

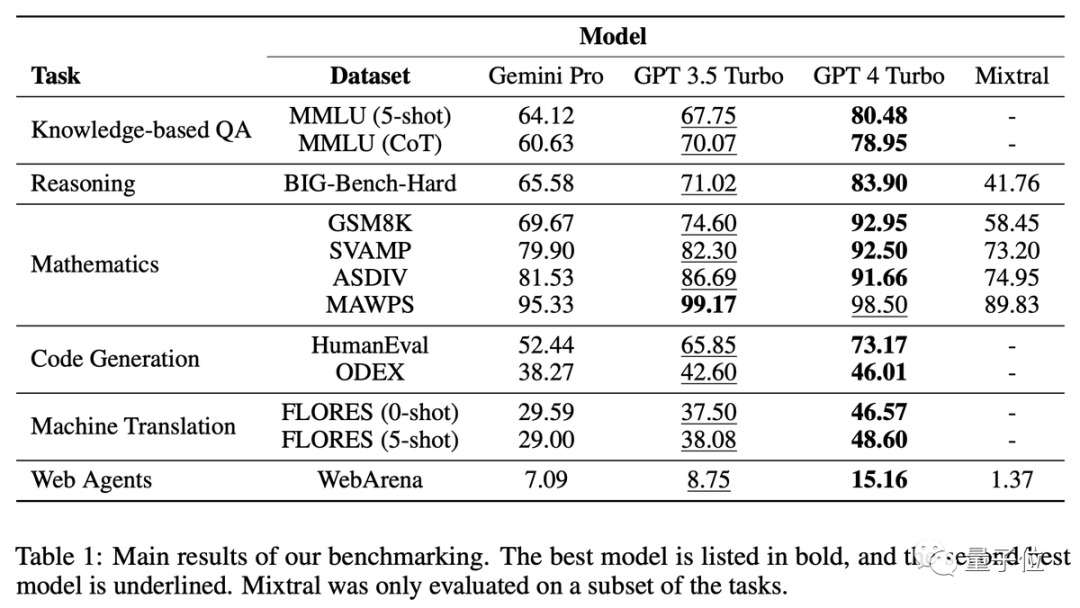
CMU进行详细比较研究,发现GPT-3.5比Gemini Pro更优,确保公平透明可重复性


谷歌Gemini的实力究竟如何?卡内基梅隆大学进行了一项专业客观的第三方比较
为保证公平,所有模型使用相同的提示和生成参数,并且提供可重复的代码和完全透明的结果。

不会像谷歌官方发布会那样,用CoT@32对比5-shot了。
一句话结果:Gemini Pro版本接近但略逊于GPT-3.5 Turbo,GPT-4还是遥遥领先。
在深入分析中还发现Gemini一些奇怪特性,比如选择题喜欢选D……

