

科大讯飞:华为升腾 910B 能力基本可对标英伟达 A100,正合力打造我国通用人工智能新底座

本站 10 月 22 日消息,今年第三季度,科大讯飞实现净利润 2579 万元,同比下降 81.86%;前三季度净利润 9936 万元,同比下降 76.36%。
科大讯飞副总裁江涛在Q3 业绩说明会上透露,讯飞已于2023 年初与华为升腾启动专项攻关,与华为联合研发高性能算子库,合力打造我国通用人工智能新底座,让国产大模型架构在自主创新的软硬件基础之上。
他指出,目前华为升腾 910B 能力已经基本做到可对标英伟达 A100。在即将举行的科大讯飞 1024 全球开发者节上,讯飞和华为在人工智能算力底座上将有进一步联合发布。

他还提到,该公司一直致力于实现算法提升和工程技术方面的加速。自2019 年被列入美国实体清单后,公司于2022 年10 月7 日再次被美国对包括科大讯飞在内的28 家中国人工智能、高性能芯片、超级计算机领域的头部企业和机构加码制裁。
本站查询公开资料发现,海思升腾 910 发布于 2019 年,同时还推出了与之配套的新一代 AI 开源计算框架 MindSpore,而 MindSpore 也已经于 2020 年完成开源。
目前,华为升腾社区已公开Atlas 300T 产品有三个型号,分别对应升腾910A、910B、910 Pro B,最大300W 功耗,前两者AI 算力均为256 TFLOPS,而910 Pro B 可达280 TFLOPS(FP16)。


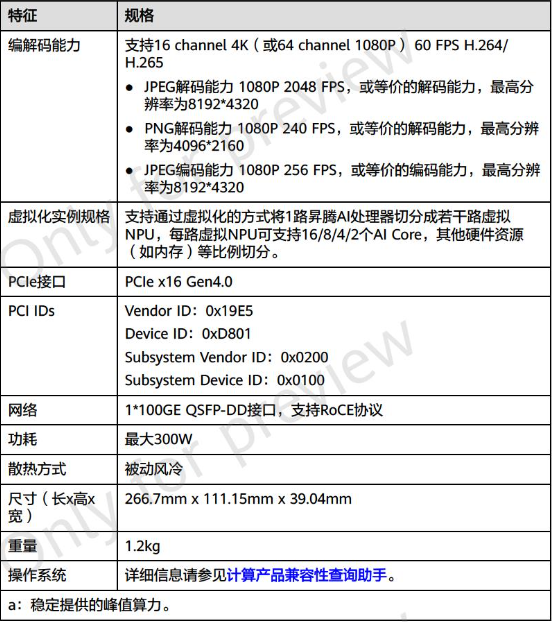



作为对比,NVIDIA A100 发布于2020 年,采用双精度Tensor Core,基于Ampere架构,功耗达到了400W,FP32 浮点性能19.5TFLOPS,FP16 Tensor Core 性能可达312TFLOPS。
按照华为官方给出的规格,升腾 910 Pro B 要比 A100 慢 18% 左右。
说到这里也顺便提一下 A800 芯片。这颗芯片是为了解决去年的美国商务部的半导体出口规定特意推出的一款型号,算力等参数完全不变,只是传输速率为从每秒600GB 降至400GB,所以美国本周发布的半导体出口新规封堵了这一漏洞。
根据知乎上AI 从业者的反馈,哪怕升腾910B 目前还有不少小问题、单卡性能落后于A800、Arm 生态有所欠缺(应该是指CANN 对比CUDA),但随着英伟达先进产品被禁,后续国内厂商只能被迫选择升腾,相信升腾产品会更加完善,并且国产厂商还可以通过堆量、增加算力集群规模的方式完成替换,至少在大模型训练领域整体差距不大。

