

Stable Video Diffusion来了,代码权重已上线

AI 画图的著名公司 Stability AI,终于入局 AI 生成视频了。
这周二,基于稳定扩散的视频生成模型 Stable Video Diffusion 推出了,AI 社区立即展开了讨论
很多人都表示「我们终于等到了」。
项目链接:https://github.com/Stability-AI/generative-models
现在,你可以利用现有的静态图像生成几秒钟的视频
基于 Stability AI 原有的 Stable Diffusion 文生图模型,Stable Video Diffusion 成为了开源或已商业行列中为数不多的视频生成模型之一。


但目前还不是所有人都可以使用,Stable Video Diffusion 已经开放了用户候补名单注册(https://stability.ai/contact)。
根据介绍,稳定视频传播可以轻松适应各种下游任务,包括通过对多视图数据集进行微调,从单个图像进行多视图合成。稳定人工智能表示,正在计划建立和扩展这一基础的各种模型,类似于围绕稳定扩散建立的生态系统


通过稳定的视频传播,可以以每秒3到30帧的可定制帧速率生成14和25帧的视频
在外部评估中,Stability AI 证实这些模型超越了用户偏好研究中领先的闭源模型:

Stability AI 强调,Stable Video Diffusion 现阶段不适用于现实世界或直接的商业应用,后续将根据用户对安全和质量的见解和反馈完善该模型。

论文地址:https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
稳定的视频传输是稳定AI开源模型家族中的一员。现在看来,他们的产品已涵盖图像、语言、音频、三维和代码等多个模态,这充分证明了他们对提升人工智能的承诺
Stable Video Diffusion 的技术层面
稳定视频扩散模型作为一种高分辨率视频的潜在扩散模型,已经达到了文本到视频或图像到视频的 SOTA 水平。最近,通过在小型高质量视频数据集上插入时间层并进行微调,将2D图像合成训练的潜在扩散模型转变为生成视频模型。然而,文献中的训练方法千差万别,该领域尚未就视频数据整理的统一策略达成一致
在 Stable Video Diffusion 的论文中,Stability AI 确定并评估了成功训练视频潜在扩散模型的三个不同阶段:文本到图像预训练、视频预训练和高质量视频微调。他们还证明了精心准备的预训练数据集对于生成高质量视频的重要性,并介绍了训练出一个强大基础模型的系统化策划流程,其中包括了字幕和过滤策略。
Stability AI 在论文中还探讨了在高质量数据上对基础模型进行微调的影响,并训练出一个可与闭源视频生成相媲美的文本到视频模型。该模型为下游任务提供了强大的运动表征,例如图像到视频的生成以及对摄像机运动特定的 LoRA 模块的适应性。除此之外,该模型还能够提供强大的多视图 3D 先验,这可以作为多视图扩散模型的基础,模型以前馈方式生成对象的多个视图,只需要较小的算力需求,性能还优于基于图像的方法。

