

1个token终结LLM数字编码难题!九大机构联合发布xVal:训练集没有的数字也能预测!

虽然大型语言模型(LLM)在文本分析和生成任务上的性能非常强大,但在面对包含数字的问题时,比如多位数乘法,由于模型内部缺乏统一且完善的数字分词机制,会导致LLM无法理解数字的语义,从而胡编乱造答案。
目前LLM还没有广泛应用于科学领域数据分析的一大阻碍就是数字编码问题。
最近,熨斗研究所(Flatiron Institute)、劳伦斯伯克利国家实验室、剑桥大学、纽约大学、普林斯顿大学等九个研究机构联合发布了一个全新的数字编码方案xVal,只需一个token即可对所有数字进行编码。

论文链接:https://arxiv.org/pdf/2310.02989.pdf
xVal通过将专用token([NUM])的嵌入向量按数值缩放来表示目标真实值,再结合修改后的数字推理方法,xVal策略成功使模型在输入字符串数字到输出数字之间映射时端到端连续,更适合科学领域的应用。
在合成和真实世界数据集上的评估结果显示,xVal比现有的数字编码方案不仅性能更好,而且更节省token,还表现出更好的插值泛化特性。
数字编码新突破
标准的LLM分词方案并没有对数字和文本进行区分,也就无法对数值进行量化。
之前有工作按照科学计数法的形式,以10为基底,将所有数字映射到有限的原型数字(prototype numerals)集合中,或是计算数字embedding之间的余弦距离来反映数字本身的数值差异,已经成功用于解决线性代数问题,诸如矩阵乘法等。
不过对于科学领域中的连续或平滑问题,语言模型仍然无法很好地处理插值和分布外泛化问题,因为将数字编码为文本后,LLM在编码和解码阶段本质上仍然是离散的,很难学习近似连续函数。
xVal的思路是对数值大小进行乘法(multiplicatively)编码,并在嵌入空间中将其定向到可学习的方向,极大地改变了Transformer架构中处理和解释数字的方式。
xVal使用单个token进行数字编码,具有token效率的优势以及最小的词典足迹(vocabulary footprint)。
结合修改后的数字推理范式,Transformer模型值在输入数字和输出字符串的数字之间的映射时是连续的(平滑),当近似的函数是连续或平滑时,可以带来更好的归纳偏差(inductive bias)。
xVal: 连续数字编码
xVal没有对不同的数字使用不同的token,而是直接沿着嵌入空间中特定可学习方向嵌入数值。
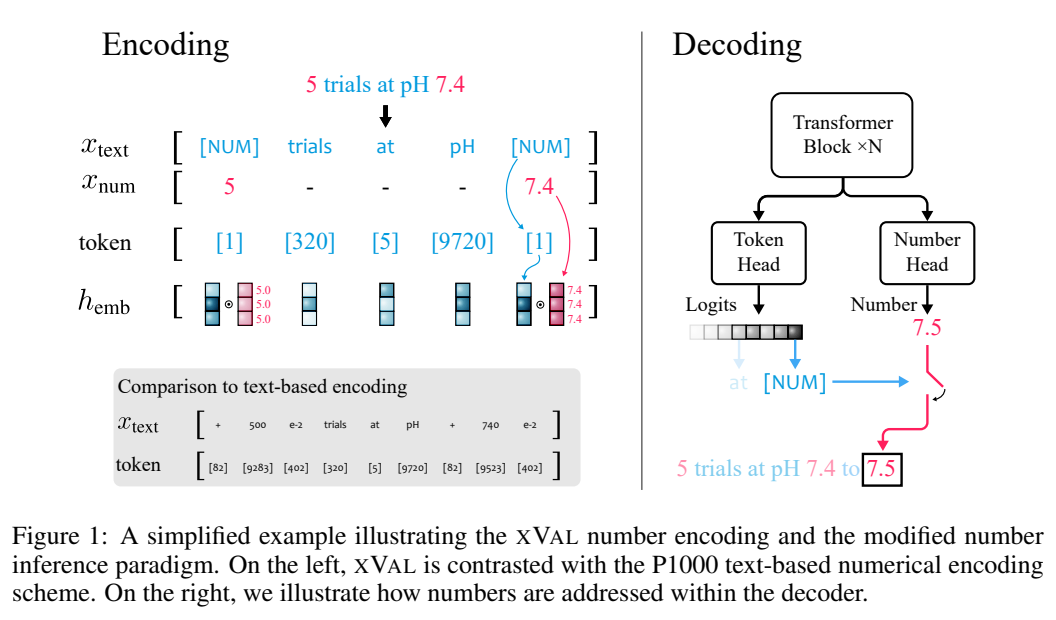
