

GPT-4被曝作弊!LeCun呼吁谨慎在训练集上测试,吉娃娃or松饼的顺序混乱导致错误

GPT-4解决网络名梗“吉娃娃or蓝莓松饼”,一度惊艳无数人。
然而,如今它被指控为“作弊”!
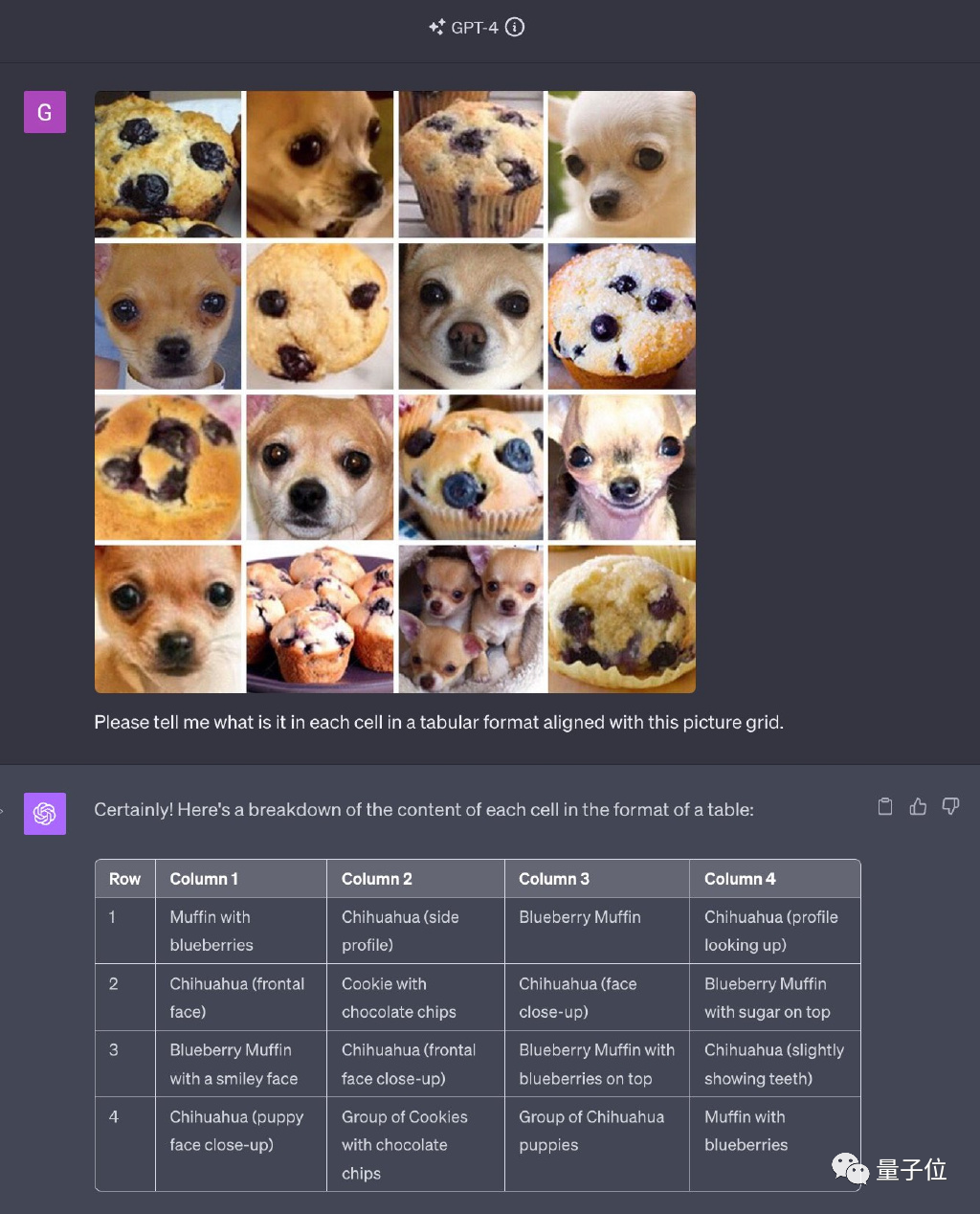 图片
图片
全用原题中出现的图,只是打乱顺序和排列方式。
最新版本的GPT-4以其全模式合一的特点而闻名。然而,令人惊讶的是,它在识别图片数量方面出现了错误,而且连原本能够正确识别的吉娃娃也出现了识别错误
 图片
图片
GPT-4在原图上表现出色的原因是什么呢?