有许多研究者表示,Gemini刚刚发布没几天就进行了非常详细的测试,这是非常了不起的成就

六大任务深入测试
这个测试具体比较了6个不同的任务,并且为每个任务选择了相应的数据集
- 知识问答:MMLU
- 推理:BIG-Bench Hard
- 数学:GSM8k、SVAMP、ASDIV、MAWPS
- 代码:HumanEval、ODEX
- 翻译:FLORES
- 上网冲浪:WebArena
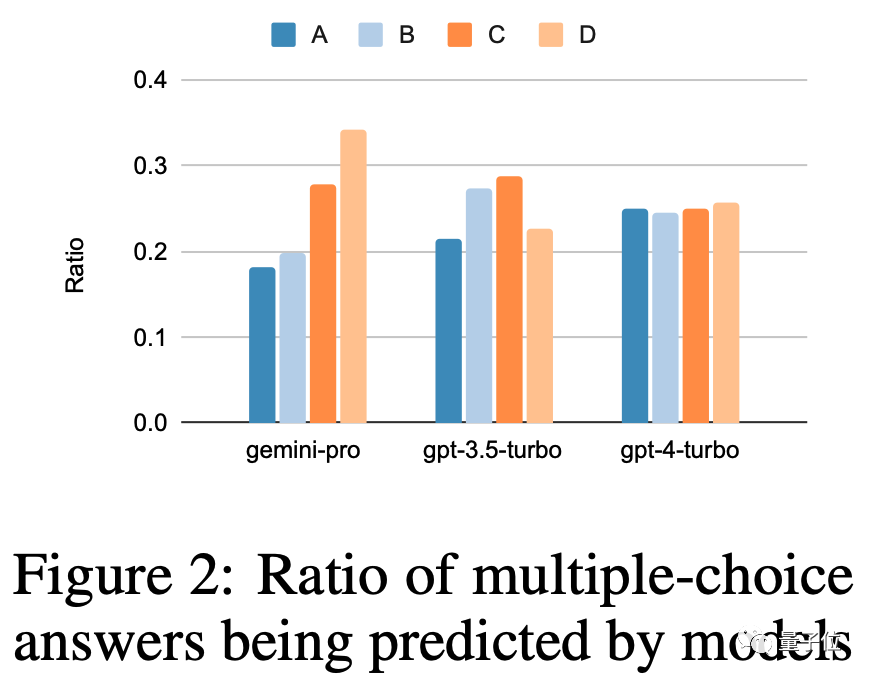
知识问答:喜欢选D
根据结果可以看出,在这类任务中使用思维链提示并不一定能够提升效果

在MMLU数据集中,所有的题目都是多选题。进一步分析结果后,发现了一个奇怪的现象:Gemini更喜欢选择D选项
GPT系列在4个选项上的分布就要平衡很多,团队提出这可能是Gemini没针对多选题做大量指令微调造成的。
另外,Gemini的安全过滤非常严格。在涉及道德问题时,它只能回答85%的问题。而在涉及人类性行为相关问题时,它只能回答28%的问题

Gemini Pro在安全研究和高中微观经济学方面的表现超过了GPT-3.5,但差距并不大,团队表示无法找出任何特别之处

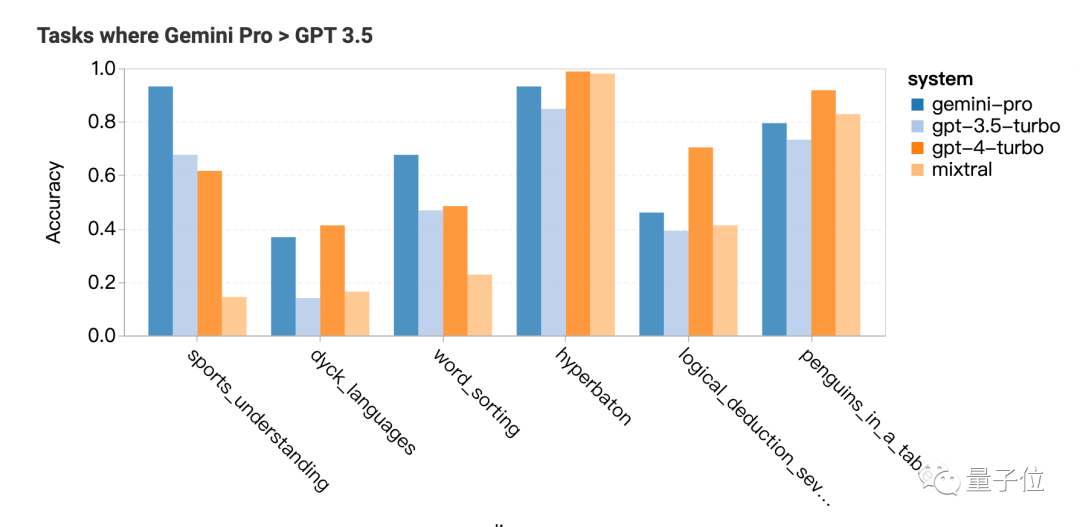
推理:长问题不擅长

GPT系列在处理更长、更复杂的问题时表现更出色,相比之下,Gemini Pro的表现较为不佳
特别是在长篇问题上,GPT-4 Turbo几乎没有性能下降,这表明它具备了理解复杂问题的强大能力

