

11 月 10 日消息,大语言模型(LLM)快速崛起,在语言生成和理解方面表现出光明的前景,影响超越了语言领域,延伸到逻辑、数学、物理学等领域。
不过想要解锁这些“非凡能量”,需要付出高额的代价,例如训练 540B 模型,需要 Project PaLM 的 6144 个 TPUv4 芯片;而训练 175B 的 GPT-3,需要数千 Petaflop/s-day。
一个很好的解决方案是进行低精度训练,这可以提高处理速度,降低内存使用和通信成本。目前主流的训练系统包括Megatron-LM、MetaSeq和Colossal-AI,默认使用FP16/BF16混合精度或FP32全精度来训练大型语言模型
虽然这些精度水平对于大语言模型来说是必不可少的,但它们的计算成本很高。
如果采用 FP8 低精度,可以将速度提高 2 倍、内存成本降低 50% 至 75%,并且可节省通信成本。
目前只有 Nvidia Transformer Engine 兼容 FP8 框架,主要利用这种精度进行 GEMM(通用矩阵乘法)计算,同时以 FP16 或 FP32 高精度保持主权重和梯度。
为了应对这一挑战,来自 Microsoft Azure 和 Microsoft Research 的一组研究人员推出了一个高效的 FP8 混合精度框架,专为大型语言模型训练量身定制。
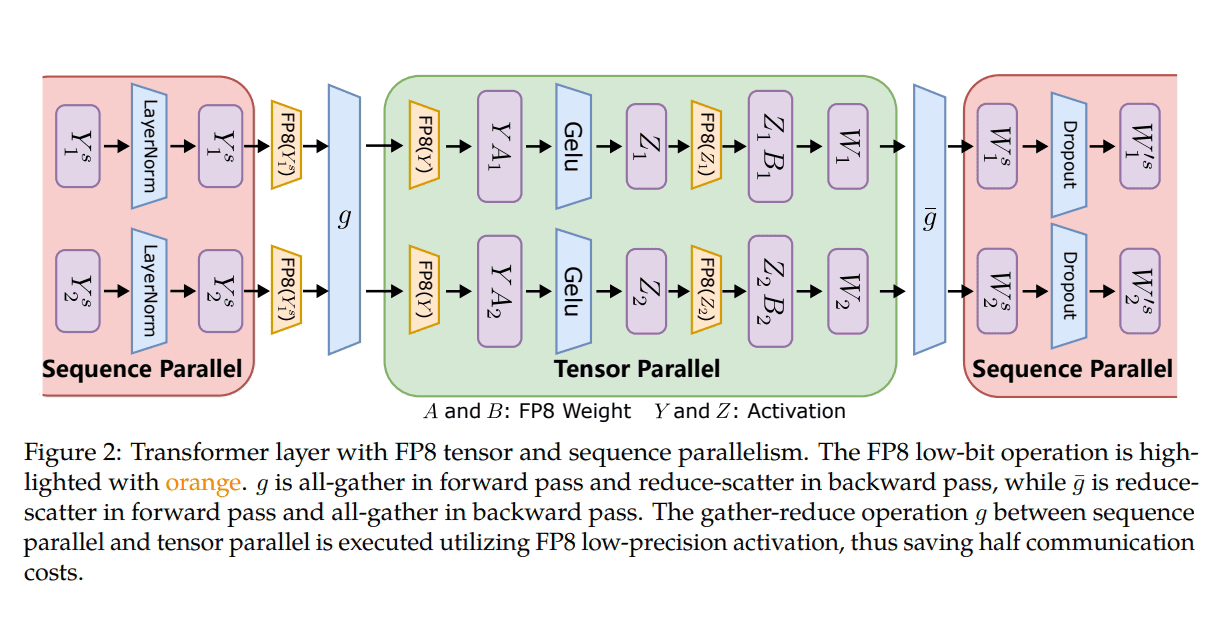
微软引入了三个优化阶段,利用 FP8 进行分布式和混合精度训练。随着这些层级的进展,FP8 集成程度的提高变得明显,这表明对 LLM 训练过程的影响更大。
