

我们一起聊聊知识抽取,你学会了吗?

一、简介
知识抽取通常指从非结构化文本中挖掘结构化信息,例如含有丰富语义信息的标签和短语。这在业界被广泛应用于内容理解和商品理解等场景,通过从用户生成的文本信息中提取有价值的标签,将其应用于内容或商品上
知识抽取通常伴随着对所抽取标签或短语的分类,通常被建模为命名实体识别任务,通用的命名实体识别任务就是识别命名实体成分并将成分划分到地名、人名、机构名等类型上;领域相关的标签词抽取将标签词识别并划分到领域自定义的类别上,如系列(空军一号、音速 9)、品牌(Nike、李宁)、类型(鞋、服装、数码)、风格(ins 风、复古风、北欧风)等。
为了方便描述,下文中将富含信息的标签或短语统一称为标签词
二、知识抽取分类
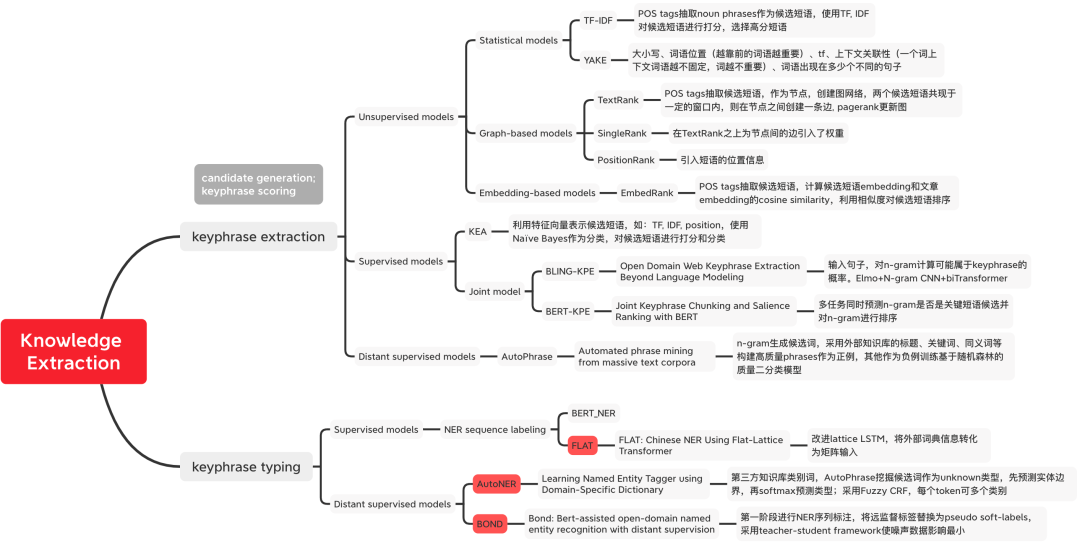 图1 知识抽取方法分类
图1 知识抽取方法分类
三、标签词挖掘
无监督方法
基于统计的方法
- TF-IDF(Term Frequency-Inverse Document Frequency) :统计每个词的 TF-IDF 打分,分数越高说明包含的信息量越大。
重写后的内容:计算方法:tfidf(t, d, D) = tf(t, d) * idf(t, D),其中tf(t, d) = log(1 + freq(t, d)),freq(t,d)表示候选词 t 在当前文档 d 中出现的次数,idf(t,D) = log(N/count(d∈D:t∈D))表示候选词 t 出现在多少个文档中,用来表示一个词语的稀有度,假如一个词语只在一篇文档中出现,说明这个词语比较稀有,信息量更丰富
特定业务场景下可以借助外部工具对候选词先进行一轮筛选,如采用词性标识筛选名词。
- YAKE[1]:定义了五个特征来捕捉关键词特征,这些特征被启发式地组合起来,为每个关键词分配一个分数。分数越低,关键词越重要。1)大写词:大写字母的Term(除了每句话的开头单词)的重要程度比那些小写字母的 Term 重要程度要大,对应到中文可能是粗体字次数;2)词位置:每段文本越开头的部分词的重要程度比后面的词重要程度更大;3)词频,统计词出现的频次;4)词的上下文关系,用来衡量固定窗口大小下出现不同词的个数,一个词与越多不相同的词共现,该词的重要程度越低;5)词在不同句子中出现的次数,一个词在更多句子中出现,相对更重要。
