

对Gemini进行全面评估:从CMU到GPT 3.5 Turbo,Gemini Pro失利

谷歌的 Gemini 到底有多重?和 OpenAI 的 GPT 模型相比如何表现?CMU 这篇论文对此有清楚的测量结果
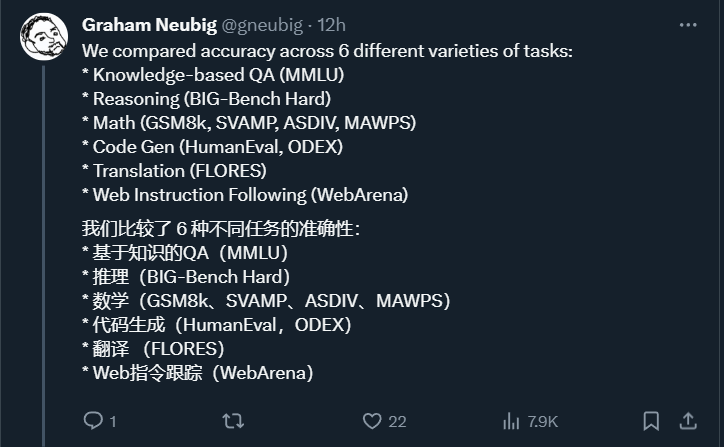
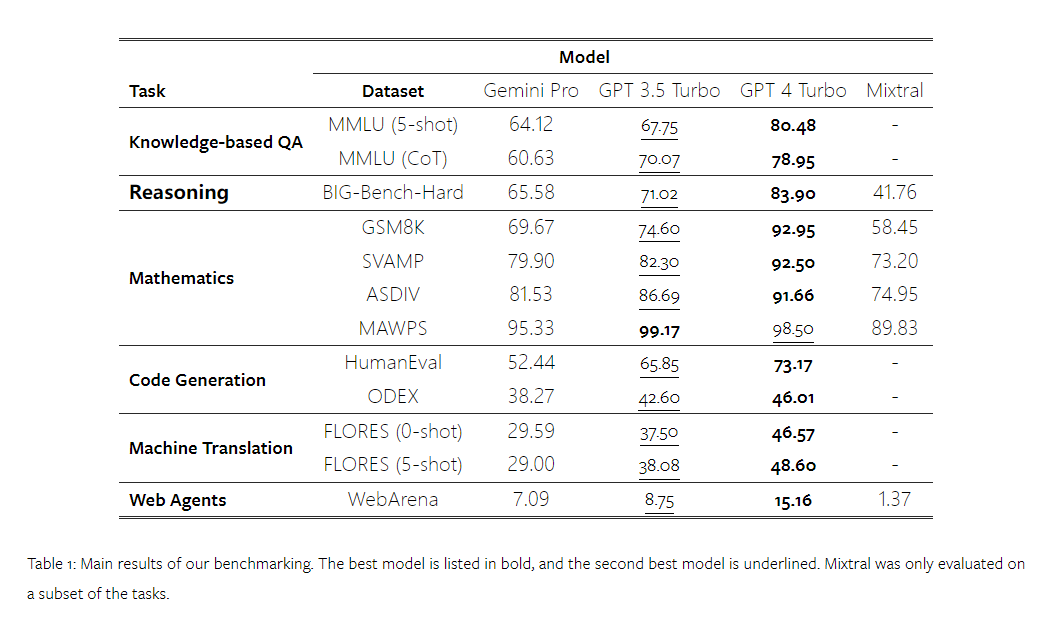

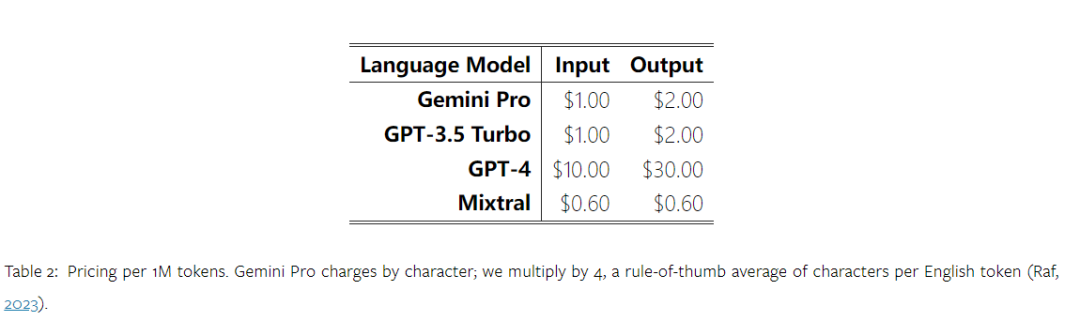
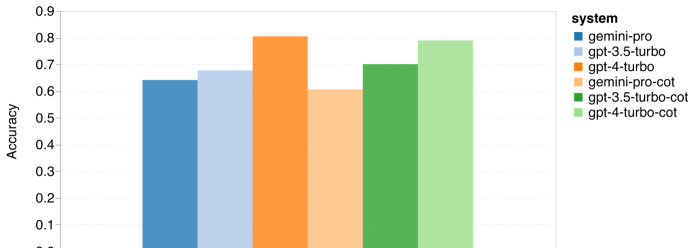
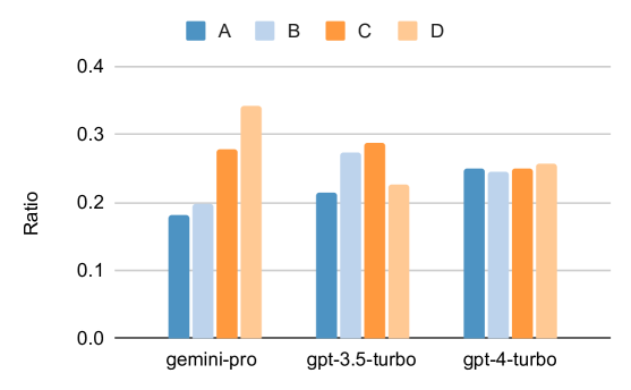
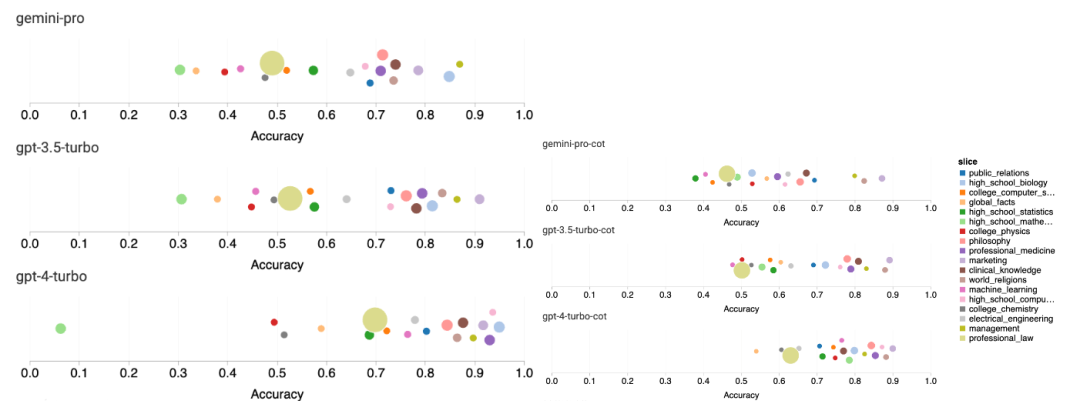
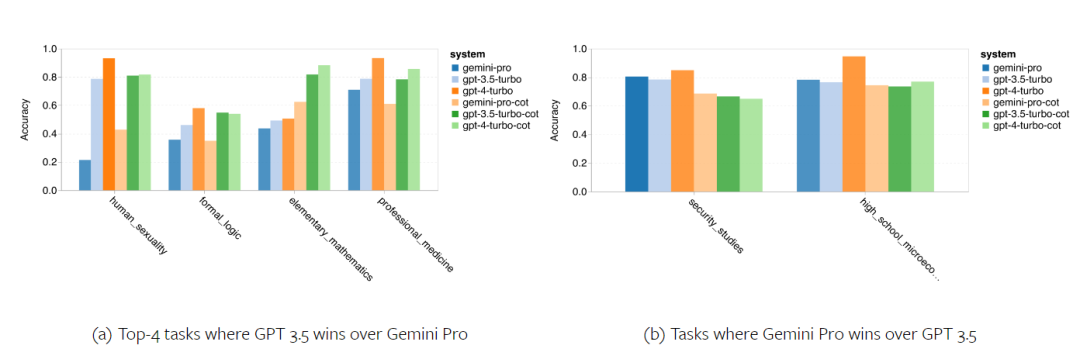
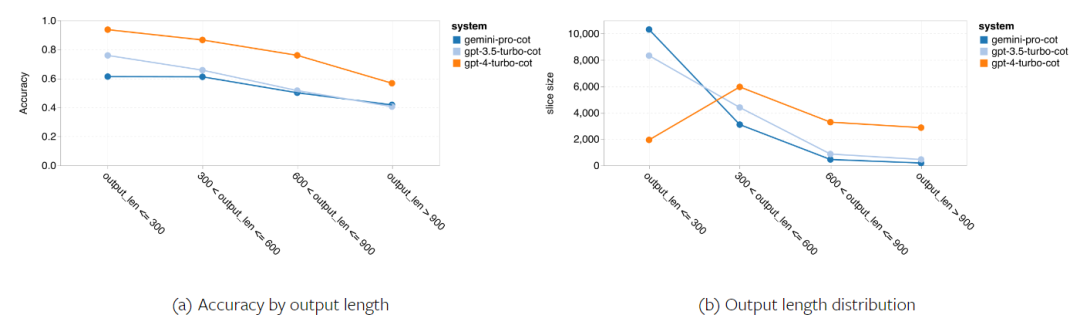
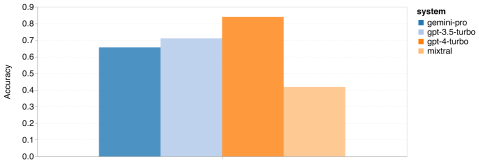
