

横扫13个视觉语言任务!哈工深发布多模态大模型「九天」,性能直升5%

为了应对多模态大语言模型中视觉信息提取不充分的问题,哈尔滨工业大学(深圳)的研究人员提出了双层知识增强的多模态大语言模型-九天(JiuTian-LION)。

需要重新写的内容是:论文链接:https://arxiv.org/abs/2311.11860
GitHub: https://github.com/rshaojimmy/JiuTian
项目主页: https://rshaojimmy.github.io/Projects/JiuTian-LION
与现有的工作相比,九天首次分析了图像级理解任务和区域级定位任务之间的内部冲突,提出了分段指令微调策略和混合适配器来实现两种任务的互相提升。
通过注入细粒度空间感知和高层语义视觉知识,九天实现了在包括图像描述、视觉问题、和视觉定位等17个视觉语言任务上显着的性能提升( 比如Visual Spatial Reasoning 上高达5%的性能提升),在其中13个评测任务上达到了国际领先水平,性能对比如图1所示。
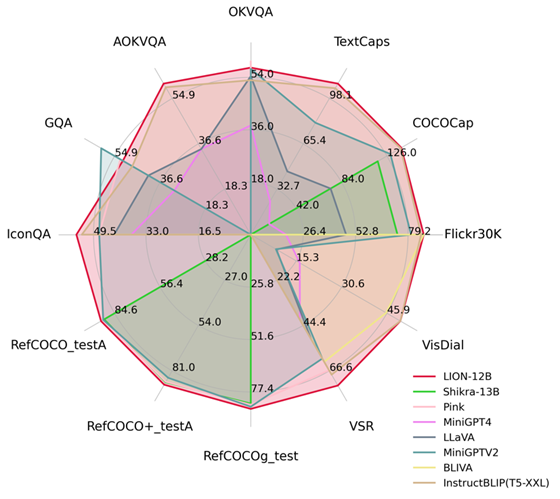
图1:对比其他MLLMs,九天在大部分任务上都取得了最优的性能。
九天JiuTian-LION
通过赋予大型语言模型(LLMs)多模态感知能力,一些工作开始生成多模态大语言模型(MLLMs),并在许多视觉语言任务上取得了突破性进展。然而,现有的MLLMs主要采用图文对预训练得到的视觉编码器,如CLIP-ViT
这些视觉编码器的主要任务是学习图像层面的粗粒度图像文本模态对齐,但是它们缺乏全面的视觉感知和信息抽取能力,无法进行细粒度的视觉理解
在很大程度上,这种视觉信息提取不足和理解程度不够的问题会导致MLLMs存在视觉定位偏差、空间推理不足和物体幻觉等多个缺陷,如图2所示
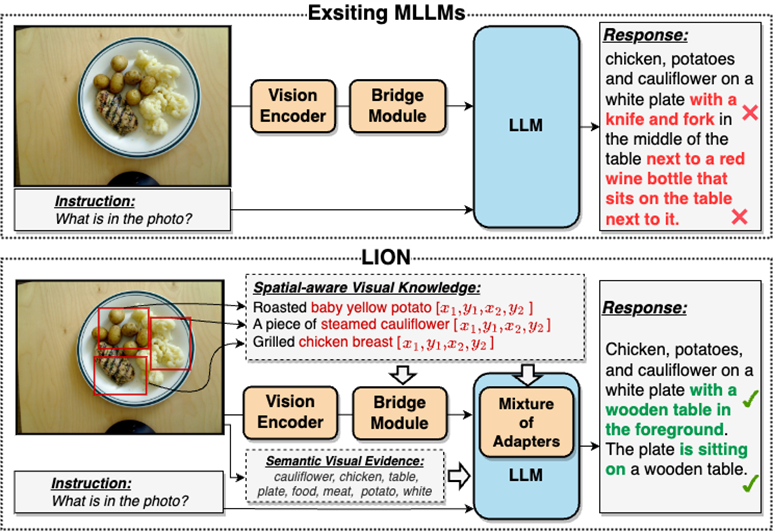
请参考图2:九天(JiuTian-LION)是一种采用双层视觉知识增强的多模态大语言模型
九天相较于现有的多模态大语言模型(MLLMs),通过注入细粒度空间感知视觉知识和高层语义视觉证据,有效地提升了MLLMs的视觉理解能力,生成更准确的文本回应,减少了MLLMs的幻觉现象
双层视觉知识增强的多模态大语言模型-九天(JiuTian-LION)
为了解决MLLMs在视觉信息提取和理解方面存在的不足,研究人员提出了一种双层视觉知识增强的MLLMs方法,被称为九天(JiuTian-LION)。具体的方法框架如图3所示
该方法主要从两方面增强MLLMs,渐进式融合细粒度空间感知视觉知识(Progressive Incorporation of Fine-grained Spatial-aware Visual knowledge)和软提示下的高层语义视觉证据(Soft Prompting of High-level Semantic Visual Evidence)。
