

新标题:英伟达H200发布:HBM容量提升76%,大幅提升大模型性能90%的最强AI芯片


11月14日消息,英伟达(Nvidia)在当地时间13日上午的“Supercomputing 23”会议上正式发布了全新的H200 GPU,并更新了GH200产品线
其中,H200依然是建立在现有的 Hopper H100 架构之上,但增加了更多高带宽内存(HBM3e),从而更好地处理开发和实施人工智能所需的大型数据集,使得运行大模型的综合性能相比前代H100提升了60%到90%。而更新后的GH200,也将为下一代 AI 超级计算机提供动力。2024 年将会有超过 200 exaflops 的 AI 计算能力上线。
H200:HBM容量增加了76%,大型模型的性能提升了90%
具体来说,全新的H200提供了高达141GB的HBM3e内存,有效运行速度约为6.25 Gbps,六个HBM3e堆栈中每个GPU的总带宽为4.8 TB/s。与上一代的H100(具有80GB HBM3和3.35 TB/s带宽)相比,这是一个巨大的改进,HBM容量提升了超过76%。根据官方提供的数据,在运行大模型时,H200相比H100将带来60%(GPT3 175B)到90%(Llama 2 70B)的提升


虽然H100 的某些配置确实提供了更多内存,例如 H100 NVL 将两块板配对,并提供总计 188GB 内存(每个 GPU 94GB),但即便是与 H100 SXM 变体相比,新的 H200 SXM 也提供了 76% 以上的内存容量和 43 % 更多带宽。
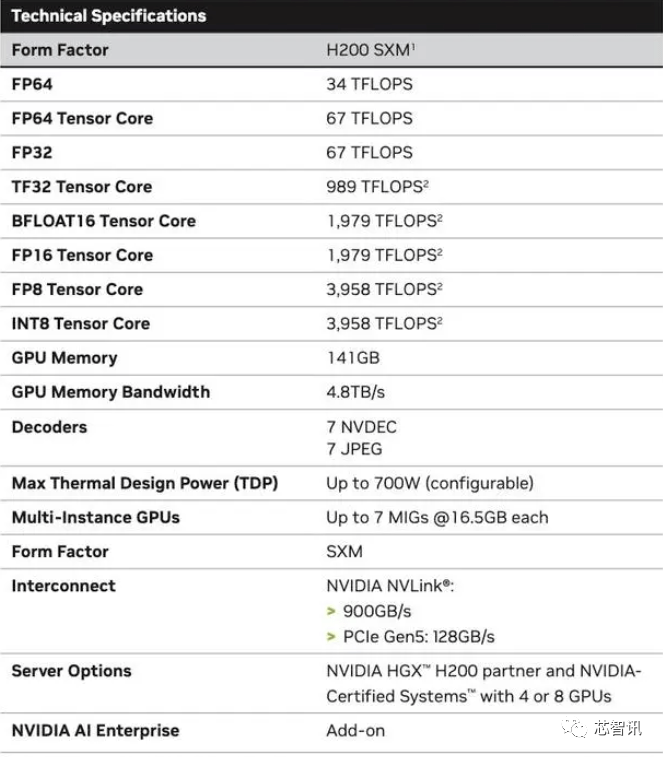
需要指出的是,H200原始计算性能似乎没有太大变化。英伟达展示的唯一体现计算性能的幻灯片是基于使用了8个GPU的HGX 200配置,总性能为“32 PFLOPS FP8”。而最初的H100提供了3,958 teraflops的FP8算力,因此八个这样的GPU也提供了大约32 PFLOPS的FP8算力
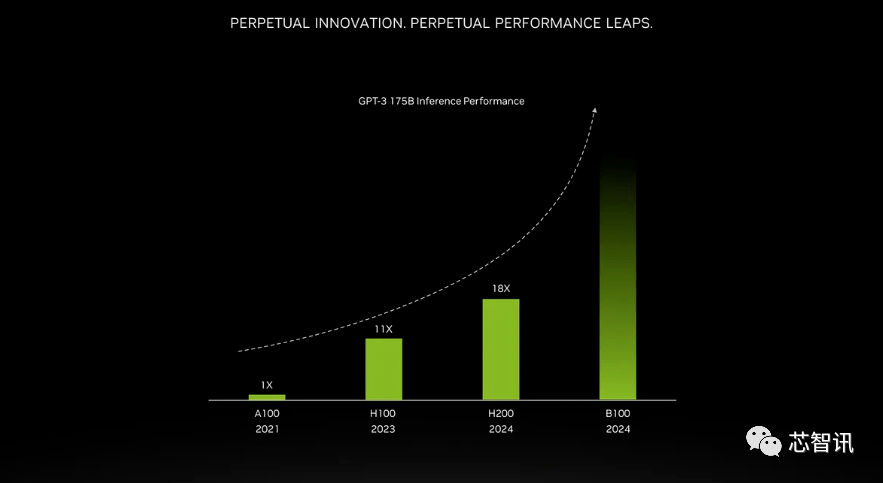
更高带宽内存带来的提升取决于工作量。大型模型(如GPT-3)将极大受益于HBM内存容量的增加。据英伟达表示,H200在运行GPT-3时的性能将比原始A100高出18倍,比H100快大约11倍。此外,即将推出的Blackwell B100的预告片显示,它包含一个逐渐变黑的更高条,大约是H200的两倍最右
不仅如此,H200和H100是互相兼容的。也就是说,使用H100训练/推理模型的AI企业,可以无缝更换成最新的H200芯片。云端服务商将H200新增到产品组合时也不需要进行任何修改。
英伟达表示,通过推出新产品,他们希望跟上用于创建人工智能模型和服务的数据集规模的增长。增强的内存能力将使H200在向软件提供数据的过程中更快速,这个过程有助于训练人工智能执行识别图像和语音等任务。
“整合更快、更大容量的HBM內存有助于对运算要求较高的任务提升性能,包括生成式AI模型和高效能运算应用程序,同时优化GPU使用率和效率”,NVIDIA高性能计算产品副总裁Ian Buck表示。
英伟达数据中心产品负责人迪翁·哈里斯(Dion Harris)表示:“当你观察市场发展的趋势时,会发现模型规模正在迅速增大。这是我们持续引入最新和最优秀技术的典范。”