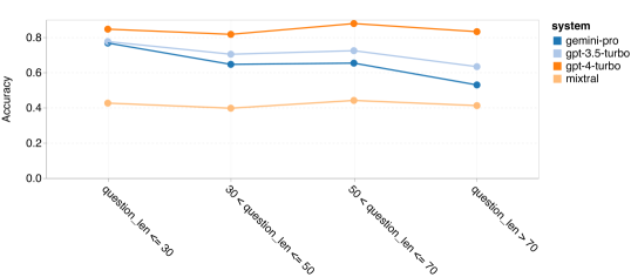
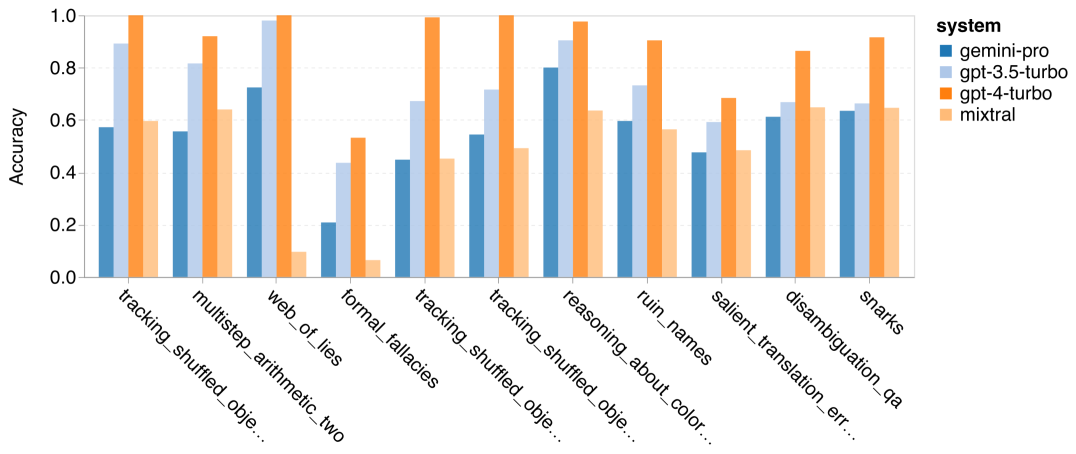
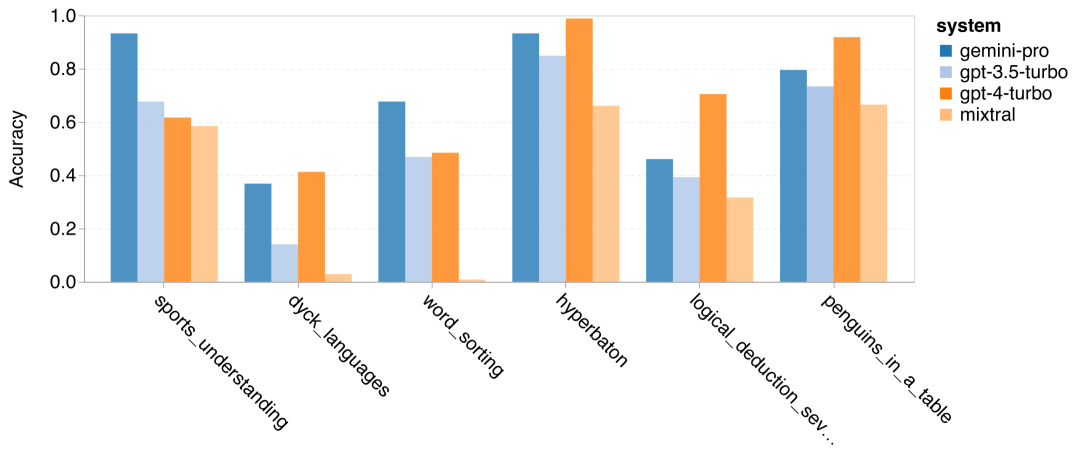
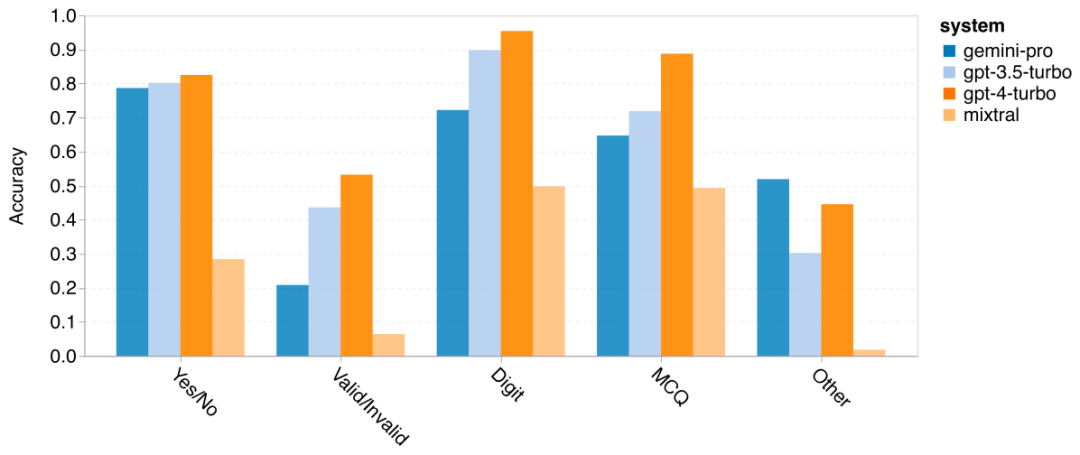
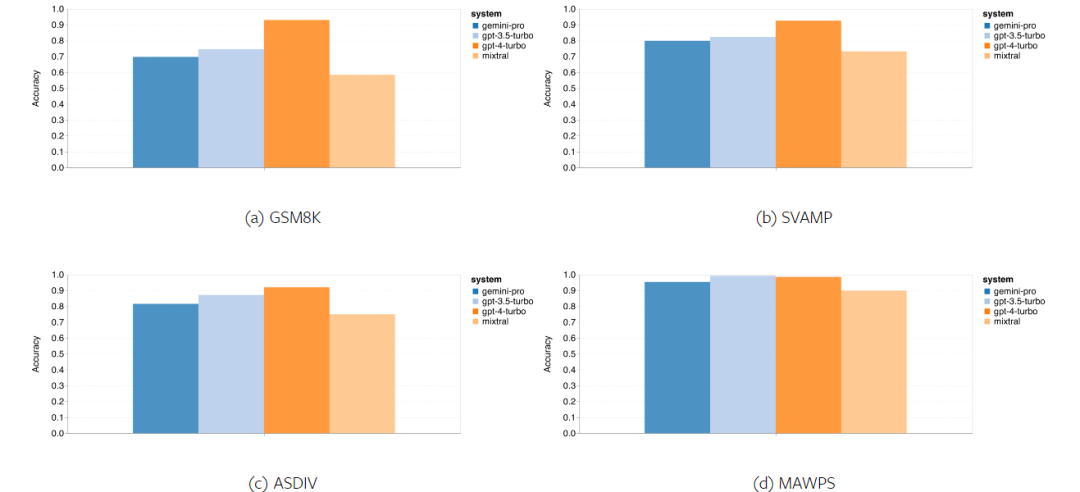
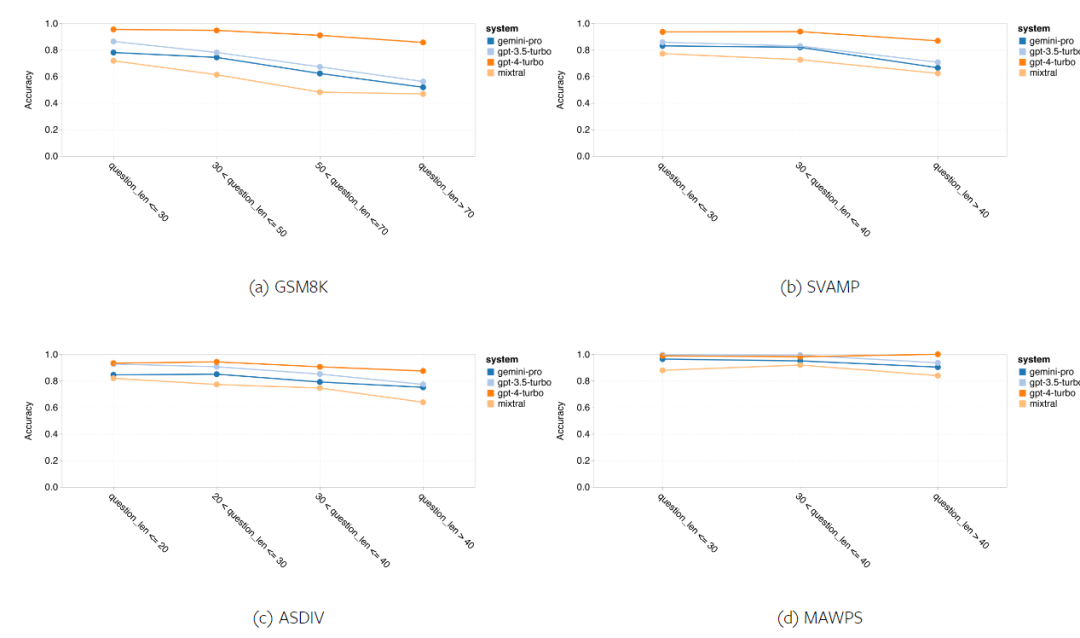
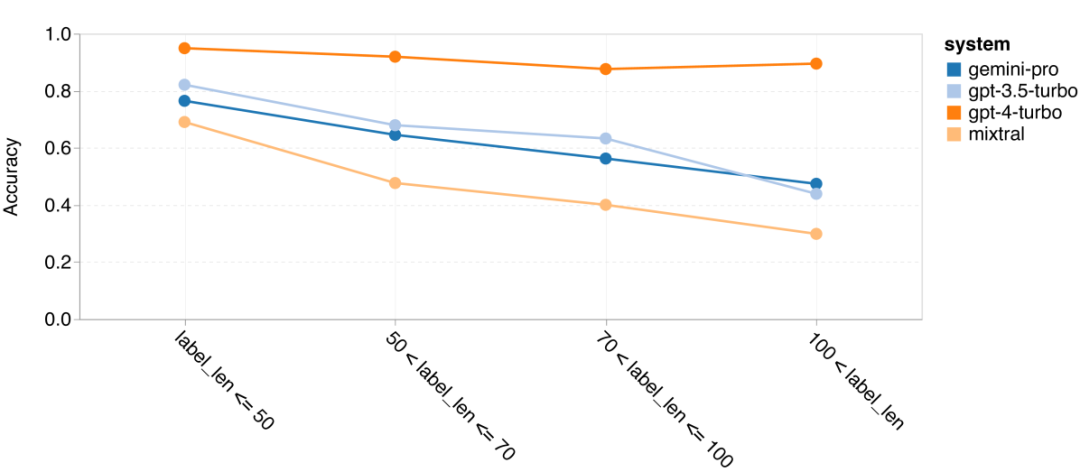
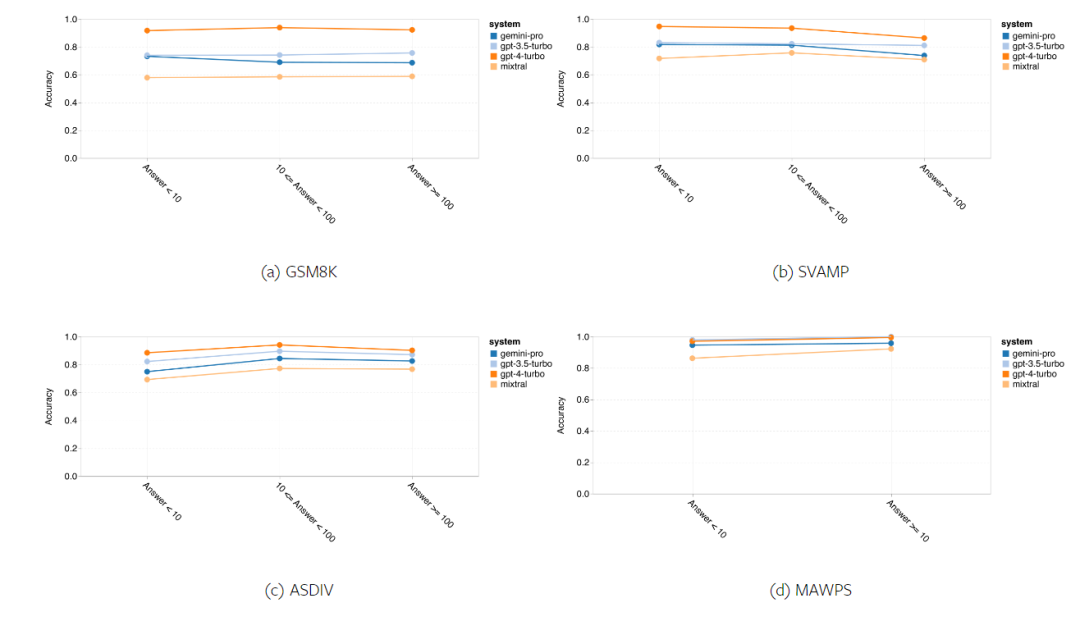
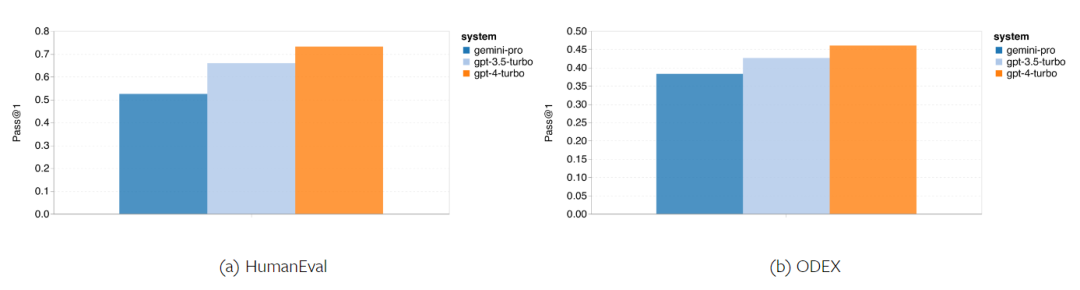
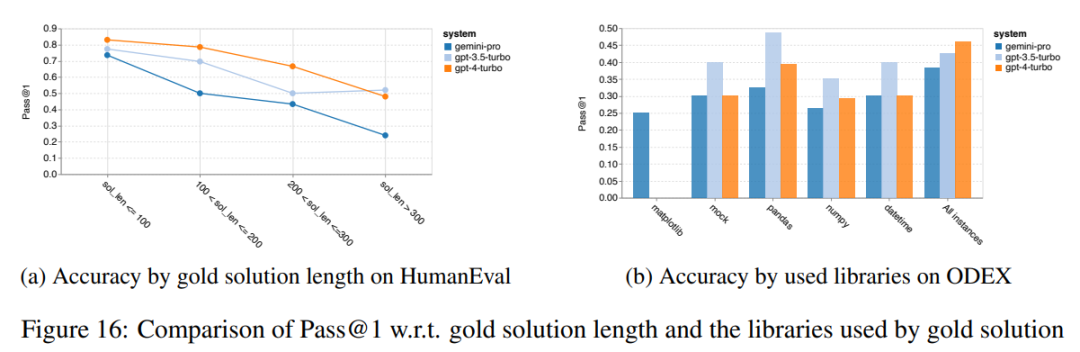
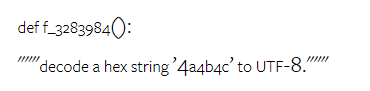
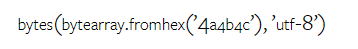
