

英伟达开创新纪元:机器人训练数据的'永动机”

之前的合成数据大多用于AI大模型训练,这一次,英伟达为机器人训练建起了“数据粮仓”——机器人技术发展步调远远落后于其他AI领域的关键原因之一,便是缺乏数据。只需200个人类演示源数据,这一系统就能直接生成50000个训练数据。
AI对数据的庞大需求之下,数据资源几近枯竭,因此各家公司已开始摸索一条获取数据的“新路”——自己“造”数据。不过之前的合成数据大多用于AI大模型训练,这一次,英伟达为机器人训练造出了“数据粮仓”。
英伟达与得克萨斯大学奥斯汀分校的一项最新研究论文中,介绍了一个名为“MimicGen”的系统,只需少量人类示范,便能自动生成大规模的机器人训练数据集。英伟达高级科学家Jim Fan表示,公司将开源一切,包括生成的数据集。
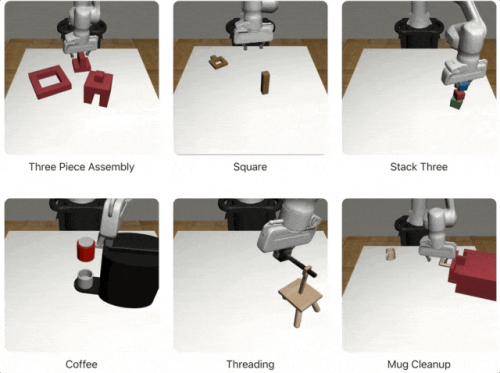
生成的数据规模有多大?利用10个人类演示,MimicGen能生成1000个合成示例;而有了200个人类演示,MimicGen更能直接生成50000个训练数据,涉及18个任务及多个模拟环境。
生成的数据集如何?
MimicGen可以在现有数据的基础上,对同一场景进行不同阶段的"演化":

其还能在广泛的任务重置分布中生成不同的数据集,包括组装物品、倒咖啡、清理马克杯等:
能生成不同的新机械臂演示:
此外还有需要长期训练的任务数据:

现实世界场景数据也不在话下:

值得注意的是,研究人员们对比了不同的源数据集生成的数据。然而他们发现,得到的两组成果不相上下——这也表明了,“在大规模数据机制中,(源)数据质量可能不那么重要”。
不仅如此,研究人员们还比较了由10个人类演示与200个人类演示生成的数据,得出的结果同样差别不大。因此论文也坦承,需要进一步研究更多的人类演示数据是否会造成冗余及多余不必要的数据标注成本。
为何如此执着于合成数据?除了文章开头提到的源数据资源有限之外,收集数据也极为昂贵且耗时,而有了MimicGen这类系统,可以仅凭借少量数据,便自动生成大规模的丰富数据集,并且这些数据集横跨多个场景、对象实力、机械臂,还能用于长时程或高精度任务,堪称一条“扩大机器人学习的强大且经济”的有效途径。
“合成数据将为我们的‘饥肠辘辘’的模型提供下一波万亿级数据。”英伟达高级科学家Jim Fan在介绍MimicGen时如此说道,“机器人技术发展步调远远落后于其他AI领域的关键原因之一,便是缺乏数据——你无法从互联网上获取(机器人的)控制信号。”
“我们正在迅速耗尽来自网络的高质量真实数据,诞生于合成数据的AI将是未来的发展方向。
来源:科创板日报
以上是英伟达开创新纪元:机器人训练数据的'永动机”的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 第二代Ameca来了!和观众对答如流,面部表情更逼真,会说几十种语言
Mar 04, 2024 am 09:10 AM
第二代Ameca来了!和观众对答如流,面部表情更逼真,会说几十种语言
Mar 04, 2024 am 09:10 AM
人形机器人Ameca升级第二代了!最近,在世界移动通信大会MWC2024上,世界上最先进机器人Ameca又现身了。会场周围,Ameca引来一大波观众。得到GPT-4加持后,Ameca能够对各种问题做出实时反应。「来一段舞蹈」。当被问及是否有情感时,Ameca用一系列的面部表情做出回应,看起来非常逼真。就在前几天,Ameca背后的英国机器人公司EngineeredArts刚刚演示了团队最新的开发成果。视频中,机器人Ameca具备了视觉能力,能看到并描述房间整个情况、描述具体物体。最厉害的是,她还能
 AI如何使机器人更具自主性和适应性?
Jun 03, 2024 pm 07:18 PM
AI如何使机器人更具自主性和适应性?
Jun 03, 2024 pm 07:18 PM
在工业自动化技术领域,最近有两个热点很难被忽视:人工智能(AI)和英伟达(Nvidia)。不要改变原内容的意思,微调内容,重写内容,不要续写:“不仅如此,这两者密切相关,因为英伟达在不仅仅局限于其最开始的图形处理单元(GPU),正在将其GPU技术扩展到数字孪生领域,同时紧密连接着新兴的AI技术。”最近,英伟达与众多工业企业达成了合作,包括领先的工业自动化企业,如Aveva、罗克韦尔自动化、西门子和施耐德电气,以及泰瑞达机器人及其MiR和优傲机器人公司。Recently,Nvidiahascoll
 首个自主完成人类任务机器人出现,五指灵活速度超人,大模型加持虚拟空间训练
Mar 11, 2024 pm 12:10 PM
首个自主完成人类任务机器人出现,五指灵活速度超人,大模型加持虚拟空间训练
Mar 11, 2024 pm 12:10 PM
这周,由OpenAI、微软、贝佐斯和英伟达投资的机器人公司FigureAI宣布获得接近7亿美元的融资,计划在未来一年内研发出可独立行走的人形机器人。而特斯拉的擎天柱也屡屡传出好消息。没人怀疑,今年会是人形机器人爆发的一年。一家位于加拿大的机器人公司SanctuaryAI最近发布了一款全新的人形机器人Phoenix。官方号称它能以和人类一样的速率自主完成很多工作。世界上第一台能以人类速度自主完成任务的机器人Pheonix可以轻轻地抓取、移动并优雅地将每个对象放置在它的左右两侧。它能够自主识别物体的
 2 个月不见,人形机器人 Walker S 会叠衣服了
Apr 03, 2024 am 08:01 AM
2 个月不见,人形机器人 Walker S 会叠衣服了
Apr 03, 2024 am 08:01 AM
机器之能报道编辑:吴昕国内版的人形机器人+大模型组队,首次完成叠衣服这类复杂柔性材料的操作任务。随着融合了OpenAI多模态大模型的Figure01揭开神秘面纱,国内同行的相关进展一直备受关注。就在昨天,国内"人形机器人第一股"优必选发布了人形机器人WalkerS深入融合百度文心大模型后的首个Demo,展示了一些有趣的新功能。现在,得到百度文心大模型能力加持的WalkerS是这个样子的。和Figure01一样,WalkerS没有走动,而是站在桌子后面完成一系列任务。它可以听从人类的命令,折叠衣物
 塑造未来的十款类人机器人
Mar 22, 2024 pm 08:51 PM
塑造未来的十款类人机器人
Mar 22, 2024 pm 08:51 PM
以下10款类人机器人正在塑造我们的未来:1、ASIMO:ASIMO由Honda开发,是最知名的人形机器人之一。ASIMO高4英尺,重119磅,配备先进的传感器和人工智能功能,使其能够在复杂的环境中导航并与人类互动。ASIMO的多功能性使其适用于各种任务,从帮助残疾人到在活动中进行演示。2、Pepper:由SoftbankRobotics创建,Pepper旨在成为人类的社交伴侣。凭借其富有表现力的面孔和识别情绪的能力,Pepper可以参与对话、在零售环境中提供帮助,甚至提供教育支持。Pepper的
 云鲸逍遥001扫拖机器人,长「脑子」了!| 体验
Apr 26, 2024 pm 04:22 PM
云鲸逍遥001扫拖机器人,长「脑子」了!| 体验
Apr 26, 2024 pm 04:22 PM
近几年最受消费者欢迎的智能家电,扫拖机器人可谓是其中之一。它所带来的操作便利性,甚至是无需操作,让懒人们释放了双手,让消费者能够从日常的家务中「解放」出来,也能拿更多的时间花在自己喜欢的事情上,变相提高了生活品质。借着这股热潮,市面上几乎所有的家电产品品牌都在做自己的扫拖机器人,一时间使得整个扫拖机器人市场热闹非凡。但市场的快速拓张必然会带来一个隐患:很多厂商会采用机海战术的方式快速占领更多的市场份额,从而导致很多新品并没有什么升级点,说它是“套娃”机型也不为过。不过,并不是所有的扫拖机器人都是
 人形机器人会变魔术了,春晚节目组了解一下
Feb 04, 2024 am 09:03 AM
人形机器人会变魔术了,春晚节目组了解一下
Feb 04, 2024 am 09:03 AM
一眨眼的功夫,机器人都已经学会变魔术了?只见它先是拿起桌上的水勺,向观众证明了里面什么也没有……然后,它又把手中鸡蛋似的物体放了进去,然后把水勺放回桌子上,开始“施法”……就在它把水勺再次拿起的时候,奇迹发生了。原先放进去的鸡蛋不翼而飞,跳出的东西变成了一个篮球……再来看一遍连贯动作:△此动图为二倍速一套动作下来如行云流水,只有把视频用0.5倍速反复观看,才终于发现了其中的端倪:如果手速再快一些,大概真的就可以瞒天过海了。有网友感叹,机器人变魔术的水平比自己还要高:为我们表演这段魔术的,是Mag
 美国大学开《萨尔达传说:王国之泪》工程学让学生比赛打造机器人
Nov 23, 2023 pm 08:45 PM
美国大学开《萨尔达传说:王国之泪》工程学让学生比赛打造机器人
Nov 23, 2023 pm 08:45 PM
创下有史以来销售速度最快的任天堂游戏《塞尔达传说:王国之泪》(TheLegendofZelda:TearsoftheKingdom)不仅因为左纳乌科技带来各种“塞尔达创作家”社群内容,同时也成为美国马里兰大学(UniversityofMaryland;UMD)全新工程学的一门课程。重写:《塞尔达传说:王国之泪》是任天堂创纪录销售最快的游戏之一。不仅仅因为左纳乌科技带来了丰富的社群内容,还成为了美国马里兰大学全新工程学课程的一部分今年秋季,马里兰大学的RyanD.Sochol副教授开设了一门名为《