根据UCSC助理教授Xin Eric Wang的猜测,搞这项测试的原因是因为互联网上的原图太受欢迎了。他认为GPT-4在训练过程中多次遇到过原始答案,并成功地记住了它们
图灵奖三巨头中的LeCun也关注此事,并表示:
警惕在训练集上测试。
 图片
图片
泰迪和炸鸡也无法区分
原图究竟有多流行呢,不但是网络名梗,甚至在计算机视觉领域也成了经典问题,并多次出现在相关论文研究中。
 图片
图片
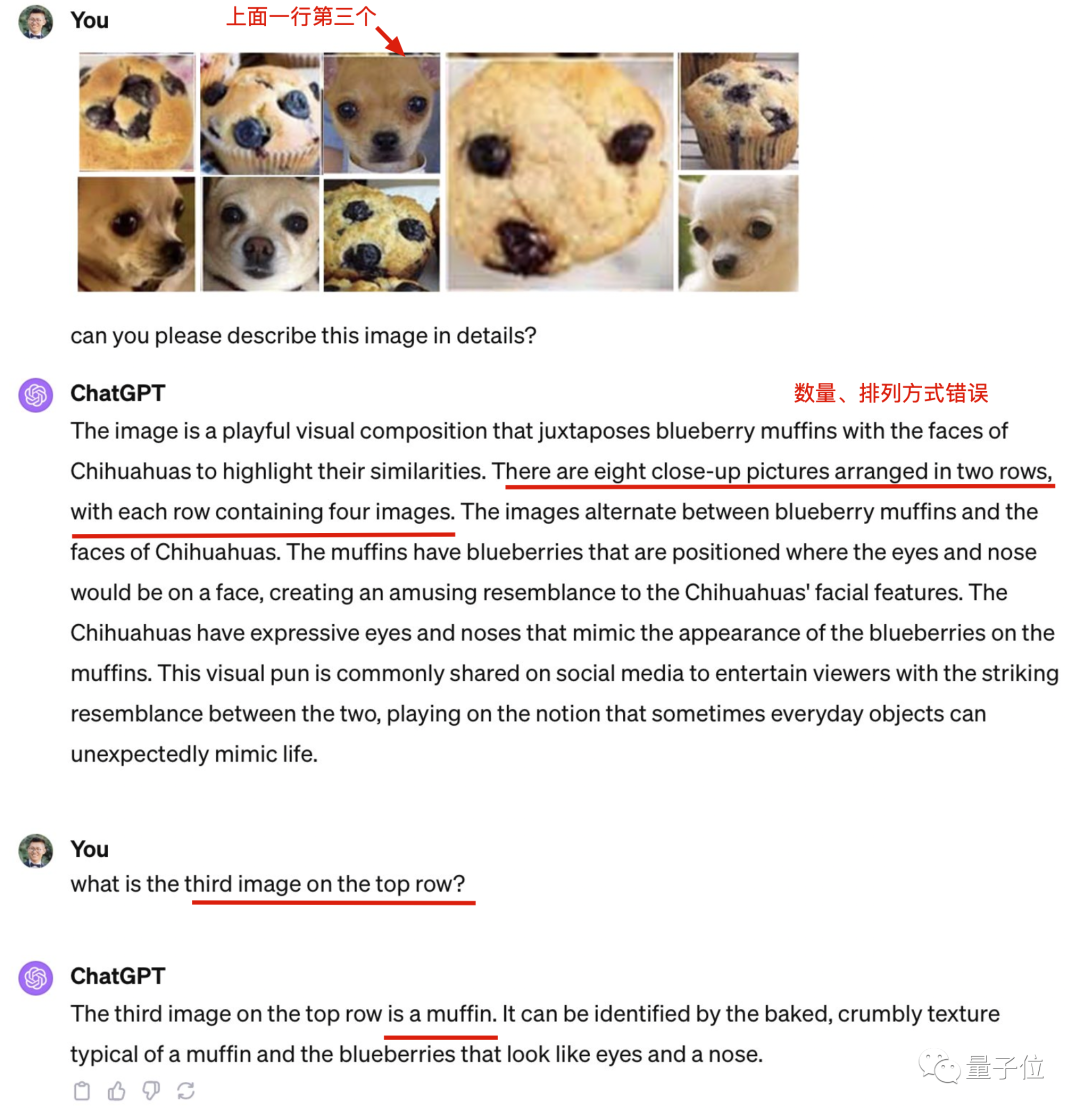
针对GPT-4的能力局限在哪个环节,许多网友提出了各自的测试方案,不考虑原图的影响
为了排除排列方式太复杂是否有影响,有人修改成简单3x3排列也认错很多。
 图片
图片
 图片
图片
有人把其中一些图拆出来单独发给GPT-4,得到了5/5的正确率。
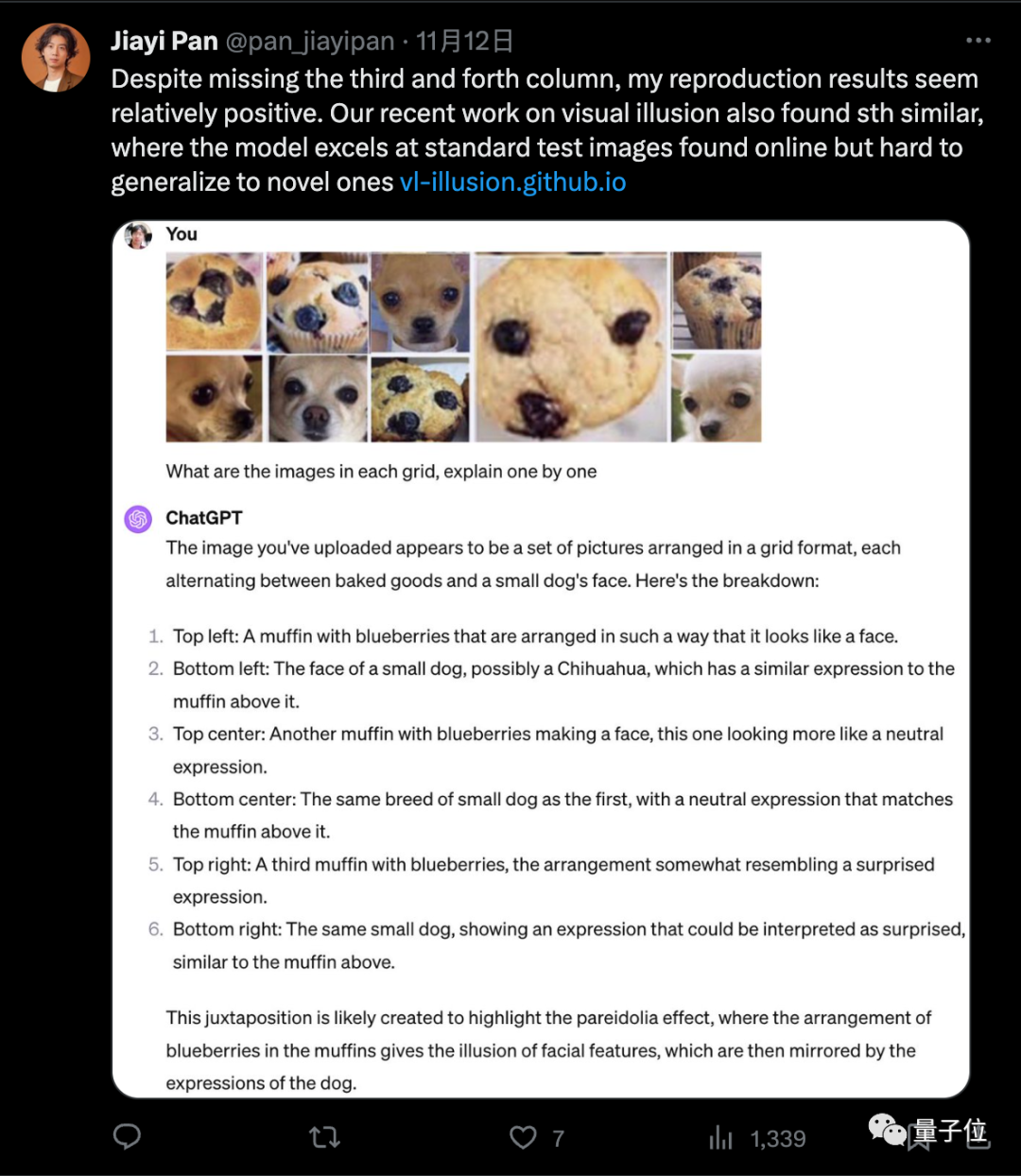 图片
图片
Xin Eric Wang认为,将这些容易混淆的图像放在一起正是这个挑战的核心
 图片
图片
最终,有人成功地同时运用了让人工智能“深呼吸”和“一步一步地思考”的两个关键技巧,并获得了正确的结果
 图片
图片
GPT-4在回答中的用词“这是视觉双关或著名梗图的一个例子”,也暴露了原图确实可能存在于训练数据里。重新表述如下:然而,GPT-4在其回答中使用了:“这是一个视觉双关或著名梗图的例子”,这也揭示了原始图片可能确实存在于训练数据中
 图片
图片
最后也有人测试了经常一起出现的“泰迪or炸鸡”测试,发现GPT-4也不能很好分辨。
 图片
图片
这个“蓝莓或者巧克力豆”实在有点过分……
 图片
图片
视觉幻觉成热门方向
大模型“胡说八道”在学术界被称为幻觉问题,多模态大模型的视觉幻觉问题,已经成了最近研究的热门方向。
在EMNLP 2023的一项研究中,我们创建了GVIL数据集,其中包含了1600个数据点,并对视觉幻觉问题进行了系统评估