基于图的方法 Graph-Based Model
- TextRank[2]:首先对文本进行分词和词性标注,并过滤掉停用词,只保留指定词性的单词来构造图。每个节点都是一个单词,边表示单词之间的关系,通过定义单词在预定大小的移动窗口内的共现来构造边。采用 PageRank 更新节点的权重直至收敛;对节点权重进行倒排序,从而得到最重要的 k 个词语,作为候选关键词;将候选词在原始文本中进行标记,若形成相邻词组,则组合成多词组的关键词短语。
基于表征的方法 Embedding-Based Model
- EmbedRank[3]:通过分词和词性标注选择候选词,采用预训练好的 Doc2Vec 和 Sent2vec 作为候选词和文档的向量表征,计算余弦相似度对候选词进行排序。类似的,KeyBERT[4] 将 EmbedRank 的向量表征替换为 BERT。
有监督方法
- 先筛候选词再采用标签词分类:经典的模型 KEA[5] 对四个设计的特征采用 Naive Bayes 作为分类器对 N-gram 候选词进行打分。
- 候选词筛选和标签词识别联合训练:BLING-KPE[6] 将原始句子作为输入,分别用 CNN、Transformer 对句子的 N-gram 短语进行编码,计算该短语是标签词的概率,是否是标签词采用人工标注 Label。BERT-KPE[7] 在 BLING-KPE 的思想基础上,将 ELMO 替换为 BERT 来更好地表示句子的向量。
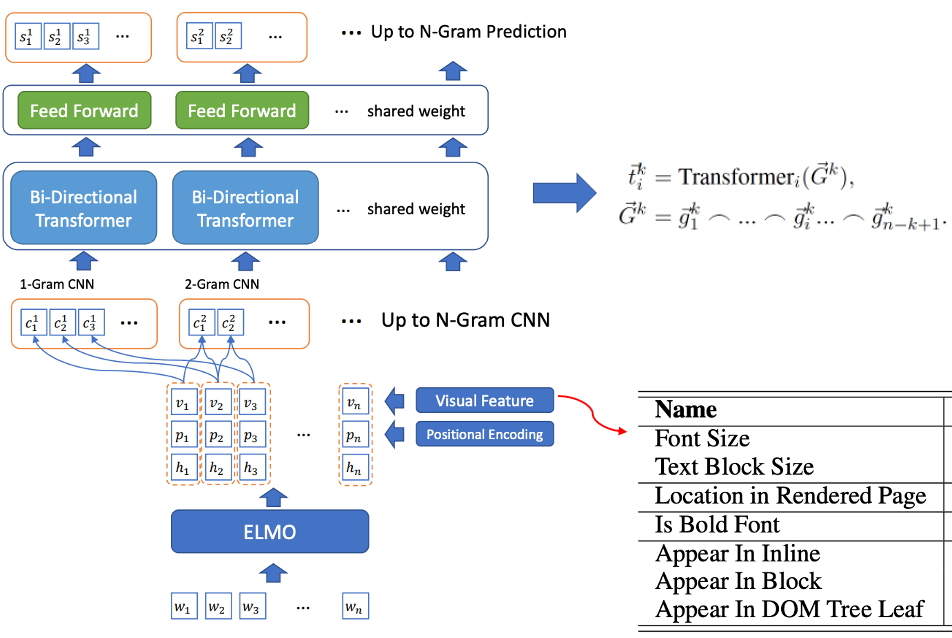 图2 BLING-KPE 模型结构
图2 BLING-KPE 模型结构
远监督方法
AutoPhrase
在本文中,我们将高质量短语定义为那些具备完整语义的单词,在同时满足以下四个条件的情况下
- Popularit:文档中出现的频次足够高;
- Concordance:Token 搭配出现的频率远高于替换后的其他搭配,即共现的频次;
- Informativeness:有信息量、明确指示性,如 “this is” 就是没有信息量的负例;
- Completeness:短语及其子短语都要具有完整性。
