

探索全新路径-IO等待的诊断工具

| 导读 | 最近在做日志的实时同步,上线之前是做过单份线上日志压力测试的,消息队列和客户端、本机都没问题,但是没想到上了第二份日志之后,问题来了: |
集群中的某台机器 top 看到负载巨高,集群中的机器硬件配置一样,部署的软件都一样,却单单这一台负载有问题,初步猜测可能硬件有问题了。
同时,我们还需要把负载有异常的罪魁祸首揪出来,到时候从软件、硬件层面分别寻找解决方案。

从 top 中可以看到 load average 偏高,%wa 很高,%us 偏低:
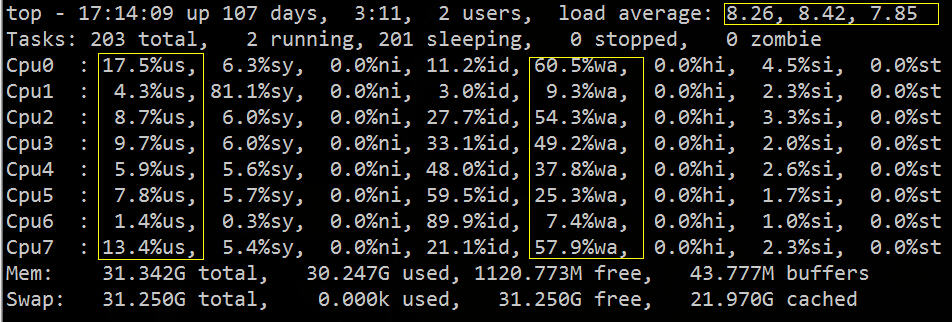
从上图我们大致可以推断 IO 遇到了瓶颈,下面我们可以再用相关的 IO 诊断工具,具体的验证排查下。
常用组合方式有如下几种:
•用vmstat、sar、iostat检测是否是CPU瓶颈
•用free、vmstat检测是否是内存瓶颈
•用iostat、dmesg 检测是否是磁盘I/O瓶颈
•用netstat检测是否是网络带宽瓶颈
vmstat命令的含义为显示虚拟内存状态(“Virtual Memor Statics”),但是它可以报告关于进程、内存、I/O等系统整体运行状态。
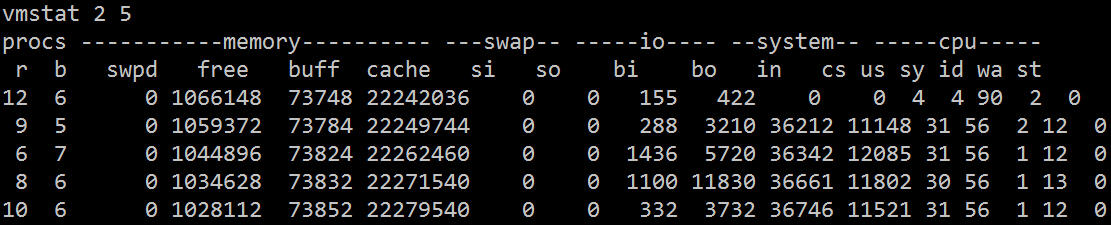
它的相关字段说明如下:
Procs(进程)
•r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)
•b: 等待IO的进程数量,也就是处在非中断睡眠状态的进程数,展示了正在执行和等待CPU资源的任务个数。当这个值超过了CPU数目,就会出现CPU瓶颈了
Memory(内存)
•swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
•free: 空闲物理内存大小。
•buff: 用作缓冲的内存大小。
•cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。
Swap(交换区)
•si: 每秒从交换区写到内存的大小,由磁盘调入内存。
