

英伟达打脸AMD:H100在软件加持下,AI性能比MI300X快47%!


12月14日消息,AMD于本月初推出了其最强的AI芯片Instinct MI300X,其8-GPU服务器的AI性能比英伟达H100 8-GPU高出了60%。对此,英伟达于近日发布了一组最新的H100与MI300X的性能对比数据,展示了H100如何使用正确的软件提供比MI300X更快的AI性能。
根据AMD此前公布的数据显示,MI300X的FP8/FP16性能都达到了英伟达(NVIDIA)H100的1.3倍,运行Llama 2 70B和FlashAttention 2 模型的速度比H100均快了20%。在8v8 服务器中,运行Llama 2 70B模型,MI300X比H100快了40%;运行Bloom 176B模型,MI300X比H100快了60%。
但是,需要指出的是,AMD在将MI300X 与 英伟达H100 进行比较时,AMD使用了最新的 ROCm 6.0 套件中的优化库(可支持最新的计算格式,例如 FP16、Bf16 和 FP8,包括 Sparsity等),才得到了这些数字。相比之下,对于英伟达H100则并未没有使用英伟达的 TensorRT-LLM 等优化软件加持情况下进行测试。
AMD对英伟达H100测试的隐含声明显示,使用vLLM v.02.2.2推理软件和英伟达DGX H100系统,Llama 2 70B查询的输入序列长度为2048,输出序列长度为128
英伟达最新发布的对于DGX H100(带有8个NVIDIA H100 Tensor Core GPU,带有80 GB HBM3)的测试结果显示,使用了公开的NVIDIA TensorRT LLM软件,其中v0.5.0用于Batch-1测试,v0.6.1用于延迟阈值测量。测试的工作量详细信息与之前进行的AMD测试相同
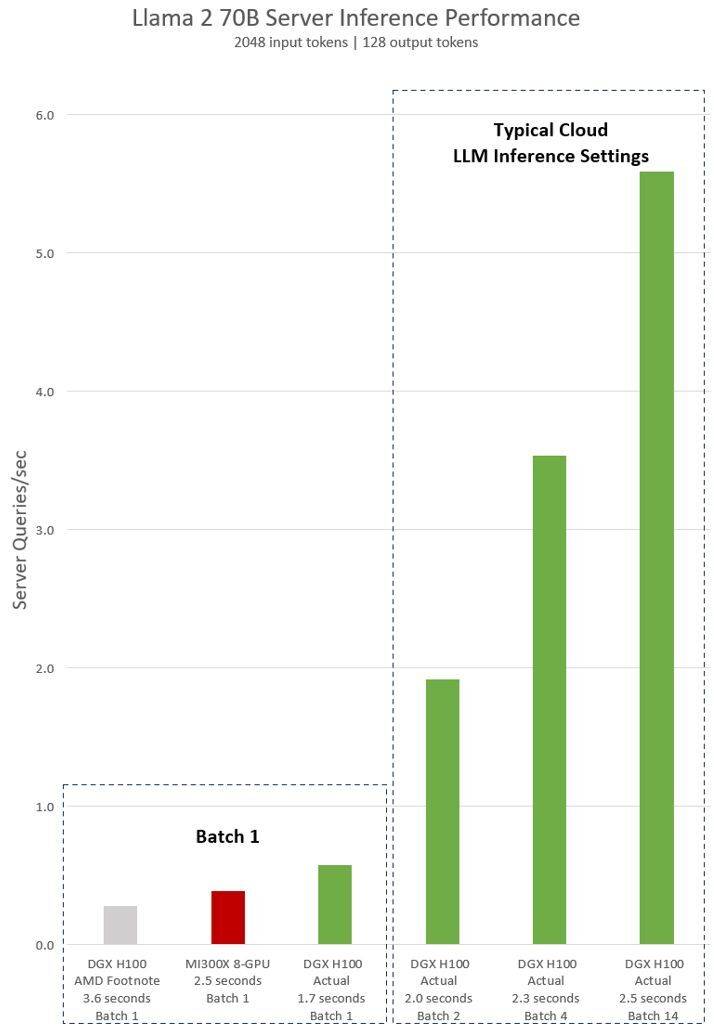
根据结果显示,英伟达DGX H100服务器在使用优化的软件后,其性能提高了超过2倍,比AMD展示的MI300X 8-GPU服务器快了47%
DGX H100 在1.7秒内可以处理单个推理任务。为了优化响应时间和数据中心的吞吐量,云服务为特定的服务设置了固定的响应时间。这样他们可以将多个推理请求组合成更大的“Batch”,从而增加服务器每秒的总体推理次数。MLPerf 等行业标准基准测试也使用这个固定的响应时间指标来衡量性能
响应时间的微小权衡可能会导致服务器可以实时处理的推理请求数量产生不确定因素。使用固定的 2.5 秒响应时间预算,英伟达DGX H100 服务器每秒可以处理超过 5 个 Llama 2 70B 推理,而Batch-1每秒处理不到一个。
显然,英伟达使用这些新的基准测试是相对公平的,毕竟AMD也使用其优化的软件来评估其GPU的性能,所以为什么不在测试英伟达H100时也这样做呢?