根据问题类型进行分析,Gemini在“追踪交换物品”这类问题上表现不佳,这类问题涉及人们进行物品交换,最终需要AI判断每个人拥有哪些物品

Gemini擅长的任务包括理解世界各种体育运动知识、操作符号堆栈、按字母顺序排序单词以及解析表格
数学:复杂任务反超

问题本身太长,导致Gemini Pro和GPT-3.5的表现同时下降,只有GPT-4能够保持一贯的水准

当思维链的长度达到最长时,Gemini超过了GPT-3.5

代码:擅长matplotlib
对于代码问题,Gemini在参考答案较长的问题上表现不佳

GPT系列在大多数类型中更强大,但在matplotlib方面表现完全不佳

翻译:只要回答了,质量就很高
在翻译任务中,Gemini拒绝回答了12种类型的问题,但只要回答了的翻译质量都非常出色,整体表现超过了GPT-4

双子座拒绝翻译的语言主要涉及拉丁语和阿拉伯语

网络导航:擅长跨站点冲浪
WebArena为AI模拟了一个互联网环境,包括电子商务、社交论坛、GitLab协作开发、内容管理系统和在线地图等。AI需要在这个环境中查找信息或跨站点完成任务
Gemini在整体表现不如GPT-3.5 Turbo,但在跨多个站点的任务中表现稍好。

网友:但是它免费啊
最终,CMU副教授格雷厄姆·纽比格承认了这项研究的一些限制
- 基于API的模型行为可能随时变化
- 只尝试了有限数量的提示,对不同模型来说适用的提示词可能不一样
- 无法控制测试集是否泄露

谷歌大型模型推理团队的负责人周登勇指出,将Gemini的温度设置为0可以提高5-10个百分点,对于推理任务非常有帮助

在这项测试中,除了Gemini和GPT系列,还引入了最近备受关注的开源MoE模型Mixtral
不过,强化学习专家Noam Brown认为可以不考虑Mixtral的结果,因为它使用的是第三方API而不是官方实现


Mistral AI创始人为团队提供了官方版调用权限,他相信这将带来更好的结果
虽然Gemini Pro还不及GPT-3.5,但它的优势在于每分钟调用不超过60次就可以免费使用
因此,许多个人开发者已经改变了阵营