•so: 每秒写入交换区的内存大小,由内存调入磁盘。
注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
IO(输入输出)
(现在的Linux版本块的大小为1kb)
•bi: 每秒读取的块数
•bo: 每秒写入的块数
注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
system(系统)
•in: 每秒中断数,包括时钟中断。
•cs: 每秒上下文切换数。
注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
CPU
(以百分比表示)
•us: 用户进程执行时间百分比(user time)。us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
•sy: 内核系统进程执行时间百分比(system time)。sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
•wa: IO等待时间百分比。wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
•id: 空闲时间百分比
从 vmstat 中可以看到,CPU大部分的时间浪费在等待IO上面,可能是由于大量的磁盘随机访问或者磁盘的带宽所造成的,bi、bo 也都超过 1024k,应该是遇到了IO瓶颈。
2.2 iostat下面再用更加专业的磁盘 IO 诊断工具来看下相关统计数据。
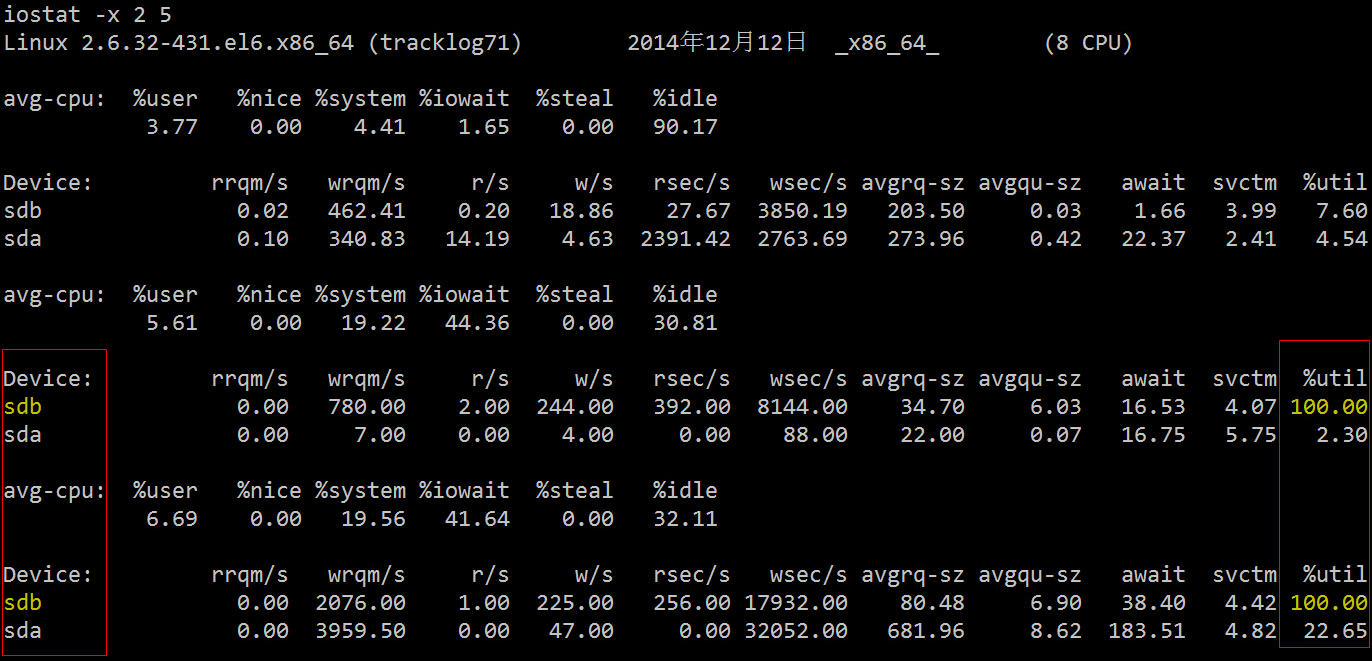
它的相关字段说明如下:
•rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
•wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
•r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
•w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
