
作者:叶小飞
链接:https://www.zhihu.com/question/269707221/answer/2281374258
我之前在北美奔驰落地时,曾有段时间为了测试不同的结构和参数,一周能训练一百来个不同的模型,为此我结合公司前辈们的做法和自己的一点思考总结了一套高效的代码实验管理方法,成功帮助了项目落地, 现在在这里分享给大家。
我知道很多开源repo喜欢用input argparse来传输一大堆训练和模型相关的参数,其实非常不高效。一方面,你每次训练都需要手动输入大量参数会很麻烦,如果直接改默认值又要跑到代码里去改,会浪费很多时间。这里我推荐大家直接使用一个Yaml file来控制所有模型和训练相关的参数,并将该yaml的命名与模型名字和时间戳联系起来,著名的3d点云检测库OpenPCDet就是这么做的,如下方这个链接所示。
github.com/open-mmlab/OpenPCDet/blob/master/tools/cfgs/kitti_models/pointrcnn.yaml
我从上方给的链接截了该yaml文件部分内容,如下图所示,这个配置文件涵盖了如何预处理点云,classification的种类,还有backbone各方面的参数、optimzer和loss的选择(图中未展示,完整请看上方链接)。也就是说,基本所有能影响你模型的因素,都被涵括在了这个文件里,而在代码中,你只需要用一个简单的 yaml.load()就能把这些参数全部读到一个dict里。更关键的是,这个配置文件可以随着你的checkpoint一起被存到相同的文件夹,方便你直接拿来做断点训练、finetune或者直接做测试,用来做测试时你也可以很方便把结果和对应的参数对上。

有些研究人员写代码时喜欢把整个系统写的过于耦合,比如把loss function和模型写到一起,这就会经常导致牵一发而动全身,你改动某一小块就会导致后面的接口也全变,所以代码模块化做的好,可以节省你许多时间。一般的深度学习代码基本可以分为这么几大块(以pytorch为例):I/O模块、预处理模块、可视化模块、模型主体(如果一个大模型包含子模型则应该另起class)、损失函数、后处理,并在训练或者测试脚本里串联起来。代码模块化的另一好处,就是方便你在yaml里去定义不同方面的参数,便于阅览。另外很多成熟代码里都会用到importlib神库,它可以允许你不把训练时用哪个模型或者哪个子模型在代码里定死,而是可以直接在yaml里定义。
这两个库我基本上每次必用。Tensorboard可以很好的追踪你训练的loss曲线变化,方便你判断模型是否还在收敛、是否overfit,如果你是做图像相关,还可以把一些可视化结果放在上面。很多时候你只需要看看tensorboard的收敛状态就基本知道你这个模型怎么样,有没有必要花时间再单独测试、finetune. Tqdm则可以帮你很直观地跟踪你的训练进度,方便你做early stop.
无论你是多人合作开发还是单独项目,我都强烈建议使用Github(公司可能会使用bitbucket, 差不多)记录你的代码。具体可以参考我这篇回答:
作为一个研究生,有哪些你直呼好用的科研神器?
https://www.zhihu.com/question/484596211/answer/2163122684
我一般会保存一个总的excel来记录实验结果,第一列是模型对应的yaml的路径,第二列是模型训练epoches, 第三列是测试结果的log, 我一般会把这个过程自动化,只要在测试脚本中给定总excel路径,利用pandas可以很轻松地搞定。
作者:Jason
链接:https://www.zhihu.com/question/269707221/answer/470576066
git管理代码是跟深度学习、科研都没关系的,写代码肯定要用版本管理工具。用不用github个人觉着倒是两可,毕竟公司内是不可能所有代码都挂外部git的。
那么说几个写代码的时候需要注意的地方吧:
一方面外部传入参数可以避免git上过多的版本修改是由于参数导致的,介于DL不好debug,有时候利用git做一下代码比对是在所难免的;
另一方面当试验了万千版本之后,相信你不会知道哪个model是哪些参数了,好的习惯是非常有效的。另外新加的参数尽量提供default值,方便调用老版的config文件。
同一个项目里,好的复用性是编程的一种非常好的习惯,但是在飞速发展的DL coding中,假设项目是以任务驱动的,这也许有时候会成为牵绊,所以尽量把可复用的一些函数提取出来,模型结构相关的尽量让不同的模型解耦在不同的文件中,反而会更加方便日后的update。否则一些看似优美的设计几个月之后就变得很鸡肋。
往往有个尴尬的情况,从一个项目开始到结束,框架update了好几个版本,新版有一些让人垂涎若滴的特性,但是无奈有些api发生了change。所以在项目内可以尽量保持框架版本稳定,项目开始前尽量考量一下不同版本的利弊,有时候适当的学习是必要的。
另外,对不同的框架怀揣着一颗包容的心。
作者:OpenMMLab
链接:https://www.zhihu.com/question/269707221/answer/2480772257
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题主你好呀,前面的回答提到了使用 Tensorboard、Weights&Biases、MLFlow、Neptune 等工具来管理实验数据。然而随着实验管理工具的轮子越造越多,工具的学习成本也越来越高,我们又应该如何选择呢?