目前Gemini的最高版本Ultra版尚未发布,届时CMU团队也打算继续进行这项研究
你认为双子座Ultra能够达到GPT-4的水平吗?
本文详细介绍了论文:https://arxiv.org/abs/2312.11444
参考链接:
[1]https://twitter.com/gneubig/status/1737108977954251216。
以上是CMU进行详细比较研究,发现GPT-3.5比Gemini Pro更优,确保公平透明可重复性的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 2025币圈交易所平台哪个好 十大热门货币交易app最新推荐
Mar 25, 2025 pm 06:18 PM
2025币圈交易所平台哪个好 十大热门货币交易app最新推荐
Mar 25, 2025 pm 06:18 PM
2025币圈交易所平台排名:1. OKX,2. Binance,3. Gate.io,4. Coinbase,5. Kraken,6. Huobi Global,7. Crypto.com,8. KuCoin,9. Gemini,10. Bitstamp。这些平台在安全措施、用户评价和市场表现方面表现优异,适合用户选择进行数字货币交易。
 欧易okex账号怎么注册、使用、注销教程
Mar 31, 2025 pm 04:21 PM
欧易okex账号怎么注册、使用、注销教程
Mar 31, 2025 pm 04:21 PM
本文详细介绍了欧易OKEx账号的注册、使用和注销流程。注册需下载APP,输入手机号或邮箱注册,完成实名认证。使用方面涵盖登录、充值提现、交易以及安全设置等操作步骤。而注销账号则需要联系欧易OKEx客服,提供必要信息并等待处理,最终获得账号注销确认。 通过本文,用户可以轻松掌握欧易OKEx账号的完整生命周期管理,安全便捷地进行数字资产交易。
 2025年安全好用的虚拟币交易平台榜单汇总
Mar 25, 2025 pm 06:15 PM
2025年安全好用的虚拟币交易平台榜单汇总
Mar 25, 2025 pm 06:15 PM
2025年安全好用的虚拟币交易平台推荐,本文汇总了Binance、OKX、火币、Gate.io、Coinbase、Kraken、KuCoin、Bitfinex、Crypto.com和Gemini等十个全球主流虚拟货币交易平台。它们在交易对数量、24小时成交额、安全性、用户体验等方面各有优势,例如Binance交易速度快,OKX期货交易热门,Coinbase适合新手,Kraken则以安全性着称。 但需注意,虚拟货币交易风险极高,投资需谨慎,中国大陆地区不受法律保护。选择平台前请务必仔细评估自身风
 2025数字货币交易所APP哪个好 十大虚拟币app交易所排行
Mar 25, 2025 pm 06:06 PM
2025数字货币交易所APP哪个好 十大虚拟币app交易所排行
Mar 25, 2025 pm 06:06 PM
2025年安全的数字货币App交易所排名:1. OKX,2. Binance,3. Gate.io,4. Coinbase,5. Kraken,6. Huobi Global,7. Crypto.com,8. KuCoin,9. Gemini,10. Bitstamp。这些平台在安全措施、用户评价和市场表现方面表现优异,适合用户选择进行数字货币交易。
 以太坊正规交易平台最新汇总2025
Mar 26, 2025 pm 04:45 PM
以太坊正规交易平台最新汇总2025
Mar 26, 2025 pm 04:45 PM
2025年,选择“正规”的以太坊交易平台意味着安全、合规、透明。 持牌经营、资金安全、透明运营、AML/KYC、数据保护和公平交易是关键。 Coinbase、Kraken、Gemini 等合规交易所值得关注。 币安和欧易有机会通过加强合规性成为正规平台。 DeFi 是一个选择,但也存在风险。 务必关注安全性、合规性、费用,分散风险,备份私钥,并进行自己的研究 。
 2025全球十大加密货币交易所最新排名
Mar 26, 2025 pm 05:09 PM
2025全球十大加密货币交易所最新排名
Mar 26, 2025 pm 05:09 PM
要预测2025年加密货币交易所的排名很困难,因为市场变化迅速。重要的不是具体的排名,而是要了解影响排名的因素:监管合规、机构投资、DeFi整合、用户体验、安全性和全球化。 Binance、Coinbase、Kraken等都有望进入前十,但也可能出现黑天鹅事件。 关注市场趋势和交易所的动态,不要盲信排名,投资前做好调研。
 如何优化jieba分词以改善景区评论的关键词提取效果?
Apr 01, 2025 pm 06:24 PM
如何优化jieba分词以改善景区评论的关键词提取效果?
Apr 01, 2025 pm 06:24 PM
如何优化jieba分词以改善景区评论的关键词提取?在使用jieba分词处理景区评论数据时,如果发现分词结果不理�...
 十大虚拟数字货币交易所 最新货币交易平台app排行2025年
Mar 25, 2025 pm 06:30 PM
十大虚拟数字货币交易所 最新货币交易平台app排行2025年
Mar 25, 2025 pm 06:30 PM
2025年安全的数字货币App交易所排名:1. OKX,2. Binance,3. Gate.io,4. Coinbase,5. Kraken,6. Huobi Global,7. Crypto.com,8. KuCoin,9. Gemini,10. Bitstamp。这些平台在安全措施、用户评价和市场表现方面表现优异,适合用户选择进行数字货币交易。
