
在算力为王的时代,你的 GPU 可以顺畅的运行大模型(LLM)吗?
对于这一问题,很多人都难以给出确切的回答,不知该如何计算 GPU 内存。因为查看 GPU 可以处理哪些 LLM 并不像查看模型大小那么容易,在推理期间(KV 缓存)模型会占用大量内存,例如,llama-2-7b 的序列长度为 1000,需要 1GB 的额外内存。不仅如此,模型在训练期间,KV 缓存、激活和量化都会占用大量内存。
我们不禁要问,能不能提前了解上述内存的占用情况。近几日,GitHub 上新出现了一个项目,可以帮你计算在训练或推理 LLM 的过程中需要多少 GPU 内存,不仅如此,借助该项目,你还能知道详细的内存分布情况、评估采用什么的量化方法、处理的最大上下文长度等问题,从而帮助用户选择适合自己的 GPU 配置。
项目地址:https://github.com/RahulSChand/gpu_poor
不仅如此,这个项目还是可交互的,如下所示,它能计算出运行 LLM 所需的 GPU 内存,简单的就像填空题一样,用户只需输入一些必要的参数,最后点击一下蓝色的按钮,答案就出来了。
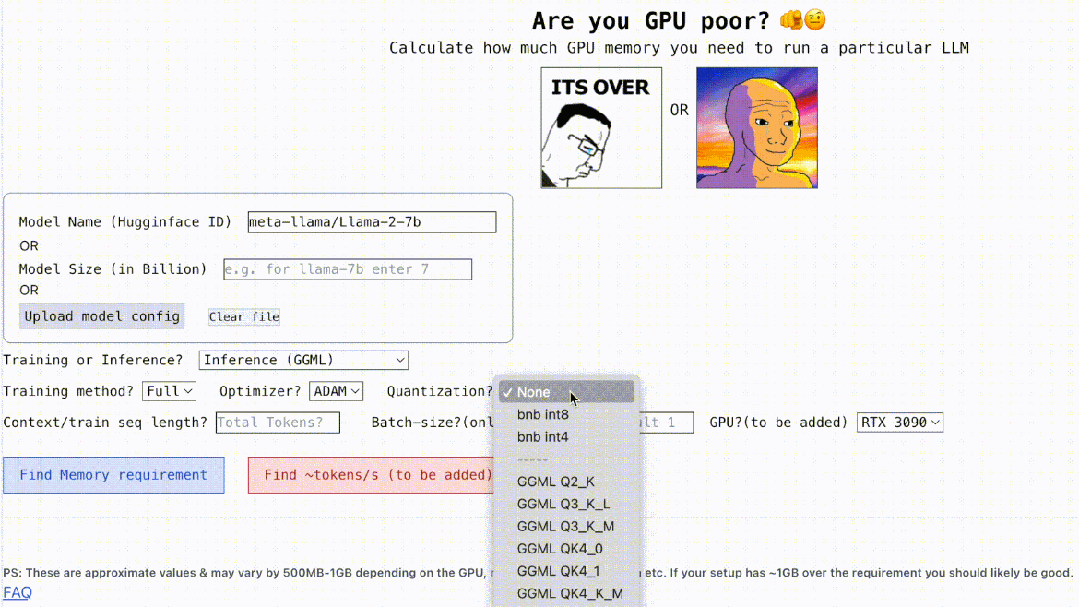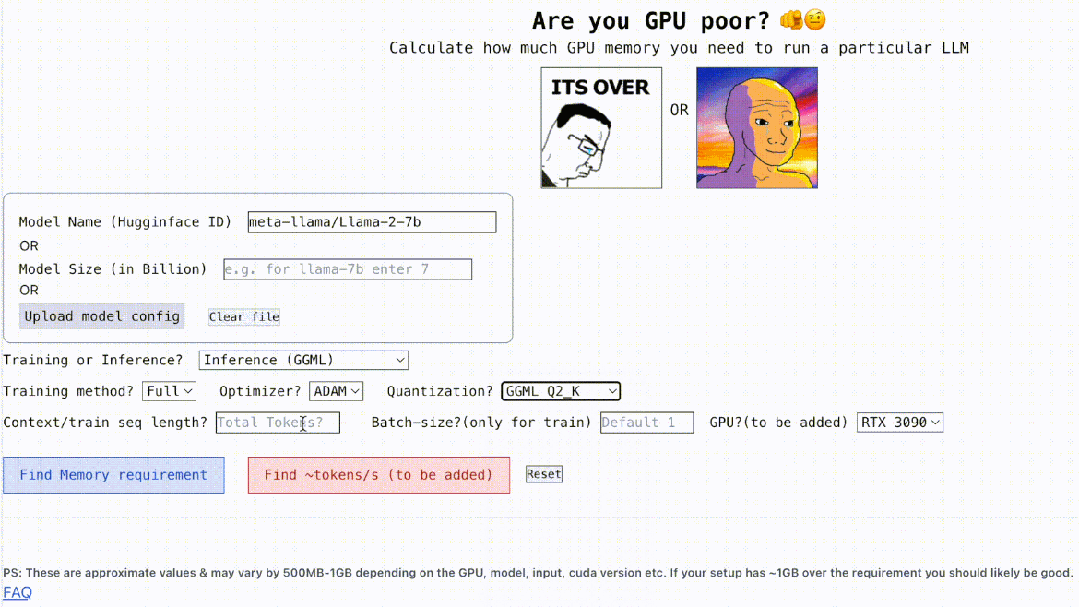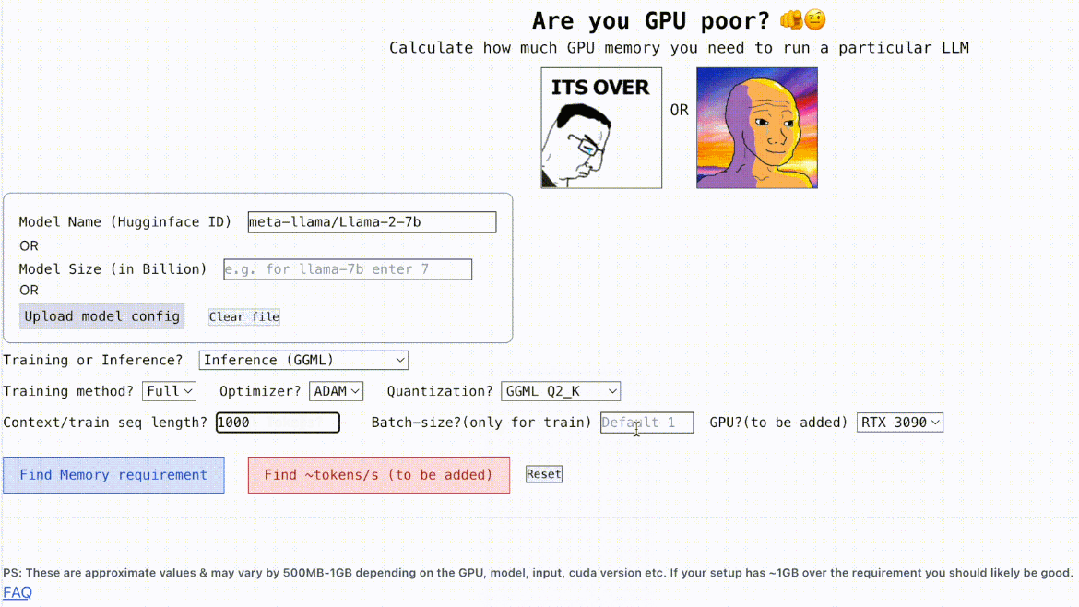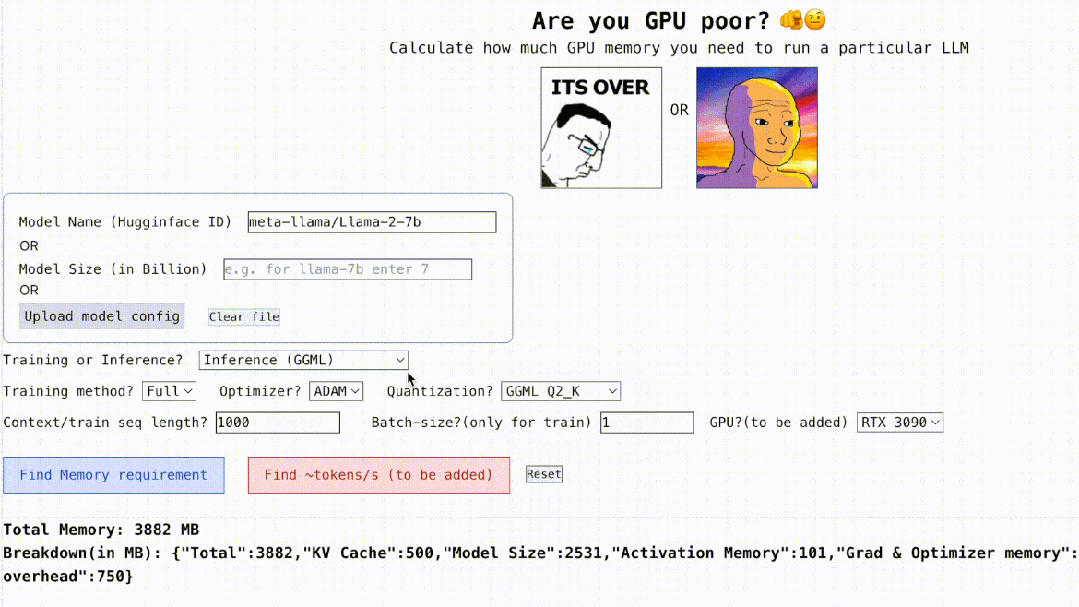
交互地址:https://rahulschand.github.io/gpu_poor/
最终的输出形式是这样子的:
{"Total": 4000,"KV Cache": 1000,"Model Size": 2000,"Activation Memory": 500,"Grad & Optimizer memory": 0,"cuda + other overhead":500}至于为什么要做这个项目,作者 Rahul Shiv Chand 表示,有以下原因:
那么,我们该如何使用呢?