AutoPhrase 标签挖掘流程如图 3 所示。首先,我们使用词性标注筛选高频 N-gram 词作为候选。然后,我们通过远监督的方式对候选词进行分类。最后,我们使用以上四个条件筛选出高质量的短语(短语质量再估计)
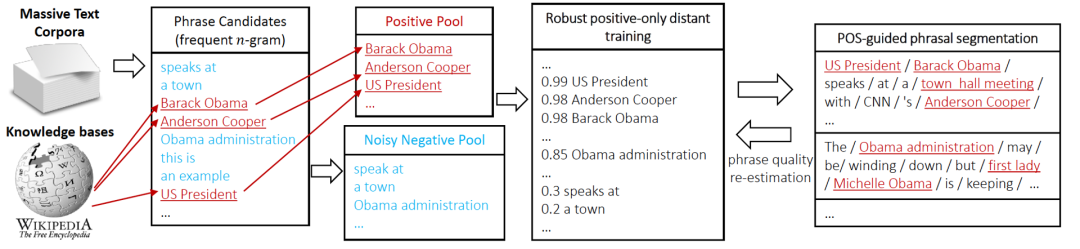 图3 AutoPhrase 标签挖掘流程
图3 AutoPhrase 标签挖掘流程
从外部知识库获取高质量的短语作为 Positive Pool,其他短语作为负例,按论文实验统计,负例池中存在 10% 的高质量短语因为没有在知识库中被分到了负例中,因此论文采用了如图 4 所示的随机森林集成分类器来降低噪声对分类的影响。在业界应用中,分类器的训练也可以采用基于预训练模型 BERT 的句间关系任务二分类方法[13]。
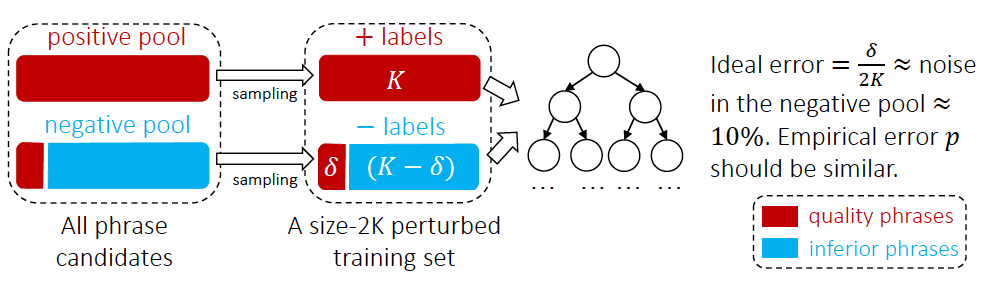 图4 AutoPhrase标签词分类方法
图4 AutoPhrase标签词分类方法
四、标签词分类
有监督方法
NER 序列标注模型
Lattice LSTM[8] 是针对中文 NER 任务引入词汇信息的开篇之作,Lattice 是一个有向无环图,词汇的开始和结束字符决定了格子位置,通过词汇信息(词典)匹配一个句子时,可以获得一个类似 Lattice 的结构,如图 5(a) 所示。Lattice LSTM 结构则融合了词汇信息到原生的 LSTM 中,如 5(b) 所示,对于当前的字符,融合以该字符结束的所有外部词典信息,如“店”融合了“人和药店”和“药店”的信息。对于每一个字符,Lattice LSTM 采取注意力机制去融合个数可变的词单元。虽然 Lattice-LSTM 有效提升了 NER 任务的性能,但 RNN 结构无法捕捉长距离依赖,同时引入词汇信息是有损的,同时动态的 Lattice 结构也不能充分进行 GPU 并行,Flat[9] 模型有效改善了这两个问题。如图 5(c),Flat 模型通过 Transformer 结构来捕捉长距离依赖,并设计了一种位置编码 Position Encoding 来融合 Lattice 结构,将字符匹配到的词汇拼接到句子后,对于每一个字符和词汇都构建两个 Head Position Encoding 和 Tail Position Encoding,将 Lattice 结构展平,从一个有向无环图展平为一个平面的 Flat-Lattice Transformer 结构。