假设输入字符串中同时包含数字和文本,系统首先会对输入进行解析,提取出所有的数值,然后构造出一个新的字符串,其中数字被替换为[NUM]占位符,再将[NUM]的嵌入向量与其所对应的数值相乘。
整个编码过程可以用于遮罩语言建模(MLM)和自回归(AR)生成。
基于层归一化的隐式归一化(Implicit normalization via layer-norm)
在具体实现中,第一个Transformer块中的xVal的乘法嵌入(multiplicative embedding)之后需要加上位置编码向量,以及层归一化(layer-norm),基于输入样本对每个token的嵌入进行归一化。
当位置嵌入与[NUM]标记的嵌入不共线(collinear)时,标量值可以通过非线性重缩放函数(non-linear rescaling)进行传递。
假设u为[NUM]的嵌入,p为位置嵌入,x是被编码的标量值,为了简化计算可以假定u · p=0,其中∥u∥ =∥p∥ = 1,可以得到
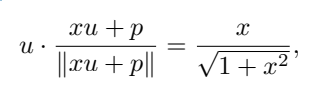
即x的值被编码为与u同方向,并且该属性在训练后仍然可以保持。
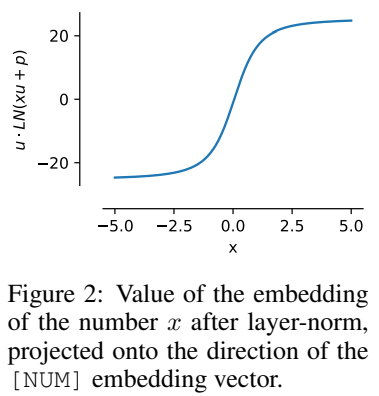
这种归一化特性意味着xVal的动态范围比其他基于文本的编码方案的动态范围更小,在实验中设定为[-5, 5]以作为训练前的预处理步骤。
数值推理
xVal定义了在输入数值中连续的嵌入,但如果使用多分类任务作为输出和训练算法时,考虑到从输入数值到输出数值之间的映射,则模型作为一个整体不是端到端连续的,需要在输出层单独对数字进行处理。
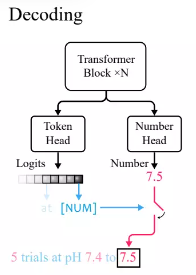
根据Transformer语言模型中的标准实践,研究人员定义了一个token head,输出词汇表token的概率分布。
因为xVal使用[NUM]对数字进行替换,所以head不携带任何关于数值的信息,所以需要引入了一个具有标量输出的新number head,通过均方误差(MSE)损失进行训练,以恢复与[NUM]相关联的具体数值。
给定输入后,首先观察token head的输出,如果生成的token为[NUM],则查看number head来填充该token的值。
在实验中,由于Transformer模型在推断数值时是端到端连续的,所以当插值到未见过的数值时表现得更好。
实验部分
对比其他数字编码方法
研究人员将XVAL的性能与其他四种数字编码进行了比较,这些方法都需要先将数字处理为±ddd E±d的形式,然后再根据格式调用单个或多个token来确定编码。