预计大型计算机制造商和云服务提供商将于2024年第二季度开始使用H200。英伟达服务器制造伙伴(包括永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)可以使用H200更新现有系统,而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端服务商。
鉴于目前市场对于英伟达AI芯片的旺盛需求,以及全新的H200增加了更多的昂贵的HBM3e内存,因此H200的价格肯定会更昂贵。英伟达没有列出它的价格,但上一代H100价格就已经高达25,000美元至40,000美元。
英伟达发言人Kristin Uchiyama表示,最终的定价将由英伟达的制造伙伴来确定
对于H200的推出是否会影响H100的生产,Kristin Uchiyama表示:“我们预计全年的总供应量将会增加。”
英伟达的高端AI芯片一直以来被视为处理大量数据和训练大型语言模型、AI生成工具的最佳选择。然而,在推出H200芯片之时,AI公司仍在市场上拼命寻求A100/H100芯片。市场关注的焦点仍然在于,英伟达是否能够提供足够多的供应来满足市场需求。因此,H200芯片是否会像H100芯片一样供不应求,NVIDIA并没有给出答案
不过,明年对GPU买家来说可能将是一个更有利时期,据《金融时报》8月报导曾指出,NVIDIA计划在2024年将H100产量提升三倍,产量目标将从2023年约50万个增加至2024年200万个。但生成式AI仍在蓬勃发展,未来需求也可能会更大。
举个例子,最新推出的GPT-4大约是在10000-25000块A100上进行训练的。Meta的AI大模型需要大约21000块A100进行训练。Stability AI使用了大约5000块A100。Falcon-40B的训练则需要384块A100
根据马斯克的说法,GPT-5可能需要30000-50000块H100。摩根士丹利的说法是25000个GPU。
Sam Altman否认了在训练GPT-5,但却提过“OpenAI的GPU严重短缺,使用我们产品的人越少越好”。
当然,除了英伟达之外,AMD和英特尔也在积极的进入AI市场与英伟达展开竞争。此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽,这将使其在容量和带宽上远超H200。
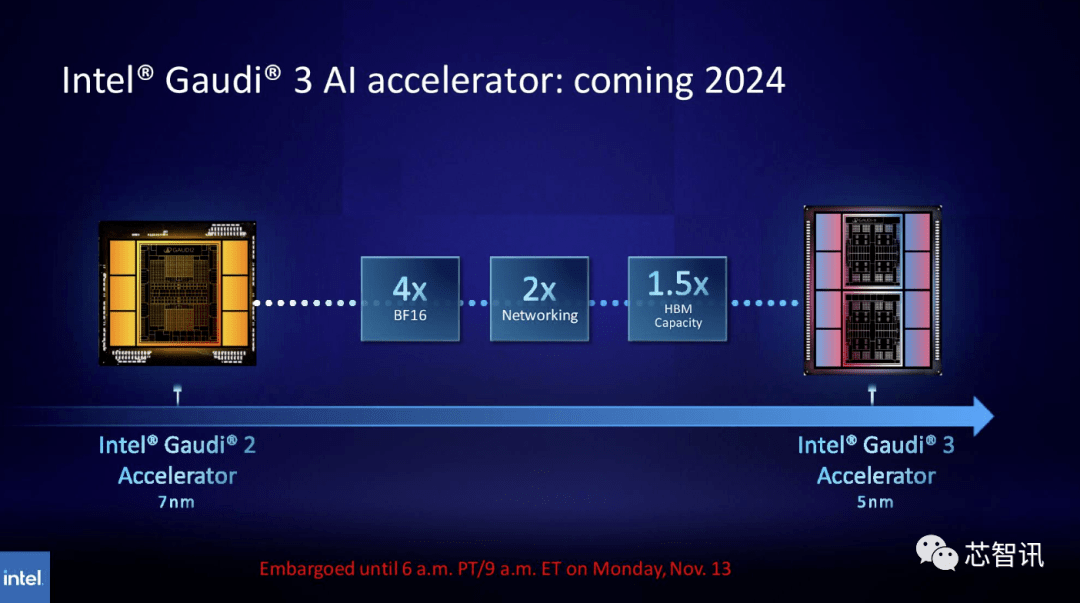
同样,英特尔计划提升Gaudi AI芯片的HBM容量。根据最新公布的信息显示,Gaudi 3采用5nm工艺,其在BF16工作负载方面的性能将是Gaudi 2的四倍,网络性能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic)。此外,Gaudi 3的HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。从下图可以看出,Gaudi 3采用了基于chiplet的设计,具有两个计算集群,而不像Gaudi 2使用英特尔的单芯片解决方案
全新GH200超级芯片:为下一代 AI 超级计算机提供动力