•rsec/s: 每秒读扇区数。即 delta(rsect)/s
•wsec/s: 每秒写扇区数。即 delta(wsect)/s
•rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
•wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)
•avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
•avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
•await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
•svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
•%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
可以看到两块硬盘中的 sdb 的利用率已经 100%,存在严重的 IO 瓶颈,下一步我们就是要找出哪个进程在往这块硬盘读写数据。
2.3 iotop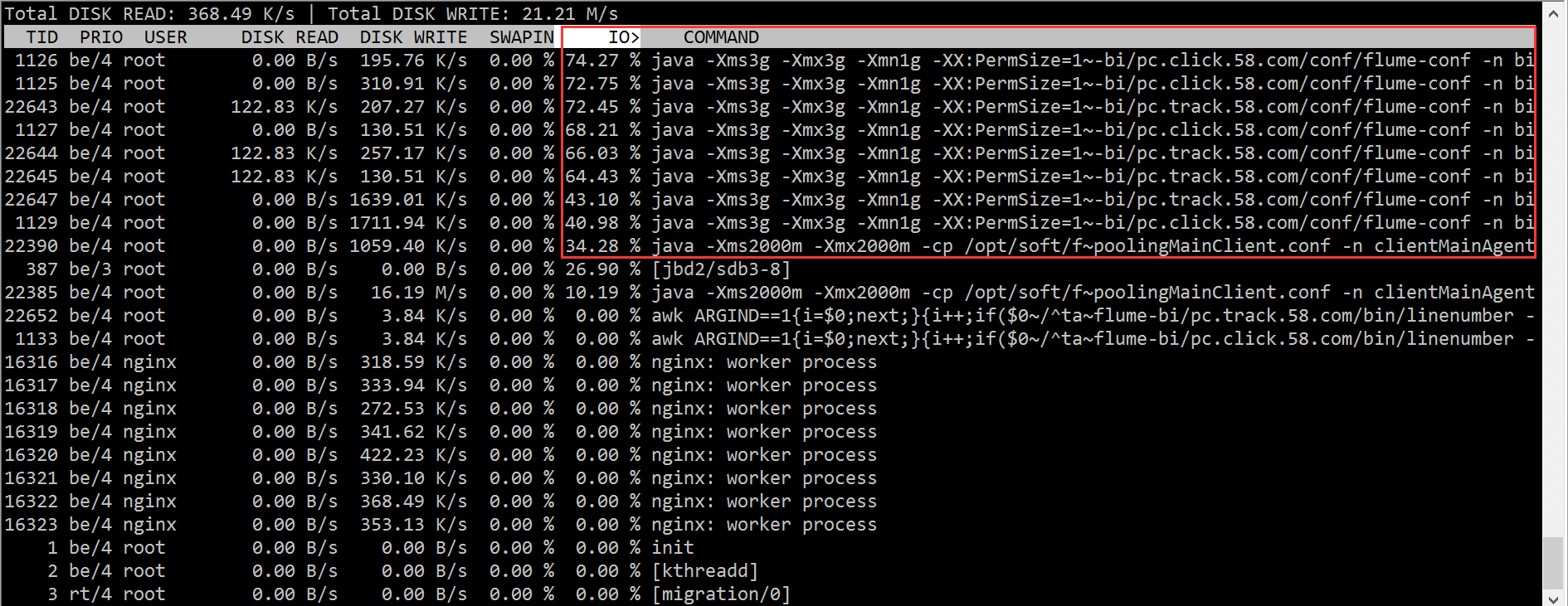
根据 iotop 的结果,我们迅速的定位到是 flume 进程的问题,造成了大量的 IO wait。
但是在开头我已经说了,集群中的机器配置一样,部署的程序也都 rsync 过去的一模一样,难道是硬盘坏了?
这得找运维同学来查证了,最后的结论是:
Sdb为双盘raid1,使用raid卡为“LSI Logic / Symbios Logic SAS1068E”,无cache。近400的IOPS压力已经达到了硬件极限。而其它机器使用的raid卡是“LSI Logic / Symbios Logic MegaRAID SAS 1078”,有256MB cache,并未达到硬件瓶颈,解决办法是更换能提供更大IOPS的机器,比如最后我们换了一台带 PERC6/i 集成RAID控制器卡的机器。需要说明的是,raid信息是在raid卡和磁盘固件里面各存一份,磁盘上的raid信息和raid卡上面的信息格式要是匹配的,否则raid卡识别不了就需要格式化磁盘。