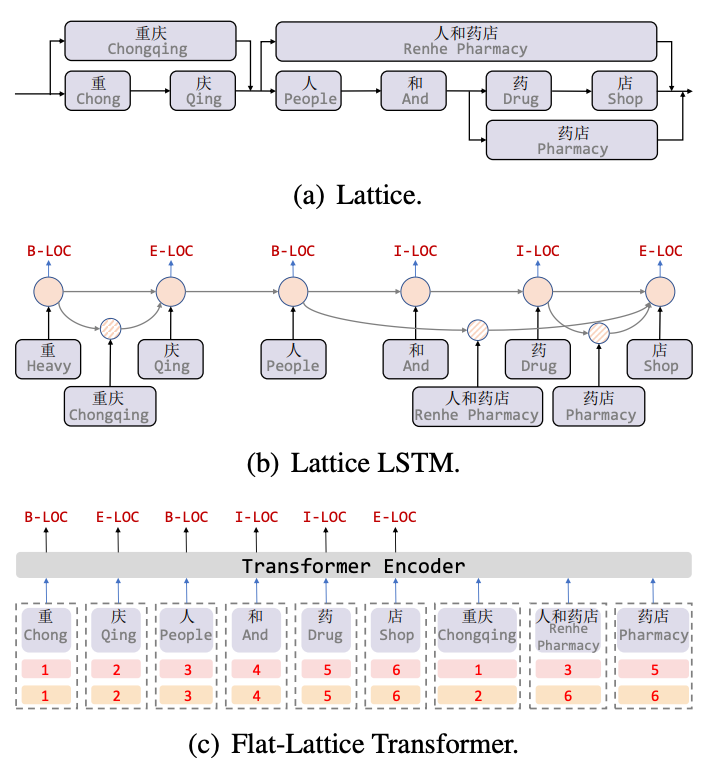 图5 引入词汇信息的 NER 模型
图5 引入词汇信息的 NER 模型
远监督方法
AutoNER
为了解决远监督中的噪声问题,我们采用了Tie或Break的实体边界标识方案来替代BIOE的标注方式。其中,Tie表示当前词和上一个词属于同一个实体,而Break表示当前词和上一个词不再同一个实体中
在实体分类阶段,使用模糊CRF(Fuzzy CRF)来应对一个实体具有多种类型的情况
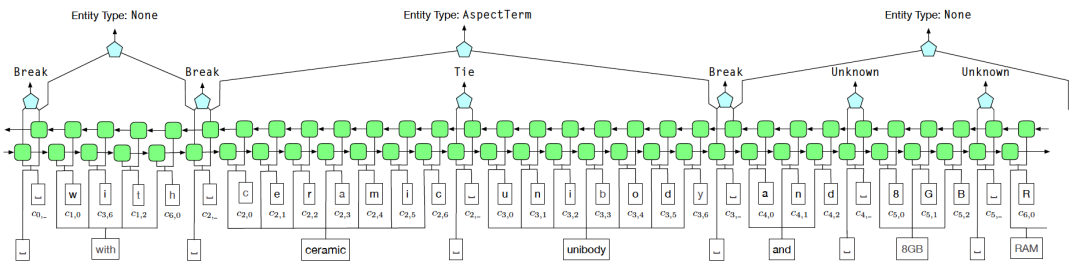 图6 AutoNER 模型结构图
图6 AutoNER 模型结构图
BOND
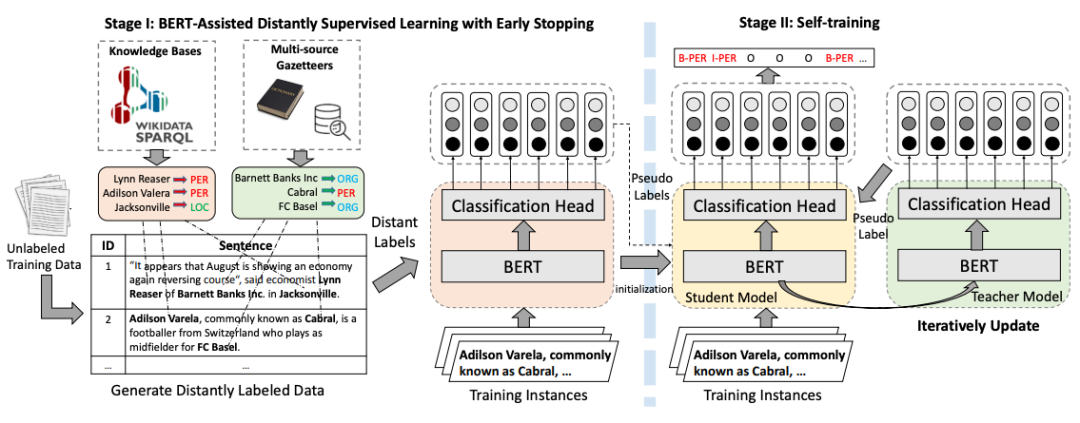 图片
图片
需要重新书写的内容是:图7 BOND训练流程图
五、总结
参考文献
【1】Campos R, Mangaravite V, Pasquali A, et al. Yake! collection-independent automatic keyword extractor[C]//Advances in Information Retrieval: 40th European Conference on IR Research, ECIR 2018, Grenoble, France, March 26-29, 2018, Proceedings 40. Springer International Publishing, 2018: 806-810. https://github.com/LIAAD/yake
【2】Mihalcea R, Tarau P. Textrank: Bringing order into text[C]//Proceedings of the 2004 conference on empirical methods in natural language processing. 2004: 404-411.
