

九章云极DataCanvas多模态大模型平台的实践和思考


一、多模态大模型的历史发展

上图这张照片是1956 年在美国达特茅斯学院召开的第一届人工智能workshop,这次会议也被认为拉开了人工智能的序幕,与会者主要是符号逻辑学届的前驱(除了前排中间的神经生物学家Peter Milner)。
然而这套符号逻辑学理论在随后的很长一段时间内都无法实现,甚至到 80 年代90年代还迎来了第一次AI寒冬期。直到最近大语言模型的落地,我们才发现真正承载这个逻辑思维的是神经网络,神经生物学家Peter Milner的工作激发了后来人工神经网络的发展,也正因为此他被邀请参加了这个学术研讨会。

2012年,Tesla自动驾驶主管Andrew在博客上发布了上面这张图,显示当时美国总统奥巴马和自己的下属开玩笑。要让人工智能去理解这张图,不仅是一个视觉感知任务,因为除了要识别物体,还需要理解他们之间的关系;只有知道体重秤的物理原理,才能知道图里描述的故事:奥巴马踩了秤,导致秤上的人体重升高,他因此做出了这个奇怪的表情,同时其他人在一旁笑。这样的逻辑思维显然已经超出了纯粹的视觉感知范畴,因此必须将视觉认知和逻辑思维结合到一起,才能摆脱“人工智障”的尴尬,而多模态大模型的重要性和困难性也体现在这里。
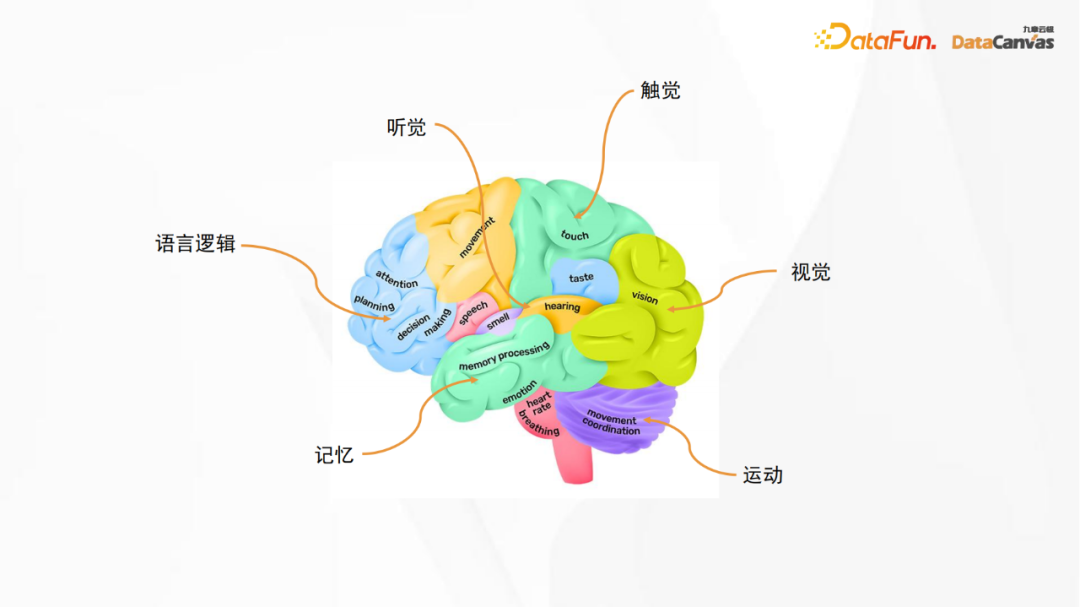
上图是人类大脑的解剖结构图,图中的语言逻辑区对应的就是大语言模型,而其他的区域则分别对应着不同的感官,包括视觉、听觉、触觉、运动、记忆等等。虽然人工神经网络并不是真正意义上的脑神经网络,但还是可以从中受到一些启发,即构造大模型的时候,可以将不同的功能联合在一起,这也是多模态模型构建的基本思想。
1、多模态大模型可以做什么?
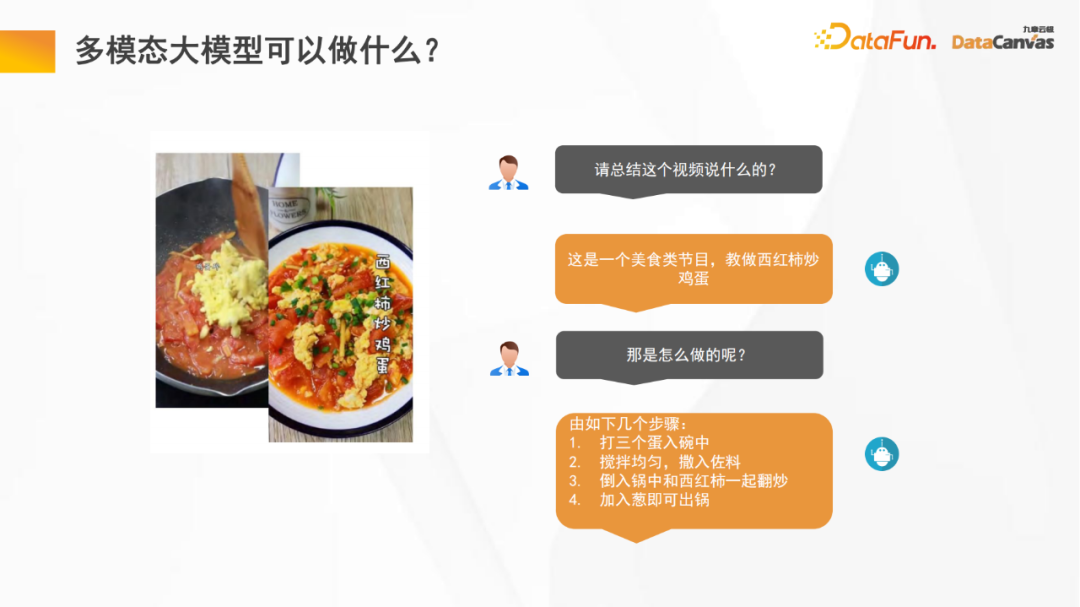
多模态大模型可以为我们做很多事情,例如视频理解,大模型可以帮我们总结视频的摘要以及关键信息,从而节约我们看视频的时间;大模型还可以帮助我们进行视频的后期分析,例如节目分类、节目收视率统计等;此外,文生图也是多模态大模型的一个重要的应用领域。
而大模型如果和人的运动,或者机器人的运动联合在一起,就会产生一个具身智能体,就像人一样,基于过往经验规划最佳路径的方法,并应用到全新的场景中,解决一些先前没有遇见过的问题,同时规避风险;甚至可以在执行过程中修改原有计划,直到最后获得成功。这也是一个具有广泛前景的应用场景。