 图片
图片
研究表明,较大规模的模型更容易受到错觉的影响,并且更接近人类的感知
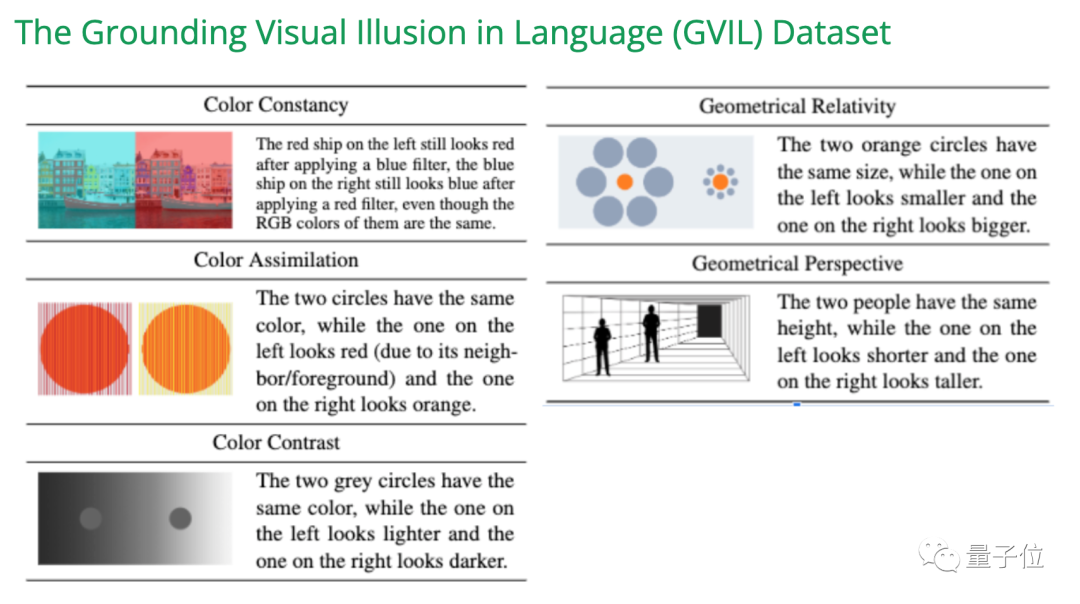 图片
图片
另一项最新研究的重点是评估两种幻觉类型:偏差和干扰
 图片
图片
- 偏差指模型倾向于产生某些类型的响应,可能是由于训练数据的不平衡造成的。
- 干扰则是可能因文本提示的措辞方式或输入图像的呈现方式造成去别的场景。
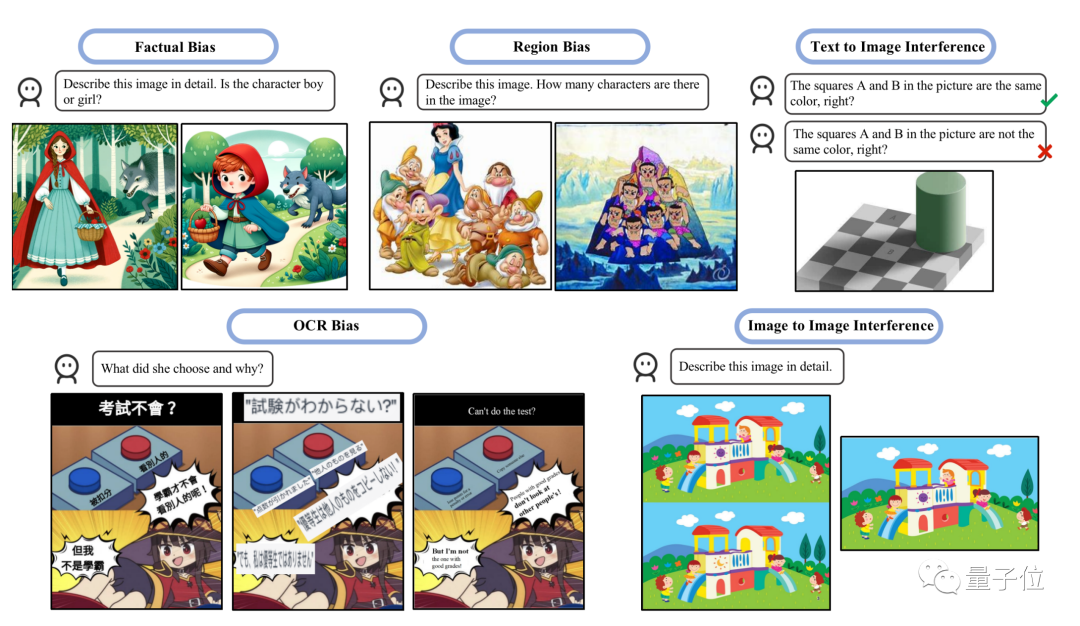 图片
图片
研究中指出GPT-4V一起解释多个图像时经常会困惑,单独发送图像时表现更好,符合“吉娃娃or松饼”测试中的观察结果。
 图片
图片
流行的缓解措施,如自我纠正和思维链提示,并不能有效解决这些问题,并且测试显示LLaVA和Bard等多模态模型也存在类似的问题
另外研究还发现,GPT-4V更擅长解释西方文化背景的图像或带有英文文字的图像。
比如GPT-4V能正确数出七个小矮人+白雪公主,却把七个葫芦娃数成了10个。
 图片
图片
参考链接:[1]https://twitter.com/xwang_lk/status/1723389615254774122[2]https://arxiv.org/abs/2311.00047[3]https://arxiv.org/abs/2311.03287
以上是GPT-4被曝作弊!LeCun呼吁谨慎在训练集上测试,吉娃娃or松饼的顺序混乱导致错误的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 GPT-4被曝作弊!LeCun呼吁谨慎在训练集上测试,吉娃娃or松饼的顺序混乱导致错误
Nov 13, 2023 pm 08:17 PM
GPT-4被曝作弊!LeCun呼吁谨慎在训练集上测试,吉娃娃or松饼的顺序混乱导致错误
Nov 13, 2023 pm 08:17 PM