【3】Bennani-Smires K, Musat C, Hossmann A, et al. Simple unsupervised keyphrase extraction using sentence embeddings[J]. arXiv preprint arXiv:1801.04470, 2018.
【4】KeyBERT,https://github.com/MaartenGr/KeyBERT
【5】Witten I H, Paynter G W, Frank E, et al. KEA: Practical automatic keyphrase extraction[C]//Proceedings of the fourth ACM conference on Digital libraries. 1999: 254-255.
翻译内容:【6】熊L,胡C,熊C,等。超越语言模型的开放领域Web关键词提取[J]。arXiv预印本arXiv:1911.02671,2019年
【7】Sun, S., Xiong, C., Liu, Z., Liu, Z., & Bao, J. (2020). Joint Keyphrase Chunking and Salience Ranking with BERT. arXiv preprint arXiv:2004.13639.
需要重写的内容是:【8】张Y,杨J。使用格子LSTM的中文命名实体识别[C]。ACL 2018
【9】Li X, Yan H, Qiu X, et al. FLAT: Chinese NER using flat-lattice transformer[C]. ACL 2020.
【10】Shang J, Liu J, Jiang M, et al. Automated phrase mining from massive text corpora[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(10): 1825-1837.
【11】 Shang J, Liu L, Ren X, et al. Learning named entity tagger using domain-specific dictionary[C]. EMNLP, 2018.
【12】Liang C, Yu Y, Jiang H, et al. Bond: Bert-assisted open-domain named entity recognition with distant supervision[C]//Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2020: 1054-1064.
【13】美团搜索中NER技术的探索与实践,https://zhuanlan.zhihu.com/p/163256192
以上是我们一起聊聊知识抽取,你学会了吗?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 带你了解相当震撼的win10x系统知识
Jul 14, 2023 am 11:29 AM
带你了解相当震撼的win10x系统知识
Jul 14, 2023 am 11:29 AM
近日,网络中有win10X系统的最新镜像下载流出,不同于常见的ISO,此次的镜像是.ffu格式,目前仅能用于SurfacePro7体验。虽然很多小伙伴不能体验,但是依旧可以看看测评的相关内容,过过瘾,那么一起来看看win10x系统最新评测吧!win10x系统最新评测 1、Win10X与Win10最大的不同首先就表现在开机后开始按钮等被放在了任务栏中央,除了固定的应用程序,任务栏还可以显示最近启动的应用程序,类似于Android和iOS手机。 2、另外一个就是,新系统的“开始”菜单不支持文
 原神胡桃一斗抽取建议
Mar 15, 2024 pm 05:07 PM
原神胡桃一斗抽取建议
Mar 15, 2024 pm 05:07 PM
原神胡桃后面的池子就是一斗,作为一个新的岩元素角色,未出先火,很多女玩家都在期待,那么原神胡桃和一斗抽哪个?下面小编给大家带来原神胡桃一斗抽取建议,一起看看吧。原神胡桃和一斗抽哪个1、胡桃强度不弱,而且不吃圣遗物,一斗目前只爆料一点点,具体情况还不知道怎么样。2、胡桃近半年内不会有替代品,还是强力火c,打深渊冰水够了,称得上是最强火c。3、一斗就是大号女仆,而且比较吃命座,五星命座很难获取,不太划算。4、一斗基本是绑定阿贝多的,虽然强度也不算低,但是有一定的培养成本。主要还是看玩家自己的角色,如
 我们一起聊聊知识抽取,你学会了吗?
