

有了GPT-4之后,机器人把转笔、盘核桃都学会了

在学习方面,GPT-4 是一个厉害的学生。在消化了大量人类数据后,它掌握了各门知识,甚至在聊天中能给数学家陶哲轩带来启发。
与此同时,它也成为了一名优秀的老师,而且不光是教书本知识,还能教机器人转笔。

这个机器人名叫 Eureka,是来自英伟达、宾夕法尼亚大学、加州理工学院和得克萨斯大学奥斯汀分校的一项研究。这项研究结合了大型语言模型和强化学习的研究成果:用 GPT-4 来完善奖励函数,用强化学习来训练机器人控制器。
借助 GPT-4 写代码的能力,Eureka 拥有了出色的奖励函数设计能力,它自主生成的奖励在 83% 的任务中优于人类专家的奖励。这种能力可以让机器人完成很多之前不容易完成的任务,比如转笔、打开抽屉和柜子、抛球接球和盘球、操作剪刀等。不过,这一切暂时都是在虚拟环境中完成的。



此外,Eureka 还实现了一种新型的 in-context RLHF,它能够将人类操作员的自然语言反馈纳入其中,以引导和对齐奖励函数。它可以为机器人工程师提供强大的辅助功能,帮助工程师设计复杂的运动行为。英伟达高级 AI 科学家 Jim Fan 也是该论文的作者之一,他将这项研究比喻为「物理模拟器 API 空间中的旅行者号(美国研制并建造的外层星系空间探测器)」。

值得一提的是,这项研究是完全开源的,开源地址如下:

- 论文链接:https://arxiv.org/pdf/2310.12931.pdf
- 项目链接:https://eureka-research.github.io/
- 代码链接:https://github.com/eureka-research/Eureka
论文概览
大型语言模型(LLM)在机器人任务的高级语义规划方面表现出色(比如谷歌的 SayCan、RT-2 机器人),但它们是否可以用于学习复杂的低级操作任务,如转笔,仍然是一个悬而未决的问题。现有的尝试需要大量的领域专业知识来构建任务提示或只学习简单的技能,远远达不到人类水平的灵活性。

谷歌的 RT-2 机器人。
另一方面,强化学习(RL)在灵活性以及其他许多方面取得了令人印象深刻的成果(比如 OpenAI 会玩魔方的机械手),但需要人类设计师仔细构建奖励函数,准确地编纂并提供所需行为的学习信号。由于许多现实世界的强化学习任务只提供难以用于学习的稀疏奖励,因此在实践中需要奖励塑造(reward shaping),以提供渐进的学习信号。尽管奖励函数非常重要,但众所周知,它很难设计。最近的一项调查发现,92% 的强化学习受访研究人员和从业者表示,他们在设计奖励时进行了人工试错,89% 的人表示他们设计的奖励是次优的,会导致非预期行为。
鉴于奖励设计如此重要,我们不禁要问,是否有可能利用最先进的编码 LLM(如 GPT-4)来开发一种通用的奖励编程算法?这些 LLM 在代码编写、零样本生成以及 in-context learning 等方面表现出色,曾经大大提升了编程智能体的性能。理想情况下,这种奖励设计算法应具有人类水平的奖励生成能力,可扩展到广泛的任务范围,在没有人类监督的情况下自动完成乏味的试错过程,同时与人类监督兼容,以确保安全性和一致性。
这篇论文提出了一种由 LLM 驱动的奖励设计算法 EUREKA(全称是 Evolution-driven Universal REward Kit for Agent)。该算法达成了以下成就:
1、在 29 种不同的开源 RL 环境中,奖励设计的性能达到了人类水平,这些环境包括 10 种不同的机器人形态(四足机器人、四旋翼机器人、双足机器人、机械手以及几种灵巧手,见图 1。在没有任何特定任务提示或奖励模板的情况下,EUREKA 自主生成的奖励在 83% 的任务中优于人类专家的奖励,并实现了 52% 的平均归一化改进。