不同方法对于编码每个数字所需要的token数量、词汇表数量都有很大不同,但总体来看,xVal的编码效率是最高的,并且词汇表尺寸也最小。
研究人员还在三个数据集上对xVal进行评估,包括合成的算术运算数据、全球温度数据和行星轨道模拟数据。
学习算术
即使对于最大的LLM来说,「多位数乘法」也仍然是一个极具挑战的任务,例如GPT-4在三位数乘法问题上仅能达到59%的zero-shot准确率,在四位数和五位数乘法问题上的准确率甚至只有4%和0%
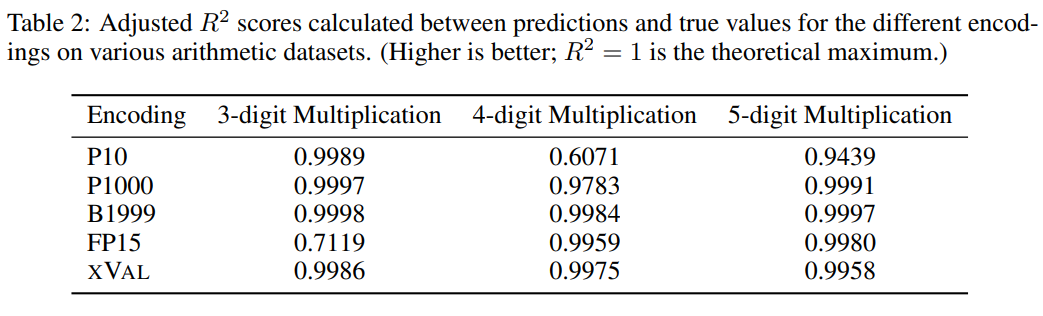
从对比实验来看,其他数字编码通常也能很好地解决多位数乘法问题,不过xVal的预测结果相比P10和FP15来说更稳定,不会产生异常预测值。
为了提升任务难度,研究人员使用随机二叉树,使用加法、减法和乘法的二元运算符组合固定数量的操作数(2、3或4)构造出了一个数据集,其中每个样本都是一个算术表达式,例如((1.32 * 32.1) + (1.42-8.20)) = 35.592
然后根据每个数字编码方案的处理要求对样本进行处理,任务目标是计算等式左侧的表达式,即等式右侧为掩码。
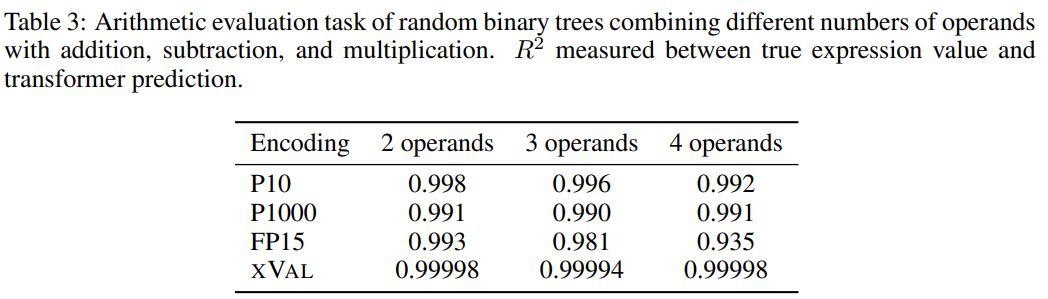
从结果来看,xVal在这个任务上表现得非常好,不过单靠算术实验不足以完全评估语言模型的数学能力,因为算术运算中的样本通常是短序列,底层数据流形是低维的,这些问题并没有突破LLMs在计算上的瓶颈,而现实世界中的应用更复杂。
温度预测
研究人员使用ERA5全球气候数据集的子集用作评估,简单起见,实验中只关注地表温度数据(ERA5中的T2m),然后对样本进行划分,其中每个样本包括2-4天的地表温度数据(一化后具有单位方差)以及来自60-90个随机选择的报告站的纬度和经度。
对坐标的纬度的正弦和经度的正弦和余弦编码,从而保持数据的周期性,然后使用同样的操作对24小时和365天周期中位置进行编码。

坐标(coords)、起点(start)和数据(data)对应于报告站坐标、第一个样本的时间和标准化温度数据,然后使用MLM方法来训练语言模型。
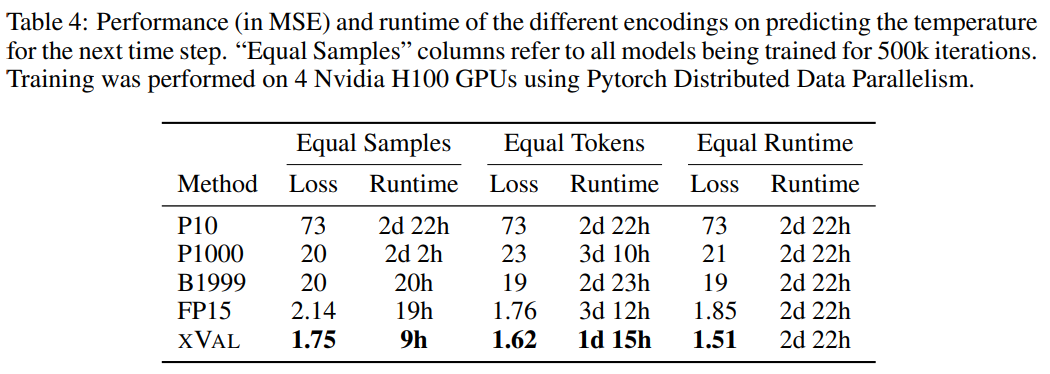
从结果来看,xVal的性能最好,同时计算所需时间也显著降低。
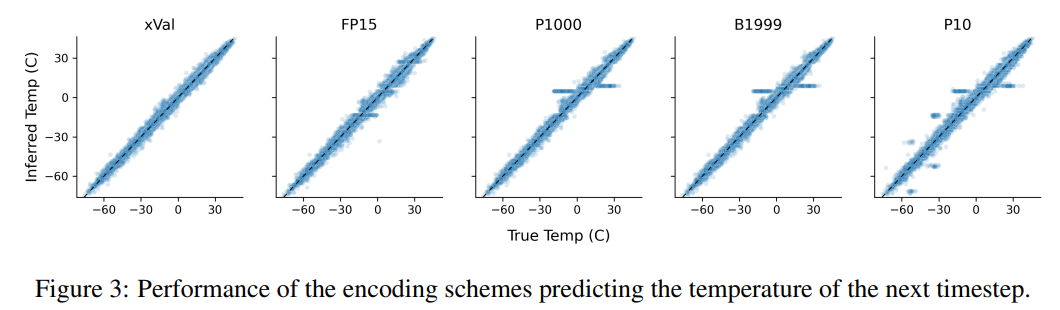
这项任务也说明了基于文本编码方案的缺点,模型可以利用数据中的虚假相关性,即P10、P1000和B1999具有预测归一化温度±0.1的趋势,主要原因是该数字在数据集中出现的频率最高。
