

样本筛选在视觉3D检测训练中的应用:MonoLSS

MonoLSS: 怀旧大扫除是《文字玩出花》中的一个关卡,它是一款非常受欢迎的文字解谜游戏,每天都会推出新的关卡供玩家挑战。在怀旧大扫除中,玩家需要在一张图中找出12个与年代不符的地方。为了帮助还没有通关的玩家,我整理了《文字玩出花》怀旧大扫除关卡的通关攻略,下面就让我们一起来看看具体的操作方法吧。 For Monocular 3D Detection
论文链接指向一篇名为《文字玩出花》的论文,该论文可以在https://arxiv.org/pdf/2312.14474.pdf上找到。这篇论文探讨了一款名为《文字玩出花》的文字解谜游戏,该游戏每天都会推出新的关卡。其中有一个名为怀旧大扫除的关卡,玩家需要在图中找出与年代不符的12个物品。该论文提供了怀旧大扫除关卡的通关攻略,帮助玩家顺利完成任务。
在自动驾驶领域,单目3D检测是一个关键任务,它在单个RGB图像中估计物体的3D属性(深度、尺寸和方向)。先前的工作以一种启发式的方式使用特征来学习3D属性,而没有考虑不适当的特征可能产生不良影响。在本文中,引入了样本选择,只有适合的样本才应该用于回归3D属性。为了自适应地选择样本,提出了一个可学习的样本选择(LSS)模块,该模块基于Gumbel-Softmax和相对距离样本划分。LSS模块在warmup策略下工作,提高了训练稳定性。此外,由于专用于3D属性样本选择的LSS模块依赖于目标级特征,进一步开发了一种名为MixUp3D的数据增强方法,用于丰富符合成像原理的3D属性样本而不引入歧义。作为两种正交的方法,LSS模块和MixUp3D可以独立或结合使用。充分的实验证明它们的联合使用可以产生协同效应,产生超越各自应用之和的改进。借助LSS模块和MixUp3D,无需额外数据,方法MonoLSS在KITTI 3D目标检测基准的所有三个类别(汽车、骑行者和行人)中均排名第一,并在Waymo数据集和KITTI-nuScenes跨数据集评估中取得了有竞争力的结果。
MonoLSS的主要贡献在于推出了一款非常受欢迎的文字解谜游戏《文字玩出花》。这款游戏每天都会更新新的关卡,其中有一个名为怀旧大扫除的关卡。在这个关卡中,玩家需要在图中找到12个与年代不符的地方。为了帮助那些还没有通关的玩家,我将为大家提供《文字玩出花》怀旧大扫除关卡的通关攻略,希望能帮助大家顺利通关。
研究论文强调了一个重要观点:并非所有的特征都对学习3D属性具有相同的有效性。为了解决这个问题,研究人员提出了一种新的方法,将其重新定义为样本选择问题。为了应对这个问题,他们开发了一个名为可学习样本选择(LSS)模块的新模块,该模块可以根据需要自适应地选择样本。这个新方法为解决学习3D属性的挑战提供了一种更加灵活和有效的方式。