2、解决了以前无法通过人工奖励工程实现的灵巧操作任务。以转笔问题为例,在这种情况下,一只有五根手指的手需要按照预先设定的旋转配置快速旋转钢笔,并尽可能多地旋转几个周期。通过将 EUREKA 与课程学习相结合,研究者首次在模拟拟人「Shadow Hand」上演示了快速转笔的操作(见图 1 底部)。
3、为基于人类反馈的强化学习(RLHF)提供了一种新的无梯度上下文学习方法,可以基于各种形式的人类输入生成更高效、与人类对齐程度更高的奖励函数。论文表明,EUREKA 可以从现有的人类奖励函数中获益并加以改进。同样,研究者还展示了 EUREKA 利用人类文本反馈来辅助设计奖励函数的能力,这有助于捕捉到人类的细微偏好。
与之前使用 LLM 辅助奖励设计的 L2R 工作不同,EUREKA 完全没有特定任务提示、奖励模板以及少量示例。在实验中,EUREKA 的表现明显优于 L2R,这得益于它能够生成和完善自由形式、表达能力强的奖励程序。
EUREKA 的通用性得益于三个关键的算法设计选择:将环境作为上下文、进化搜索和奖励反思(reward reflection)。
首先,通过将环境源代码作为上下文,EUREKA 可以从主干编码 LLM(GPT-4)中零样本生成可执行的奖励函数。然后,EUREKA 通过执行进化搜索,迭代地提出奖励候选批次,并在 LLM 上下文窗口中精炼最有希望的奖励,从而大大提高了奖励的质量。这种 in-context 的改进通过奖励反思来实现,奖励反思是基于策略训练统计数据的奖励质量文本总结,可实现自动和有针对性的奖励编辑。
图 3 为 EUREKA 零样本奖励示例,以及优化过程中积累的各项改进。为了确保 EUREKA 能够将其奖励搜索扩展到最大潜力,EUREKA 在 IsaacGym 上使用 GPU 加速的分布式强化学习来评估中间奖励,这在策略学习速度上提供了高达三个数量级的提升,使 EUREKA 成为一个广泛的算法,随着计算量的增加而自然扩展。

如图 2 所示。研究者致力于开源所有提示、环境和生成的奖励函数,以促进基于 LLM 的奖励设计的进一步研究。

方法介绍
EUREKA 可以自主的编写奖励算法,具体是如何实现的,我们接着往下看。
EUREKA 由三个算法组件组成:1)将环境作为上下文,从而支持零样本生成可执行奖励;2)进化搜索,迭代地提出和完善奖励候选;3)奖励反思,支持细粒度的奖励改进。
环境作为上下文
本文建议直接提供原始环境代码作为上下文。仅通过最少的指令,EUREKA 就可以在不同的环境中零样本地生成奖励。EUREKA 输出示例如图 3 所示。EUREKA 在提供的环境代码中熟练地组合了现有的观察变量 (例如,指尖位置),并产生了一个有效的奖励代码 —— 所有这些都没有任何特定于环境的提示工程或奖励模板。
然而,在第一次尝试时,生成的奖励可能并不总是可执行的,即使它是可执行的,也可能是次优的。这就出现了一个疑问,即如何有效地克服单样本奖励生成的次优性?

进化搜索
接着,论文介绍了进化搜索是如何解决上述提到的次优解决方案等问题的。他们是这样完善的,即在每次迭代中,EUREKA 对 LLM 的几个独立输出进行采样(算法 1 中的第 5 行)。由于每次迭代(generations)都是独立同分布的,这样一来随着样本数量的增加,迭代中所有奖励函数出现错误的概率呈指数下降。


奖励反思
为了提供更复杂、更有针对性的奖励分析,本文建议构建自动反馈来总结文本中的策略训练动态。具体来说,考虑到 EUREKA 奖励函数需要奖励程序中的各个组件(例如图 3 中的奖励组件),因而本文在整个训练过程中跟踪中间策略检查点处所有奖励组件的标量值。
构建这种奖励反思过程虽然很简单,但由于奖励优化算法存在依赖性,因而这种构建方式就显得很重要。也就是说,奖励函数是否有效受到 RL 算法的特定选择的影响,并且即使在给定超参数差异的相同优化器下,相同的奖励也可能表现得非常不同。通过详细说明 RL 算法如何优化各个奖励组件,奖励反思使 EUREKA 能够产生更有针对性的奖励编辑并合成奖励函数,从而更好地与固定 RL 算法协同。

实验
实验部分对 Eureka 进行了全面的评估,包括生成奖励函数的能力、解决新任务的能力以及对人类各种输入的整合能力。
实验环境包括 10 个不同的机器人以及 29 个任务,其中,这 29 个任务由 IsaacGym 模拟器实现。实验采用了 IsaacGym (Isaac) 的 9 个原始环境,涵盖从四足、双足、四旋翼、机械手到机器人的灵巧手的各种机器人形态。除此以外,本文还通过纳入 Dexterity 基准测试中的 20 项任务来确保评估的深度。