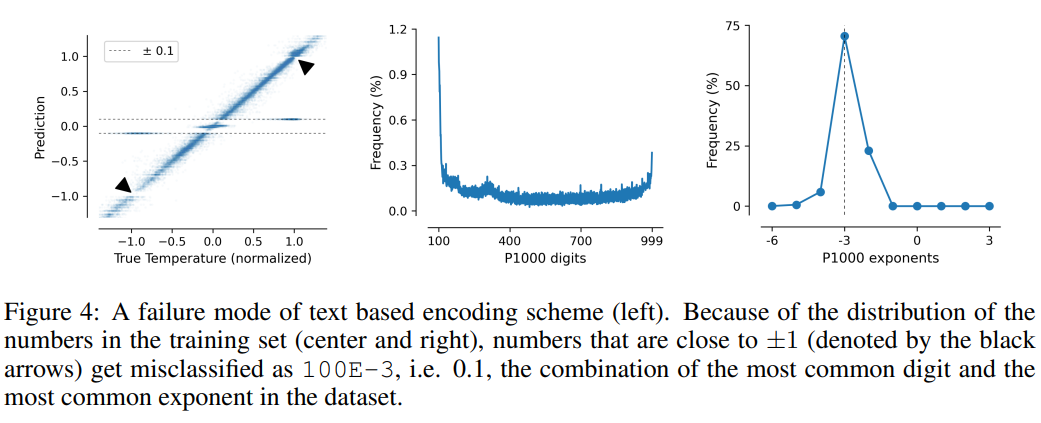
对于P1000和P10方案来说,二者的编码输出平均分别约为8000和5000个token(相比之下,FP15和xVal平均约为1800个token),模型的不良性能可能是由于长距离建模的问题。
以上是1个token终结LLM数字编码难题!九大机构联合发布xVal:训练集没有的数字也能预测!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
MySQL启动失败的原因有多种,可以通过检查错误日志进行诊断。常见原因包括端口冲突(检查端口占用情况并修改配置)、权限问题(检查服务运行用户权限)、配置文件错误(检查参数设置)、数据目录损坏(恢复数据或重建表空间)、InnoDB表空间问题(检查ibdata1文件)、插件加载失败(检查错误日志)。解决问题时应根据错误日志进行分析,找到问题的根源,并养成定期备份数据的习惯,以预防和解决问题。
 mysql 能返回 json 吗
Apr 08, 2025 pm 03:09 PM
mysql 能返回 json 吗
Apr 08, 2025 pm 03:09 PM
MySQL 可返回 JSON 数据。JSON_EXTRACT 函数可提取字段值。对于复杂查询,可考虑使用 WHERE 子句过滤 JSON 数据,但需注意其性能影响。MySQL 对 JSON 的支持在不断增强,建议关注最新版本及功能。
 了解 ACID 属性:可靠数据库的支柱
Apr 08, 2025 pm 06:33 PM
了解 ACID 属性:可靠数据库的支柱
Apr 08, 2025 pm 06:33 PM
数据库ACID属性详解ACID属性是确保数据库事务可靠性和一致性的一组规则。它们规定了数据库系统处理事务的方式,即使在系统崩溃、电源中断或多用户并发访问的情况下,也能保证数据的完整性和准确性。ACID属性概述原子性(Atomicity):事务被视为一个不可分割的单元。任何部分失败,整个事务回滚,数据库不保留任何更改。例如,银行转账,如果从一个账户扣款但未向另一个账户加款,则整个操作撤销。begintransaction;updateaccountssetbalance=balance-100wh
 掌握SQL LIMIT子句:控制查询中的行数
Apr 08, 2025 pm 07:00 PM
掌握SQL LIMIT子句:控制查询中的行数
Apr 08, 2025 pm 07:00 PM