具体来说,研究人员提出了一种分段指令微调策略,以解决图像级理解任务和区域级定位任务之间的内部冲突。他们逐步将细粒度的空间感知知识注入到MLLMs中。同时,他们将图像标签作为高层语义视觉证据加入MLLMs,并使用软提示方法来减轻不正确标签可能带来的负面影响
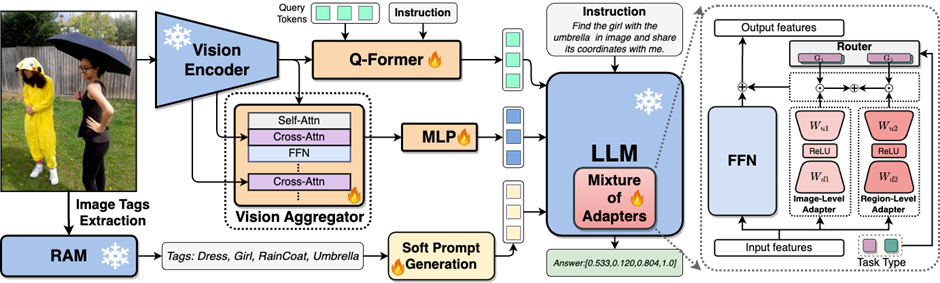
九天(JiuTian-LION)模型框架图如下所示:
该工作通过分段式训练策略先分别基于Q-Former 和 Vision Aggregator – MLP 两个分支学习图像级理解和区域级定位任务,然后在最后训练阶段利用具有路由机制的混合适配器来动态融合不同分支的知识提升模型在两种任务的表现。
该工作还通过RAM提取图像标签作为高层语义视觉证据,然后提出软提示方法来提高高层语义注入的效果
渐进式融合细粒度空间感知视觉知识
当直接将图像级理解任务(包括图像描述和视觉问答)与区域级定位任务(包括指示表达理解,指示表达生成等)进行单阶段混合训练时,MLLMs 会遭遇两种任务之间存在的内部冲突,从而不能在所有任务上取得较好的综合性能。
研究人员认为这种内部冲突主要由两个问题引起。第一个问题是缺少区域级的模态对齐预训练,当前具有区域级定位能力的 MLLMs 大多先使用大量相关数据进行预训练,不然很难在有限地训练资源下让基于图像级模态对齐的视觉特征适应区域级任务。
另一个问题是图像级理解任务和区域级定位任务之间的输入输出模式差异,后者需要模型额外理解关于物体坐标的特定短句(以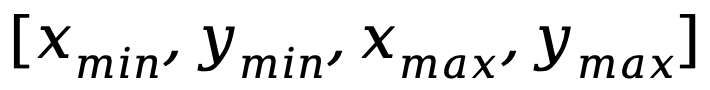 的形式)。为了解决以上问题,研究人员提出了分段式指令微调策略,以及具有路由机制的混合适配器。
的形式)。为了解决以上问题,研究人员提出了分段式指令微调策略,以及具有路由机制的混合适配器。
如图4所示,研究人员将单阶段指令微调过程拆分为三阶段:
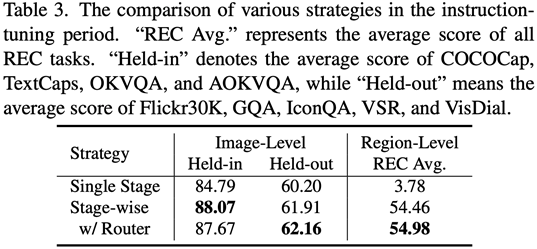
使用ViT、Q-Former和图像级适配器学习全局视觉知识的图像级理解任务;使用Vision Aggregator、MLP和区域级适配器学习细粒度空间感知视觉知识的区域级定位任务;提出了具有路由机制的混合适配器,动态融合不同分支中学习到的不同粒度的视觉知识。表3显示了分段式指令微调策略相对于单阶段训练的性能优势
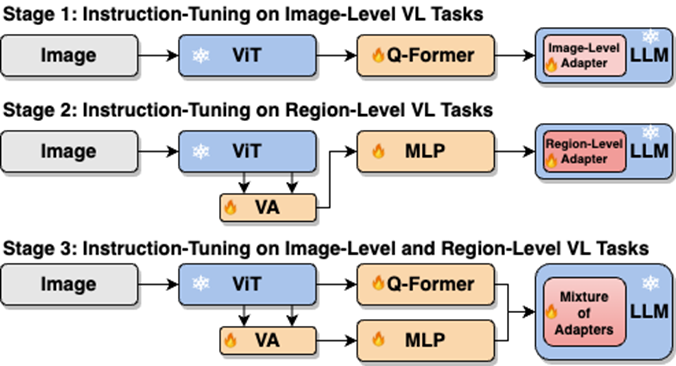
图4:分段式指令微调策略
对于注入软提示下的高层语义视觉证据,需要进行重写处理
研究人员提出使用图像标签作为高层语义视觉证据的有效补充,以进一步增强MLLMs的全局视觉感知理解能力
具体来说,首先通过 RAM 提取图像的标签,然后利用特定的指令模版“According to
配合模版中特定短语“use or partially use”,软提示向量可以指导模型减轻不正确标签带来的潜在负面影响。
实验结果
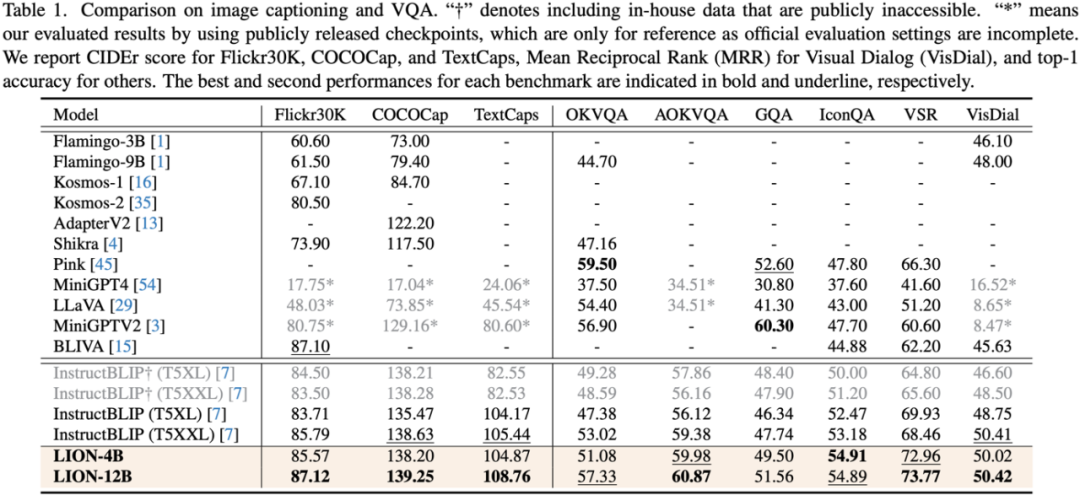