IOPS本质上取决于磁盘本身,但是又很多提升IOPS的方法,加硬件cache、采用RAID阵列是常用的办法。如果是DB那种IOPS很高的场景,现在流行用SSD来取代传统的机械硬盘。
不过前面也说了,我们从软硬件两方面着手的目的就是看能否分别寻求代价最小的解决方案:
知道硬件的原因了,我们可以尝试把读写操作移到另一块盘,然后再看看效果:
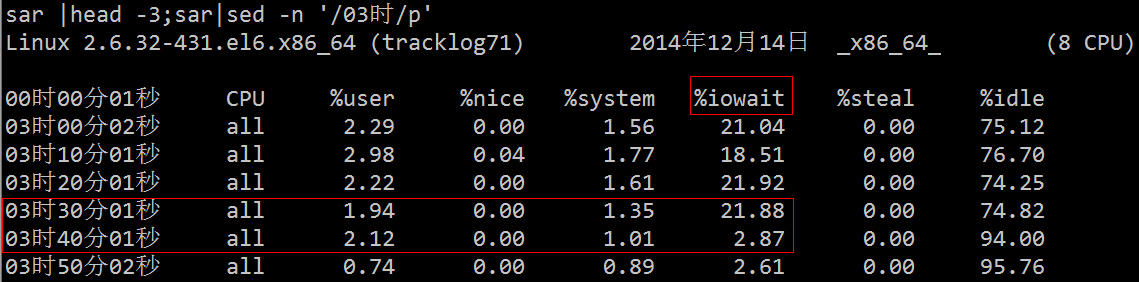
其实,除了用上述专业的工具定位这个问题外,我们可以直接利用进程状态来找到相关的进程。
我们知道进程有如下几种状态:
•D uninterruptible sleep (usually IO)
•R running or runnable (on run queue)
•S interruptible sleep (waiting for an event to complete)
•T stopped, either by a job control signal or because it is being traced.
•W paging (not valid since the 2.6.xx kernel)
•X dead (should never be seen)
•Z defunct ("zombie") process, terminated but not reaped by its parent.
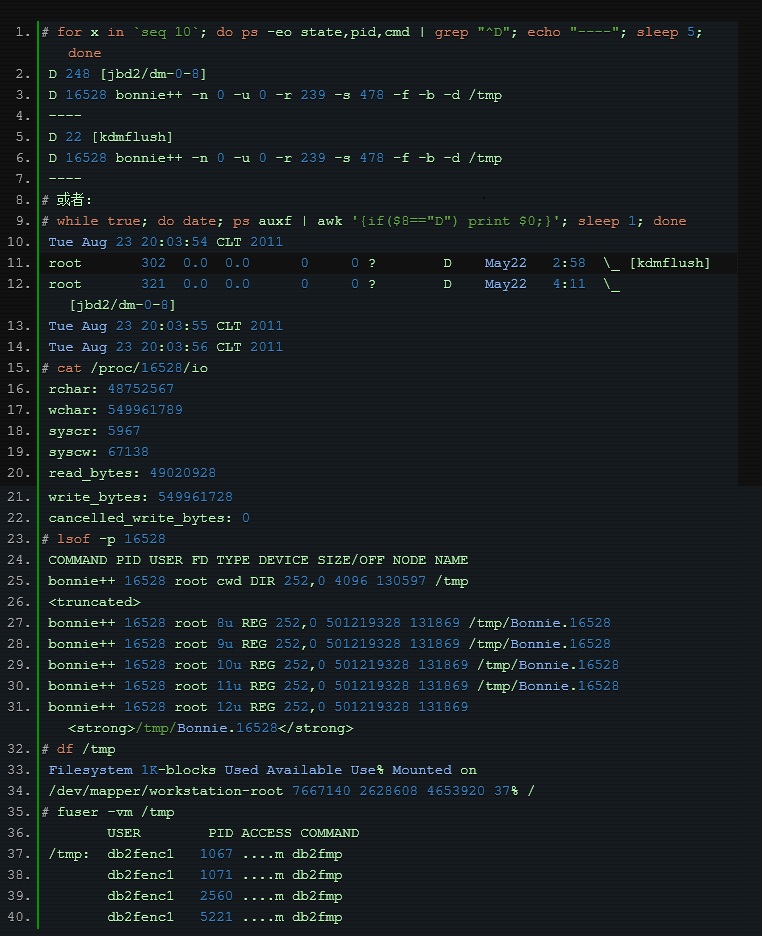
其中状态为 D 的一般就是由于 wait IO 而造成所谓的”非中断睡眠“,我们可以从这点入手然后一步步的定位问题:
以上是探索全新路径-IO等待的诊断工具的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Linux实际上有什么好处?
Apr 12, 2025 am 12:20 AM
Linux实际上有什么好处?