首先是对模型名称、ID 以及模型尺寸的处理。你可以输入 Huggingface 上的模型 ID(例如 meta-llama/Llama-2-7b)。目前,该项目已经硬编码并保存了 Huggingface 上下载次数最多的 top 3000 LLM 的模型配置。
如果你使用自定义模型或 Hugginface ID 不可用,这时你需要上传 json 配置(参考项目示例)或仅输入模型大小(例如 llama-2-7b 为 70 亿)就可以了。
接着是量化,目前该项目支持 bitsandbytes (bnb) int8/int4 以及 GGML(QK_8、QK_6、QK_5、QK_4、QK_2)。后者仅用于推理,而 bnb int8/int4 可用于训练和推理。
最后是推理和训练,在推理过程中,使用 HuggingFace 实现或用 vLLM、GGML 方法找到用于推理的 vRAM;在训练过程中,找到 vRAM 进行全模型微调或使用 LoRA(目前项目已经为 LoRA 配置硬编码 r=8)、QLoRA 进行微调。
不过,项目作者表示,最终结果可能会有所不同,具体取决于用户模型、输入的数据、CUDA 版本以及量化工具等。实验中,作者试着把这些因素都考虑在内,并确保最终结果在 500MB 以内。下表是作者交叉检查了网站提供的 3b、7b 和 13b 模型占用内存与作者在 RTX 4090 和 2060 GPU 上获得的内存比较结果。所有值均在 500MB 以内。
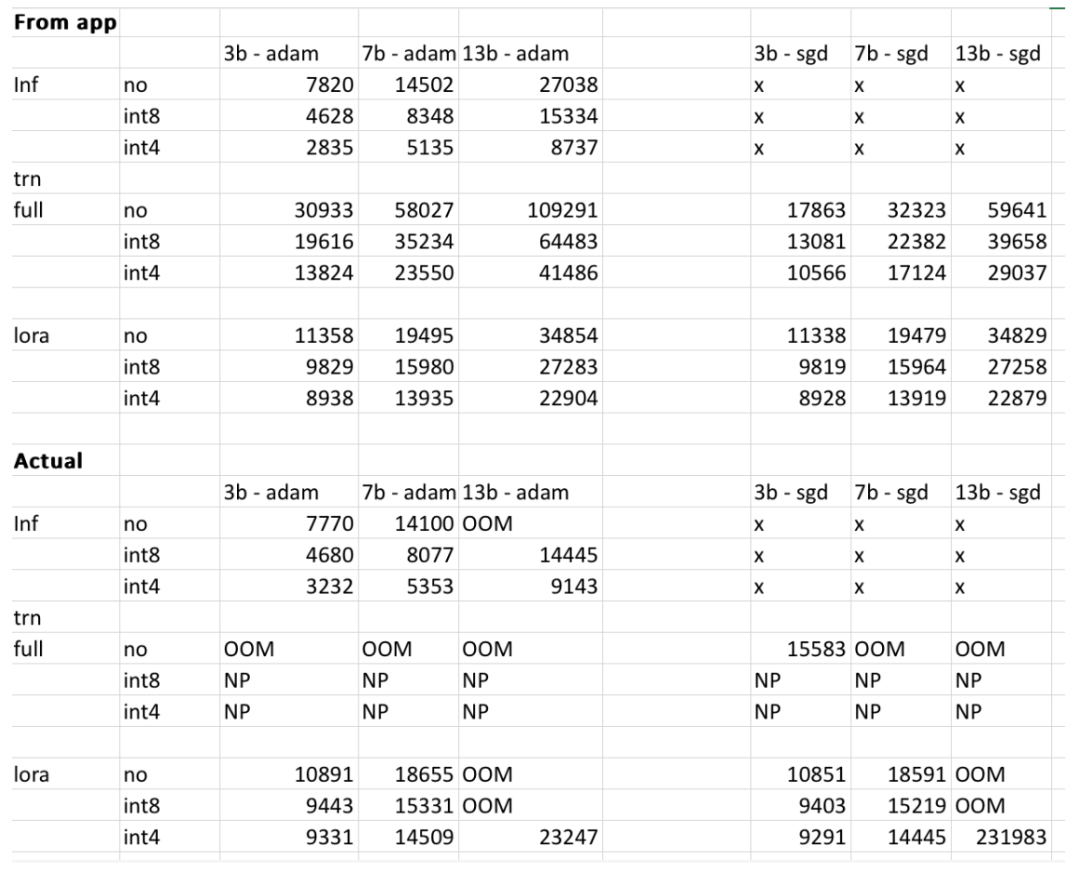
感兴趣的读者可以亲自体验一下,假如给定的结果不准确,项目作者表示,会对项目进行及时优化,完善项目。
以上是你的GPU能跑Llama 2等大模型吗?用这个开源项目上手测一测的详细内容。更多信息请关注PHP中文网其他相关文章!





