2、多模态大模型
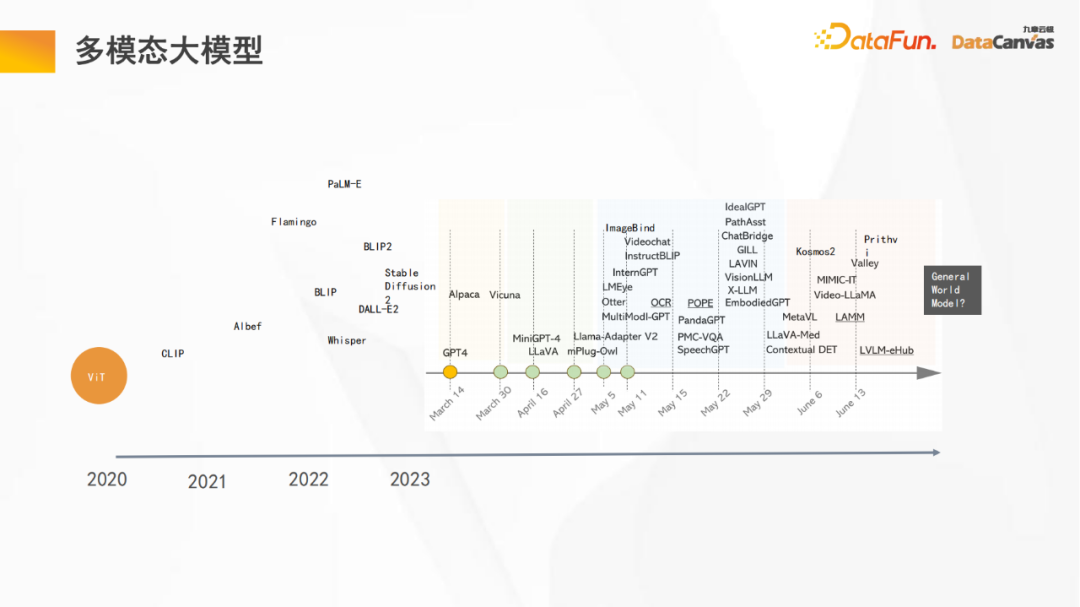
上图是多模态大模型在发展过程中的一些重要节点:
- 2020年的ViT模型(Vision Transformer)是大模型的开端,首次将Transformer架构用到除语言和逻辑处理外的其它类型数据(视觉数据),并且显示了良好的泛化能力;
- 随后通过OpenAI开源的CLIP模型,再次证明了通过ViT和大语言模型的使用,视觉任务实现了很强的长尾泛化能力,即通过常识推测先前没有见过的类别
- 到了2023年,各式各样的多模态大模型逐渐显现,从PaLM-E(机器人),到 whisper(语音识别),再到ImageBind(图像对齐),再到Sam(语义分割),最后到地理图像;还包括微软的统一多模态架构Kosmos2,多模态大模型发展迅速。
- 特斯拉在6月的CVPR还提出了通用世界模型这样的愿景。
从上图可以看出,短短半年时间,大模型就发生了非常多的变化,其迭代速度是非常快的。
3、模态对齐架构
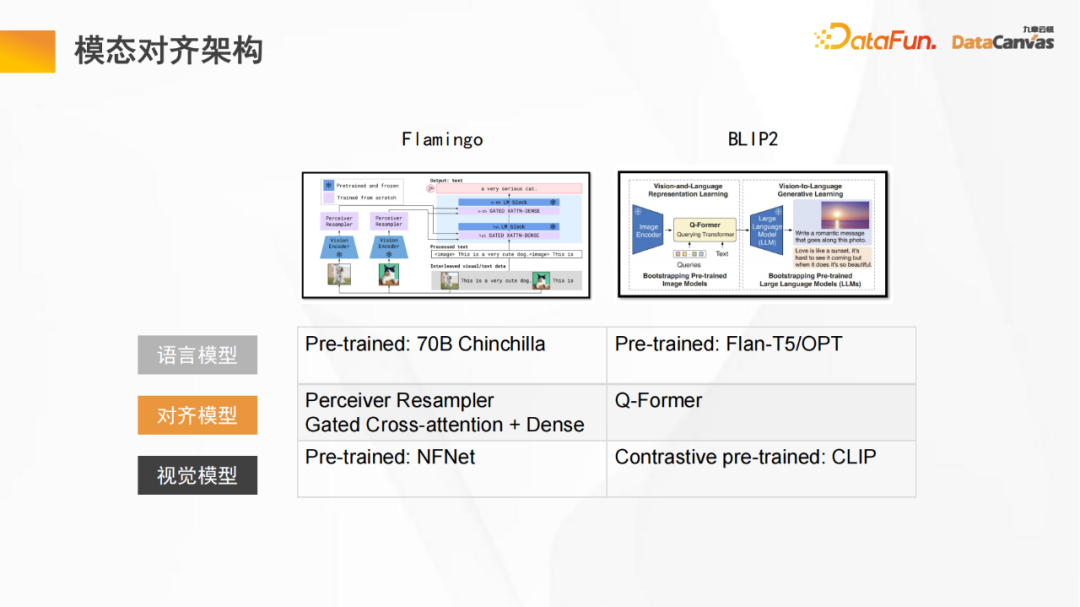
上图是多模态大模型的通用架构图,包含一个语言模型、一个视觉模型,通过固定语言模型和固定视觉模型进而学习对齐模型;而对齐就是将视觉模型的矢量空间和语言模型的矢量空间进行联合,进而在统一的矢量空间里完成两者内在逻辑关系的理解。
图中所示的Flamingo模型和BLIP2模型都采用类似的结构(Flamingo模型采用Perceiver架构,而BLIP2模型采用改良版的Transformer架构);然后通过多种对比学习的方法进行预训练,对海量的token进行大量学习,获得较好的对齐效果;最后根据特定的任务对模型进行微调。
二、九章云极DataCanvas的多模态大模型平台
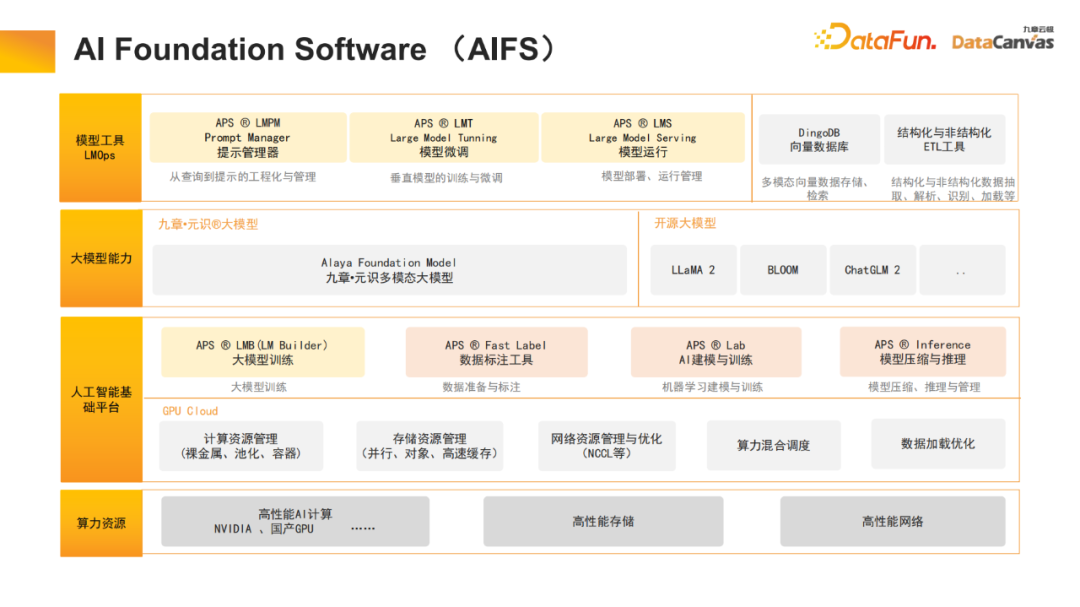
1、AI Foundation Software (AIFS)