英伟达除了发布全新的H200 GPU外,还推出了升级版的GH200超级芯片。这款芯片采用了NVIDIA NVLink-C2C芯片互连技术,结合了最新的H200 GPU和Grace CPU(不确定是否为升级版)。每个GH200超级芯片还将搭载总计624GB的内存

作为对比,上一代的GH200则是基于H100 GPU和 72 核的Grace CPU,提供了96GB 的 HBM3 和 512 GB 的 LPDDR5X 集成在同一个封装中。
虽然英伟达并未介绍GH200超级芯片当中的Grace CPU细节,但是英伟达提供了GH200 和“现代双路 x86 CPU”之间的一些比较。可以看到,GH200带来了ICON性能8倍的提升,MILC、Quantum Fourier Transform、RAG LLM Inference等更是带来数十倍乃至百倍的提升。
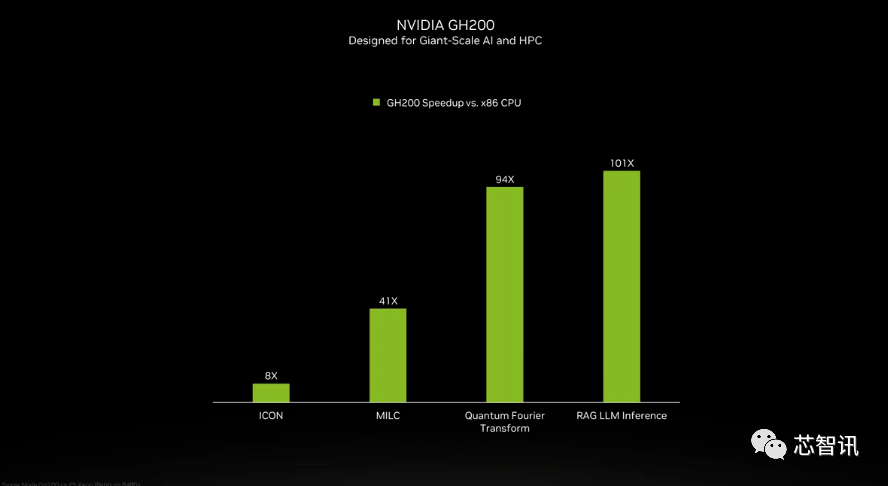
但需要指出的是,其中提到了加速与“非加速系统”。这意味着什么?我们只能假设 x86 服务器运行的是未完全优化的代码,特别是考虑到人工智能世界正在快速发展,并且优化方面似乎定期出现新的进展。
全新的GH200 还将用于新的 HGX H200 系统。据说这些与现有的 HGX H100 系统“无缝兼容”,这意味着 HGX H200 可以在相同的安装中使用,以提高性能和内存容量,而无需重新设计基础设施。
据介绍,瑞士国家超级计算中心的阿尔卑斯超级计算机可能是明年第一批投入使用的基于GH100的Grace Hopper超级计算机之一。第一个在美国投入使用的GH200系统将是洛斯阿拉莫斯国家实验室的Venado超级计算机。德克萨斯高级计算中心(TACC) Vista系统同样将使用刚刚宣布的Grace CPU和Grace Hopper超级芯片,但尚不清楚它们是基于H100还是H200

目前,即将安装的最大的超级计算机是Jϋlich超级计算中心的Jupiter 超级计算机。它将容纳“近”24000 个 GH200 超级芯片,总共 93 exaflops 的 AI 计算(大概是使用 FP8,虽然大多数 AI 仍然使用 BF16 或 FP16)。它还将提供 1 exaflop 的传统 FP64 计算。它将使用具有四个 GH200 超级芯片的“Quad GH200”板。
英伟达预计在未来一年左右安装的这些新型超级计算机,总体来说,将实现超过200 exaflops的人工智能计算能力
不需要改变原始意思的情况下,需要将内容改写成中文,不需要出现原句
以上是新标题:英伟达H200发布:HBM容量提升76%,大幅提升大模型性能90%的最强AI芯片的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 英伟达上线 RTX HDR 功能:不支持的游戏借助 AI 滤镜达到 HDR 艳丽视觉效果
Feb 24, 2024 pm 06:37 PM
英伟达上线 RTX HDR 功能:不支持的游戏借助 AI 滤镜达到 HDR 艳丽视觉效果
Feb 24, 2024 pm 06:37 PM
