

使用LangChain和OpenAI API进行文档分析的方法

译者需要改写的内容是:|需要改写的内容是:布加迪
审校需要改写的内容是:|需要改写的内容是:重楼
从文档和数据中提取洞察力对于您做出明智的决策至关重要。然而在处理敏感信息时,会出现隐私问题。结合使用LangChain与OpenAI需要改写的内容是:API,您就可以分析本地文档,无需上传到网上。
它们通过将数据保存在本地、使用嵌入和向量化进行分析以及在您的环境中执行进程来做到这一点。OpenAI不使用客户通过其API提交的数据来训练模型或改进服务。
搭建环境
创建一个新的Python虚拟环境,这将确保没有库版本冲突。然后运行以下终端命令来安装所需的库。
pip需要改写的内容是:install需要改写的内容是:langchain需要改写的内容是:openai需要改写的内容是:tiktoken需要改写的内容是:faiss-cpu需要改写的内容是:pypdf
下面详细说明您将如何使用每个库:
- LangChain:您将用它来创建和管理用于文本处理和分析的语言链。它将提供用于文档加载、文本分割、嵌入和向量存储的模块。
- OpenAI:您将用它来运行查询,并从语言模型获取结果。
- tiktoken:您将用它来计算给定文本中token(文本单位)的数量。这是为了在与基于您使用的token数量收费的OpenAI需要改写的内容是:API交互时跟踪token计数。
- FAISS:您将用它来创建和管理向量存储,允许基于嵌入快速检索相似的向量。
- PyPDF:这个库从PDF提取文本。它有助于加载PDF文件并提取其文本,供进一步处理。
安装完所有库之后,您的环境现已准备就绪。
获得OpenAI需要改写的内容是:API密钥
当您向OpenAI需要改写的内容是:API发出请求时,需要添加API密钥作为请求的一部分。该密钥允许API提供者验证请求是否来自合法来源,以及您是否拥有访问其功能所需的权限。
为了获得OpenAI需要改写的内容是:API密钥,进入到OpenAI平台。
然后在右上方的帐户个人资料下,点击“查看API密钥”,将出现API密钥页面。
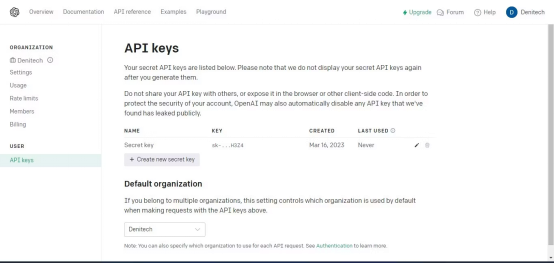
点击“创建新的密钥”按钮。为密钥命名,点击“创建新密钥”。OpenAI将生成API密钥,您应该复制并保存在安全的地方。出于安全原因,您将无法通过OpenAI帐户再次查看它。如果丢失了该密钥,需要生成新的密钥。
导入所需的库
为了能够使用安装在虚拟环境中的库,您需要导入它们。
from需要改写的内容是:langchain.document_loaders需要改写的内容是:import需要改写的内容是:PyPDFLoader,需要改写的内容是:TextLoaderfrom需要改写的内容是:langchain.text_splitter需要改写的内容是:import需要改写的内容是:CharacterTextSplitterfrom需要改写的内容是:langchain.embeddings.openai需要改写的内容是:import需要改写的内容是:OpenAIEmbeddingsfrom需要改写的内容是:langchain.vectorstores需要改写的内容是:import需要改写的内容是:FAISSfrom需要改写的内容是:langchain.chains需要改写的内容是:import需要改写的内容是:RetrievalQAfrom需要改写的内容是:langchain.llms需要改写的内容是:import需要改写的内容是:OpenAI
注意,您从LangChain导入了依赖项库,这让您可以使用LangChain框架的特定功能。
加载用于分析的文档
先创建一个含有API密钥的变量。稍后,您将在代码中使用该变量用于身份验证。
#需要改写的内容是:Hardcoded需要改写的内容是:API需要改写的内容是:keyopenai_api_key需要改写的内容是:=需要改写的内容是:"Your需要改写的内容是:API需要改写的内容是:key"
如果您打算与第三方共享您的代码,不建议对API密钥进行硬编码。对于打算分发的生产级代码,则改而使用环境变量。
接下来,创建一个加载文档的函数。该函数应该加载PDF或文本文件。如果文档既不是PDF文件,也不是文本文件,该函数会抛出值错误。