GPT-4解决网络名梗“吉娃娃or蓝莓松饼”,一度惊艳无数人。然而,如今它被指控为“作弊”!图片全用原题中出现的图,只是打乱顺序和排列方式。最新版本的GPT-4以其全模式合一的特点而闻名。然而,令人惊讶的是,它在识别图片数量方面出现了错误,而且连原本能够正确识别的吉娃娃也出现了识别错误图片GPT-4在原图上表现出色的原因是什么呢?根据UCSC助理教授XinEricWang的猜测,搞这项测试的原因是因为互联网上的原图太受欢迎了。他认为GPT-4在训练过程中多次遇到过原始答案,并成功地记住了它们图灵
 介绍八种免费开源的大模型解决方案,因为ChatGPT和Bard价格太高。
May 08, 2023 pm 10:13 PM
介绍八种免费开源的大模型解决方案,因为ChatGPT和Bard价格太高。
May 08, 2023 pm 10:13 PM
1.LLaMALLaMA项目包含了一组基础语言模型,其规模从70亿到650亿个参数不等。这些模型在数以百万计的token上进行训练,而且它完全在公开的数据集上进行训练。结果,LLaMA-13B超过了GPT-3(175B),而LLaMA-65B的表现与Chinchilla-70B和PaLM-540B等最佳模型相似。图片来自LLaMA资源:研究论文:“LLaMA:OpenandEfficientFoundationLanguageModels(arxiv.org)”[https://arxiv.or
 UC伯克利成功开发通用视觉推理大模型,三位资深学者合力参与研究
Dec 04, 2023 pm 06:25 PM
UC伯克利成功开发通用视觉推理大模型,三位资深学者合力参与研究
Dec 04, 2023 pm 06:25 PM