具体而言,训练该模型成功需要经历以下三个阶段:
阶段一:图像预训练。本文将图像预训练视为训练 pipeline 的第一阶段,并将初始模型建立在 Stable Diffusion 2.1 的基础上,这样一来为视频模型配备了强大的视觉表示。为了分析图像预训练的效果,本文还训练并比较了两个相同的视频模型。图 3a 结果表明,图像预训练模型在质量和提示跟踪方面都更受青睐。
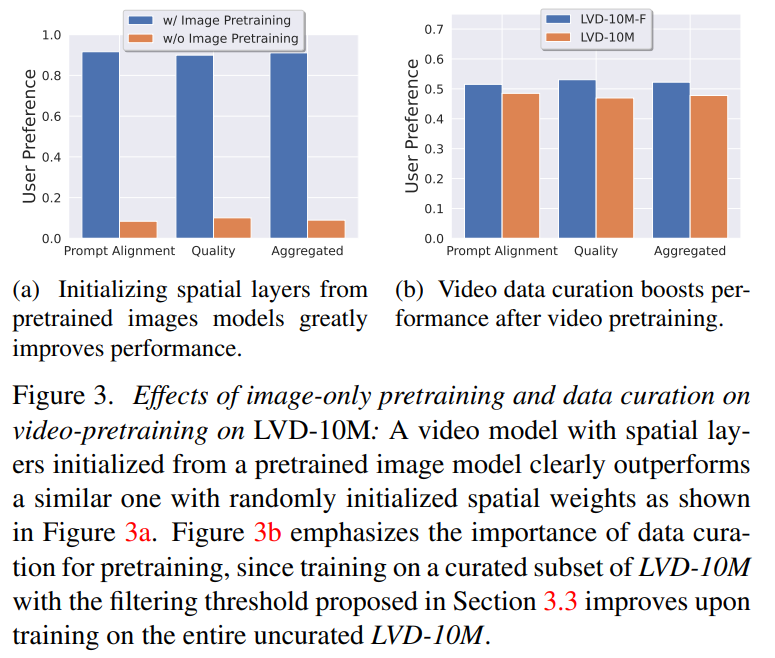
阶段 2:视频预训练数据集。本文依靠人类偏好作为信号来创建合适的预训练数据集。本文创建的数据集为 LVD(Large Video Dataset ),由 580M 对带注释的视频片段组成。
进一步调查发现,生成的数据集中包含一些可能会降低最终视频模型性能的样例。因此,在本文中我们使用了密集光流来给数据集进行标注
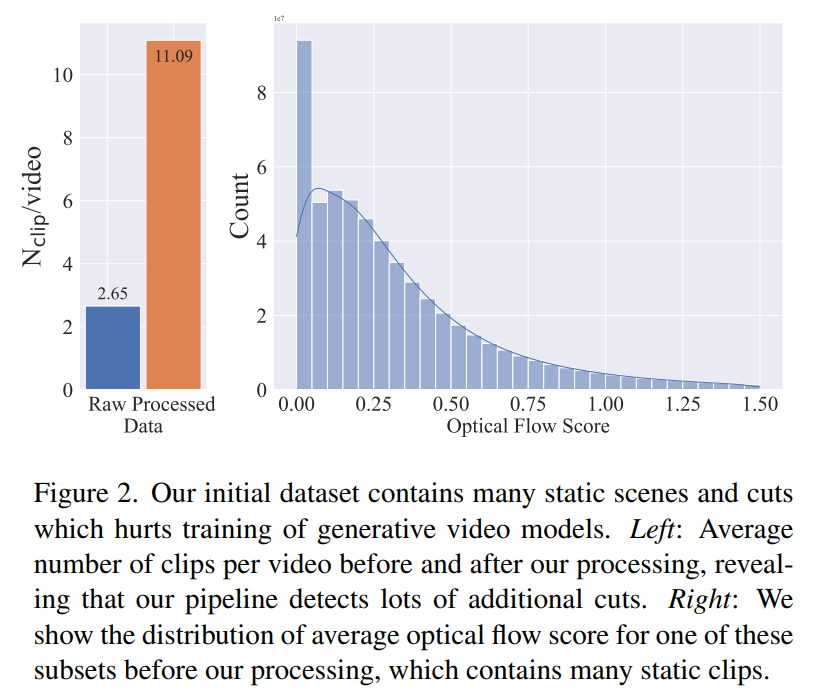
此外,本文还应用光学字符识别来清除包含大量文本的剪辑。最后,本文使用 CLIP 嵌入来注释每个剪辑的第一帧、中间帧和最后一帧。下表提供了 LVD 数据集的一些统计信息:
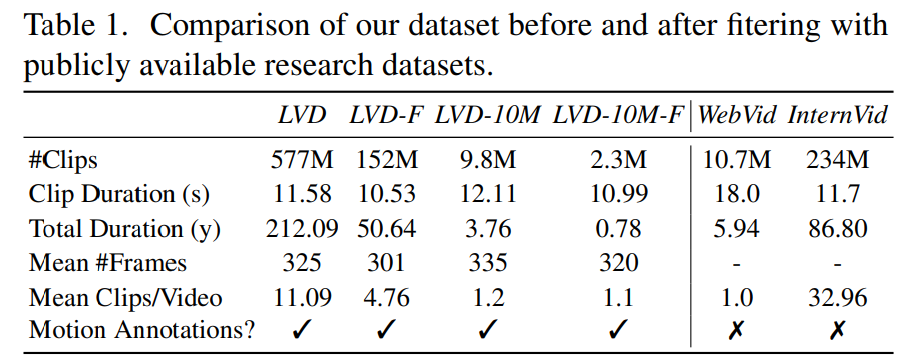
阶段 3:高质量微调。为了分析视频预训练对最后阶段的影响,本文对三个模型进行了微调,这些模型仅在初始化方面有所不同。图 4e 为结果。

