

Stable Video Diffusion问世!3D合成功能引关注,网友:进步太快

稳定扩散官方终于开始处理视频——
发布生成式视频模型Stable Video Diffusion(SVD)。
Stability AI官方博客显示,全新SVD支持文本到视频、图像到视频生成:

并且还支持物体从单一视角到多视角的转化,也就是3D合成:

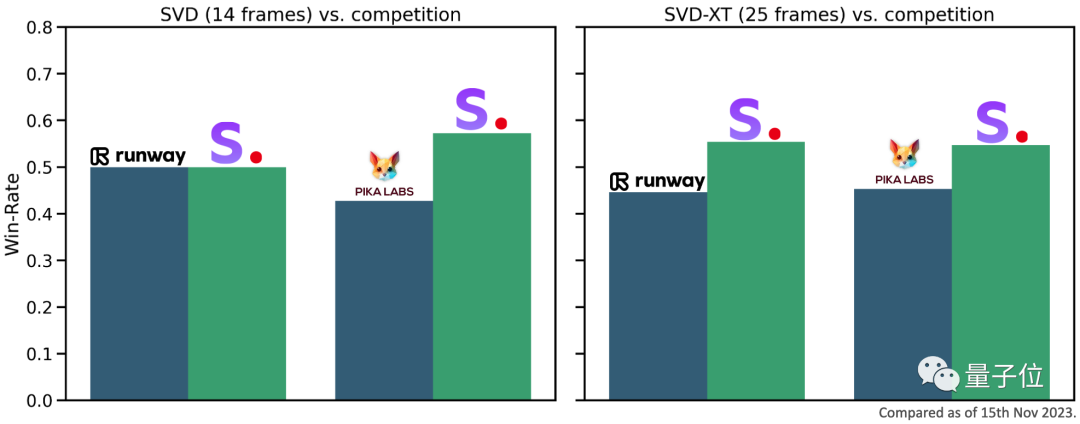
根据外部评估,官方宣称SVD甚至比runway和Pika的视频生成AI更受用户欢迎。
尽管目前只发布了基础模型,但官方透露“正计划继续扩展,建立类似于稳定扩散的生态系统”
目前论文代码权重已上线。

近期视频生成领域不断涌现新的玩法,如今轮到了Stable Diffusion的出现,以至于网友们纷纷感叹“快”,这样进步的速度太快了!

但仅从Demo效果来说,更多网友们表示并没有感到很惊喜。
虽然我喜欢SD,而且这些Demo也很棒……但也存在一些缺陷,光影不对、而且整体不连贯(视频帧与帧之间闪烁)。

总归来说这是个开始,网友对SVD的3D合成功能还满是看好:
我敢保证,很快就会有更好的东西问世,只需要简单描述一下,就能够呈现一个完整的3D场景

SD视频官方版来袭
除了以上所展示的,官方还发布了更多的演示,下面来先看一下:

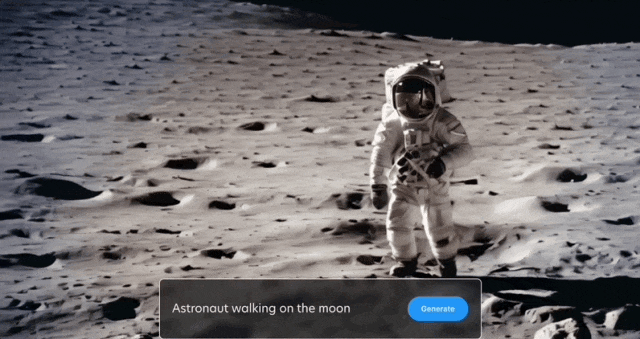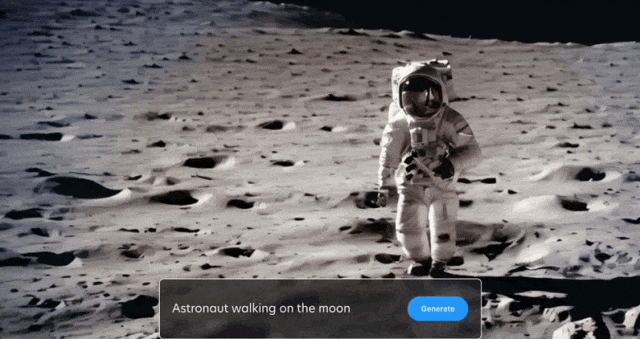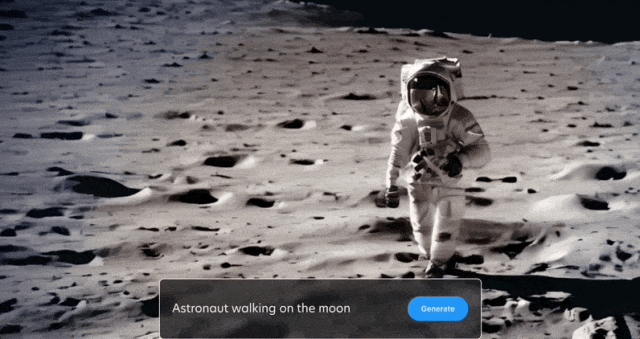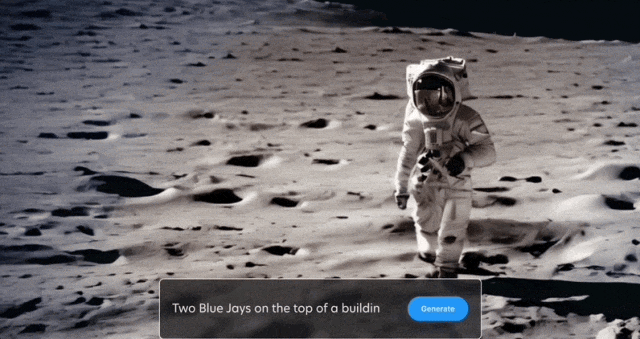
太空漫步也安排上:
保持背景静止,只让两只鸟移动也可以:

SVD的研究论文目前也已发布,据介绍SVD基于Stable Diffusion 2.1,用约6亿个样本的视频数据集预训练了基础模型。
可轻松适应各种下游任务,包括通过对多视图数据集进行微调从单个图像进行多视图合成。
经过微调后,官方公布了两种图像到视频模型。这些模型可以根据用户的需求,以每秒3到30帧的自定义帧速率生成14帧(SVD)和25帧(SVD-XT)的视频
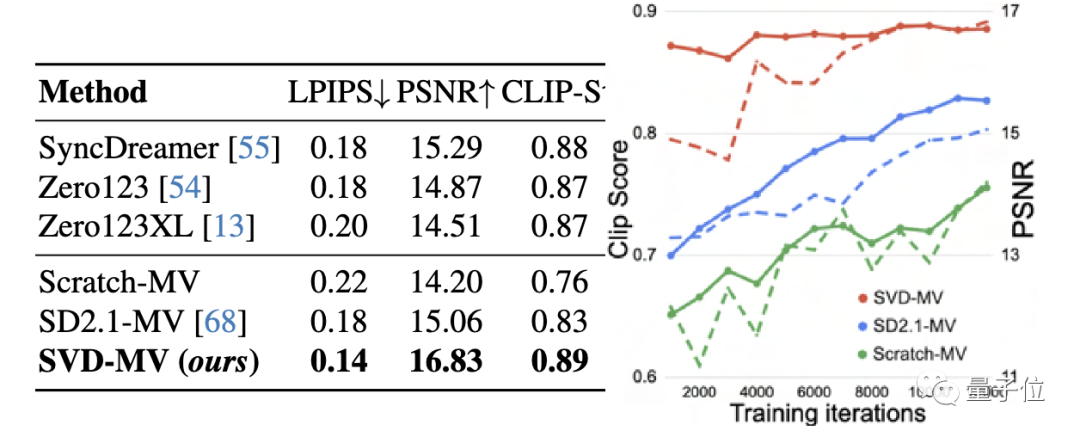
对多视角视频生成模型进行了微调后,我们将其命名为SVD-MV

根据测试结果,在GSO数据集上,SVD-MV得分优于多视角生成模型Zero123、Zero123XL、SyncDreamer:
值得一提的是,Stability AI表示SVD目前仅限于研究,不适用于实际或商业应用。SVD目前也不是所有人都可以使用,但已开放用户候补名单注册。
视频生成大爆发
近期,视频生成领域出现了一种“混战”状态
前有PikaLabs开发的文生视频AI:

后又有号称“史上最强大的视频生成AIMoonvalley推出:

最近Gen-2的“运动笔刷”功能也正式上线,指哪画哪:

这不现在SVD又出现了,又有要卷3D视频生成的可能。
但文本到3D生成方面好像还没有太多进展,网友对这一现象也很是困惑。

有人认为数据是阻碍发展的瓶颈:

还有一些网友认为问题在于强化学习的能力还不够强

家人们对这方面的最新进展有了解吗?欢迎评论区分享~
论文链接:https://static1.squarespace.com/static/6213c340453c3f502425776e/t/655ce779b9d47d342a93c890/1700587395994/stable_video_diffusion.pdf 需要重新写的内容是:
以上是Stable Video Diffusion问世!3D合成功能引关注,网友:进步太快的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
创建Oracle数据库并非易事,需理解底层机制。1. 需了解数据库和Oracle DBMS的概念;2. 掌握SID、CDB(容器数据库)、PDB(可插拔数据库)等核心概念;3. 使用SQL*Plus创建CDB,再创建PDB,需指定大小、数据文件数、路径等参数;4. 高级应用需调整字符集、内存等参数,并进行性能调优;5. 需注意磁盘空间、权限和参数设置,并持续监控和优化数据库性能。 熟练掌握需不断实践,才能真正理解Oracle数据库的创建和管理。
 oracle数据库怎么创建 oracle数据库怎么建库
Apr 11, 2025 pm 02:36 PM
oracle数据库怎么创建 oracle数据库怎么建库
Apr 11, 2025 pm 02:36 PM
创建Oracle数据库,常用方法是使用dbca图形化工具,步骤如下:1. 使用dbca工具,设置dbName指定数据库名;2. 设置sysPassword和systemPassword为强密码;3. 设置characterSet和nationalCharacterSet为AL32UTF8;4. 设置memorySize和tablespaceSize根据实际需求调整;5. 指定logFile路径。 高级方法为使用SQL命令手动创建,但更复杂易错。 需要注意密码强度、字符集选择、表空间大小及内存
 oracle数据库的语句怎么写
Apr 11, 2025 pm 02:42 PM
oracle数据库的语句怎么写
Apr 11, 2025 pm 02:42 PM
Oracle SQL语句的核心是SELECT、INSERT、UPDATE和DELETE,以及各种子句的灵活运用。理解语句背后的执行机制至关重要,如索引优化。高级用法包括子查询、连接查询、分析函数和PL/SQL。常见错误包括语法错误、性能问题和数据一致性问题。性能优化最佳实践涉及使用适当的索引、避免使用SELECT *、优化WHERE子句和使用绑定变量。掌握Oracle SQL需要实践,包括代码编写、调试、思考和理解底层机制。
 MySQL数据表字段操作指南之添加、修改与删除方法
Apr 11, 2025 pm 05:42 PM
MySQL数据表字段操作指南之添加、修改与删除方法
Apr 11, 2025 pm 05:42 PM
MySQL 中字段操作指南:添加、修改和删除字段。添加字段:ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY] [AUTO_INCREMENT]修改字段:ALTER TABLE table_name MODIFY column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY]
 oracle数据库表的完整性约束有哪些
Apr 11, 2025 pm 03:42 PM
oracle数据库表的完整性约束有哪些
Apr 11, 2025 pm 03:42 PM
Oracle 数据库的完整性约束可确保数据准确性,包括:NOT NULL:禁止空值;UNIQUE:保证唯一性,允许单个 NULL 值;PRIMARY KEY:主键约束,加强 UNIQUE,禁止 NULL 值;FOREIGN KEY:维护表间关系,外键引用主表主键;CHECK:根据条件限制列值。
 MySQL数据库中的嵌套查询实例详解
Apr 11, 2025 pm 05:48 PM
MySQL数据库中的嵌套查询实例详解
Apr 11, 2025 pm 05:48 PM
嵌套查询是一种在一个查询中包含另一个查询的方式,主要用于检索满足复杂条件、关联多张表以及计算汇总值或统计信息的数据。实例示例包括:查找高于平均工资的雇员、查找特定类别的订单以及计算每种产品的总订购量。编写嵌套查询时,需要遵循:编写子查询、将其结果写入外层查询(使用别名或 AS 子句引用)、优化查询性能(使用索引)。
 如何配置Debian Apache日志格式
Apr 12, 2025 pm 11:30 PM
如何配置Debian Apache日志格式
Apr 12, 2025 pm 11:30 PM
本文介绍如何在Debian系统上自定义Apache的日志格式。以下步骤将指导您完成配置过程:第一步:访问Apache配置文件Debian系统的Apache主配置文件通常位于/etc/apache2/apache2.conf或/etc/apache2/httpd.conf。使用以下命令以root权限打开配置文件:sudonano/etc/apache2/apache2.conf或sudonano/etc/apache2/httpd.conf第二步:定义自定义日志格式找到或
 oracle是干嘛的
Apr 11, 2025 pm 06:06 PM
oracle是干嘛的
Apr 11, 2025 pm 06:06 PM
Oracle 是全球最大的数据库管理系统(DBMS)软件公司,其主要产品包括以下功能:关系数据库管理系统(Oracle 数据库)开发工具(Oracle APEX、Oracle Visual Builder)中间件(Oracle WebLogic Server、Oracle SOA Suite)云服务(Oracle Cloud Infrastructure)分析和商业智能(Oracle Analytics Cloud、Oracle Essbase)区块链(Oracle Blockchain Pla