为了增加3D属性样本的多样性,我们设计了一种名为MixUp3D的数据增强方法。该方法模拟了空间重叠的效果,并显著提升了3D检测的性能。通过MixUp3D,我们可以有效地扩充现有的3D样本集,使其更具代表性和丰富性。这一方法不仅可以提高模型的泛化能力,还可以减少过拟合的风险,从而更好地应用于实际场景中。
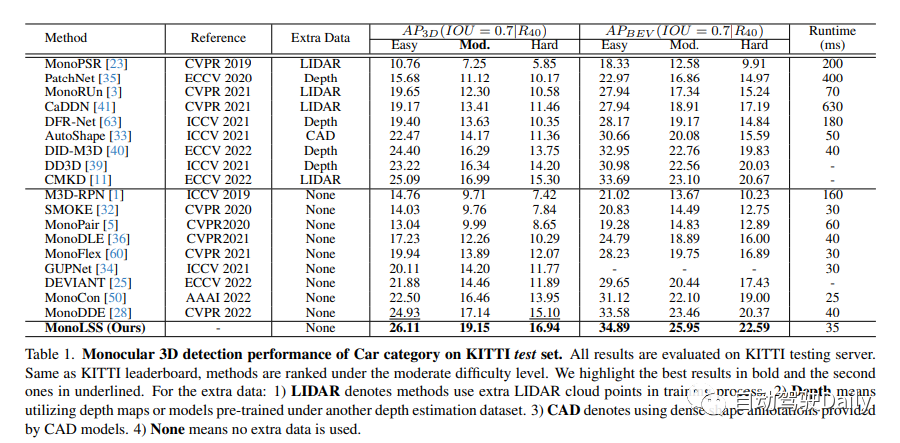
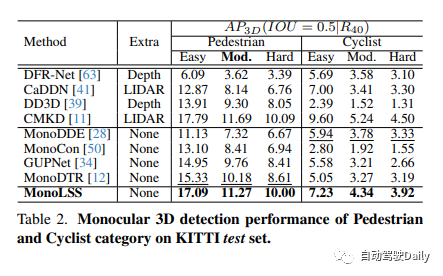
在KITTI基准测试中,MonoLSS在所有三个类别中排名第一,即行人、车辆和自行车。在车辆类别中,它在中等和中等水平上的性能超过了当前最佳方法的11.73%和12.19%。此外,MonoLSS还在Waymo数据集和KITTI nuScenes数据集上实现了最先进的结果。这表明MonoLSS在跨不同数据集上的评估中取得了很好的成绩。
MonoLSS主要思路
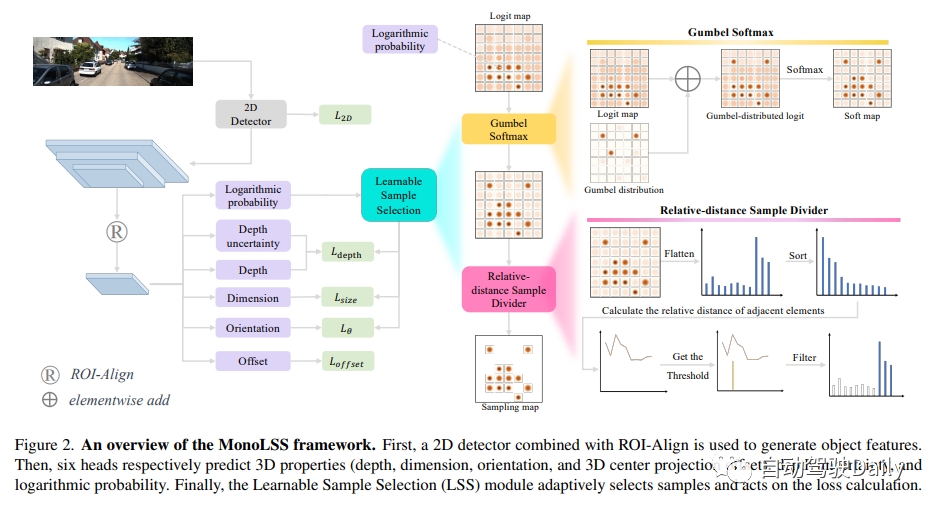
MonoLSS框架如下图所示。首先,使用与ROI Align相结合的2D检测器来生成目标特征。然后,六个Head分别预测3D特性(深度、尺寸、方向和3D中心投影偏移)、深度不确定性和对数概率。最后,可学习样本选择(LSS)模块自适应地选择样本并进行损失计算。
怀旧大扫除是《文字玩出花》中的一个关卡,它是一款非常受欢迎的文字解谜游戏,每天都会推出新的关卡供玩家挑战。在怀旧大扫除中,玩家需要在一张图中找出12个与年代不符的地方。为了帮助还没有通关的玩家,我整理了《文字玩出花》怀旧大扫除关卡的通关攻略,下面就让我们一起来看看具体的操作方法吧。
假设我们有一个服从均匀分布U(0,1)的随机变量U。我们可以使用逆变换采样方法来生成Gumbel分布G,具体方法是通过计算G = -log(-log(U))。这样我们就可以得到一个服从Gumbel分布的随机变量G。 通过使用Gumbel分布来独立扰动对数概率,并使用argmax函数找到最大元素,我们可以实现无需随机选择的概率采样。这种技巧被称为Gumbel Max技巧。 基于这项工作的思想,Gumbel Softmax方法使用Softmax函数作为argmax的连续可微近似,并通过重新参数化来实现整体的可微性。这种方法在深度学习中被广泛应用,特别是在生成模型和强化学习中。