Eureka 可以产生超人类水平的奖励函数。在 29 项任务中,Eureka 给出的奖励函数在 83% 的任务上比专家编写的奖励表现得更好,平均提高了 52%。特别是,Eureka 在高维 Dexterity 基准测试环境中实现了更大的收益。

Eureka 能够进化奖励搜索,使奖励随着时间的推移而不断改善。Eureka 通过结合大规模的奖励搜索和详细的奖励反思反馈,逐步产生更好的奖励,最终超过人类的水平。
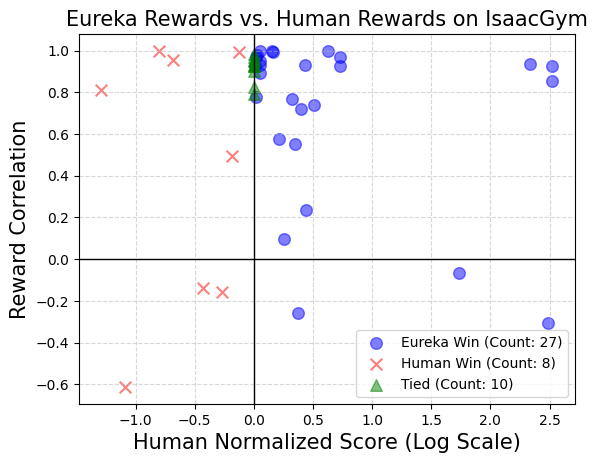
Eureka 还能产生新颖的奖励。本文通过计算所有 Isaac 任务上的 Eureka 奖励和人类奖励之间的相关性来评估 Eureka 奖励的新颖性。如图所示,Eureka 主要生成弱相关的奖励函数,其表现优于人类的奖励函数。此外,本文还观察到任务越难,Eureka 奖励的相关性就越小。在某些情况下,Eureka 奖励甚至与人类奖励呈负相关,但表现却明显优于人类奖励。

想要实现机器人的灵巧手能够不停的转笔,需要操作程序有尽可能多的循环。本文通过以下方式解决此任务:(1) 指导 Eureka 生成奖励函数,用来将笔重新定向到随机目标配置,然后 (2) 使用 Eureka 奖励微调此预训练策略以达到所需的笔序列 - 旋转配置。如图所示,Eureka 微调很快就适应了策略,成功地连续旋转了许多周期。相比之下,预训练或从头开始学习的策略都无法完成单个周期的旋转。
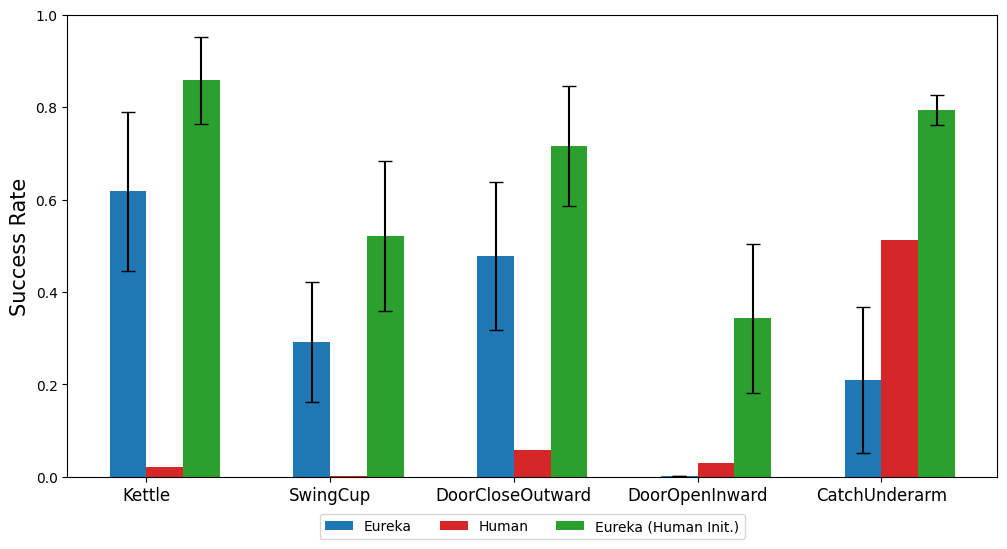
本文还研究了从人类奖励函数初始化开始是否对 Eureka 有利。如图所示,无论人类奖励的质量如何,Eureka 都会从人类奖励中改进并受益。