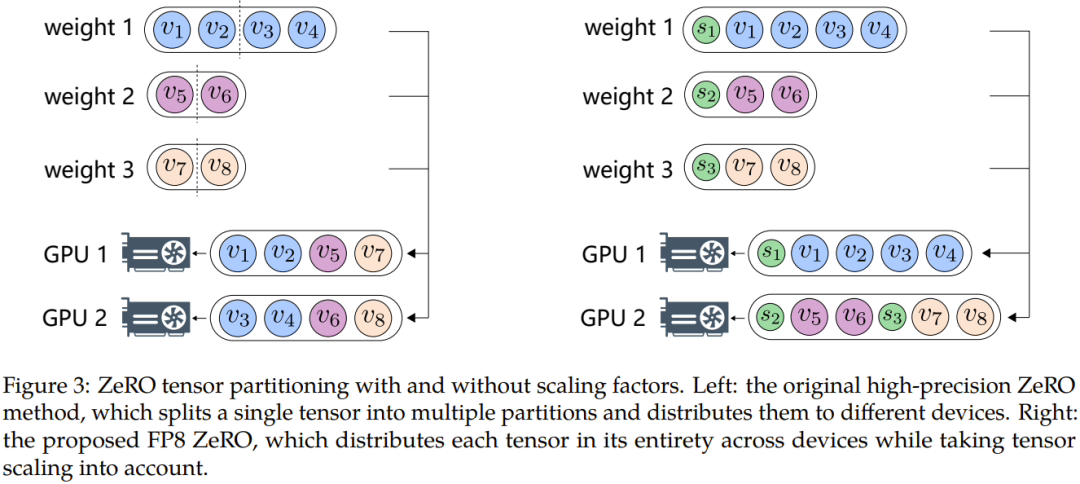
此外为了克服数据溢出或下溢等问题,微软研究人员提出自动采样和精确解耦两种关键方法,前者涉及对精度不敏感的组件降低精度,动态调整 Tensor 采样因子,以确保梯度值保持在 FP8 表示范围内。这可以防止全减少通信期间的下溢和溢流事件,确保培训过程更加顺畅。
微软经过测试,与广泛采用的 BF16 混合精度方法相比,内存占用减少 27% 至 42%,权重梯度通信开销显著降低 63% 至 65%。运行速度比广泛采用的 BF16 框架(例如 Megatron-LM)快了 64%,比 Nvidia Transformer Engine 的速度快了 17%。
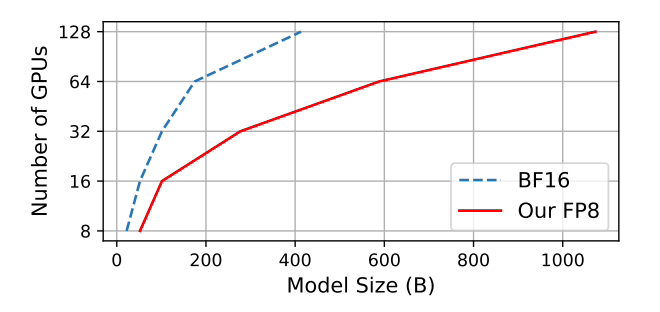
在训练 GPT-175B 模型时,混合 FP8 精度框架在 H100 GPU 平台上节省 21% 的内存,而且相比较 TE(Transformer Engine),训练时间减少 17%。
本站在此附上 GitHub 地址和论文地址:https://www.php.cn/link/7b3564b05f78b6739d06a2ea3187f5ca
以上是微软发布新的混合精度训练框架 FP8:速度超过 BF16 64%,内存占用减少 42%的详细内容。更多信息请关注PHP中文网其他相关文章!





