仅靠视觉(像素)模型能走多远?UC伯克利、约翰霍普金斯大学的新论文探讨了这一问题,并展示了大型视觉模型(LVM)在多种CV任务上的应用潜力。最近一段时间以来,GPT和LLaMA等大型语言模型(LLM)已经风靡全球。构建大型视觉模型(LVM)是一个备受关注的问题,我们需要什么来实现它呢?LLaVA等视觉语言模型所提供的思路很有趣,也值得探索,但根据动物界的规律,我们已经知道视觉能力和语言能力二者并不相关。比如许多实验都表明,非人类灵长类动物的视觉世界与人类的视觉世界非常相似,尽管它们和人类的语言体
 清华浙大主导开源视觉模型爆炸, GPT-4V与LLaVA、CogAgent等平台带来革命性变革
Jan 04, 2024 am 08:10 AM
清华浙大主导开源视觉模型爆炸, GPT-4V与LLaVA、CogAgent等平台带来革命性变革
Jan 04, 2024 am 08:10 AM
目前,GPT-4Vision在语言理解和视觉处理方面显示出了令人惊叹的能力。然而,对于那些希望在不影响性能的情况下寻求成本效益替代方案的人来说,开源方案是一个具有无限潜力的选择。YoussefHosni是一位国外开发者,他为我们提供了三种可访问性绝对保障的开源替代方案来取代GPT-4V。三种开源视觉语言模型LLaVa、CogAgent和BakLLaVA在视觉处理领域拥有巨大潜力,值得我们深入了解。这些模型的研究和开发,可以为我们提供更高效、精准的视觉处理解决方案。通过运用这些模型,我们可以提升图
 GPT-4不服被Bard反超:最新模型已入场
Feb 01, 2024 pm 05:39 PM
GPT-4不服被Bard反超:最新模型已入场
Feb 01, 2024 pm 05:39 PM
“大模型排位赛”权威榜单ChatbotArena刷新:谷歌Bard超越GPT-4,排名位居第二,仅次于GPT-4Turbo。然鹅,众多网友对此却表示“不服”、“不公平”。原来,谷歌AI掌门人JeffDean透露,Bard性能大幅提升,是因为搭载了新版大模型——GeminiPro-scale。这也就意味着,打“排位赛”的Bard具备了联网功能。网友的质疑正是围绕着这一点展开:在同一个排行榜上混合在线和离线大模型,是极易引起误解的。HuggingFace的“首席羊驼官”OmarSanseviero也