值得一提的是,PyTorch 基金会本周三正式宣布华为作为 Premier 会员加入基金会,这也是中国首个、全球第十个 PyTorch 基金会最高级别会员。
除此之外,PyTorch 最新的 2.1 版本已同步支持升腾 NPU,并在华为的推动下更新了更加完善的第三方设备接入机制。基于该特性,三方 AI 算力设备无需对原有框架代码进行修改就能对接 PyTorch 框架,升腾也提供了官方认证的 Torch NPU 参考实现,可以指导三方设备便捷接入。
基于新版本,用户可以在升腾 NPU 上直接享受原生 PyTorch 的开发体验,获得高效运行在升腾算力设备上的模型和应用。
相关阅读:
《华为与科大讯飞启动AI 存力底座联合创新项目》
《科大讯飞刘庆峰:华为GPU 可对标英伟达A100,通用大模型明年上半年对标GPT-4》
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,本站所有文章均包含本声明。
以上是科大讯飞:华为升腾 910B 能力基本可对标英伟达 A100,正合力打造我国通用人工智能新底座的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 余承东透露华为三折屏手机9月亮相:售价估计不便宜
Aug 20, 2024 am 06:36 AM
余承东透露华为三折屏手机9月亮相:售价估计不便宜
Aug 20, 2024 am 06:36 AM
8月19日,鸿蒙智行在上海为享界S9举办了首批车主交车仪式,华为高管余承东亲自出席并为车主交付车辆。现场,一位已拥有问界M5、M7、M9的车主向余承东询问什么时候可以买到华为三折叠屏手机,余承东回应,下个月会有。fenyefenye此前,网络上已流出疑似华为三折叠屏手机的实拍图,引发广泛关注。图中,余承东手持的新机展现了非凡的视觉冲击力,其屏幕尺寸远超常规折叠屏手机,设计独特,非平板却胜似平板。左侧顶部镶嵌的居中挖孔摄像头,以及隐约可见的双折痕设计,手机侧面疑似配备了手写笔。这些线索无不指向,这
 华为 Mate 60 系列最佳入手时机,新增 AI 消除 + 影像升级,更可享秋日礼遇活动
Aug 29, 2024 pm 03:33 PM
华为 Mate 60 系列最佳入手时机,新增 AI 消除 + 影像升级,更可享秋日礼遇活动
Aug 29, 2024 pm 03:33 PM
自去年华为Mate60系列开售以来,我个人就一直将Mate60Pro作为主力机使用。在将近一年的时间里,华为Mate60Pro经过多次OTA升级,综合体验有了显着提升,给人一种常用常新的感觉。比如近期,华为Mate60系列就再度迎来了影像功能的重磅升级。首先是新增AI消除功能,可以智能消除路人、杂物并对空白部分进行自动补充;其次是主摄色准、长焦清晰度均有明显升级。考虑到现在是开学季,华为Mate60系列还推出了秋日礼遇活动:购机可享至高800元优惠,入手价低至4999元。常用常新的产品力加上超值
 苹果华为都想做的无按键手机,被小米先做出来了?
Aug 29, 2024 pm 03:33 PM
苹果华为都想做的无按键手机,被小米先做出来了?
Aug 29, 2024 pm 03:33 PM
根据Smartprix的爆料称,小米正在研发一台代号为「朱雀」的无按键手机。这份爆料称,这台代号朱雀的手机将秉承一体化的理念设计,使用屏下摄像头,并搭载高通骁龙8gen4处理器,如果计划没有变动,我们很可能在2025年看到它的到来。看到这个消息,我恍惚间以为自己回到了2019年——那时候小米发布了小米MIXAlpha概念机,环绕屏无按键设计相当惊艳。这是我第一次见识到无按键手机的魅力。想要一块「魔力玻璃」,就要先把按键干掉在《乔布斯传》中,乔布斯曾经表达过:希望手机能够像一块「充满魔力的玻璃」,
 华为将在智能穿戴领域推出玄玑感知系统 可根据心率评估用户情绪状态
Aug 29, 2024 pm 03:30 PM
华为将在智能穿戴领域推出玄玑感知系统 可根据心率评估用户情绪状态
Aug 29, 2024 pm 03:30 PM