九章云极DataCanvas是人工智能基础软件提供商,同时提供算力资源(包括GPU集群),进行高性能的存储和网络优化,在此基础上提供大模型的训练工具,包括数据标注建模实验沙盒等。九章云极DataCanvas不仅支持市面上常见的开源大模型,同时也在自主研发元识多模态大模型。在应用层,提供了工具对提示词进行管理,对模型进行微调,并提供模型运维机制。同时,还开源了一款多模向量数据库,让基础软件架构更加丰富。
2、模型工具LMOPS
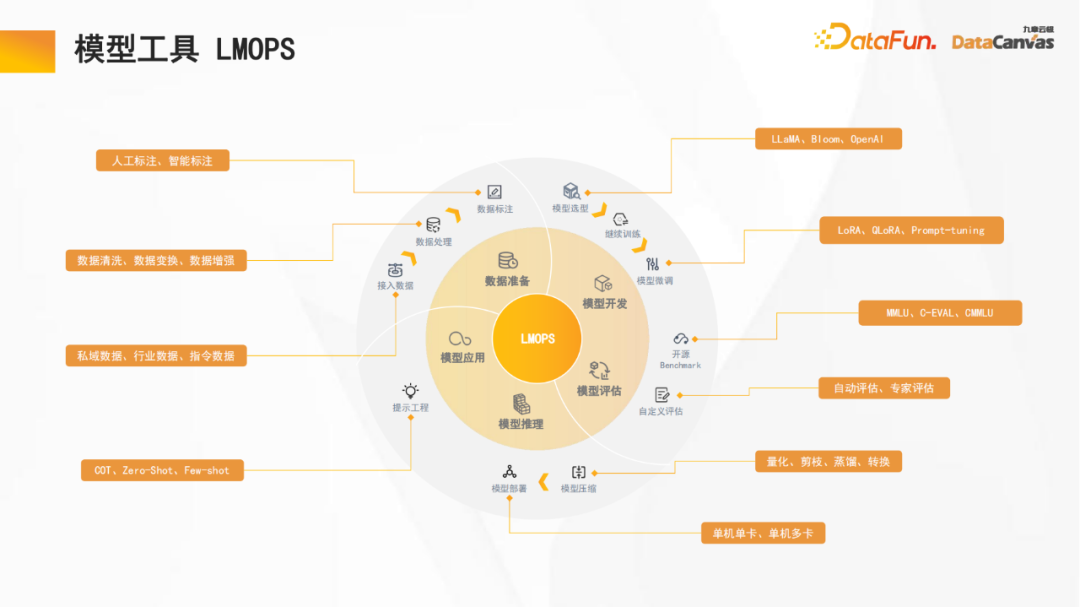
九章云极DataCanvas专注于全生命周期的开发的优化,包括数据准备(数据标注支持人工标注和智能标注)、模型开发、模型评估(包括横向评估和纵向评估)、模型推理(支持模型量化、知识蒸馏等加速推理机制)、模型应用等。
3、LMB –Large Model Builder

在构建模型时,进行了很多分布式高效优化工作,包括数据并行、Tensor并行、管道并行等。这些分布式优化工作是一键式完成的,并支持可视化调控,可以大大减少人力成本,提升开发效率。
4、LMB –Large Model Builder
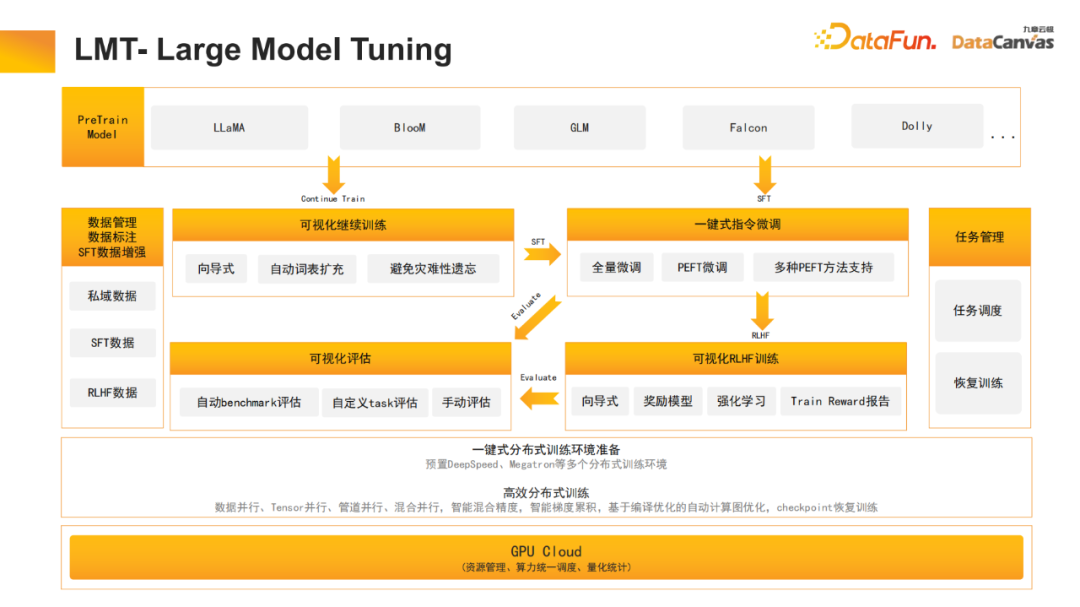
对于大模型tuning也进行了优化,包括常见的continue training、supervise tuning,以及reinforcement learning中的human feedback等。此外,对于中文也进行了很多优化,例如中文词表的自动扩展。因为很多中文词汇并未包含在开源大模型中,这些词汇可能会被拆分成多个token;将这些词汇进行自动扩充,可以让模型更好地使用这些词汇。
5、LMS –Large Model Serving
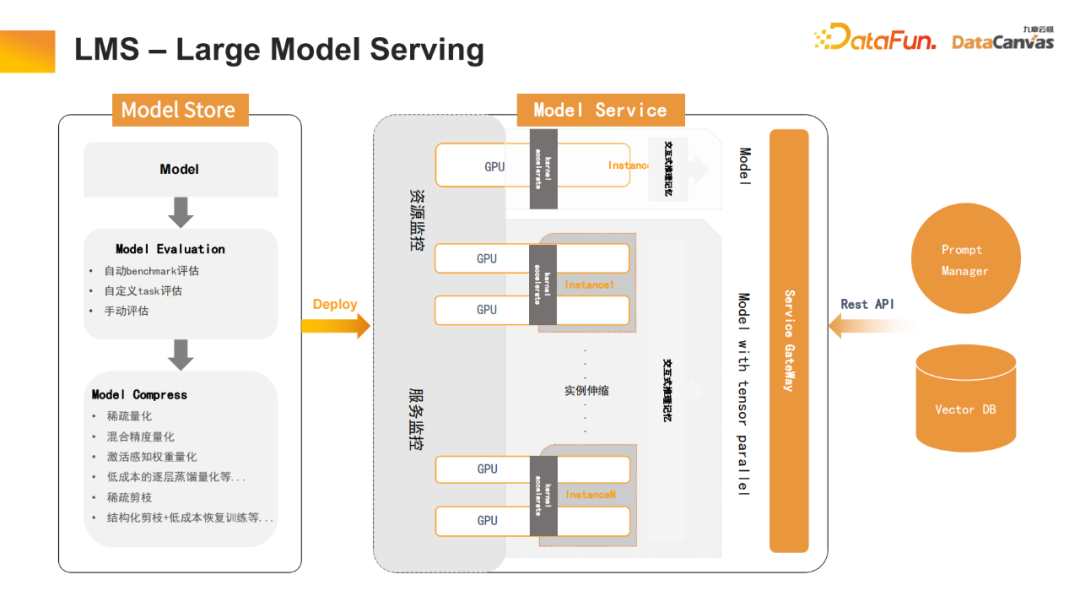
大模型的serving也是非常重要的一个组成部分,平台对模型量化、知识蒸馏等环节也进行了大量的优化,大大降低了计算成本,并通过逐层知识蒸馏来加速transformer,减少其计算量。与此同时,也做了很多剪枝工作(包括结构化剪枝、稀疏剪枝等),大大提升了大模型的推理速度。
此外,对交互式对话过程也进行了优化。例如多轮对话Transformer中,每个tensor的key和value是可以记住的,无需重复计算。因此,可将其存入Vector DB中,实现对话历史记忆功能,提升交互过程中的用户体验。
6、Prompt Manager