Nov 13, 2023 pm 08:13 PM
我们一起聊聊知识抽取,你学会了吗?
Nov 13, 2023 pm 08:13 PM
一、简介知识抽取通常指从非结构化文本中挖掘结构化信息,例如含有丰富语义信息的标签和短语。这在业界被广泛应用于内容理解和商品理解等场景,通过从用户生成的文本信息中提取有价值的标签,将其应用于内容或商品上知识抽取通常伴随着对所抽取标签或短语的分类,通常被建模为命名实体识别任务,通用的命名实体识别任务就是识别命名实体成分并将成分划分到地名、人名、机构名等类型上;领域相关的标签词抽取将标签词识别并划分到领域自定义的类别上,如系列(空军一号、音速9)、品牌(Nike、李宁)、类型(鞋、服装、数码)、风格(
 了解Golang:开发者必备知识
Feb 23, 2024 am 10:51 AM
了解Golang:开发者必备知识
Feb 23, 2024 am 10:51 AM
Golang,又称为Go语言,是一种由Google开发的开源编程语言。自2007年发布以来,Golang在软件开发领域逐渐崭露头角,得到了越来越多开发者的青睐。作为一种静态类型、编译型语言,Golang拥有诸多优点,如高效的并发处理能力、简洁的语法、强大的工具支持等,使其在云计算、大数据处理、网络编程等方面具有广泛应用前景。本文将介绍Golang的基本概念、
 聊天机器人是如何通过知识图谱回答问题的?
Apr 17, 2023 am 09:13 AM
聊天机器人是如何通过知识图谱回答问题的?
Apr 17, 2023 am 09:13 AM
前言1950年,图灵发表了具有里程碑意义的论文《计算机器与智能》(ComputingMachineryandIntelligence),提出了一个关于机器人的著名判断原则——图灵测试,也被称为图灵判断,它指出如果第三者无法辨别人类与AI机器反应的差别,则可以论断该机器具备人工智能。2008年,漫威《钢铁侠》中的AI管家贾维斯,让人们知道了AI是如何精准地帮助人类(托尼)解决丢过来的各种事务的……图1:AI管家贾维斯(图片来源网络)2023年初,以2C的方式从科技界火爆破圈的免费聊天机器人Chat
 了解Linux服务器安全:必备的知识和技能
Sep 09, 2023 pm 02:55 PM
了解Linux服务器安全:必备的知识和技能
Sep 09, 2023 pm 02:55 PM
了解Linux服务器安全:必备的知识和技能随着互联网的不断发展,Linux服务器越来越广泛地应用于各个领域。然而,由于服务器存储了大量的敏感数据,其安全性问题也成为了人们关注的焦点。本文将介绍一些必备的Linux服务器安全知识和技能,帮助您保护您的服务器免受攻击。更新和维护操作系统及软件及时更新操作系统和软件是保持服务器安全的重要一环。因为每个操作系统和软件
 深入了解jQuery兄弟节点的相关知识
Feb 27, 2024 pm 06:51 PM
深入了解jQuery兄弟节点的相关知识
Feb 27, 2024 pm 06:51 PM
毫无疑问,jQuery是前端开发中最常用的JavaScript库之一,它提供了简洁而强大的方法来操作HTML文档。在jQuery中,兄弟节点是指与指定元素有相同父元素的元素。深入了解jQuery兄弟节点的相关知识对于前端开发者来说是至关重要的。本文将介绍如何使用jQuery来操作兄弟节点,并附上具体的代码示例。1.查找兄弟节点在jQuery中,我们可以通过
 掌握HTML全局属性的关键知识与实践技巧
Jan 06, 2024 am 08:40 AM
掌握HTML全局属性的关键知识与实践技巧
Jan 06, 2024 am 08:40 AM
学习HTML全局属性的必备知识与实践技巧HTML(HyperTextMarkupLanguage)是一种用于创建网页结构的标记语言。在构建网页时,我们常常需要使用各种标签和属性来定义页面的外观与行为。而在所有的HTML属性中,全局属性是一类非常重要的属性,它们可以应用于所有的HTML标签,为网页开发者提供了强大的灵活性和自定义能力。在学习和使用HTML全