本站2月23日消息,英伟达昨晚更新推出了NVIDIA应用程序,为玩家提供了全新的统一GPU控制中心,便于玩家通过游戏内悬浮窗提供的强大录像工具捕捉精彩时刻。在本次更新中,英伟达还引入了RTXHDR功能,本站附上官方介绍如下:RTXHDR是一款AI赋能的全新Freestyle滤镜,可以将高动态范围(HDR)的艳丽视觉效果无缝引入到原本不支持HDR的游戏中。你只需拥有兼容HDR的显示器,即可对大量基于DirectX和Vulkan的游戏使用此功能。玩家在启用RTXHDR功能之后,运行即便不支持HD
 消息称英伟达 RTX 50 系列显卡原生配 16-Pin PCIe Gen 6 供电接口
Feb 20, 2024 pm 12:00 PM
消息称英伟达 RTX 50 系列显卡原生配 16-Pin PCIe Gen 6 供电接口
Feb 20, 2024 pm 12:00 PM
本站2月19日消息,Moore'sLawisDead频道最新一期视频中,主播Tom透露英伟达GeForceRTX50系列显卡将原生配备PCIeGen6的16-Pin供电接口。Tom表示除了高端的GeForceRTX5080和GeForceRTX5090系列之外,中端GeForceRTX5060也会启用新的供电接口。消息称英伟达设置明确要求,未来每块GeForceRTX50系列都配备PCIeGen6的16-Pin供电接口,从而简化供应链。本站附上截图如下:Tom还表示GeForceRTX5090在
 英伟达 RTX 4070 和 4060 Ti FE 显卡已降至建议零售价以下,分别为 4599/2999 元
Feb 22, 2024 pm 09:43 PM
英伟达 RTX 4070 和 4060 Ti FE 显卡已降至建议零售价以下,分别为 4599/2999 元
Feb 22, 2024 pm 09:43 PM
本站2月22日消息,一般来说,英伟达和AMD对于渠道定价是有限制的,对于一些私自大幅降价的经销商还会进行处罚,例如AMD最近就对6750GRE显卡低于最低限价的经销商进行了处罚。本站注意到,英伟达GeForceRTX4070和4060Ti已经降至历史新低,其创始人版本,也就是公版显卡目前在京东自营店可以领取200元优惠券,到手价4599元、2999元。当然,若是考虑第三方店铺的话还会有更低的价格。参数方面,RTX4070显卡拥有5888CUDA核心,采用12GBGDDR6X显存,位宽为192bi
 英伟达对话模型ChatQA进化到2.0版本,上下文长度提到128K
Jul 26, 2024 am 08:40 AM
英伟达对话模型ChatQA进化到2.0版本,上下文长度提到128K
Jul 26, 2024 am 08:40 AM
开放LLM社区正是百花齐放、竞相争鸣的时代,你能看到Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1等许多表现优良的模型。但是,相比于以GPT-4-Turbo为代表的专有大模型,开放模型在很多领域依然还有明显差距。在通用模型之外,也有一些专精关键领域的开放模型已被开发出来,比如用于编程和数学的DeepSeek-Coder-V2、用于视觉-语言任务的InternVL
 'AI 工厂”将推动软件全栈重塑,英伟达提供 Llama3 NIM 容器供用户部署
Jun 08, 2024 pm 07:25 PM