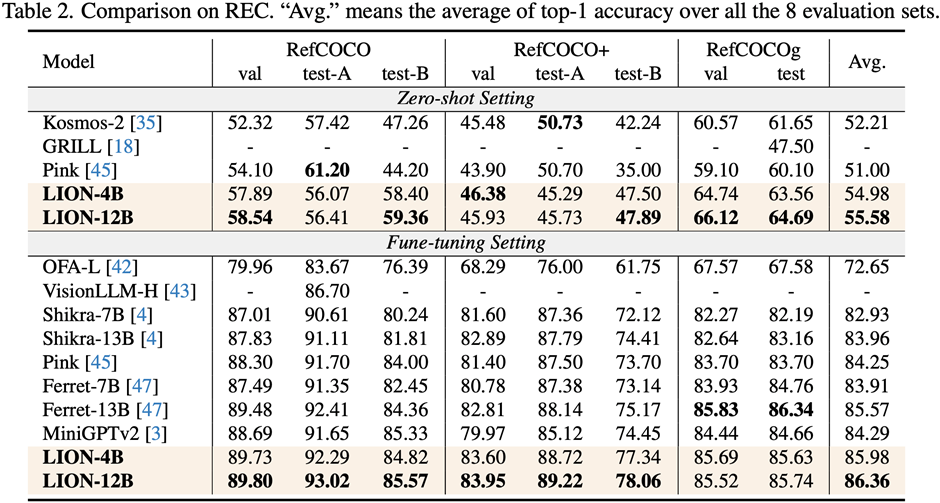
研究人员在包括图像描述(image captioning)、视觉问答(VQA)、和指示表达理解(REC)等17个任务基准集上进行了评测。
实验结果表明,九天在13个评测集上达到了国际领先水平。特别的,相比较 InstructBLIP 和 Shikra,九天分别在图像级理解任务和区域级定位任务上取得了全面且一致的性能提升,在 Visual Spatial Reasoning (VSR) 任务上可达到最高5%的提升幅度。
从图5可以看出,在不同的视觉语言多模态任务中,九天和其他MLLMs的能力存在差异,表明九天在细粒度视觉理解和视觉空间推理能力方面表现更优秀,并且能够输出具有更少幻觉的文本回应

重写的内容是:第五张图展示了对九天大模型、InstructBLIP和Shikra的能力差异进行的定性分析
图6通过样本分析,表明了九天模型在图像级和区域级视觉语言任务上都具有优秀的理解和识别能力。

第六张图:通过更多例子的分析,从图像和区域级视觉理解的角度展示了九天大模型的能力
总结
(1)该工作提出了一个新的多模态大语言模型-九天:通过双层视觉知识增强的多模态大语言模型。
(2)该工作在包括图像描述、视觉问答和指示表达理解等17个视觉语言任务基准集上进行评测,其中13个评测集达到了当前最好的性能。
(3)这项工作提出了一种分段式指令微调策略,以解决图像级理解和区域级定位任务之间的内部冲突,并实现了两种任务之间的相互提升
(4)该工作成功将图像级理解和区域级定位任务进行整合,多层次全面理解视觉场景,未来可以将这种全面的视觉理解能力应用到具身智能场景,帮助机器人更好、更全面地识别和理解当前环境,做出有效决策。
以上是横扫13个视觉语言任务!哈工深发布多模态大模型「九天」,性能直升5%的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 比特币值多少美金
Apr 28, 2025 pm 07:42 PM
比特币值多少美金
Apr 28, 2025 pm 07:42 PM
比特币的价格在20,000到30,000美元之间。1. 比特币自2009年以来价格波动剧烈,2017年达到近20,000美元,2021年达到近60,000美元。2. 价格受市场需求、供应量、宏观经济环境等因素影响。3. 通过交易所、移动应用和网站可获取实时价格。4. 比特币价格波动性大,受市场情绪和外部因素驱动。5. 与传统金融市场有一定关系,受全球股市、美元强弱等影响。6. 长期趋势看涨,但需谨慎评估风险。
 全球币圈十大交易所有哪些 排名前十的货币交易平台2025
Apr 28, 2025 pm 08:12 PM
全球币圈十大交易所有哪些 排名前十的货币交易平台2025
Apr 28, 2025 pm 08:12 PM
2025年全球十大加密货币交易所包括Binance、OKX、Gate.io、Coinbase、Kraken、Huobi、Bitfinex、KuCoin、Bittrex和Poloniex,均以高交易量和安全性着称。
