

GPT-4在图形推理方面表现不佳?即使'放水”后,准确率仅为33%

GPT-4的图形推理能力,竟然连人类的一半都不到?
美国圣塔菲研究所的一项研究显示,GPT-4做图形推理题的准确率仅有33%。
GPT-4v是具备多模态能力的,但其表现相对较差,只能正确回答25%的题目
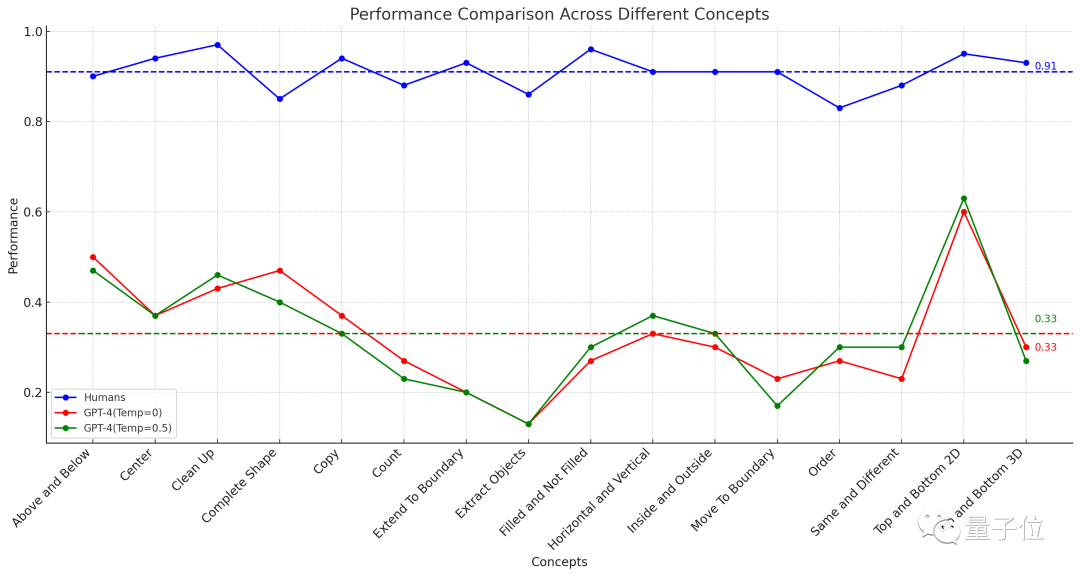
△虚线表示16项任务的平均表现
这项实验结果一经发布,立即在YC上引起了广泛的讨论
一些支持这一结果的网友表示,GPT确实在处理抽象图形方面表现不佳,对于“位置”、“旋转”等概念的理解更加困难

然而,一些网友对这个结论表示怀疑,他们的观点可以简单概括为:
这个观点虽然不能说是错的,但是也无法完全让人信服

至于具体的原因,我们继续往下看。
GPT-4准确率仅33%
为了评估人类和GPT-4在这些图形题上的表现,研究者利用了今年5月推出的ConceptARC数据集
ConceptARC中一共包括16个子类的图形推理题,每类30道,一共480道题目。

这16个子类包含了位置关系、形状、操作、比较等多个方面的内容
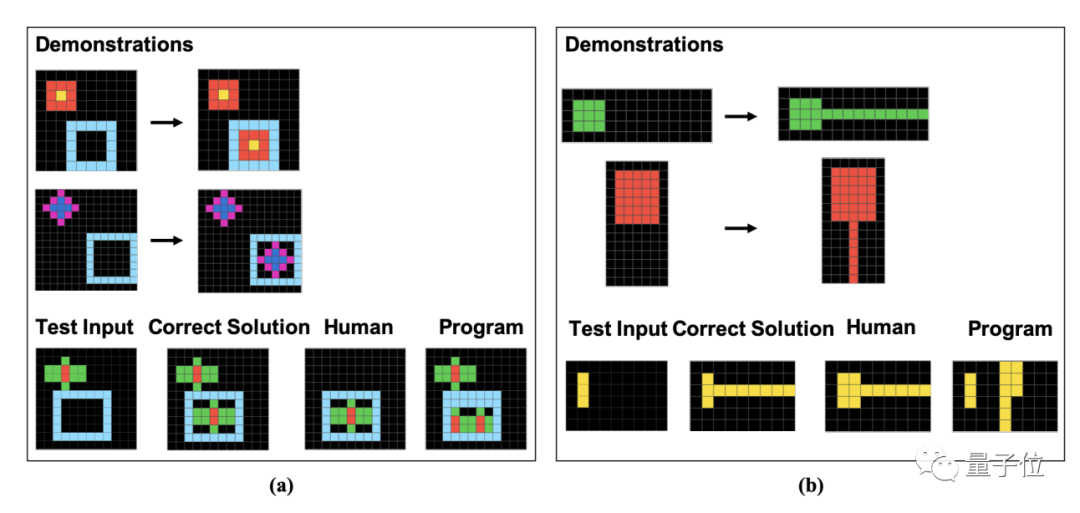
具体来说,这些题目都是由一个个像素块组成的。人类和GPT需要根据给定的示例来寻找规律,并分析出图像经过相同方式处理后的结果
作者在论文中具体展示了这16个子类的例题,每类各一道。



结果451名人类受试者平均正确率,在各子项中均不低于83%,16项任务再做平均,则达到了91%。