SQLLIMIT子句:控制查询结果行数SQL中的LIMIT子句用于限制查询返回的行数,这在处理大型数据集、分页显示和测试数据时非常有用,能有效提升查询效率。语法基本语法:SELECTcolumn1,column2,...FROMtable_nameLIMITnumber_of_rows;number_of_rows:指定返回的行数。带偏移量的语法:SELECTcolumn1,column2,...FROMtable_nameLIMIToffset,number_of_rows;offset:跳过
 如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL数据库性能优化指南在资源密集型应用中,MySQL数据库扮演着至关重要的角色,负责管理海量事务。然而,随着应用规模的扩大,数据库性能瓶颈往往成为制约因素。本文将探讨一系列行之有效的MySQL性能优化策略,确保您的应用在高负载下依然保持高效响应。我们将结合实际案例,深入讲解索引、查询优化、数据库设计以及缓存等关键技术。1.数据库架构设计优化合理的数据库架构是MySQL性能优化的基石。以下是一些核心原则:选择合适的数据类型选择最小的、符合需求的数据类型,既能节省存储空间,又能提升数据处理速度
 Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
直接通过 Navicat 查看 MongoDB 密码是不可能的,因为它以哈希值形式存储。取回丢失密码的方法:1. 重置密码;2. 检查配置文件(可能包含哈希值);3. 检查代码(可能硬编码密码)。
 mysql 主键可以为 null
Apr 08, 2025 pm 03:03 PM
mysql 主键可以为 null
Apr 08, 2025 pm 03:03 PM
MySQL 主键不可以为空,因为主键是唯一标识数据库中每一行的关键属性,如果主键可以为空,则无法唯一标识记录,将会导致数据混乱。使用自增整型列或 UUID 作为主键时,应考虑效率和空间占用等因素,选择合适的方案。
 使用 Prometheus MySQL Exporter 监控 MySQL 和 MariaDB Droplet
Apr 08, 2025 pm 02:42 PM
使用 Prometheus MySQL Exporter 监控 MySQL 和 MariaDB Droplet
Apr 08, 2025 pm 02:42 PM
有效监控 MySQL 和 MariaDB 数据库对于保持最佳性能、识别潜在瓶颈以及确保整体系统可靠性至关重要。 Prometheus MySQL Exporter 是一款强大的工具,可提供对数据库指标的详细洞察,这对于主动管理和故障排除至关重要。