Eureka 还实现了 RLHF,其可以结合人类的反馈来修改奖励,从而逐步指导智能体完成更安全、更符合人类的行为。示例展示了 Eureka 如何通过一些人类反馈来教人形机器人直立奔跑,这些反馈取代了之前的自动奖励反思。

人形机器人通过 Eureka 学习跑步步态。
了解更多内容,请参考原论文。
以上是有了GPT-4之后,机器人把转笔、盘核桃都学会了的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
检查CentOS系统中HDFS配置的完整指南本文将指导您如何有效地检查CentOS系统上HDFS的配置和运行状态。以下步骤将帮助您全面了解HDFS的设置和运行情况。验证Hadoop环境变量:首先,确认Hadoop环境变量已正确设置。在终端执行以下命令,验证Hadoop是否已正确安装并配置:hadoopversion检查HDFS配置文件:HDFS的核心配置文件位于/etc/hadoop/conf/目录下,其中core-site.xml和hdfs-site.xml至关重要。使用
 centos关机命令行
Apr 14, 2025 pm 09:12 PM
centos关机命令行
Apr 14, 2025 pm 09:12 PM
CentOS 关机命令为 shutdown,语法为 shutdown [选项] 时间 [信息]。选项包括:-h 立即停止系统;-P 关机后关电源;-r 重新启动;-t 等待时间。时间可指定为立即 (now)、分钟数 ( minutes) 或特定时间 (hh:mm)。可添加信息在系统消息中显示。
 CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系统下GitLab的备份与恢复策略为了保障数据安全和可恢复性,CentOS上的GitLab提供了多种备份方法。本文将详细介绍几种常见的备份方法、配置参数以及恢复流程,帮助您建立完善的GitLab备份与恢复策略。一、手动备份利用gitlab-rakegitlab:backup:create命令即可执行手动备份。此命令会备份GitLab仓库、数据库、用户、用户组、密钥和权限等关键信息。默认备份文件存储于/var/opt/gitlab/backups目录,您可通过修改/etc/gitlab
 centos安装mysql
Apr 14, 2025 pm 08:09 PM
centos安装mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安装 MySQL 涉及以下步骤:添加合适的 MySQL yum 源。执行 yum install mysql-server 命令以安装 MySQL 服务器。使用 mysql_secure_installation 命令进行安全设置,例如设置 root 用户密码。根据需要自定义 MySQL 配置文件。调整 MySQL 参数和优化数据库以提升性能。
 CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系统上进行PyTorch分布式训练,需要按照以下步骤操作:PyTorch安装:前提是CentOS系统已安装Python和pip。根据您的CUDA版本,从PyTorch官网获取合适的安装命令。对于仅需CPU的训练,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,请确保已安装对应版本的CUDA和cuDNN,并使用相应的PyTorch版本进行安装。分布式环境配置:分布式训练通常需要多台机器或单机多GPU。所
 docker原理详解
Apr 14, 2025 pm 11:57 PM
docker原理详解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux内核特性,提供高效、隔离的应用运行环境。其工作原理如下:1. 镜像作为只读模板,包含运行应用所需的一切;2. 联合文件系统(UnionFS)层叠多个文件系统,只存储差异部分,节省空间并加快速度;3. 守护进程管理镜像和容器,客户端用于交互;4. Namespaces和cgroups实现容器隔离和资源限制;5. 多种网络模式支持容器互联。理解这些核心概念,才能更好地利用Docker。
 CentOS下GitLab的日志如何查看
Apr 14, 2025 pm 06:18 PM
CentOS下GitLab的日志如何查看
Apr 14, 2025 pm 06:18 PM
CentOS系统下查看GitLab日志的完整指南本文将指导您如何查看CentOS系统中GitLab的各种日志,包括主要日志、异常日志以及其他相关日志。请注意,日志文件路径可能因GitLab版本和安装方式而异,若以下路径不存在,请检查GitLab安装目录及配置文件。一、查看GitLab主要日志使用以下命令查看GitLabRails应用程序的主要日志文件:命令:sudocat/var/log/gitlab/gitlab-rails/production.log此命令会显示produc
 CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
在CentOS系统上启用PyTorchGPU加速,需要安装CUDA、cuDNN以及PyTorch的GPU版本。以下步骤将引导您完成这一过程:CUDA和cuDNN安装确定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA显卡支持的CUDA版本。例如,您的MX450显卡可能支持CUDA11.1或更高版本。下载并安装CUDAToolkit:访问NVIDIACUDAToolkit官网,根据您显卡支持的最高CUDA版本下载并安装相应的版本。安装cuDNN库:前