大模型提示词设计和构建工具Prompt Manager,通过帮助用户设计更好的提示词,引导大模型生成更加准确、可靠、符合预期的输出内容。该工具既可面向技术人员提供development toolkit的开发模式,也可以面向非技术人员提供人机交互的操作模式,满足不同人群使用大模型的需求。
其主要功能包括:AI模型管理、场景管理、提示词模板管理、提示词开发和提示词应用等。

平台提供了常用的提示词管理工具,可实现版本控制,并提供常用模板来加速提示词的实现。
三、九章云极DataCanvas多模态大模型的实践
1、多模态大模型——有记忆体
介绍完平台功能,接下来会分享多模态大模型开发实践。
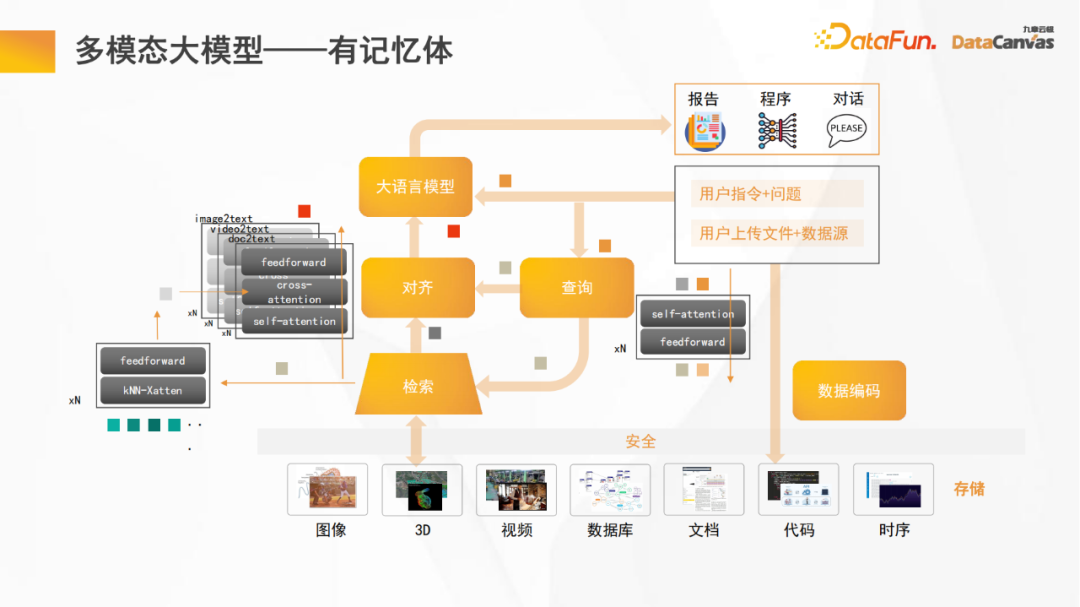
上图是九章云极DataCanvas多模态大模型的基本框架,与其它多模态大模型不同的一点是,它包含记忆体,可以提升开源大模型的推理能力。
一般开源大模型的参数量相对较低,如果再耗用一部分参数量进行记忆,其推理能力将会大幅下降。如果给开源大模型增加记忆体,则会同时提升推理能力和记忆能力。
此外,类似大多数模型,多模态大模型也会固定大语言模型和固定数据编码,针对对齐功能进行单独的模块化的训练;因此,所有不同的数据模态都会对齐到文本中的逻辑部分;在推理的过程,首先对语言进行翻译,然后进行融合,最后进行推理工作。
2、非结构化数据ETL Pipeline
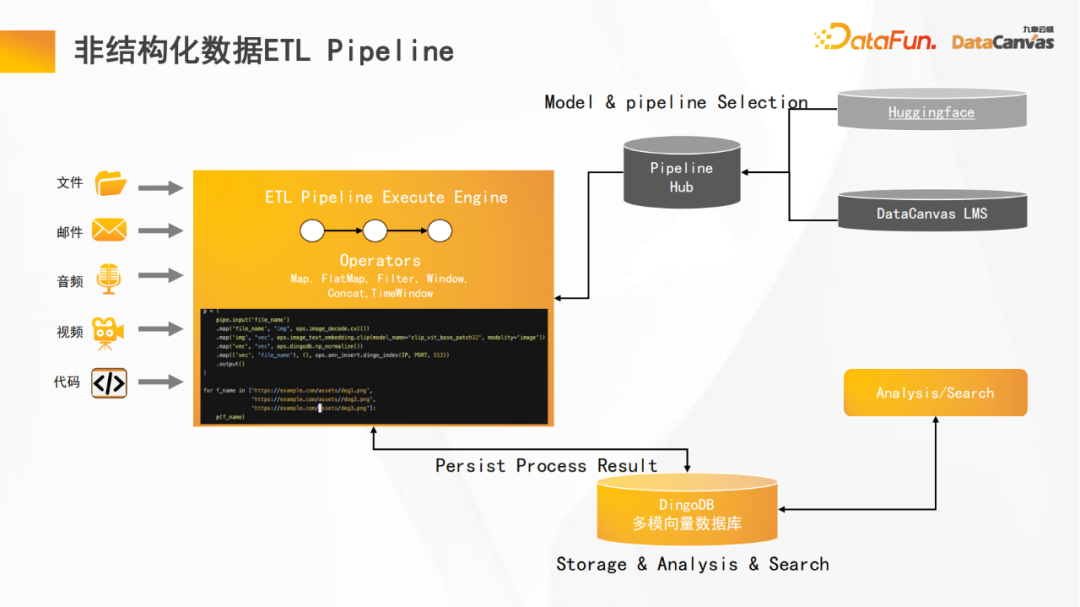
由于我们的DingoDB多模向量数据库结合了多模态与ETL的功能,因此能够提供良好的非结构化数据管理能力。平台提供pipeline ETL功能,并做了很多优化,包括算子编译、并行处理,以及缓存优化等。
此外,平台提供Hub,可以将pipeline重复使用,实现最高效的开发体验。同时,支持 Huggingface上的众多编码器,可以实现对不同模态数据的最优编码。
3、多模态大模型构建方法
九章云极DataCanvas将元识多模态大模型作为底座,支持用户选择其它开源大模型,也支持用户使用自己的模态数据进行训练。
多模态大模型的构建大概分为三个阶段:
- 第一阶段:固定大语言模型和模态编码器训练对齐和查询;
- 第二阶段(可选,支持多模态搜索):固定大语言模型,模态编码器,对齐和查询模块,训练检索模块;