MMCV 满足你的所有幻想,通过修改配置文件就能实现工具的切换。
github.com/open-mmlab/mmcv
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='TensorboardLoggerHook') ])
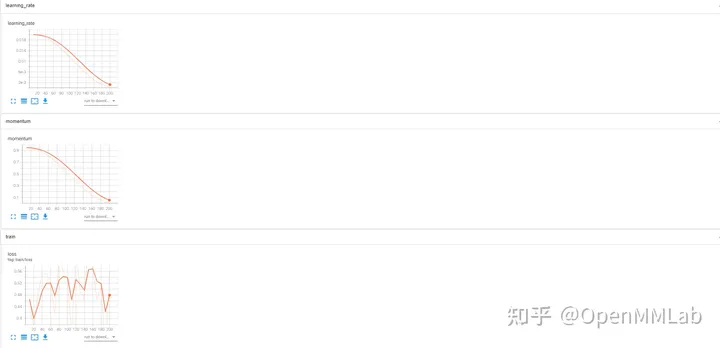
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='WandbLoggerHook') ])
(需要提前用 python api 登录 wandb)
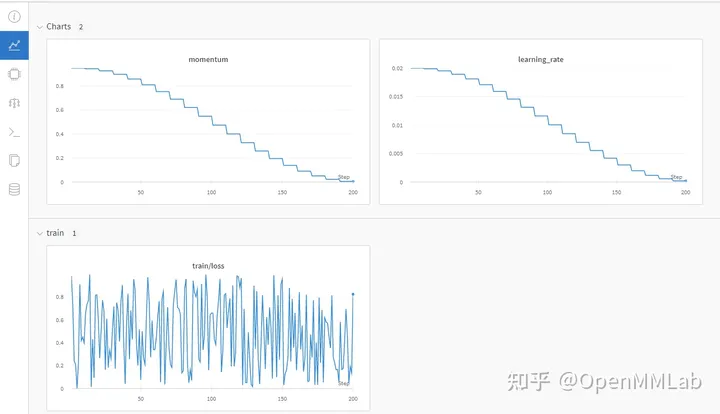
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='NeptuneLoggerHook', init_kwargs=dict(project='Your Neptume account/mmcv')) ])
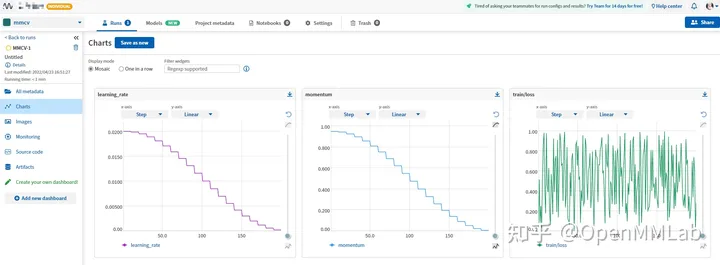
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='MlflowLoggerHook') ])
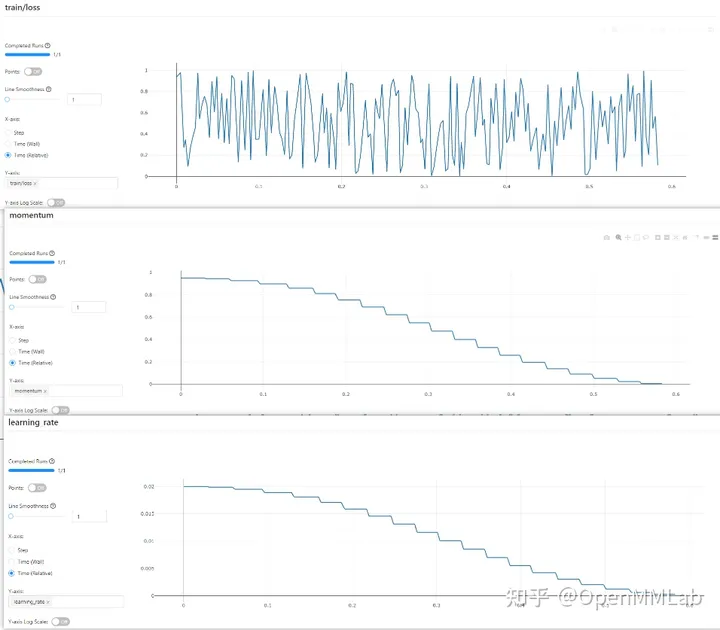
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='DvcliveLoggerHook') ])
以上只使用了各种实验管理工具最基本的功能,我们可以进一步修改配置文件来解锁更多姿势。
拥有了 MMCV,就相当于拥有了所有的实验管理工具。如果你以前是 tf boy,可以选择 TensorBoard 经典怀旧风;如果你想应有尽有的记录实验数据、实验环境,不妨尝试一下 Wandb(Weights & Biases)或者 Neptume;如果你的设备没法联网,可以选择 mlflow 将实验数据存到本地,总有一款工具适合你。
此外 MMCV 也有自己的日志管理系统,那就是 TextLoggerHook !它会将训练过程中产生的全量信息,例如设备环境、数据集、模型初始化方式、训练期间产生的 loss、metric 等信息,全部保存到本地的 xxx.log 文件。你可以在不借助任何工具的情况下,回顾之前的实验数据。
还在纠结使用哪个实验管理工具?还在苦恼于各种工具的学习成本?赶快上车 MMCV ,几行配置文件无痛体验各种工具。
github.com/open-mmlab/mmcv
以上是深度学习科研,如何高效进行代码和实验管理?的详细内容。更多信息请关注PHP中文网其他相关文章!






