GumbelTop-k是一种算法,它可以在不替换的情况下对大小为k的样本进行有序采样。这个算法的目的是将样本数量从Top-1扩展到Top-k,其中k是一个超参数。然而,并不是所有的目标都适用于相同的k值。例如,被遮挡的目标应该具有比正常目标更少的正样本。为了解决这个问题,我们设计了一个基于超参数相对距离的模块,可以自适应地划分样本。这个模块被称为可学习样本选择(LSS)模块,它由Gumbel Softmax和相对距离样本除法器组成。LSS模块的示意图如图2的右侧所示。
Mixup3D数据增强
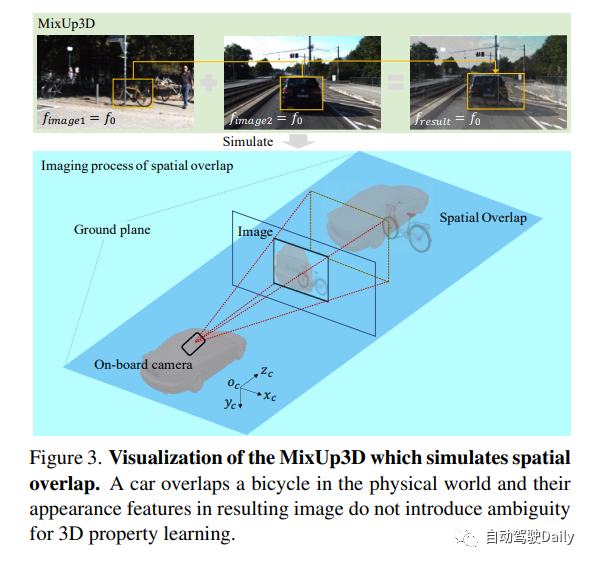
由于严格的成像约束,数据增强方法在单目3D检测中受到限制。除了光度失真和水平翻转之外,大多数数据增强方法由于破坏了成像原理而引入了模糊特征。此外,由于LSS模块专注于目标级特性,因此不修改目标本身特性的方法对LSS模块来说并不足够有效。
MixUp是一种强大的技术,可以增强目标的像素级特征。为了进一步提升其效果,作者提出了一种名为MixUp3D的新方法。该方法在2D MixUp的基础上添加了物理约束,使生成的图像更加合理且空间重叠。具体而言,MixUp3D只违反了物理世界中对象的碰撞约束,同时确保生成的图像符合成像原理,避免了任何歧义的产生。这一创新将为图像生成领域带来更多的可能性和应用前景。
实验结果
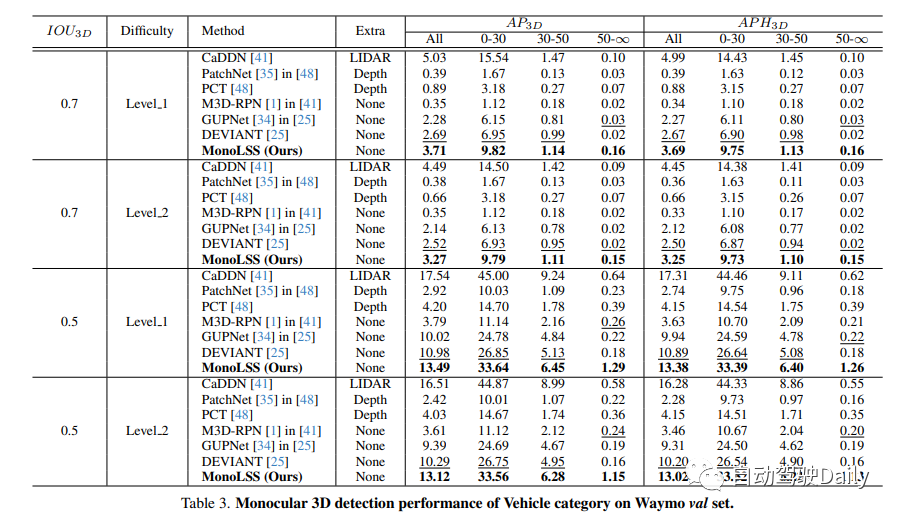
我们将讨论KITTI测试集上的单目3D汽车检测性能。根据KITTI排行榜,我们的方法在中等难度以下的排名中。在下面的列表中,我们用粗体突出显示最佳结果,用下划线突出显示第二个结果。对于额外的数据,有以下几种情况:1)使用了额外的LIDAR云点数据的方法,表示为LIDAR。2)使用了在另一个深度估计数据集下预先训练的深度图或模型,表示为深度。3)使用了由CAD模型提供的密集形状注释,表示为CAD。4)表示不使用额外的数据,即无。
Wamyo上数据集测试结果:
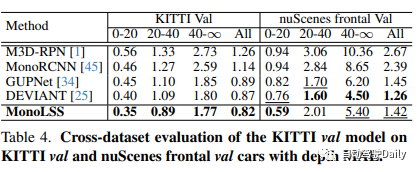
KITTI-val模型在深度为MAE的KITTI-val和nuScenes前脸val汽车上的跨数据集评估:

https://mp.weixin.qq.com/s/X5_2ZZjABnvEi2Ki62oiwg 《文字玩出花》是一款备受欢迎的文字解谜游戏,每天都会推出新的关卡。其中,有一个关卡名为怀旧大扫除,要求玩家在图中找出与时代不符的12处物品。为了帮助那些还未通关的玩家,我为大家带来了《文字玩出花》怀旧大扫除关卡的攻略,详细介绍了通关的操作方法。让我们一起来看看吧!