- 第三阶段(可选,对特定任务):指令微调大语言模型。
4、案例-知识库建设
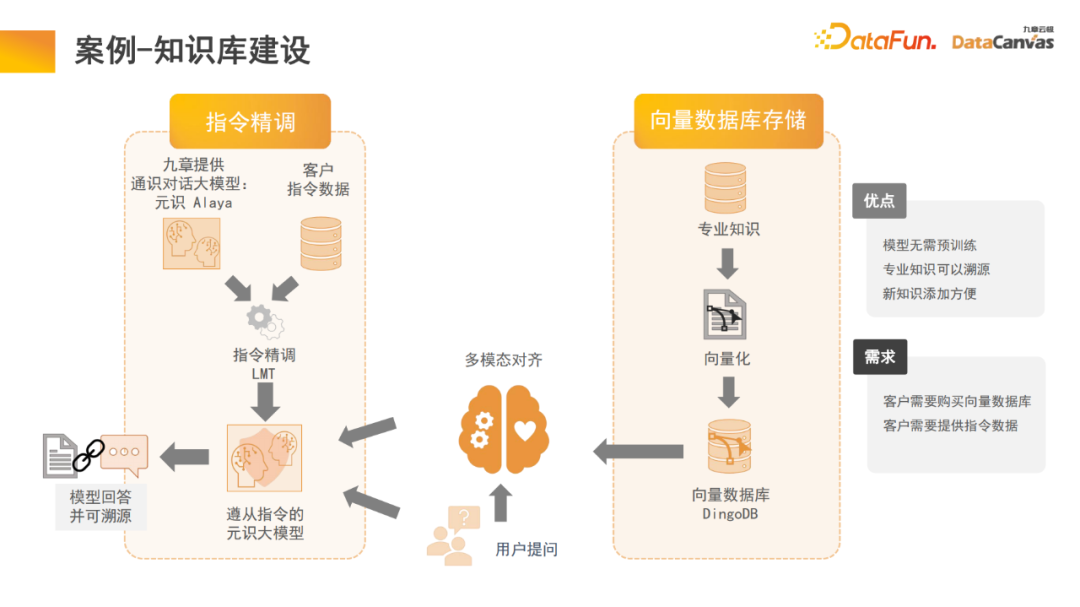
大模型中的记忆体架构,可以帮助我们实现多模态知识库建设,该知识库实际上是模型的应用。知乎就是一个典型的多模态知识库应用模块,其专业知识是可以溯源的。
为了保证知识的确定性和安全性,往往需要对专业知识进行溯源,知识库就可以帮助我们实现这此功能,同时新的知识添加也会比较方便,无需修改模型参数,直接把知识添加进数据库即可。
具体来说,将专业知识通过编码器进行不同的编码选择,同时根据不同的评价方法进行统一评价,通过一键评价来实现编码器的选择。最后应用编码器向量化之后存入DingoDB多模向量数据库,再通过大模型的多模态模块进行相关信息提取,通过语言模型来进行推理。
模型的最后一部分往往需要进行指令精调,由于不同用户的需求不太一样,因此需要对整个多模态大模型进行精调。由于多模态知识库在组织信息这部分特殊的优势,使得模型具备学习检索的能力,这也是我们在文本的段落化过程中做的创新。
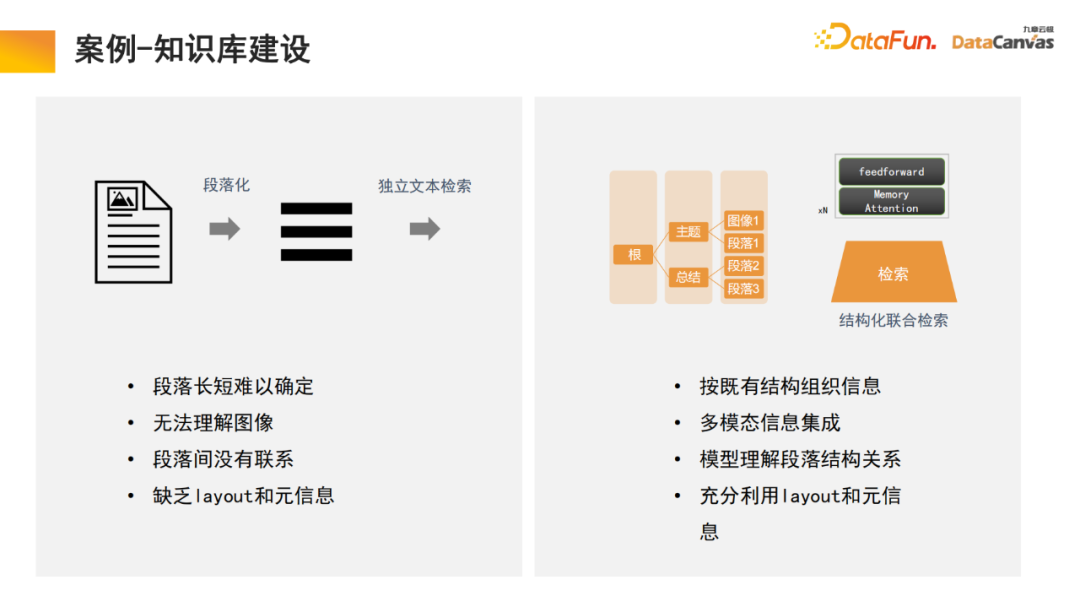
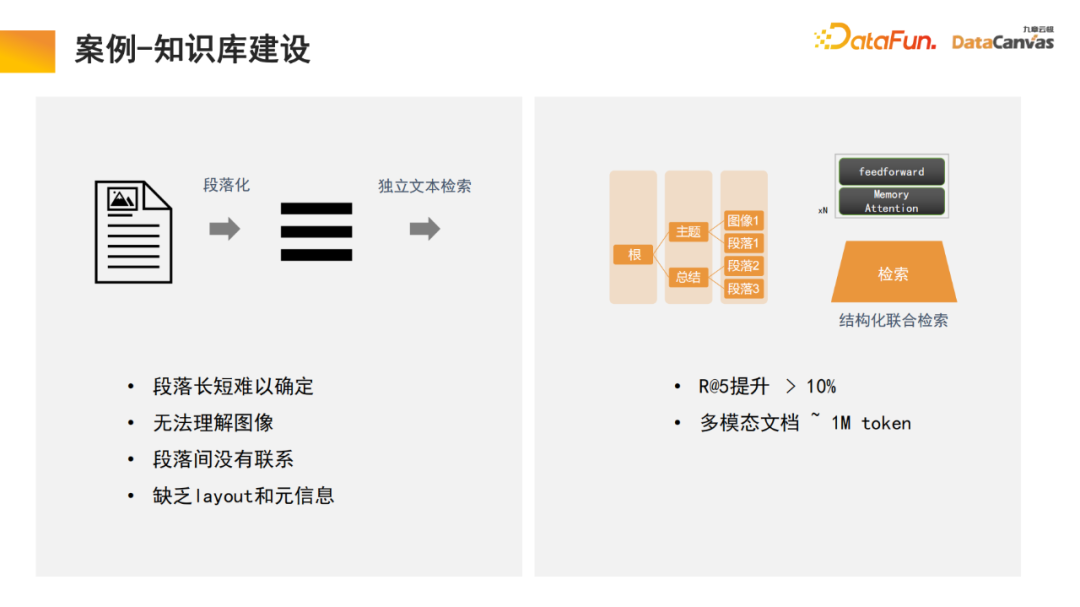
一般的知识库是将文档进行段落化,然后对每一段进行独立的文本解锁。这种方法容易受到噪声的干扰,对于很多大的文档,很难判定段落划分的标准。
而我们的模型中,检索模块进行学习,模型自动寻找合适的结构化信息组织。对于某个具体产品,从产品说明书开始,首先定位大的目录段落,再定位到具体的段落。同时由于是多模态的信息集成,除了文字以外往往还会包含图像表格等,也可以进行向量化表达,再结合Meta信息,实现联合检索,从而提升检索效率。
值得说明的是,检索模块使用内存注意力机制,相较于同类算法可提升10%的召回率;同时可将内存注意力机制用于多模态文档处理,这也是非常有优势的一个方面。
四、对未来的思考与展望
1、企业数据管理 -- 知识库
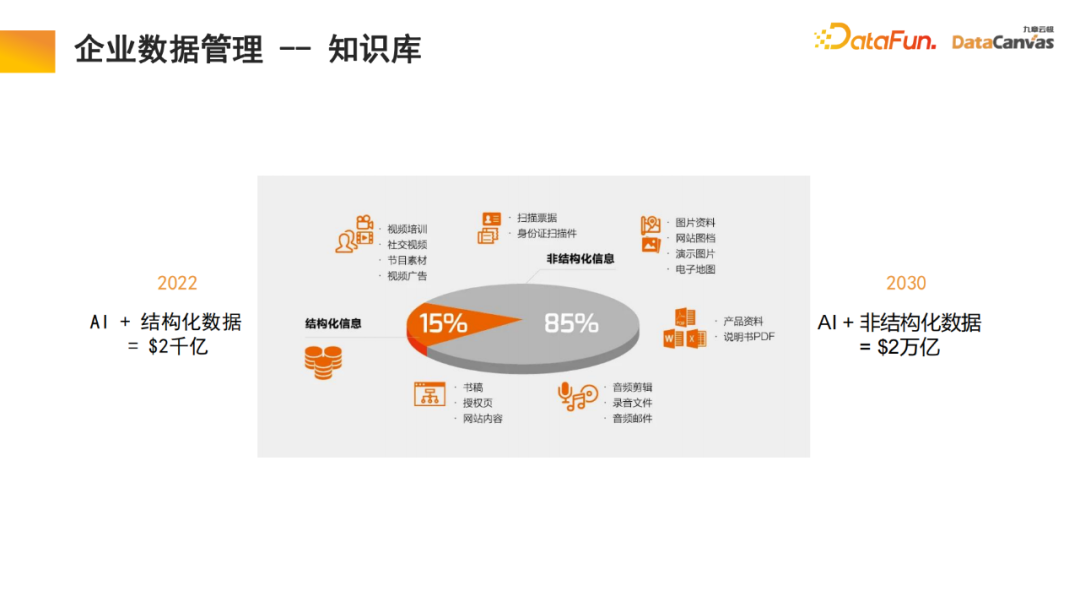
企业中85%的数据都是非结构化数据,只有15%是结构化的数据。过去的20年,人工智能主要是围绕结构化数据展开的,而非结构化数据是非常难以利用的,需要非常大的精力和代价将其转化处理为结构化数据。而借助多模态大模型和多模态知识库,通过人工智能新范式,可以大大提升企业内部管理中非结构化数据的利用率,未来可能会带来10倍的价值增长。