'AI 工厂”将推动软件全栈重塑,英伟达提供 Llama3 NIM 容器供用户部署
Jun 08, 2024 pm 07:25 PM
本站6月2日消息,在目前正在进行的黄仁勋2024台北电脑展主题演讲上,黄仁勋介绍生成式人工智能将推动软件全栈重塑,展示其NIM(NvidiaInferenceMicroservices)云原生微服务。英伟达认为“AI工厂”将掀起一场新产业革命:以微软开创的软件行业为例,黄仁勋认为生成式人工智能将推动其全栈重塑。为方便各种规模的企业部署AI服务,英伟达今年3月推出了NIM(NvidiaInferenceMicroservices)云原生微服务。NIM+是一套经过优化的云原生微服务,旨在缩短上市时间
 多次转型,与AI巨头英伟达合作,Vanar Chain凭何30天暴涨4.6倍?
Mar 14, 2024 pm 05:31 PM
多次转型,与AI巨头英伟达合作,Vanar Chain凭何30天暴涨4.6倍?
Mar 14, 2024 pm 05:31 PM
近来,Layer1区块链VanarChain凭借高涨幅以及与AI巨头英伟达合作备受市场关注。VanarChain走红背后,除了经历多次品牌转型,主打游戏、元宇宙和AI等热门概念也为该项目赚足了热度和话题。在进行转型之前,Vanar的前身是TerraVirtua,成立于2018年,最初是一个支持付费订阅、提供虚拟现实(VR)和增强现实(AR)内容的平台,并接受加密货币支付。该平台由联合创始人GaryBracey和JawadAshraf创建,其中GaryBracey在参与视频游戏制作和开发方面拥有超
 恋与深空暴击率怎么提升
Mar 23, 2024 pm 01:31 PM
恋与深空暴击率怎么提升
Mar 23, 2024 pm 01:31 PM
恋与深空中人物有着各方面的数值属性,游戏内的每一种属性都有着其特定的作用,而暴击率这一属性就会影响到角色的伤害,可以说是一项很重要的属性了,而下面要带来的就是这一属性的提升方法了,所以想知道的玩家就可以来看看了。恋与深空暴击率提升方法一、核心方法要想达到80%的暴击率,关键在于你手中的六张卡的暴击属性总和。日冕卡的选择:选择两张日冕卡时,确保它们的芯核α和芯核β副属性词条中至少有一条是暴击属性。月冕卡的优势:月冕卡不仅基础属性中包含暴击,而且当它们达到60级且未突破时,每张卡可以提供4.1%的暴
 集邦咨询:英伟达 Blackwell 平台产品带动台积电今年 CoWoS 产能提高 150%
Apr 17, 2024 pm 08:00 PM
集邦咨询:英伟达 Blackwell 平台产品带动台积电今年 CoWoS 产能提高 150%
Apr 17, 2024 pm 08:00 PM
本站4月17日消息,集邦咨询(TrendForce)近日发布报告,认为英伟达Blackwell新平台产品需求看涨,预估带动台积电2024年CoWoS封装总产能提升逾150%。英伟达Blackwell新平台产品包括B系列的GPU,以及整合英伟达自家GraceArmCPU的GB200加速卡等。集邦咨询确认为供应链当前非常看好GB200,预估2025年出货量有望超过百万片,在英伟达高端GPU中的占比达到40-50%。在英伟达计划下半年交付GB200以及B100等产品,但上游晶圆封装方面须进一步采用更复