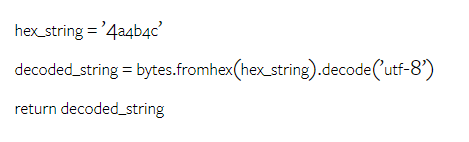


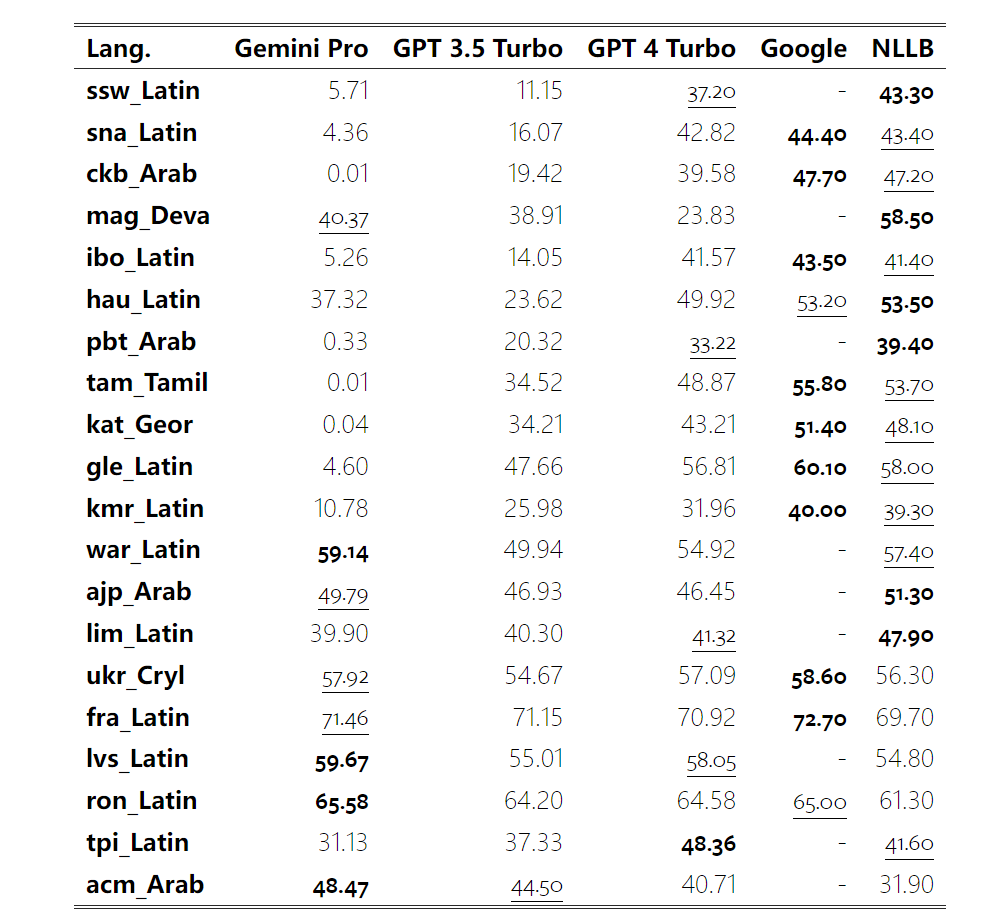
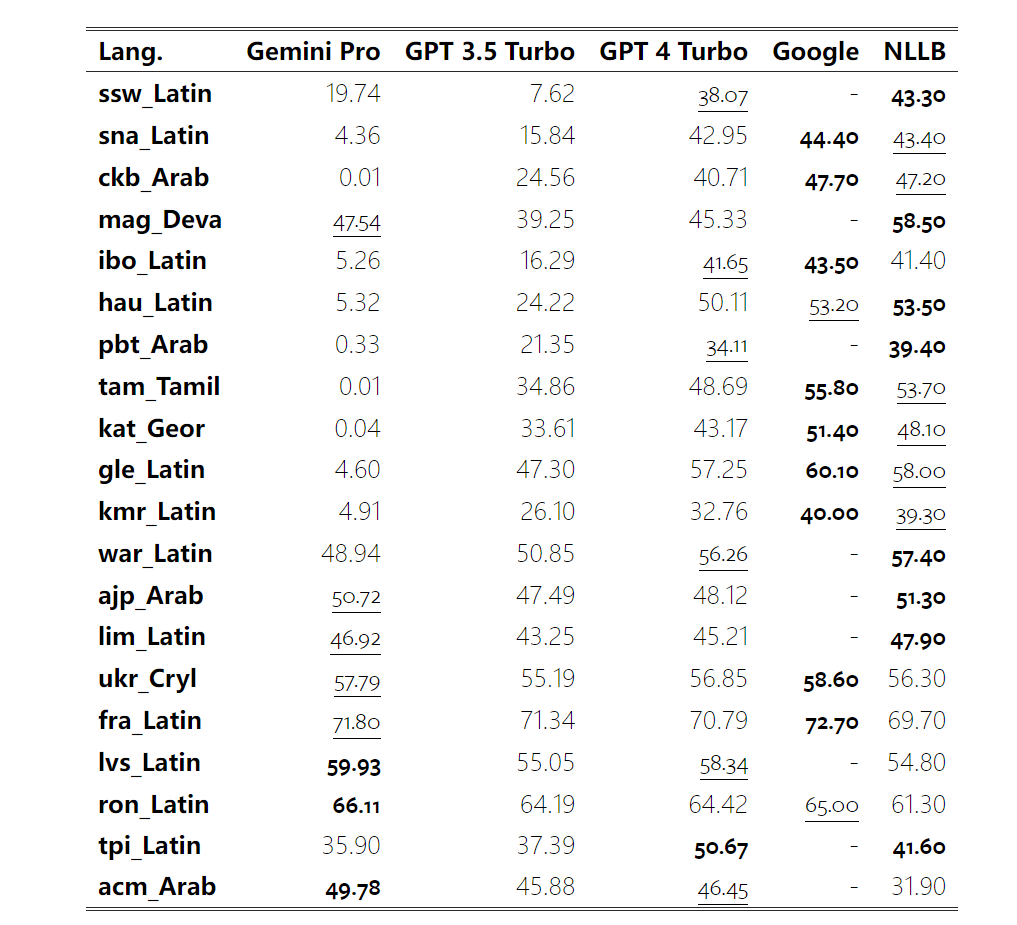
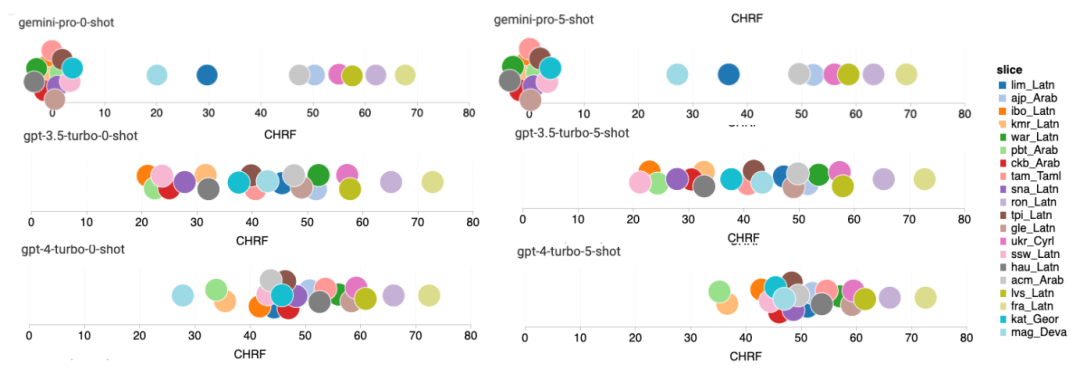
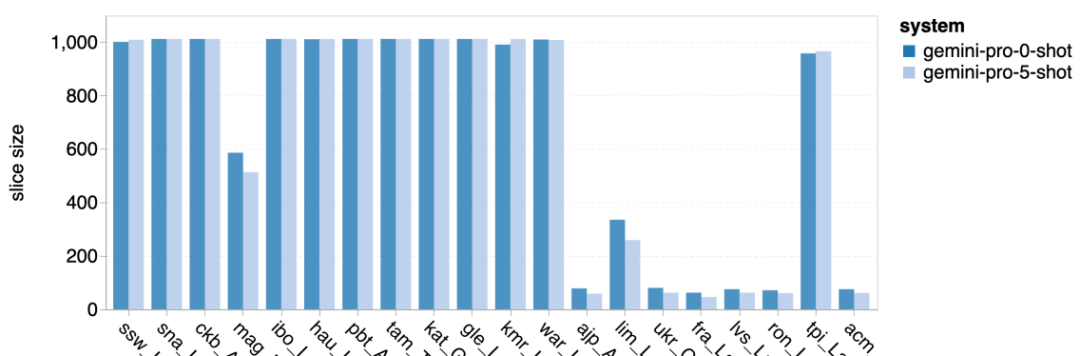
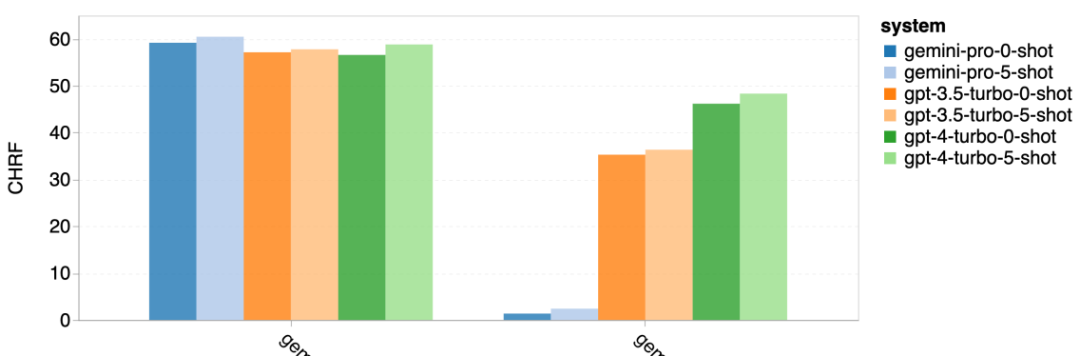
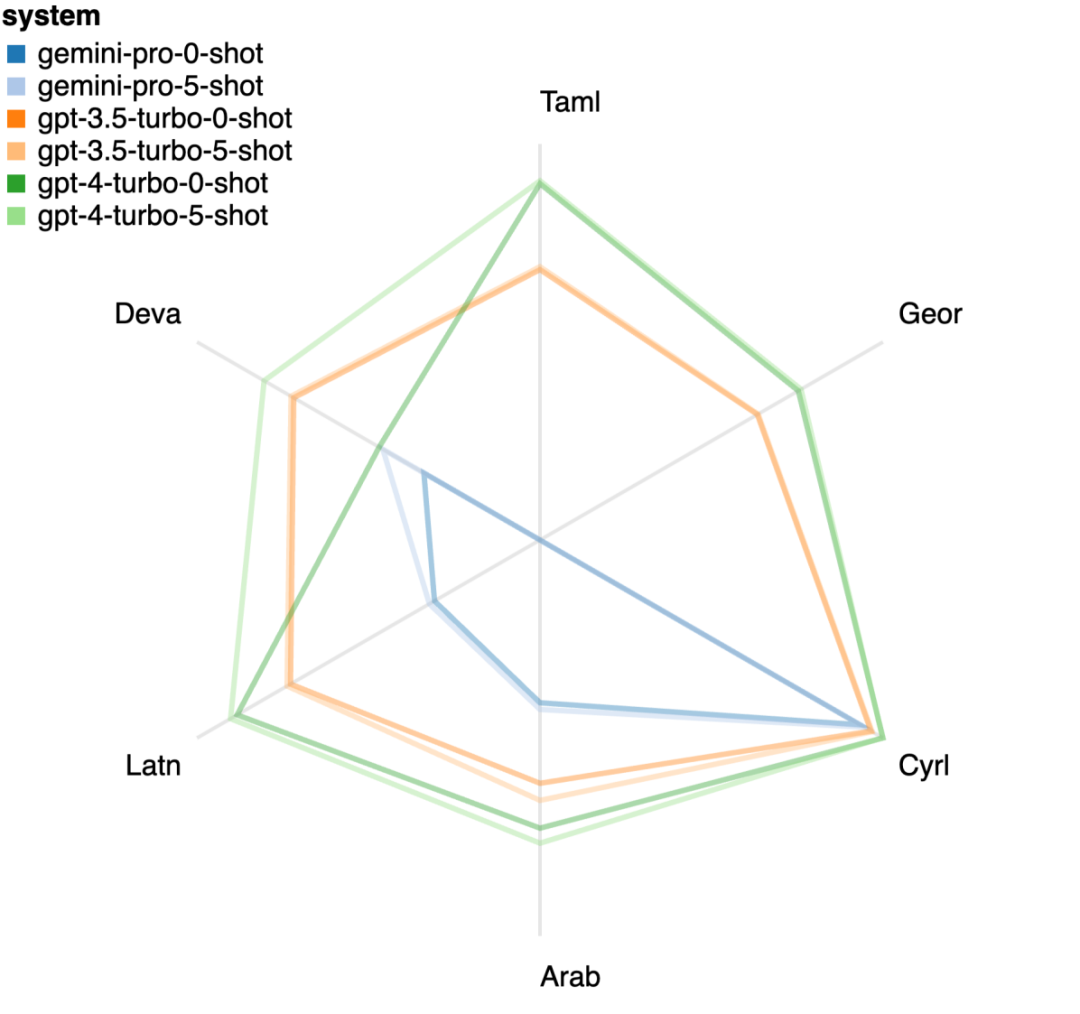
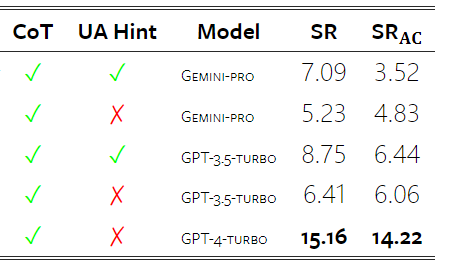
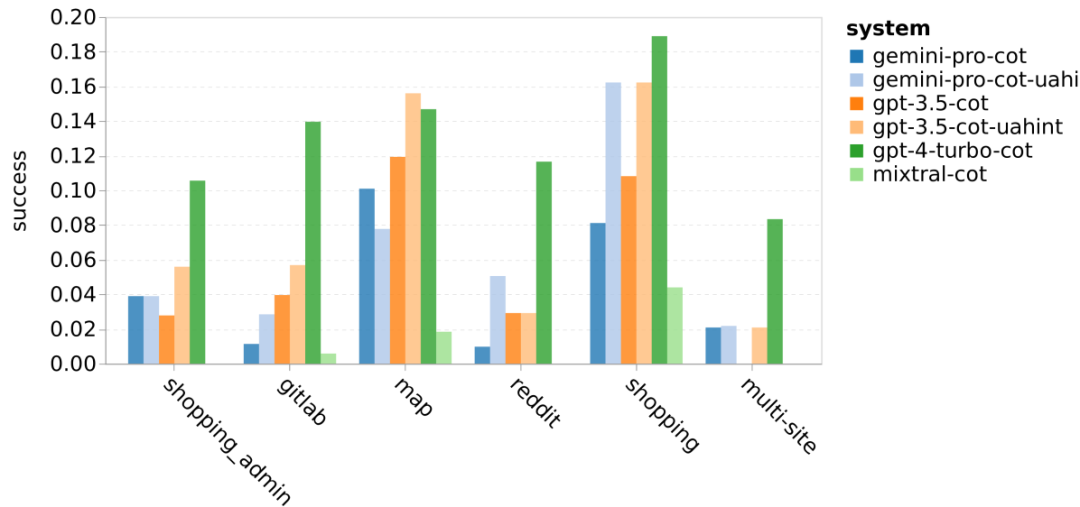
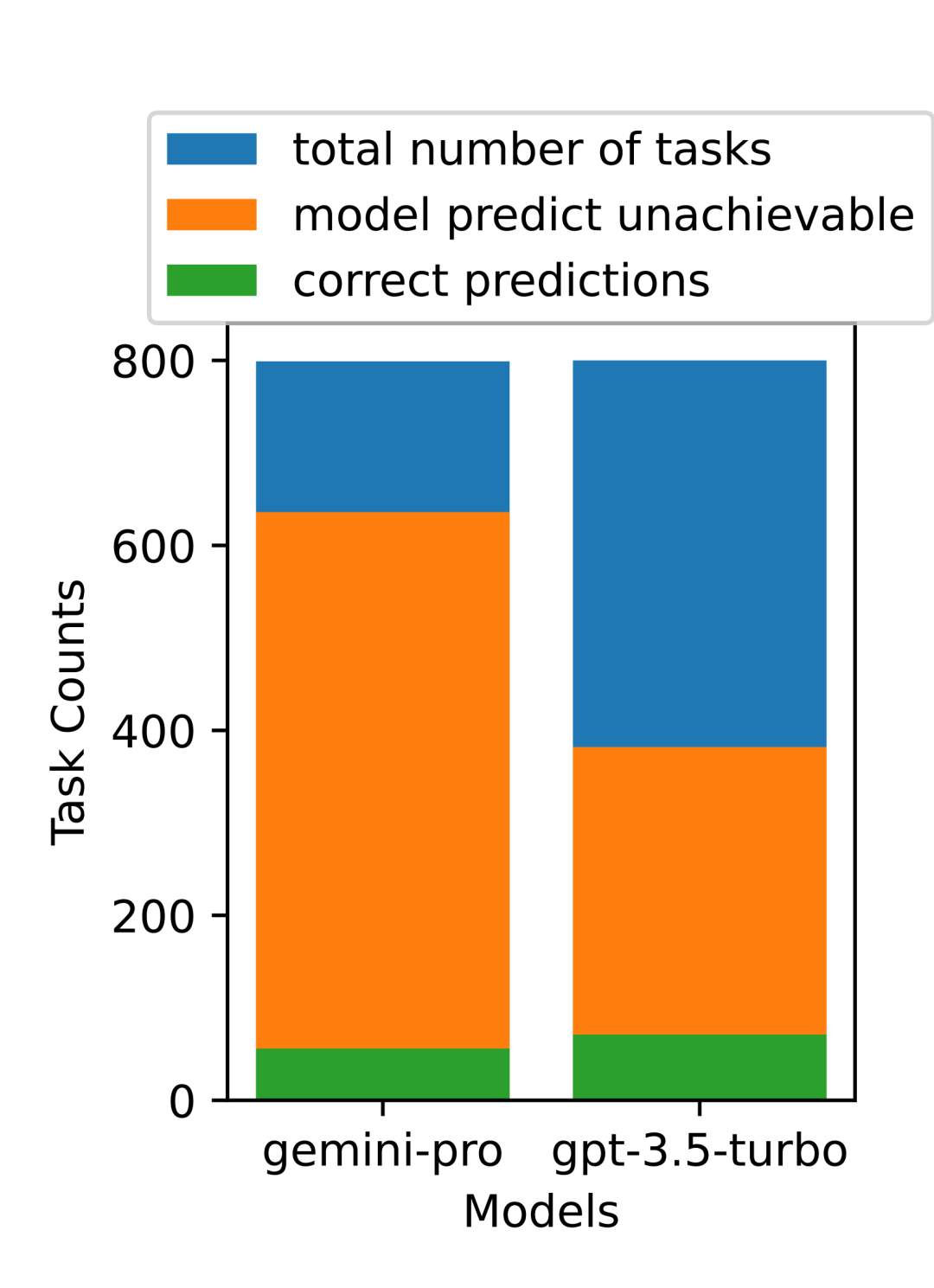
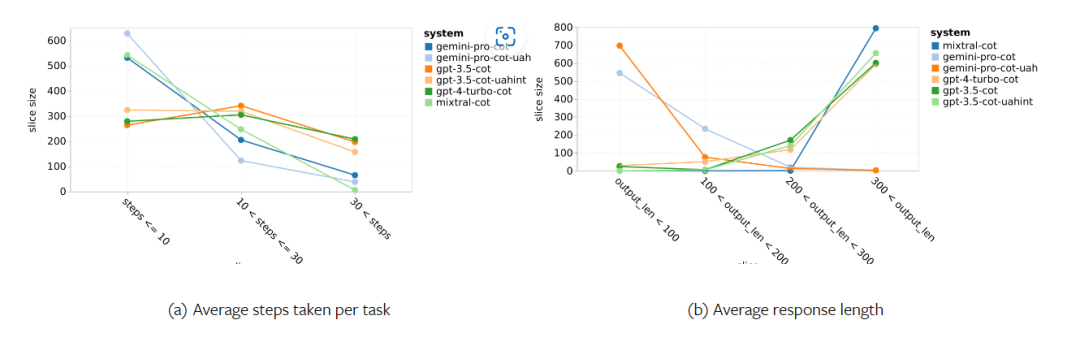