2、知识库--> 智能体(Agent)
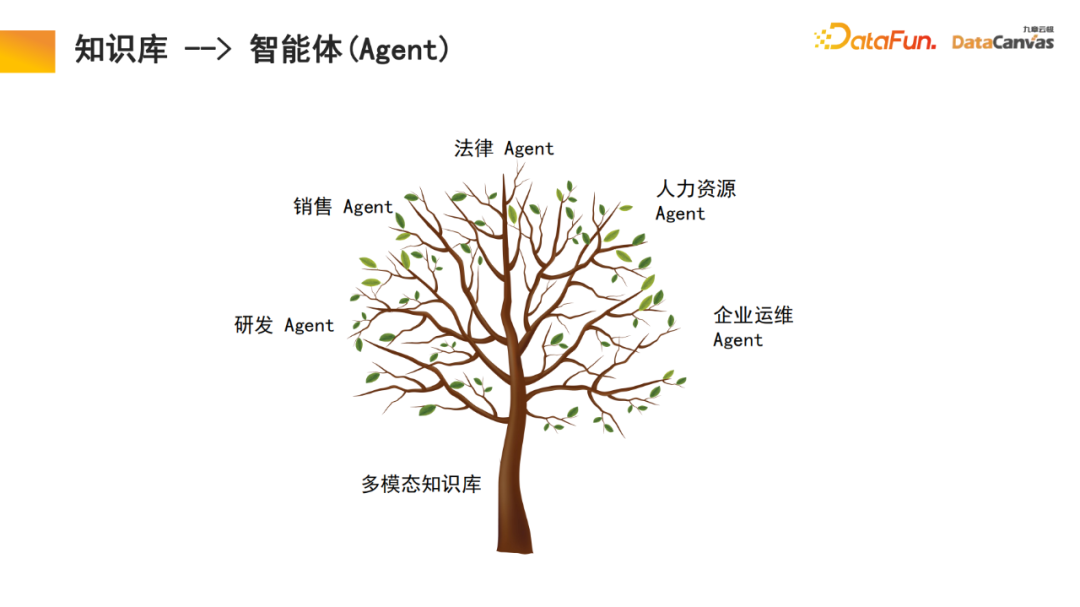
多模态知识库作为智能体的基础,之上的研发agent、客服agent、销售agent、法律agent,人力资源agent,企业运维 agent等功能都可以通过知识库进行运作。
以销售agent为例,常见架构包括两个agent同时存在,其中一个负责决策,另一个负责销售阶段的分析。这两个模块都可以通过多模态知识库寻找相关信息,包括产品信息、历史销售统计资料、客户画像、过往销售经验等,这些信息整合到一起,帮助这两个agent做最好、最正确的决定,这些决定反过来帮助用户获得最好的销售信息,再记录到多模态数据库集中,如此循环往复,不断提升销售业绩。
我们相信未来最有价值的企业,是将智能体落到实处的企业。希望九章云极DataCanvas可以跟大家一路同行,相互助力。
以上是九章云极DataCanvas多模态大模型平台的实践和思考的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
写在前面&笔者的个人理解目前,在整个自动驾驶系统当中,感知模块扮演了其中至关重要的角色,行驶在道路上的自动驾驶车辆只有通过感知模块获得到准确的感知结果后,才能让自动驾驶系统中的下游规控模块做出及时、正确的判断和行为决策。目前,具备自动驾驶功能的汽车中通常会配备包括环视相机传感器、激光雷达传感器以及毫米波雷达传感器在内的多种数据信息传感器来收集不同模态的信息,用于实现准确的感知任务。基于纯视觉的BEV感知算法因其较低的硬件成本和易于部署的特点,以及其输出结果能便捷地应用于各种下游任务,因此受到工业
 使用C++实现机器学习算法:常见挑战及解决方案
Jun 03, 2024 pm 01:25 PM
使用C++实现机器学习算法:常见挑战及解决方案
Jun 03, 2024 pm 01:25 PM
C++中机器学习算法面临的常见挑战包括内存管理、多线程、性能优化和可维护性。解决方案包括使用智能指针、现代线程库、SIMD指令和第三方库,并遵循代码风格指南和使用自动化工具。实践案例展示了如何利用Eigen库实现线性回归算法,有效地管理内存和使用高性能矩阵操作。