看起来这是个好的开始。什么时候,我们能用 AI 直接生成一部电影呢?
以上是Stable Video Diffusion来了,代码权重已上线的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 phpmyadmin建立数据表
Apr 10, 2025 pm 11:00 PM
phpmyadmin建立数据表
Apr 10, 2025 pm 11:00 PM
要使用 phpMyAdmin 创建数据表,以下步骤必不可少:连接到数据库并单击“新建”标签。为表命名并选择存储引擎(推荐 InnoDB)。通过单击“添加列”按钮添加列详细信息,包括列名、数据类型、是否允许空值以及其他属性。选择一个或多个列作为主键。单击“保存”按钮创建表和列。
 怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
创建Oracle数据库并非易事,需理解底层机制。1. 需了解数据库和Oracle DBMS的概念;2. 掌握SID、CDB(容器数据库)、PDB(可插拔数据库)等核心概念;3. 使用SQL*Plus创建CDB,再创建PDB,需指定大小、数据文件数、路径等参数;4. 高级应用需调整字符集、内存等参数,并进行性能调优;5. 需注意磁盘空间、权限和参数设置,并持续监控和优化数据库性能。 熟练掌握需不断实践,才能真正理解Oracle数据库的创建和管理。
 oracle数据库怎么创建 oracle数据库怎么建库
Apr 11, 2025 pm 02:36 PM
oracle数据库怎么创建 oracle数据库怎么建库
Apr 11, 2025 pm 02:36 PM
创建Oracle数据库,常用方法是使用dbca图形化工具,步骤如下:1. 使用dbca工具,设置dbName指定数据库名;2. 设置sysPassword和systemPassword为强密码;3. 设置characterSet和nationalCharacterSet为AL32UTF8;4. 设置memorySize和tablespaceSize根据实际需求调整;5. 指定logFile路径。 高级方法为使用SQL命令手动创建,但更复杂易错。 需要注意密码强度、字符集选择、表空间大小及内存
 oracle数据库的语句怎么写
Apr 11, 2025 pm 02:42 PM
oracle数据库的语句怎么写
Apr 11, 2025 pm 02:42 PM
Oracle SQL语句的核心是SELECT、INSERT、UPDATE和DELETE,以及各种子句的灵活运用。理解语句背后的执行机制至关重要,如索引优化。高级用法包括子查询、连接查询、分析函数和PL/SQL。常见错误包括语法错误、性能问题和数据一致性问题。性能优化最佳实践涉及使用适当的索引、避免使用SELECT *、优化WHERE子句和使用绑定变量。掌握Oracle SQL需要实践,包括代码编写、调试、思考和理解底层机制。
 MySQL数据表字段操作指南之添加、修改与删除方法
Apr 11, 2025 pm 05:42 PM
MySQL数据表字段操作指南之添加、修改与删除方法
Apr 11, 2025 pm 05:42 PM
MySQL 中字段操作指南:添加、修改和删除字段。添加字段:ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY] [AUTO_INCREMENT]修改字段:ALTER TABLE table_name MODIFY column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY]
 MySQL数据库中的嵌套查询实例详解
Apr 11, 2025 pm 05:48 PM
MySQL数据库中的嵌套查询实例详解
Apr 11, 2025 pm 05:48 PM
嵌套查询是一种在一个查询中包含另一个查询的方式,主要用于检索满足复杂条件、关联多张表以及计算汇总值或统计信息的数据。实例示例包括:查找高于平均工资的雇员、查找特定类别的订单以及计算每种产品的总订购量。编写嵌套查询时,需要遵循:编写子查询、将其结果写入外层查询(使用别名或 AS 子句引用)、优化查询性能(使用索引)。
 oracle数据库表的完整性约束有哪些
Apr 11, 2025 pm 03:42 PM
oracle数据库表的完整性约束有哪些
Apr 11, 2025 pm 03:42 PM
Oracle 数据库的完整性约束可确保数据准确性,包括:NOT NULL:禁止空值;UNIQUE:保证唯一性,允许单个 NULL 值;PRIMARY KEY:主键约束,加强 UNIQUE,禁止 NULL 值;FOREIGN KEY:维护表间关系,外键引用主表主键;CHECK:根据条件限制列值。
 oracle是干嘛的
Apr 11, 2025 pm 06:06 PM
oracle是干嘛的
Apr 11, 2025 pm 06:06 PM
Oracle 是全球最大的数据库管理系统(DBMS)软件公司,其主要产品包括以下功能:关系数据库管理系统(Oracle 数据库)开发工具(Oracle APEX、Oracle Visual Builder)中间件(Oracle WebLogic Server、Oracle SOA Suite)云服务(Oracle Cloud Infrastructure)分析和商业智能(Oracle Analytics Cloud、Oracle Essbase)区块链(Oracle Blockchain Pla