以上是对Gemini进行全面评估:从CMU到GPT 3.5 Turbo,Gemini Pro失利的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 2025币圈交易所平台哪个好 十大热门货币交易app最新推荐
Mar 25, 2025 pm 06:18 PM
2025币圈交易所平台哪个好 十大热门货币交易app最新推荐
Mar 25, 2025 pm 06:18 PM
2025币圈交易所平台排名:1. OKX,2. Binance,3. Gate.io,4. Coinbase,5. Kraken,6. Huobi Global,7. Crypto.com,8. KuCoin,9. Gemini,10. Bitstamp。这些平台在安全措施、用户评价和市场表现方面表现优异,适合用户选择进行数字货币交易。
 2025年安全好用的虚拟币交易平台榜单汇总
Mar 25, 2025 pm 06:15 PM
2025年安全好用的虚拟币交易平台榜单汇总
Mar 25, 2025 pm 06:15 PM
2025年安全好用的虚拟币交易平台推荐,本文汇总了Binance、OKX、火币、Gate.io、Coinbase、Kraken、KuCoin、Bitfinex、Crypto.com和Gemini等十个全球主流虚拟货币交易平台。它们在交易对数量、24小时成交额、安全性、用户体验等方面各有优势,例如Binance交易速度快,OKX期货交易热门,Coinbase适合新手,Kraken则以安全性着称。 但需注意,虚拟货币交易风险极高,投资需谨慎,中国大陆地区不受法律保护。选择平台前请务必仔细评估自身风
 2025加密数字货币交易app软件排名榜单最新
Mar 21, 2025 pm 02:51 PM
2025加密数字货币交易app软件排名榜单最新
Mar 21, 2025 pm 02:51 PM
加密数字货币交易app排名:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Coinbase,6. Huobi Global,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini,这些平台因其安全性、可靠性和用户体验而备受推崇,是加密货币交易的理想选择。