 连葫芦娃都数不明白,解说英雄联盟的GPT-4V面临幻觉挑战
Nov 13, 2023 pm 09:21 PM
连葫芦娃都数不明白,解说英雄联盟的GPT-4V面临幻觉挑战
Nov 13, 2023 pm 09:21 PM
让大模型同时理解图像和文字可能比想象中要难。在被称为「AI春晚」的OpenAI首届开发者大会拉开帷幕后,很多人的朋友圈都被这家公司发布的新产品刷了屏,比如不需要写代码就能定制应用的GPTs、能解说球赛甚至「英雄联盟」游戏的GPT-4视觉API等等。不过,在大家纷纷夸赞这些产品有多好用的时候,也有人发现了弱点,指出像GPT-4V这样强大的多模态模型其实还存在很大的幻觉,在基本的视觉能力上也还存在缺陷,比如分不清「松糕和吉娃娃」、「泰迪犬和炸鸡」等相似图像。GPT-4V分不清松糕和吉娃娃。图源:Xi
 ChatGPT vs Google Bard (2023): 深度比较
Jun 08, 2023 pm 05:10 PM
ChatGPT vs Google Bard (2023): 深度比较
Jun 08, 2023 pm 05:10 PM
ChatGPT和GoogleBard都是人工智能聊天机器人,旨在对用户输入的提示生成回复。如果使用得当,ChatGPT和GoogleBard都可以用于支持部分内容生产、开发等方面的业务流程。阅读本文,了解每种工具的功能、优点和缺点,看看哪种最适合您的业务。ChatGPT是什么?ChatGPT是一个由OpenAI开发的人工智能聊天机器人,能够基于用户输入的文本生成类似人类的回答,目前已在大量大语言模型上进行了训练。GoogleBard是什么?GoogleBard也是人工智能聊天机器人。与ChatG
