下几个优点:首
 你知道程序员再过几年会没落?
Nov 08, 2023 am 11:17 AM
你知道程序员再过几年会没落?
Nov 08, 2023 am 11:17 AM
《ComputerWorld》杂志曾经写过一篇文章,说“编程到1960年就会消失”,因为IBM开发了一种新语言FORTRAN,这种新语言可以让工程师写出他们所需的数学公式,然后提交给计算机运行,所以编程就会终结。图片又过了几年,我们听到了一种新说法:任何业务人员都可以使用业务术语来描述自己的问题,告诉计算机要做什么,使用这种叫做COBOL的编程语言,公司不再需要程序员了。后来,据说IBM开发出了一门名为RPG的新编程语言,可以让员工填写表格并生成报告,因此大部分企业的编程需求都可以通过它来完成图
 GR-1傅利叶智能通用人形机器人即将开始预售!
Sep 27, 2023 pm 08:41 PM
GR-1傅利叶智能通用人形机器人即将开始预售!
Sep 27, 2023 pm 08:41 PM
身高1.65米,体重55公斤,全身44个自由度,能够快速行走、敏捷避障、稳健上下坡、抗冲击干扰的人形机器人,现在可以带回家了!傅利叶智能的通用人形机器人GR-1已开启预售机器人大讲堂傅利叶智能FourierGR-1通用人形机器人现已开放预售。GR-1拥有高度仿生的躯干构型和拟人化的运动控制,全身44个自由度,具备行走、避障、越障、上下坡、抗干扰、适应不同路面等运动能力,是通用人工智能的理想载体。官网预售页面:www.fftai.cn/order#FourierGR-1#傅利叶智能需要进行改写的内
 华为将在智能穿戴领域推出玄玑感知系统 可根据心率评估用户情绪状态
Aug 29, 2024 pm 03:30 PM
华为将在智能穿戴领域推出玄玑感知系统 可根据心率评估用户情绪状态
Aug 29, 2024 pm 03:30 PM
近日,华为宣布将于9月推出一款搭载玄玑感知系统的全新智能穿戴新品,预计为华为的最新智能手表。该新品将集成先进的情绪健康监测功能,玄玑感知系统以其六大特性——准确性、全面性、快速性、灵活性、开放性和延展性——为用户提供全方位的健康评估。系统采用超感知模组,优化了多通道光路架构技术,大幅提升了心率、血氧和呼吸率等基础指标的监测精度。此外,玄玑感知系统还拓展了基于心率数据的情绪状态研究,不仅限于生理指标,还能评估用户的情绪状态和压力水平,支持超过60项运动健康指标监测,涵盖心血管、呼吸、神经、内分泌、
 行人轨迹预测有哪些有效的方法和普遍的Base方法?顶会论文分享!
Oct 17, 2023 am 11:13 AM
行人轨迹预测有哪些有效的方法和普遍的Base方法?顶会论文分享!
Oct 17, 2023 am 11:13 AM
轨迹预测近两年风头正猛,但大都聚焦于车辆轨迹预测方向,自动驾驶之心今天就为大家分享顶会NeurIPS上关于行人轨迹预测的算法—SHENet,在受限场景中人类的移动模式通常在一定程度上符合有限的规律。基于这个假设,SHENet通过学习隐含的场景规律来预测一个人的未来轨迹。文章已经授权自动驾驶之心原创!笔者的个人理解由于人类运动的随机性和主观性,当前预测一个人的未来轨迹仍然是一个具有挑战性的问题。然而,由于场景限制(例如平面图、道路和障碍物)以及人与人或人与物体的交互性,在受限场景中人类的移动模式通
 一文读懂智能汽车滑板底盘
May 24, 2023 pm 12:01 PM
一文读懂智能汽车滑板底盘
May 24, 2023 pm 12:01 PM
01什么是滑板底盘所谓滑板式底盘,即将电池、电动传动系统、悬架、刹车等部件提前整合在底盘上,实现车身和底盘的分离,设计解耦。基于这类平台,车企可以大幅降低前期研发和测试成本,同时快速响应市场需求打造不同的车型。尤其是无人驾驶时代,车内的布局不再是以驾驶为中心,而是会注重空间属性,有了滑板式底盘,可以为上部车舱的开发提供更多的可能。如上图,当然我们看滑板底盘,不要上来就被「噢,就是非承载车身啊」的第一印象框住。当年没有电动车,所以没有几百公斤的电池包,没有能取消转向柱的线传转向系统,没有线传制动系
