
大约一年前,我被分配任务从文件中提取和结构化数据,主要是包含在表格中的数据。我之前对计算机视觉没有了解,并且很难找到一个合适的“即插即用”的解决方案。当时可选的方案要么是基于最新神经网络(NN)的解决方案,这些解决方案庞大而繁琐,要么是基于OpenCV的较简单的解决方案,但不够一致。
受现有OpenCV脚本的启发,我开发了一种简单而一致的方法来提取表格,并将其制作成一个开源的Python库:img2table
需要被重写的内容是:链接:https://github.com/xavctn/img2table

与深度学习解决方案相比,这个轻量级的包不需要训练和最小化参数化。它提供了以下功能:
可以使用pip来安装这个库,安装完成后就可以使用了
pip install img2table
在文档中识别表格只需调用一个函数:
从img2table.document导入Image类# 图像实例化 img = Image(src="myimage.jpg")# 表格识别 img_tables = img.extract_tables()# 表格识别结果 img_tables[ExtractedTable(title=None, bbox=(10, 8, 745, 314),shape=(6, 3)), ExtractedTable(title=None, bbox=(936, 9, 1129, 111),shape=(2, 2))]
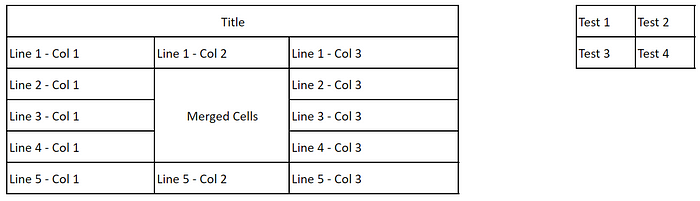
需要被改写的内容是:上述示例中使用的图像
如果我们想要提取表格的内容,就需要使用OCR工具。可以按照以下步骤来实现:
from img2table.document import PDFfrom img2table.ocr import TesseractOCR# Instantiation of the pdfpdf = PDF(src="mypdf.pdf")# Instantiation of the OCR, Tesseract, which requires prior installationocr = TesseractOCR(lang="eng")# Table identification and extractionpdf_tables = pdf.extract_tables(ocr=ocr)# We can also create an excel file with the tablespdf.to_xlsx('tables.xlsx',ocr=ocr)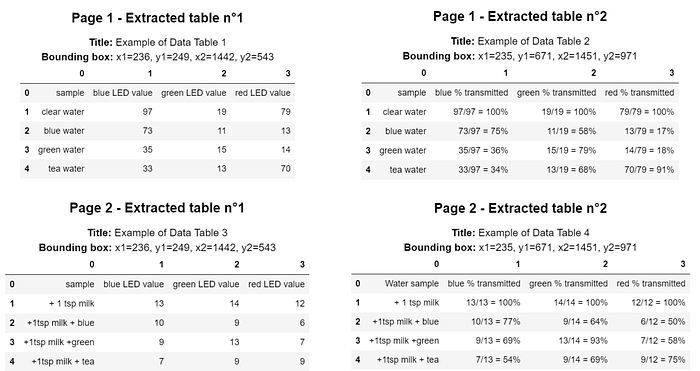
示例表格是从PDF文件中提取出来的样本
最后,在简单的情况下,可以通过设置`borderless_tables`参数来执行“无边框”表格的提取。这允许检测那些单元格不需要完全被边框包围的表格。
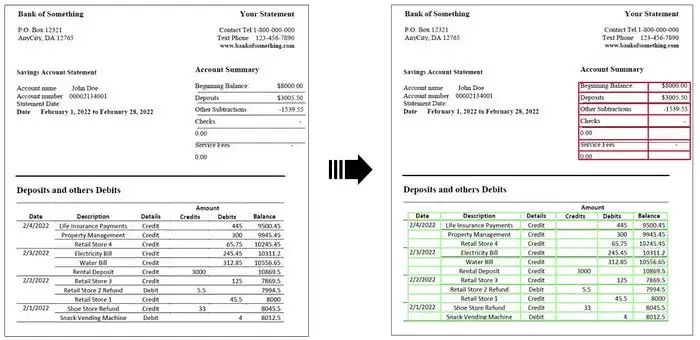
无需更改原始意思,需要重写的内容是:“无边框”表格提取示例
这是全部内容!事实上,仓库并不复杂,因为我们的目标是尽可能简化,避免引入其他可能带来复杂性的解决方案
请访问项目的GitHub页面以获取更详细的文档和示例:https://github.com/xavctn/img2table
所有图像处理都使用OpenCV和opencv-python库完成。然而,这仍然相当基础。
算法的核心是Hough变换,它能够识别图像中的直线,使我们能够检测图像中的水平和垂直线条
需要重写的内容是:cv2.HoughLinesP(img, rho, theta, threshold, None, minLinLength, maxLineGap)
在这之后,我们需要对线条进行一些处理,以便从中识别出单元格,并从单元格中进一步识别出表格
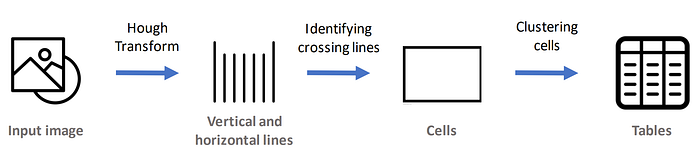
简化算法表示的实现方式
大多数计算使用Polars进行,以实现良好的性能和速度。
以上是使用Python从图像中提取表格的详细内容。更多信息请关注PHP中文网其他相关文章!





