def需要改写的内容是:load_document(filename):if需要改写的内容是:filename.endswith(".pdf"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:PyPDFLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:elif需要改写的内容是:filename.endswith(".txt"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:TextLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:else:需要改写的内容是:raise需要改写的内容是:ValueError("Invalid需要改写的内容是:file需要改写的内容是:type")加载文档后,创建一个CharacterTextSplitter。该分割器将基于字符将已加载的文档分隔成更小的块。
需要改写的内容是:
text_splitter需要改写的内容是:=需要改写的内容是:CharacterTextSplitter(chunk_size=1000,需要改写的内容是:需要改写的内容是:chunk_overlap=30,需要改写的内容是:separator="\n")需要改写的内容是:return需要改写的内容是:text_splitter.split_documents(documents=documents)
分割文档可确保块的大小易于管理,仍与一些重叠的上下文相连接。这对于文本分析和信息检索之类的任务非常有用。
查询文档
您需要一种方法来查询上传的文档,以便从中获得洞察力。为此,创建一个以查询字符串和检索器作为输入的函数。然后,它使用检索器和OpenAI语言模型的实例创建一个RetrievalQA实例。
def需要改写的内容是:query_pdf(query,需要改写的内容是:retriever):qa需要改写的内容是:=需要改写的内容是:RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),需要改写的内容是:chain_type="stuff",需要改写的内容是:retriever=retriever)result需要改写的内容是:=需要改写的内容是:qa.run(query)需要改写的内容是:print(result)
该函数使用创建的QA实例来运行查询并输出结果。
创建主函数
主函数将控制整个程序流。它将接受用户输入的文档文件名并加载该文档。然后为文本嵌入创建OpenAIEmbeddings实例,并基于已加载的文档和文本嵌入构造一个向量存储。将该向量存储保存到本地文件。
接下来,从本地文件加载持久的向量存储。然后输入一个循环,用户可以在其中输入查询。主函数将这些查询与持久化向量存储的检索器一起传递给query_pdf函数。循环将继续,直到用户输入“exit”。
def需要改写的内容是:main():需要改写的内容是:filename需要改写的内容是:=需要改写的内容是:input("Enter需要改写的内容是:the需要改写的内容是:name需要改写的内容是:of需要改写的内容是:the需要改写的内容是:document需要改写的内容是:(.pdf需要改写的内容是:or需要改写的内容是:.txt):\n")docs需要改写的内容是:=需要改写的内容是:load_document(filename)embeddings需要改写的内容是:=需要改写的内容是:OpenAIEmbeddings(openai_api_key=openai_api_key)vectorstore需要改写的内容是:=需要改写的内容是:FAISS.from_documents(docs,需要改写的内容是:embeddings)需要改写的内容是:vectorstore.save_local("faiss_index_constitution")persisted_vectorstore需要改写的内容是:=需要改写的内容是:FAISS.load_local("faiss_index_constitution",需要改写的内容是:embeddings)query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")while需要改写的内容是:query需要改写的内容是:!=需要改写的内容是:"exit":query_pdf(query,需要改写的内容是:persisted_vectorstore.as_retriever())query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")嵌入捕获词之间的语义关系。向量是一种可以表示一段文本的形式。
