

MiniGPT-4升级到MiniGPT-v2了,不用GPT-4照样完成多模态任务

几个月前,来自 KAUST(沙特阿卜杜拉国王科技大学)的几位研究者提出了一个名为 MiniGPT-4 的项目,它能提供类似 GPT-4 的图像理解与对话能力。
例如 MiniGPT-4 能够回答下图中出现的景象:「图片描述的是生长在冰冻湖上的一株仙人掌。仙人掌周围有巨大的冰晶,远处还有白雪皑皑的山峰……」假如你接着询问这种景象能够发生在现实世界中吗?MiniGPT-4 给出的回答是这张图片在现实世界中并不常见,并给出了原因。

短短几个月过去了,近日,KAUST 团队以及来自 Meta 的研究者宣布,他们将 MiniGPT-4 重磅升级到了 MiniGPT-v2 版本。

论文地址:https://arxiv.org/pdf/2310.09478.pdf
论文主页:https://minigpt-v2.github.io/
Demo: https://minigpt-v2.github.io/
具体而言,MiniGPT-v2 可以作为一个统一的接口来更好地处理各种视觉 - 语言任务。同时,本文建议在训练模型时对不同的任务使用唯一的识别符号,这些识别符号有利于模型轻松的区分每个任务指令,并提高每个任务模型的学习效率。
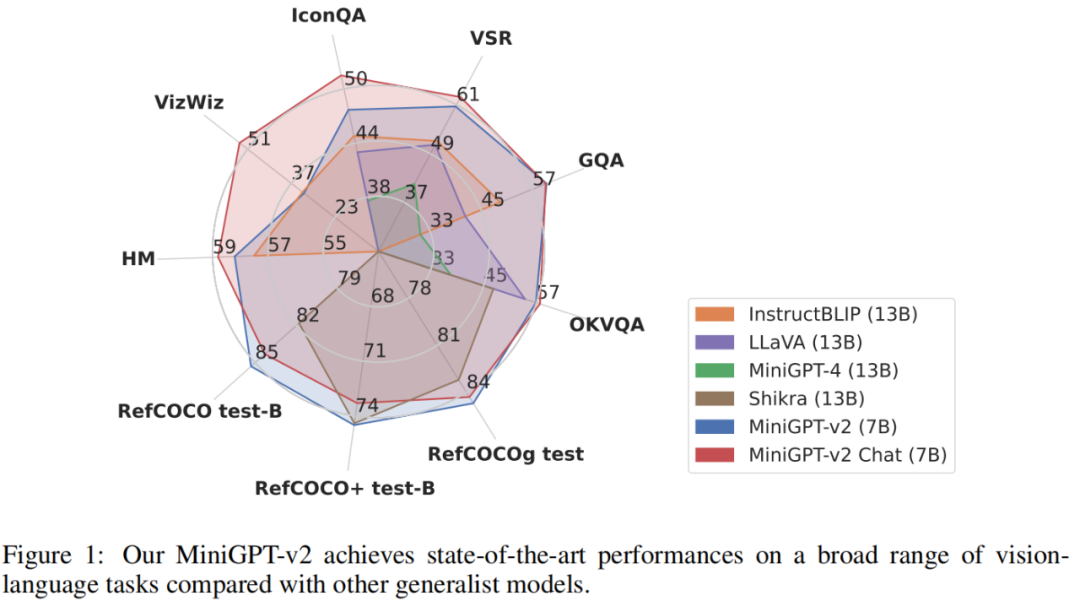
为了评估 MiniGPT-v2 模型的性能,研究者对不同的视觉 - 语言任务进行了广泛的实验。结果表明,与之前的视觉 - 语言通用模型(例如 MiniGPT-4、InstructBLIP、 LLaVA 和 Shikra)相比,MiniGPT-v2 在各种基准上实现了 SOTA 或相当的性能。例如 MiniGPT-v2 在 VSR 基准上比 MiniGPT-4 高出 21.3%,比 InstructBLIP 高出 11.3%,比 LLaVA 高出 11.7%。
下面我们通过具体的示例来说明 MiniGPT-v2 识别符号的作用。
例如,通过加 [grounding] 识别符号,模型可以很容易生成一个带有空间位置感知的图片描述:

通过添加 [detection] 识别符号,模型可以直接提取输入文本里面的物体并且找到它们在图片中的空间位置:

框出图中的一个物体,通过加 [identify] ,可以让模型直接识别出来物体的名字:
 通过加 [refer] 和一个物体的描述,模型可以直接帮你找到物体对应的空间位置:
通过加 [refer] 和一个物体的描述,模型可以直接帮你找到物体对应的空间位置:

你也可以不加任何任务识别符合,和图片进行对话:

模型的空间感知也变得更强,可以直接问模型谁出现在图片的左面,中间和右面:

方法介绍
MiniGPT-v2 模型架构如下图所示,它由三个部分组成:视觉主干、线性投影层和大型语言模型。

视觉主干:MiniGPT-v2 采用 EVA 作为主干模型,并且在训练期间会冻结视觉主干。训练模型的图像分辨率为 448x448 ,并插入位置编码来扩展更高的图像分辨率。
线性投影层:本文旨在将所有的视觉 token 从冻结的视觉主干投影到语言模型空间中。然而,对于更高分辨率的图像(例如 448x448),投影所有的图像 token 会导致非常长的序列输入(例如 1024 个 token),显着降低了训练和推理效率。因此,本文简单地将嵌入空间中相邻的 4 个视觉 token 连接起来,并将它们一起投影到大型语言模型的同一特征空间中的单个嵌入中,从而将视觉输入 token 的数量减少了 4 倍。
大型语言模型:MiniGPT-v2 采用开源的 LLaMA2-chat (7B) 作为语言模型主干。在该研究中,语言模型被视为各种视觉语言输入的统一接口。本文直接借助 LLaMA-2 语言 token 来执行各种视觉语言任务。对于需要生成空间位置的视觉基础任务,本文直接要求语言模型生成边界框的文本表示以表示其空间位置。
多任务指令训练
本文使用任务识别符号指令来训练模型,分为三个阶段。各阶段训练使用的数据集如表 2 所示。

阶段 1:预训练。本文对弱标记数据集给出了高采样率,以获得更多样化的知识。
阶段 2:多任务训练。为了提高 MiniGPT-v2 在每个任务上的性能,现阶段只专注于使用细粒度数据集来训练模型。研究者从 stage-1 中排除 GRIT-20M 和 LAION 等弱监督数据集,并根据每个任务的频率更新数据采样比。该策略使本文模型能够优先考虑高质量对齐的图像文本数据,从而在各种任务中获得卓越的性能。
阶段 3:多模态指令调优。随后,本文专注于使用更多多模态指令数据集来微调模型,并增强其作为聊天机器人的对话能力。
最后,官方也提供了 Demo 供读者测试,例如,下图中左边我们上传一张照片,然后选择 [Detection] ,接着输入「red balloon」,模型就能识别出图中红色的气球:

感兴趣的读者,可以查看论文主页了解更多内容。
以上是MiniGPT-4升级到MiniGPT-v2了,不用GPT-4照样完成多模态任务的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Laravel的地理空间:互动图和大量数据的优化
Apr 08, 2025 pm 12:24 PM
Laravel的地理空间:互动图和大量数据的优化
Apr 08, 2025 pm 12:24 PM
利用地理空间技术高效处理700万条记录并创建交互式地图本文探讨如何使用Laravel和MySQL高效处理超过700万条记录,并将其转换为可交互的地图可视化。初始挑战项目需求:利用MySQL数据库中700万条记录,提取有价值的见解。许多人首先考虑编程语言,却忽略了数据库本身:它能否满足需求?是否需要数据迁移或结构调整?MySQL能否承受如此大的数据负载?初步分析:需要确定关键过滤器和属性。经过分析,发现仅少数属性与解决方案相关。我们验证了过滤器的可行性,并设置了一些限制来优化搜索。地图搜索基于城
 mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
MySQL启动失败的原因有多种,可以通过检查错误日志进行诊断。常见原因包括端口冲突(检查端口占用情况并修改配置)、权限问题(检查服务运行用户权限)、配置文件错误(检查参数设置)、数据目录损坏(恢复数据或重建表空间)、InnoDB表空间问题(检查ibdata1文件)、插件加载失败(检查错误日志)。解决问题时应根据错误日志进行分析,找到问题的根源,并养成定期备份数据的习惯,以预防和解决问题。
 如何设置Vue Axios的超时时间
Apr 07, 2025 pm 10:03 PM
如何设置Vue Axios的超时时间
Apr 07, 2025 pm 10:03 PM
为了设置 Vue Axios 的超时时间,我们可以创建 Axios 实例并指定超时选项:在全局设置中:Vue.prototype.$axios = axios.create({ timeout: 5000 });在单个请求中:this.$axios.get('/api/users', { timeout: 10000 })。
 mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
文章介绍了MySQL数据库的上手操作。首先,需安装MySQL客户端,如MySQLWorkbench或命令行客户端。1.使用mysql-uroot-p命令连接服务器,并使用root账户密码登录;2.使用CREATEDATABASE创建数据库,USE选择数据库;3.使用CREATETABLE创建表,定义字段及数据类型;4.使用INSERTINTO插入数据,SELECT查询数据,UPDATE更新数据,DELETE删除数据。熟练掌握这些步骤,并学习处理常见问题和优化数据库性能,才能高效使用MySQL。
 偏远的高级后端工程师(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
偏远的高级后端工程师(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
远程高级后端工程师职位空缺公司:Circle地点:远程办公职位类型:全职薪资:$130,000-$140,000美元职位描述参与Circle移动应用和公共API相关功能的研究和开发,涵盖整个软件开发生命周期。主要职责独立完成基于RubyonRails的开发工作,并与React/Redux/Relay前端团队协作。为Web应用构建核心功能和改进,并在整个功能设计过程中与设计师和领导层紧密合作。推动积极的开发流程,并确定迭代速度的优先级。要求6年以上复杂Web应用后端
 mysql 能返回 json 吗
Apr 08, 2025 pm 03:09 PM
mysql 能返回 json 吗
Apr 08, 2025 pm 03:09 PM
MySQL 可返回 JSON 数据。JSON_EXTRACT 函数可提取字段值。对于复杂查询,可考虑使用 WHERE 子句过滤 JSON 数据,但需注意其性能影响。MySQL 对 JSON 的支持在不断增强,建议关注最新版本及功能。
 mysql安装后怎么优化数据库性能
Apr 08, 2025 am 11:36 AM
mysql安装后怎么优化数据库性能
Apr 08, 2025 am 11:36 AM
MySQL性能优化需从安装配置、索引及查询优化、监控与调优三个方面入手。1.安装后需根据服务器配置调整my.cnf文件,例如innodb_buffer_pool_size参数,并关闭query_cache_size;2.创建合适的索引,避免索引过多,并优化查询语句,例如使用EXPLAIN命令分析执行计划;3.利用MySQL自带监控工具(SHOWPROCESSLIST,SHOWSTATUS)监控数据库运行状况,定期备份和整理数据库。通过这些步骤,持续优化,才能提升MySQL数据库性能。
 了解 ACID 属性:可靠数据库的支柱
Apr 08, 2025 pm 06:33 PM
了解 ACID 属性:可靠数据库的支柱
Apr 08, 2025 pm 06:33 PM
数据库ACID属性详解ACID属性是确保数据库事务可靠性和一致性的一组规则。它们规定了数据库系统处理事务的方式,即使在系统崩溃、电源中断或多用户并发访问的情况下,也能保证数据的完整性和准确性。ACID属性概述原子性(Atomicity):事务被视为一个不可分割的单元。任何部分失败,整个事务回滚,数据库不保留任何更改。例如,银行转账,如果从一个账户扣款但未向另一个账户加款,则整个操作撤销。begintransaction;updateaccountssetbalance=balance-100wh