Apr 12, 2025 am 12:20 AM
Linux适用于服务器、开发环境和嵌入式系统。1.作为服务器操作系统,Linux稳定高效,常用于部署高并发应用。2.作为开发环境,Linux提供高效的命令行工具和包管理系统,提升开发效率。3.在嵌入式系统中,Linux轻量且可定制,适合资源有限的环境。
 apache怎么启动
Apr 13, 2025 pm 01:06 PM
apache怎么启动
Apr 13, 2025 pm 01:06 PM
启动 Apache 的步骤如下:安装 Apache(命令:sudo apt-get install apache2 或从官网下载)启动 Apache(Linux:sudo systemctl start apache2;Windows:右键“Apache2.4”服务并选择“启动”)检查是否已启动(Linux:sudo systemctl status apache2;Windows:查看服务管理器中“Apache2.4”服务的状态)启用开机自动启动(可选,Linux:sudo systemctl
 apache80端口被占用怎么办
Apr 13, 2025 pm 01:24 PM
apache80端口被占用怎么办
Apr 13, 2025 pm 01:24 PM
当 Apache 80 端口被占用时,解决方法如下:找出占用该端口的进程并关闭它。检查防火墙设置以确保 Apache 未被阻止。如果以上方法无效,请重新配置 Apache 使用不同的端口。重启 Apache 服务。
 如何在Debian上监控Nginx SSL性能
Apr 12, 2025 pm 10:18 PM
如何在Debian上监控Nginx SSL性能
Apr 12, 2025 pm 10:18 PM
本文介绍如何在Debian系统上有效监控Nginx服务器的SSL性能。我们将使用NginxExporter将Nginx状态数据导出到Prometheus,再通过Grafana进行可视化展示。第一步:配置Nginx首先,我们需要在Nginx配置文件中启用stub_status模块来获取Nginx的状态信息。在你的Nginx配置文件(通常位于/etc/nginx/nginx.conf或其包含文件中)中添加以下代码段:location/nginx_status{stub_status
 oracle怎么启动监听
Apr 12, 2025 am 06:00 AM
oracle怎么启动监听
Apr 12, 2025 am 06:00 AM
启动 Oracle 监听器的步骤如下:检查监听器状态(使用 lsnrctl status 命令)对于 Windows,在 Oracle Services Manager 中启动 "TNS Listener" 服务对于 Linux 和 Unix,使用 lsnrctl start 命令启动监听器运行 lsnrctl status 命令验证监听器是否已启动
 Debian系统中如何设置回收站
Apr 12, 2025 pm 10:51 PM
Debian系统中如何设置回收站
Apr 12, 2025 pm 10:51 PM
本文介绍两种在Debian系统中配置回收站的方法:图形界面和命令行。方法一:使用Nautilus图形界面打开文件管理器:在桌面或应用程序菜单中找到并启动Nautilus文件管理器(通常名为“文件”)。找到回收站:在左侧导航栏中寻找“回收站”文件夹。如果找不到,请尝试点击“其他位置”或“计算机”进行搜索。配置回收站属性:右键点击“回收站”,选择“属性”。在属性窗口中,您可以调整以下设置:最大大小:限制回收站可用的磁盘空间。保留时间:设置文件在回收站中自动删除前的保
 apache服务器怎么重启
Apr 13, 2025 pm 01:12 PM
apache服务器怎么重启
Apr 13, 2025 pm 01:12 PM
要重启 Apache 服务器,请按照以下步骤操作:Linux/macOS:运行 sudo systemctl restart apache2。Windows:运行 net stop Apache2.4 然后 net start Apache2.4。运行 netstat -a | findstr 80 检查服务器状态。
 如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系统中,readdir系统调用用于读取目录内容。如果其性能表现不佳,可尝试以下优化策略:精简目录文件数量:尽可能将大型目录拆分成多个小型目录,降低每次readdir调用处理的项目数量。启用目录内容缓存:构建缓存机制,定期或在目录内容变更时更新缓存,减少对readdir的频繁调用。内存缓存(如Memcached或Redis)或本地缓存(如文件或数据库)均可考虑。采用高效数据结构:如果自行实现目录遍历,选择更高效的数据结构(例如哈希表而非线性搜索)存储和访问目录信