 排名靠前的货币交易平台有哪些 最新虚拟币交易所排名榜前10
Apr 28, 2025 pm 08:06 PM
排名靠前的货币交易平台有哪些 最新虚拟币交易所排名榜前10
Apr 28, 2025 pm 08:06 PM
目前排名前十的虚拟币交易所:1.币安,2. OKX,3. Gate.io,4。币库,5。海妖,6。火币全球站,7.拜比特,8.库币,9.比特币,10。比特戳。
 解密Gate.io战略升级:MeMebox 2.0如何重新定义加密资产管理?
Apr 28, 2025 pm 03:33 PM
解密Gate.io战略升级:MeMebox 2.0如何重新定义加密资产管理?
Apr 28, 2025 pm 03:33 PM
MeMebox 2.0通过创新架构和性能突破重新定义了加密资产管理。1) 它解决了资产孤岛、收益衰减和安全与便利悖论三大痛点。2) 通过智能资产枢纽、动态风险管理和收益增强引擎,提升了跨链转账速度、平均收益率和安全事件响应速度。3) 为用户提供资产可视化、策略自动化和治理一体化,实现了用户价值重构。4) 通过生态协同和合规化创新,增强了平台的整体效能。5) 未来将推出智能合约保险池、预测市场集成和AI驱动资产配置,继续引领行业发展。
 排名前十的虚拟币交易app有哪 最新数字货币交易所排行榜
Apr 28, 2025 pm 08:03 PM
排名前十的虚拟币交易app有哪 最新数字货币交易所排行榜
Apr 28, 2025 pm 08:03 PM
Binance、OKX、gate.io等十大数字货币交易所完善系统、高效多元化交易和严密安全措施严重推崇。
 全球币圈十大交易所有哪些 排名前十的货币交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球币圈十大交易所有哪些 排名前十的货币交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球十大加密货币交易平台包括Binance、OKX、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、KuCoin和Poloniex,均提供多种交易方式和强大的安全措施。
 靠谱的数字货币交易平台推荐 全球十大数字货币交易所排行榜2025
Apr 28, 2025 pm 04:30 PM
靠谱的数字货币交易平台推荐 全球十大数字货币交易所排行榜2025
Apr 28, 2025 pm 04:30 PM
靠谱的数字货币交易平台推荐:1. OKX,2. Binance,3. Coinbase,4. Kraken,5. Huobi,6. KuCoin,7. Bitfinex,8. Gemini,9. Bitstamp,10. Poloniex,这些平台均以其安全性、用户体验和多样化的功能着称,适合不同层次的用户进行数字货币交易