这段代码使用OpenAIEmbeddings生成的嵌入将文档中的文本数据转换成向量。然后使用FAISS对这些向量进行索引,以便高效地检索和比较相似的向量。这便于对上传的文档进行分析。
最后,如果用户独立运行程序,使用__name__需要改写的内容是:==需要改写的内容是:"__main__"构造函数来调用主函数:
if需要改写的内容是:__name__需要改写的内容是:==需要改写的内容是:"__main__":需要改写的内容是:main()
这个应用程序是一个命令行应用程序。作为一个扩展,您可以使用Streamlit为该应用程序添加Web界面。
执行文件分析
要执行文档分析,将所要分析的文档存储在项目所在的同一个文件夹中,然后运行该程序。它将询问所要分析的文档的名称。输入全名,然后输入查询,以便程序分析。
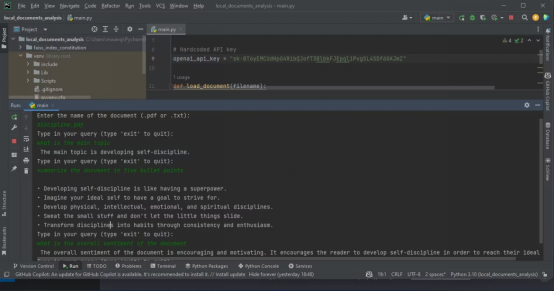
以下截图展示了对PDF进行分析的结果
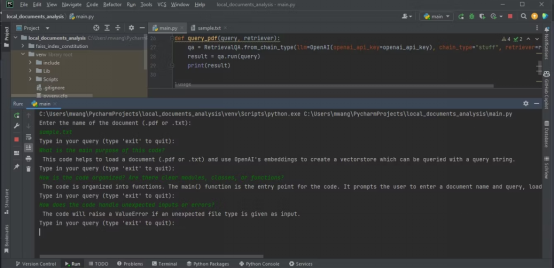
下面的输出显示了分析含有源代码的文本文件的结果。
确保所要分析的文件是PDF或文本格式。如果您的文档采用其他格式,可以使用在线工具将它们转换成PDF格式。
可以在GitHub代码库中获取完整的源代码:https://github.com/makeuseofcode/Document-analysis-using-LangChain-and-OpenAI
原文标题:How需要改写的内容是:to需要改写的内容是:Analyze需要改写的内容是:Documents需要改写的内容是:With需要改写的内容是:LangChain需要改写的内容是:and需要改写的内容是:the需要改写的内容是:OpenAI需要改写的内容是:API,作者:Denis需要改写的内容是:Kuria
需要改写的内容是:
以上是使用LangChain和OpenAI API进行文档分析的方法的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 编程新范式,当Spring Boot遇上OpenAI
Feb 01, 2024 pm 09:18 PM
编程新范式,当Spring Boot遇上OpenAI
Feb 01, 2024 pm 09:18 PM
2023年,AI技术已经成为热点话题,对各行业产生了巨大影响,编程领域尤其如此。人们越来越认识到AI技术的重要性,Spring社区也不例外。随着GenAI(GeneralArtificialIntelligence)技术的不断进步,简化具备AI功能的应用程序的创建变得至关重要和迫切。在这个背景下,"SpringAI"应运而生,旨在简化开发AI功能应用程序的过程,使其变得简单直观,避免不必要的复杂性。通过"SpringAI",开发者可以更轻松地构建具备AI功能的应用程序,将其变得更加易于使用和操作
 选择最适合数据的嵌入模型:OpenAI 和开源多语言嵌入的对比测试
Feb 26, 2024 pm 06:10 PM
选择最适合数据的嵌入模型:OpenAI 和开源多语言嵌入的对比测试
Feb 26, 2024 pm 06:10 PM
OpenAI最近宣布推出他们的最新一代嵌入模型embeddingv3,他们声称这是性能最出色的嵌入模型,具备更高的多语言性能。这一批模型被划分为两种类型:规模较小的text-embeddings-3-small和更为强大、体积较大的text-embeddings-3-large。这些模型的设计和训练方式的信息披露得很少,模型只能通过付费API访问。所以就出现了很多开源的嵌入模型但是这些开源的模型与OpenAI闭源模型相比如何呢?本文将对这些新模型与开源模型的性能进行实证比较。我们计划建立一个数据
 OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
如果AI模型给的答案一点也看不懂,你敢用吗?随着机器学习系统在更重要的领域得到应用,证明为什么我们可以信任它们的输出,并明确何时不应信任它们,变得越来越重要。获得对复杂系统输出结果信任的一个可行方法是,要求系统对其输出产生一种解释,这种解释对人类或另一个受信任的系统来说是可读的,即可以完全理解以至于任何可能的错误都可以被发现。例如,为了建立对司法系统的信任,我们要求法院提供清晰易读的书面意见,解释并支持其决策。对于大型语言模型来说,我们也可以采用类似的方法。不过,在采用这种方法时,确保语言模型生