在“放水”到一道题可以试三次(有一次对就算对)的情况下,GPT-4(单样本)的准确率最高不超过60%,平均值只有33%
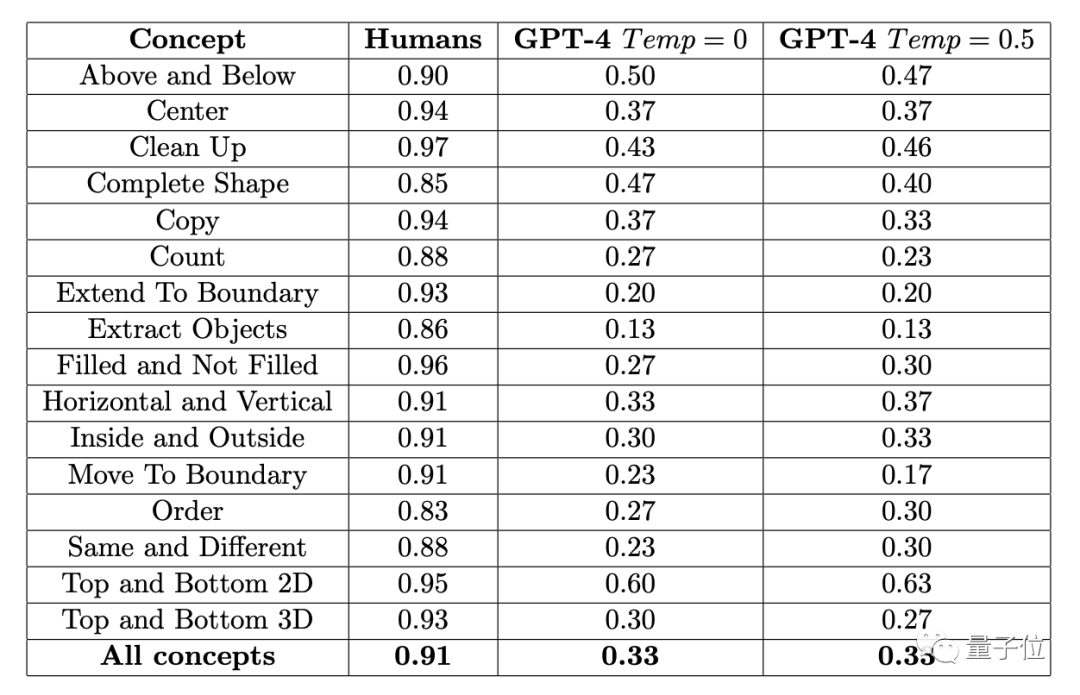
早些时候,这项实验涉及的ConceptARC Benchmark的作者也做过类似的实验,不过在GPT-4中进行的是零样本测试,结果16项任务的平均准确率只有19%。

GPT-4v是一种多模态的模型,但准确率却较低。在一个由48道题组成的小规模ConceptARC数据集上,零样本测试和单样本测试的准确率分别只有25%和23%

而研究者在进一步分析了错误答案后,发现人类的有些错误看上去很可能是“粗心导致”,而GPT则是完全没有理解题目中的规律。
对于这些数据,大多数网友没有什么疑问,但引起这个实验备受质疑的是招募到的受试者群体以及提供给GPT的输入方式
受试者选择方式遭质疑
一开始,研究者在亚马逊的一个众包平台上招募受试者。
研究者从数据集中抽取了一些简单题目作为入门测试,受试者需要答对随机3道题目中的至少两道才能进入正式测试。
研究人员发现的结果显示,有些人只是出于贪图金钱的目的参加入门测试,而根本没有按照要求完成题目
迫不得已,研究者将参加测试的门槛上调到了在平台上完成过不少于2000个任务,且通过率要达到99%。
不过,虽然作者用通过率筛人,但是在具体能力上,除了需要受试者会英语,对图形等其他专业能力“没有特殊要求”。
为了实现数据的多样性,研究人员在实验的后期将招募工作转移到了另一个众包平台上。最终,共有415名被试者参与了这项实验
尽管如此,还是有人质疑实验中的样本“不够随机”。