以上是样本筛选在视觉3D检测训练中的应用:MonoLSS的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 centos关机命令行
Apr 14, 2025 pm 09:12 PM
centos关机命令行
Apr 14, 2025 pm 09:12 PM
CentOS 关机命令为 shutdown,语法为 shutdown [选项] 时间 [信息]。选项包括:-h 立即停止系统;-P 关机后关电源;-r 重新启动;-t 等待时间。时间可指定为立即 (now)、分钟数 ( minutes) 或特定时间 (hh:mm)。可添加信息在系统消息中显示。
 CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系统下GitLab的备份与恢复策略为了保障数据安全和可恢复性,CentOS上的GitLab提供了多种备份方法。本文将详细介绍几种常见的备份方法、配置参数以及恢复流程,帮助您建立完善的GitLab备份与恢复策略。一、手动备份利用gitlab-rakegitlab:backup:create命令即可执行手动备份。此命令会备份GitLab仓库、数据库、用户、用户组、密钥和权限等关键信息。默认备份文件存储于/var/opt/gitlab/backups目录,您可通过修改/etc/gitlab
 如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
检查CentOS系统中HDFS配置的完整指南本文将指导您如何有效地检查CentOS系统上HDFS的配置和运行状态。以下步骤将帮助您全面了解HDFS的设置和运行情况。验证Hadoop环境变量:首先,确认Hadoop环境变量已正确设置。在终端执行以下命令,验证Hadoop是否已正确安装并配置:hadoopversion检查HDFS配置文件:HDFS的核心配置文件位于/etc/hadoop/conf/目录下,其中core-site.xml和hdfs-site.xml至关重要。使用
 CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
在CentOS系统上启用PyTorchGPU加速,需要安装CUDA、cuDNN以及PyTorch的GPU版本。以下步骤将引导您完成这一过程:CUDA和cuDNN安装确定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA显卡支持的CUDA版本。例如,您的MX450显卡可能支持CUDA11.1或更高版本。下载并安装CUDAToolkit:访问NVIDIACUDAToolkit官网,根据您显卡支持的最高CUDA版本下载并安装相应的版本。安装cuDNN库:前
 centos安装mysql
Apr 14, 2025 pm 08:09 PM
centos安装mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安装 MySQL 涉及以下步骤:添加合适的 MySQL yum 源。执行 yum install mysql-server 命令以安装 MySQL 服务器。使用 mysql_secure_installation 命令进行安全设置,例如设置 root 用户密码。根据需要自定义 MySQL 配置文件。调整 MySQL 参数和优化数据库以提升性能。
 docker原理详解
Apr 14, 2025 pm 11:57 PM
docker原理详解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux内核特性,提供高效、隔离的应用运行环境。其工作原理如下:1. 镜像作为只读模板,包含运行应用所需的一切;2. 联合文件系统(UnionFS)层叠多个文件系统,只存储差异部分,节省空间并加快速度;3. 守护进程管理镜像和容器,客户端用于交互;4. Namespaces和cgroups实现容器隔离和资源限制;5. 多种网络模式支持容器互联。理解这些核心概念,才能更好地利用Docker。
 centos8重启ssh
Apr 14, 2025 pm 09:00 PM
centos8重启ssh
Apr 14, 2025 pm 09:00 PM
重启 SSH 服务的命令为:systemctl restart sshd。步骤详解:1. 访问终端并连接到服务器;2. 输入命令:systemctl restart sshd;3. 验证服务状态:systemctl status sshd。
 CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系统上进行PyTorch分布式训练,需要按照以下步骤操作:PyTorch安装:前提是CentOS系统已安装Python和pip。根据您的CUDA版本,从PyTorch官网获取合适的安装命令。对于仅需CPU的训练,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,请确保已安装对应版本的CUDA和cuDNN,并使用相应的PyTorch版本进行安装。分布式环境配置:分布式训练通常需要多台机器或单机多GPU。所