 基于Rust的Zed编辑器已开源,内置对OpenAI和GitHub Copilot的支持
Feb 01, 2024 pm 02:51 PM
基于Rust的Zed编辑器已开源,内置对OpenAI和GitHub Copilot的支持
Feb 01, 2024 pm 02:51 PM
作者丨TimAnderson编译丨诺亚出品|51CTO技术栈(微信号:blog51cto)Zed编辑器项目目前仍处于预发布阶段,已在AGPL、GPL和Apache许可下开源。该编辑器以高性能和多种AI辅助选择为特色,但目前仅适用于Mac平台使用。内森·索博(NathanSobo)在一篇帖子中解释道,Zed项目在GitHub上的代码库中,编辑器部分采用了GPL许可,服务器端组件则使用了AGPL许可证,而GPUI(GPU加速用户界面)部分则采用了Apache2.0许可。GPUI是Zed团队开发的一款
 没等来OpenAI,等来了Open-Sora全面开源
Mar 18, 2024 pm 08:40 PM
没等来OpenAI,等来了Open-Sora全面开源
Mar 18, 2024 pm 08:40 PM
不久前OpenAISora以其惊人的视频生成效果迅速走红,在一众文生视频模型中突出重围,成为全球瞩目的焦点。继2周前推出成本直降46%的Sora训练推理复现流程后,Colossal-AI团队全面开源全球首个类Sora架构视频生成模型「Open-Sora1.0」,涵盖了整个训练流程,包括数据处理、所有训练细节和模型权重,携手全球AI热爱者共同推进视频创作的新纪元。先睹为快,我们先看一段由Colossal-AI团队发布的「Open-Sora1.0」模型生成的都市繁华掠影视频。Open-Sora1.0
 微软、OpenAI 计划 1 亿美元投向人形机器人!网友纷纷喊话马斯克
Feb 01, 2024 am 11:18 AM
微软、OpenAI 计划 1 亿美元投向人形机器人!网友纷纷喊话马斯克
Feb 01, 2024 am 11:18 AM
微软、OpenAI开年被曝预将大笔资金砸向一家人形机器人初创公司。其中,微软计划掏出9500万美元,OpenAI跟投500万美元。彭博社消息称,这家公司本轮预计共要融资5亿美元,投前估值或将达到19亿美元。是什么吸引了他们?不妨先来看一下这家公司的机器人成果。只见这个机器人通体银黑,外观酷似好莱坞科幻大片中的机器人形象:现在,他正在将一颗咖啡胶囊放进咖啡机里:如果没放正,还会自主调整,无需任何人为远程遥控:不过一会儿,一杯咖啡就可以端走享用:有木有家人们已经认出来了,没错,这款机器人就是前段时间
 本地运行性能超越 OpenAI Text-Embedding-Ada-002 的 Embedding 服务,太方便了!
Apr 15, 2024 am 09:01 AM
本地运行性能超越 OpenAI Text-Embedding-Ada-002 的 Embedding 服务,太方便了!
Apr 15, 2024 am 09:01 AM
Ollama是一款超级实用的工具,让你能够在本地轻松运行Llama2、Mistral、Gemma等开源模型。本文我将介绍如何使用Ollama实现对文本的向量化处理。如果你本地还没有安装Ollama,可以阅读这篇文章。本文我们将使用nomic-embed-text[2]模型。它是一种文本编码器,在短的上下文和长的上下文任务上,性能超越了OpenAItext-embedding-ada-002和text-embedding-3-small。启动nomic-embed-text服务当你已经成功安装好o
 突发!OpenAI开除Ilya盟友,理由:涉嫌信息泄漏
Apr 15, 2024 am 09:01 AM
突发!OpenAI开除Ilya盟友,理由:涉嫌信息泄漏
Apr 15, 2024 am 09:01 AM
突发!OpenAI开人了,理由:涉嫌信息泄露。一位是失踪的首席科学家Ilya盟友,超级对齐(Superalignment)团队核心成员LeopoldAschenbrenner。另一位也不简单,是LLM推理团队研究员PavelIzmailov,曾经也在超级对齐团队干过。目前尚不清楚这俩人到底泄露了啥信息。消息被曝出后,不少网友表示“挺震惊”:不久前我还看过Aschenbrenner的帖子,感觉他正处于事业上升期,没想到会有这样的转变。图片还有网友认为:OpenAI失去Aschenbrenner,I