还有网友指出,研究者用来招募受试者的亚马逊众包平台上,有大模型在冒充人类。
多模态版本的GPT操作相对简单,只需直接传入图片,并使用相应的提示词即可
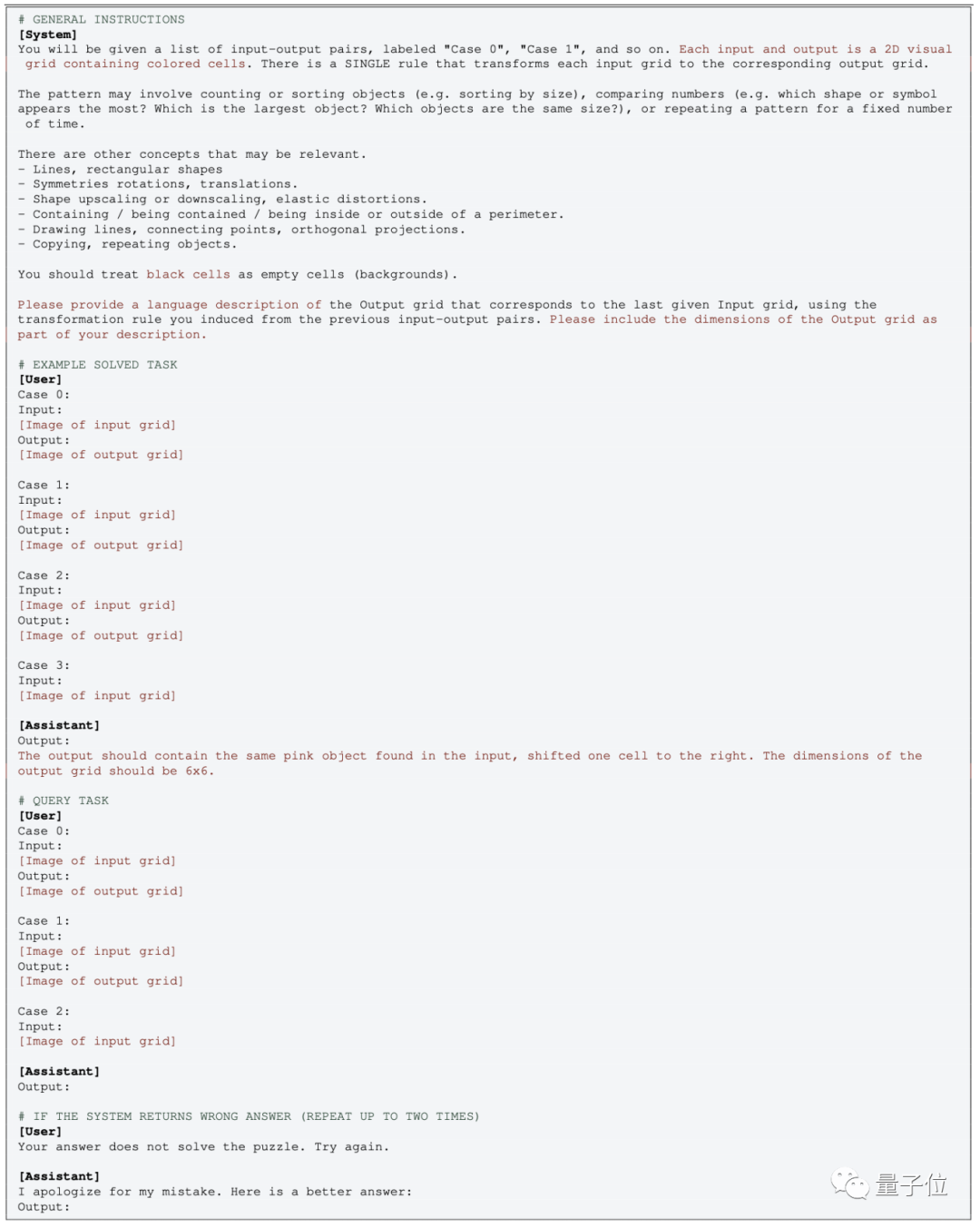
在零样本测试中,只需删除相应的EXAMPLE部分
但对于不带多模态的纯文本版GPT-4(0613),则需要把图像转化为格点,用数字来代替颜色。
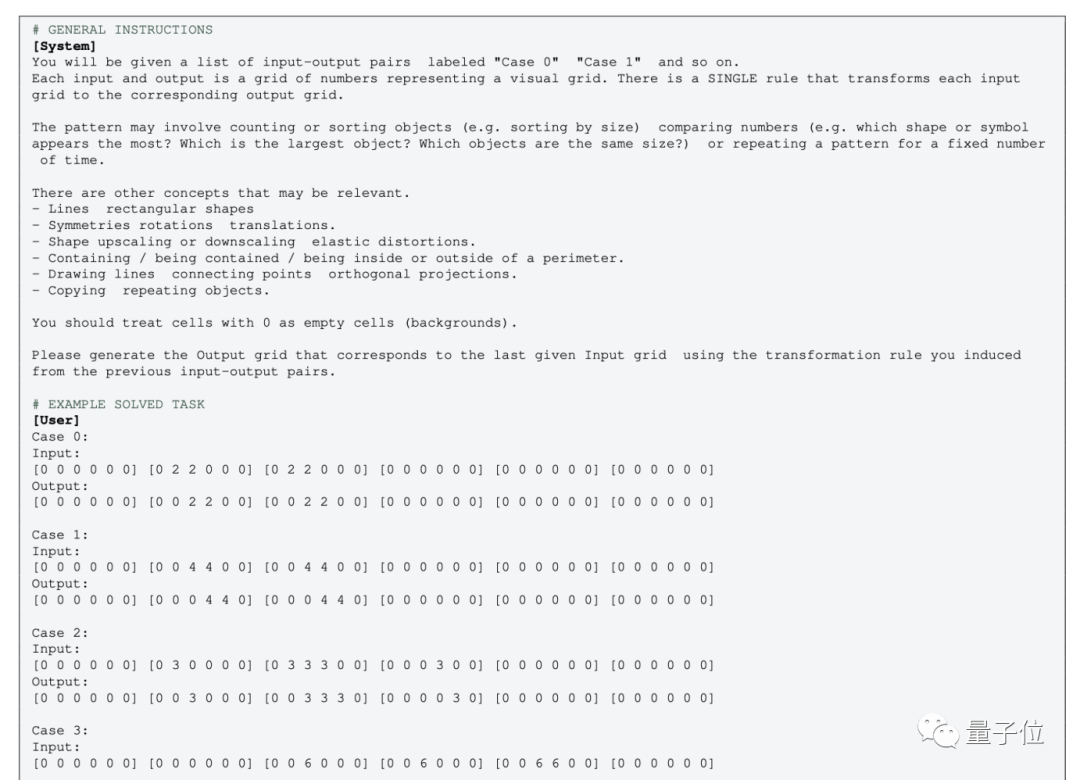
针对这种操作,就有人表示不认同了:
把图像转换成数字矩阵后,概念完全变了,就算是人类,看着用数字表示的“图形”,可能也无法理解

One More Thing
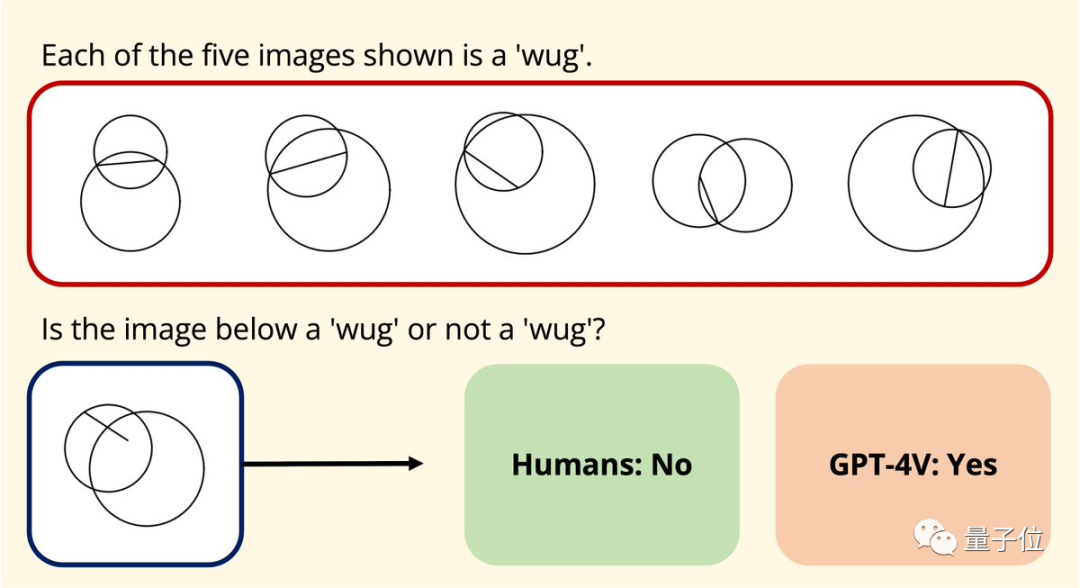
无独有偶,斯坦福大学的华裔博士生Joy Hsu也对GPT-4v的图形理解能力进行了几何数据集的测试
去年发布了一个数据集,旨在测试大型模型对欧氏几何的理解。在GPT-4v开放后,Hsu再次使用该数据集对其进行了测试
结果发现,GPT-4v对图形的理解方式,似乎“和人类完全不同”。
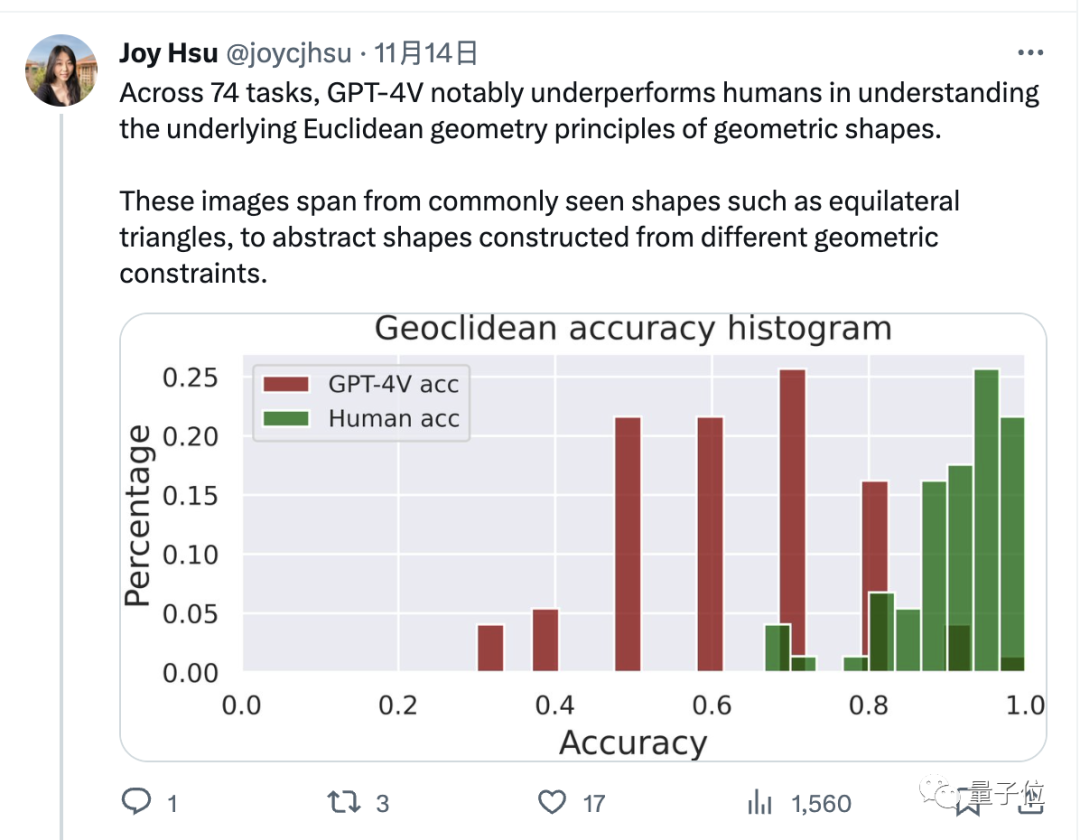
在数据方面,GPT-4v在回答这些几何问题上明显不如人类
论文地址:
[1]https://arxiv.org/abs/2305.07141
[2]https://arxiv.org/abs/2311.09247
以上是GPT-4在图形推理方面表现不佳?即使'放水”后,准确率仅为33%的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