近日,华为宣布将于9月推出一款搭载玄玑感知系统的全新智能穿戴新品,预计为华为的最新智能手表。该新品将集成先进的情绪健康监测功能,玄玑感知系统以其六大特性——准确性、全面性、快速性、灵活性、开放性和延展性——为用户提供全方位的健康评估。系统采用超感知模组,优化了多通道光路架构技术,大幅提升了心率、血氧和呼吸率等基础指标的监测精度。此外,玄玑感知系统还拓展了基于心率数据的情绪状态研究,不仅限于生理指标,还能评估用户的情绪状态和压力水平,支持超过60项运动健康指标监测,涵盖心血管、呼吸、神经、内分泌、
 Mate 60降价800元、Pura 70降价1000元:就等华为发布Mate 70了!
Aug 16, 2024 pm 03:45 PM
Mate 60降价800元、Pura 70降价1000元:就等华为发布Mate 70了!
Aug 16, 2024 pm 03:45 PM
8月16日消息,对于现在的华为手机来说,已经在努力给接下来新机上市扫清道路了,所以大家看到了Mate60系列和Pura70系列陆续降价。随着8月15日,华为官宣Mate60系列降价,华为这两大旗舰系列的最新机型均已完成价格调整。今年7月,华为官方宣布,华为Pura70系列开启促销,降幅最高达1000元。其中,华为Pura70直降500元,到手价4999元起;华为Pura70北斗卫星消息版直降500元,到手价5099元起;华为Pura70Pro直降800元,到手价5699元起;华为Pura70Pr
 2024Q2 全球移动程序化广告报告:苹果 iPhone 51% 话语权份额领衔,三星、华为和小米追赶
Aug 22, 2024 pm 02:05 PM
2024Q2 全球移动程序化广告报告:苹果 iPhone 51% 话语权份额领衔,三星、华为和小米追赶
Aug 22, 2024 pm 02:05 PM
本站8月22日消息,市场调查机构Pixalate昨日(8月21日)发布报告,称在全球移动程序化广告市场中,苹果公司以51%的话语权份额(SOV)位居榜首。相关名词解释本站简要介绍下专有名词:程序化广告(ProgrammaticAdvertising):程序化广告是指利用广告技术手段来购买并销售数字广告。程序化广告可以在不到一秒的时间内通过自动操作步骤向受众展示相关的广告。话语权份额(shareofvoice,简称SOV):由Pixalate测算,每个地区与特定设备类型相关的开放式程序化广告销售百
 华为为 Mate X5 等多款机型提供优惠 最高降价上千元
Aug 29, 2024 pm 03:32 PM
华为为 Mate X5 等多款机型提供优惠 最高降价上千元
Aug 29, 2024 pm 03:32 PM
8月29日,华为终端官方宣布,华为先锋感恩回馈季开启!即刻入手华为MateX5、华为Pocket2、华为novaFlip、华为Pura70系列、华为Mate60系列可享购机礼遇。不过,华为官方并未详细说明"购机礼遇"的具体权益。1.华为MateX5CNMO在华为商城查询到,目前华为MateX5降价1500元,先锋感恩回馈季购机享HUAWEICare+(一年期),咨询客服领取;华为Pocket2购机赠价值199元Pocket2绮梦彩蝶保护壳,限10点/16点/20点,每整点下单
 全球第一款三折叠屏!华为Mate XT屏幕供应商曝光
Sep 03, 2024 pm 06:34 PM
全球第一款三折叠屏!华为Mate XT屏幕供应商曝光
Sep 03, 2024 pm 06:34 PM
9月3日消息,今天,华为终端公布了非凡大师系列新成员——MateXT。华为余承东转发此微博,使用的手机正是MateXT非凡大师。据悉,MateXT将是非凡大师系列首款折叠屏手机,预计为三折叠形态,在预告视频中,数字“3”一闪而过,表明新品是一款三折叠屏旗舰。博主数码闲聊站暗示,华为MateXT非凡大师新品的屏幕供应商为京东方,这也是行业内第一家量产三折叠屏的屏厂。此前在今年8月份,余承东被拍到在飞机上使用三折叠屏手机,从曝光图的图片来看,华为三折叠屏手机非常薄。华为三折叠屏手机1.