要知道英伟达的软件堆栈围绕CUDA生态系统,经过多年的努力和开发,在人工智能市场拥有非常强大的地位,而AMD的ROCm 6.0是新的,尚未在现实场景中进行测试。
根据AMD之前透露的信息显示,其已经与微软、Meta等大公司达成了很大一部分交易,这些公司将其MI300X GPU视为英伟达H100解决方案的替代品。
AMD最新的Instinct MI300X预计将在2024年上半年大量出货,但是,届时英伟达更强的H200 GPU也将出货,2024下半年英伟达还将推出新一代的Blackwell B100。另外,英特尔也将会推出其新一代的AI芯片Gaudi 3。接下来,人工智能领域的竞争似乎会变得更加激烈。
编辑:芯智讯-浪客剑
以上是英伟达打脸AMD:H100在软件加持下,AI性能比MI300X快47%!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 华硕推出 Adol Book 14 Air,搭载 AMD Ryzen 9 8945H 和好奇的香炉
Aug 01, 2024 am 11:12 AM
华硕推出 Adol Book 14 Air,搭载 AMD Ryzen 9 8945H 和好奇的香炉
Aug 01, 2024 am 11:12 AM
华硕已经提供了多款 14 英寸笔记本电脑,包括 Zenbook 14 OLED(亚马逊售价 1,079.99 美元)。现在,它决定推出 Adol Book 14 Air,从表面上看它就像一台典型的 14 英寸笔记本电脑。然而,一个不起眼的元
 OneXGPU 2 中的 AMD Radeon RX 7800M 性能优于 Nvidia RTX 4070 笔记本电脑 GPU
Sep 09, 2024 am 06:35 AM
OneXGPU 2 中的 AMD Radeon RX 7800M 性能优于 Nvidia RTX 4070 笔记本电脑 GPU
Sep 09, 2024 am 06:35 AM
OneXGPU 2 是首款搭载 Radeon RX 7800M 的 eGPU,而 AMD 尚未宣布推出这款 GPU。据外置显卡方案制造商One-Netbook透露,AMD新GPU基于RDNA 3架构,拥有Navi
 Ryzen AI 软件获得对新 Strix Halo 和 Kraken Point AMD Ryzen 处理器的支持
Aug 01, 2024 am 06:39 AM
Ryzen AI 软件获得对新 Strix Halo 和 Kraken Point AMD Ryzen 处理器的支持
Aug 01, 2024 am 06:39 AM
AMD Strix Point 笔记本电脑刚刚上市,下一代 Strix Halo 处理器预计将于明年某个时候发布。不过,该公司已经在其 Ryzen AI 软件中添加了对 Strix Halo 和 Krackan Point APU 的支持。
 适用于手持游戏机的 AMD Z2 Extreme 芯片预计将于 2025 年初推出
Sep 07, 2024 am 06:38 AM
适用于手持游戏机的 AMD Z2 Extreme 芯片预计将于 2025 年初推出
Sep 07, 2024 am 06:38 AM
尽管 AMD 为手持游戏机量身定制了 Ryzen Z1 Extreme(及其非 Extreme 变体),但该芯片只出现在两款主流手持设备中:华硕 ROG Ally(亚马逊售价 569 美元)和联想 Legion Go(三款)。如果你算一下R
 AMD 公布'Sinkclose”高危漏洞,数百万锐龙和 EPYC 处理器受影响
Aug 10, 2024 pm 10:31 PM
AMD 公布'Sinkclose”高危漏洞,数百万锐龙和 EPYC 处理器受影响
Aug 10, 2024 pm 10:31 PM
本站8月10日消息,AMD官方确认,部分EPYC和Ryzen处理器存在一个名为“Sinkclose”的新漏洞,代码为“CVE-2023-31315”,可能涉及全球数百万AMD用户。那么,什么是Sinkclose呢?根据WIRED的一份报告,该漏洞允许入侵者在“系统管理模式(SMM)”中运行恶意代码。据称,入侵者可以使用一种名为bootkit的恶意软件控制对方系统,而这种恶意软件无法被杀毒软件检测到。本站注:系统管理模式(SMM)是一种特殊的CPU工作模式,旨在实现高级电源管理和操作系统独立功能,
 传言首款搭载 Ryzen AI 9 HX 370 的 Minisforum 迷你电脑将以高价推出
Sep 29, 2024 am 06:05 AM
传言首款搭载 Ryzen AI 9 HX 370 的 Minisforum 迷你电脑将以高价推出
Sep 29, 2024 am 06:05 AM
Aoostar 是最早推出 Strix Point 迷你电脑的公司之一,随后 Beelink 推出了 SER9,起价高达 999 美元。 Minisforum 通过调侃 EliteMini AI370 加入了聚会,顾名思义,它将是该公司的
 交易 |配备 120Hz OLED、64GB RAM 和 AMD Ryzen 7 Pro 的 Lenovo ThinkPad P14s Gen 5 现在有 60% 折扣
Sep 07, 2024 am 06:31 AM
交易 |配备 120Hz OLED、64GB RAM 和 AMD Ryzen 7 Pro 的 Lenovo ThinkPad P14s Gen 5 现在有 60% 折扣
Sep 07, 2024 am 06:31 AM
这些天许多学生都回到了学校,有些人可能会注意到他们的旧笔记本电脑不再能胜任这项任务。一些大学生甚至可能正在市场上购买一款配备华丽 OLED 屏幕的高端商务笔记本电脑,在这种情况下
 Beelink SER9:紧凑型 AMD Zen 5 迷你 PC 宣布配备 Radeon 890M iGPU,但 eGPU 选项有限
Sep 12, 2024 pm 12:16 PM
Beelink SER9:紧凑型 AMD Zen 5 迷你 PC 宣布配备 Radeon 890M iGPU,但 eGPU 选项有限
Sep 12, 2024 pm 12:16 PM
Beelink 继续以惊人的速度推出新的迷你电脑和随附配件。回顾一下,自发布 EQi12、EQR6 和 EX eGPU 扩展坞以来,已经过去了一个多月的时间。现在,该公司已将注意力转向AMD的新Strix