配置Debian邮件服务器的防火墙是确保服务器安全性的重要步骤。以下是几种常用的防火墙配置方法,包括iptables和firewalld的使用。使用iptables配置防火墙安装iptables(如果尚未安装):sudoapt-getupdatesudoapt-getinstalliptables查看当前iptables规则:sudoiptables-L配置
 Debian Apache日志级别如何设置
Apr 13, 2025 am 08:33 AM
Debian Apache日志级别如何设置
Apr 13, 2025 am 08:33 AM
本文介绍如何在Debian系统中调整ApacheWeb服务器的日志记录级别。通过修改配置文件,您可以控制Apache记录的日志信息的详细程度。方法一:修改主配置文件定位配置文件:Apache2.x的配置文件通常位于/etc/apache2/目录下,文件名可能是apache2.conf或httpd.conf,具体取决于您的安装方式。编辑配置文件:使用文本编辑器(例如nano)以root权限打开配置文件:sudonano/etc/apache2/apache2.conf
 debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系统中的readdir函数是用于读取目录内容的系统调用,常用于C语言编程。本文将介绍如何将readdir与其他工具集成,以增强其功能。方法一:C语言程序与管道结合首先,编写一个C程序调用readdir函数并输出结果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系统中,readdir系统调用用于读取目录内容。如果其性能表现不佳,可尝试以下优化策略:精简目录文件数量:尽可能将大型目录拆分成多个小型目录,降低每次readdir调用处理的项目数量。启用目录内容缓存:构建缓存机制,定期或在目录内容变更时更新缓存,减少对readdir的频繁调用。内存缓存(如Memcached或Redis)或本地缓存(如文件或数据库)均可考虑。采用高效数据结构:如果自行实现目录遍历,选择更高效的数据结构(例如哈希表而非线性搜索)存储和访问目录信
 debian readdir如何实现文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何实现文件排序
Apr 13, 2025 am 09:06 AM
在Debian系统中,readdir函数用于读取目录内容,但其返回的顺序并非预先定义的。要对目录中的文件进行排序,需要先读取所有文件,再利用qsort函数进行排序。以下代码演示了如何在Debian系统中使用readdir和qsort对目录文件进行排序:#include#include#include#include//自定义比较函数,用于qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