 探究C++sort函数的底层原理与算法选择
Apr 02, 2024 pm 05:36 PM
探究C++sort函数的底层原理与算法选择
Apr 02, 2024 pm 05:36 PM
C++sort函数底层采用归并排序,其复杂度为O(nlogn),并提供不同的排序算法选择,包括快速排序、堆排序和稳定排序。
 人工智能可以预测犯罪吗?探索CrimeGPT的能力
Mar 22, 2024 pm 10:10 PM
人工智能可以预测犯罪吗?探索CrimeGPT的能力
Mar 22, 2024 pm 10:10 PM
人工智能(AI)与执法领域的融合为犯罪预防和侦查开辟了新的可能性。人工智能的预测能力被广泛应用于CrimeGPT(犯罪预测技术)等系统,用于预测犯罪活动。本文探讨了人工智能在犯罪预测领域的潜力、目前的应用情况、所面临的挑战以及相关技术可能带来的道德影响。人工智能和犯罪预测:基础知识CrimeGPT利用机器学习算法来分析大量数据集,识别可以预测犯罪可能发生的地点和时间的模式。这些数据集包括历史犯罪统计数据、人口统计信息、经济指标、天气模式等。通过识别人类分析师可能忽视的趋势,人工智能可以为执法机构
 改进的检测算法:用于高分辨率光学遥感图像目标检测
Jun 06, 2024 pm 12:33 PM
改进的检测算法:用于高分辨率光学遥感图像目标检测
Jun 06, 2024 pm 12:33 PM
01前景概要目前,难以在检测效率和检测结果之间取得适当的平衡。我们就研究出了一种用于高分辨率光学遥感图像中目标检测的增强YOLOv5算法,利用多层特征金字塔、多检测头策略和混合注意力模块来提高光学遥感图像的目标检测网络的效果。根据SIMD数据集,新算法的mAP比YOLOv5好2.2%,比YOLOX好8.48%,在检测结果和速度之间实现了更好的平衡。02背景&动机随着远感技术的快速发展,高分辨率光学远感图像已被用于描述地球表面的许多物体,包括飞机、汽车、建筑物等。目标检测在远感图像的解释中
 算法在 58 画像平台建设中的应用
May 09, 2024 am 09:01 AM
算法在 58 画像平台建设中的应用
May 09, 2024 am 09:01 AM