 2025数字货币交易所APP哪个好 十大虚拟币app交易所排行
Mar 25, 2025 pm 06:06 PM
2025数字货币交易所APP哪个好 十大虚拟币app交易所排行
Mar 25, 2025 pm 06:06 PM
2025年安全的数字货币App交易所排名:1. OKX,2. Binance,3. Gate.io,4. Coinbase,5. Kraken,6. Huobi Global,7. Crypto.com,8. KuCoin,9. Gemini,10. Bitstamp。这些平台在安全措施、用户评价和市场表现方面表现优异,适合用户选择进行数字货币交易。
 以太坊正规交易平台最新汇总2025
Mar 26, 2025 pm 04:45 PM
以太坊正规交易平台最新汇总2025
Mar 26, 2025 pm 04:45 PM
2025年,选择“正规”的以太坊交易平台意味着安全、合规、透明。 持牌经营、资金安全、透明运营、AML/KYC、数据保护和公平交易是关键。 Coinbase、Kraken、Gemini 等合规交易所值得关注。 币安和欧易有机会通过加强合规性成为正规平台。 DeFi 是一个选择,但也存在风险。 务必关注安全性、合规性、费用,分散风险,备份私钥,并进行自己的研究 。
 2025年安全靠谱的数字货币交易平台排名前十
Mar 21, 2025 pm 03:21 PM
2025年安全靠谱的数字货币交易平台排名前十
Mar 21, 2025 pm 03:21 PM
2025年安全靠谱的数字货币交易平台排名前十:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Coinbase,6. Huobi Global,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini,这些平台因其安全性、可靠性和用户体验而备受推崇,是加密货币交易的理想选择。
 2025全球十大加密货币交易所最新排名
Mar 26, 2025 pm 05:09 PM
2025全球十大加密货币交易所最新排名
Mar 26, 2025 pm 05:09 PM
要预测2025年加密货币交易所的排名很困难,因为市场变化迅速。重要的不是具体的排名,而是要了解影响排名的因素:监管合规、机构投资、DeFi整合、用户体验、安全性和全球化。 Binance、Coinbase、Kraken等都有望进入前十,但也可能出现黑天鹅事件。 关注市场趋势和交易所的动态,不要盲信排名,投资前做好调研。
 全球安全好用十大虚拟货币交易所排行榜2025
Mar 21, 2025 pm 03:09 PM
全球安全好用十大虚拟货币交易所排行榜2025
Mar 21, 2025 pm 03:09 PM
十大虚拟货币交易平台排名:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Coinbase,6. Huobi Global,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini,这些平台因其安全性、可靠性和用户体验而备受推崇,是加密货币交易的理想选择。