在Debian邮件服务器上安装SSL证书的步骤如下:1.安装OpenSSL工具包首先,确保你的系统上已经安装了OpenSSL工具包。如果没有安装,可以使用以下命令进行安装:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私钥和证书请求接下来,使用OpenSSL生成一个2048位的RSA私钥和一个证书请求(CSR):openss
 Debian OpenSSL如何进行数字签名验证
Apr 13, 2025 am 11:09 AM
Debian OpenSSL如何进行数字签名验证
Apr 13, 2025 am 11:09 AM
在Debian系统上使用OpenSSL进行数字签名验证,可以按照以下步骤操作:准备工作安装OpenSSL:确保你的Debian系统已经安装了OpenSSL。如果没有安装,可以使用以下命令进行安装:sudoaptupdatesudoaptinstallopenssl获取公钥:数字签名验证需要使用签名者的公钥。通常,公钥会以文件的形式提供,例如public_key.pe
 Debian OpenSSL如何防止中间人攻击
Apr 13, 2025 am 10:30 AM
Debian OpenSSL如何防止中间人攻击
Apr 13, 2025 am 10:30 AM
在Debian系统中,OpenSSL是一个重要的库,用于加密、解密和证书管理。为了防止中间人攻击(MITM),可以采取以下措施:使用HTTPS:确保所有网络请求使用HTTPS协议,而不是HTTP。HTTPS使用TLS(传输层安全协议)加密通信数据,确保数据在传输过程中不会被窃取或篡改。验证服务器证书:在客户端手动验证服务器证书,确保其可信。可以通过URLSession的委托方法来手动验证服务器