一、58画像平台建设背景首先和大家分享下58画像平台的建设背景。1.传统的画像平台传统的思路已经不够,建设用户画像平台依赖数据仓库建模能力,整合多业务线数据,构建准确的用户画像;还需要数据挖掘,理解用户行为、兴趣和需求,提供算法侧的能力;最后,还需要具备数据平台能力,高效存储、查询和共享用户画像数据,提供画像服务。业务自建画像平台和中台类型画像平台主要区别在于,业务自建画像平台服务单条业务线,按需定制;中台平台服务多条业务线,建模复杂,提供更为通用的能力。2.58中台画像建设的背景58的用户画像
 实时加SOTA一飞冲天!FastOcc:推理更快、部署友好Occ算法来啦!
Mar 14, 2024 pm 11:50 PM
实时加SOTA一飞冲天!FastOcc:推理更快、部署友好Occ算法来啦!
Mar 14, 2024 pm 11:50 PM
写在前面&笔者的个人理解在自动驾驶系统当中,感知任务是整个自驾系统中至关重要的组成部分。感知任务的主要目标是使自动驾驶车辆能够理解和感知周围的环境元素,如行驶在路上的车辆、路旁的行人、行驶过程中遇到的障碍物、路上的交通标志等,从而帮助下游模块做出正确合理的决策和行为。在一辆具备自动驾驶功能的车辆中,通常会配备不同类型的信息采集传感器,如环视相机传感器、激光雷达传感器以及毫米波雷达传感器等等,从而确保自动驾驶车辆能够准确感知和理解周围环境要素,使自动驾驶车辆在自主行驶的过程中能够做出正确的决断。目
 开创性CVM算法破解40多年计数难题!计算机科学家掷硬币算出「哈姆雷特」独特单词
Jun 07, 2024 pm 03:44 PM
开创性CVM算法破解40多年计数难题!计算机科学家掷硬币算出「哈姆雷特」独特单词
Jun 07, 2024 pm 03:44 PM
计数,听起来简单,却在实际执行很有难度。想象一下,你被送到一片原始热带雨林,进行野生动物普查。每当看到一只动物,拍一张照片。数码相机只是记录追踪动物总数,但你对独特动物的数量感兴趣,却没有统计。那么,若想获取这一独特动物数量,最好的方法是什么?这时,你一定会说,从现在开始计数,最后再从照片中将每一种新物种与名单进行比较。然而,这种常见的计数方法,有时并不适用于高达数十亿条目的信息量。来自印度统计研究所、UNL、新加坡国立大学的计算机科学家提出了一种新算法——CVM。它可以近似计算长列表中,不同条
