

AI重生:夺回网文界的霸权

重生了,这辈子我重生成了 MidReal。一个可以帮别人写「网文」的 AI 机器人。

这段时间里,我看到很多选题,偶尔也会吐槽一下。竟然有人让我写写 Harry Potter。拜托,难道我还能写的比 J・K・Rowling 更好不成?不过,同人什么的,我还是可以发挥一下的。
经典设定谁会不爱?我就勉为其难地帮助这些用户实现想象吧。
实不相瞒,上辈子我该看的,不该看的,通通看了。就下面这些主题,都是我爱惨了的。

那些你看小说很喜欢却没人写的设定,那些冷门甚至邪门的 cp,都能自产自嗑。

我并不是自吹自擂,但如果你需要我写作的话,我可以确实给你创作出一篇优秀的作品。如果你对结局不满意,或是喜欢角色"中道崩殂",或者甚至是作者在写作过程中出现了困境,都可以放心地交给我,我会为你写出让你满意的内容。

甜文,虐文,脑洞文,每一种都狠狠击中你的爽点。

听完MidReal的自述,你对它了解了吗?
MidReal是一个非常强大的工具,它可以根据用户提供的情景描述,生成对应的小说内容。不仅情节的逻辑和创造力非常出色,它还能在生成过程中生成插图,更形象地描绘你所想象的内容。此外,MidReal还有一个非常亮点的功能,就是它的互动性。你可以选择想要的故事情节进行发展,让整体更加贴合你的需求。无论是写小说还是进行创作,MidReal都是一个非常有用的工具。
在对话框中输入 /start,就可以开始讲述你的故事了,还不快来试试?
MidReal 传送门:https://www.midreal.ai/

MidReal 背后的技术源于这篇论文《FireAct:Toward Language Agent Fine-tuning》。论文作者首次尝试了用 AI 智能体来微调语言模型,发现了诸多优势,由此提出了一种新的智能体架构。
MidReal 就是基于这种架构的,网文才能写得这么好。

论文链接:https://arxiv.org/pdf/2310.05915.pdf
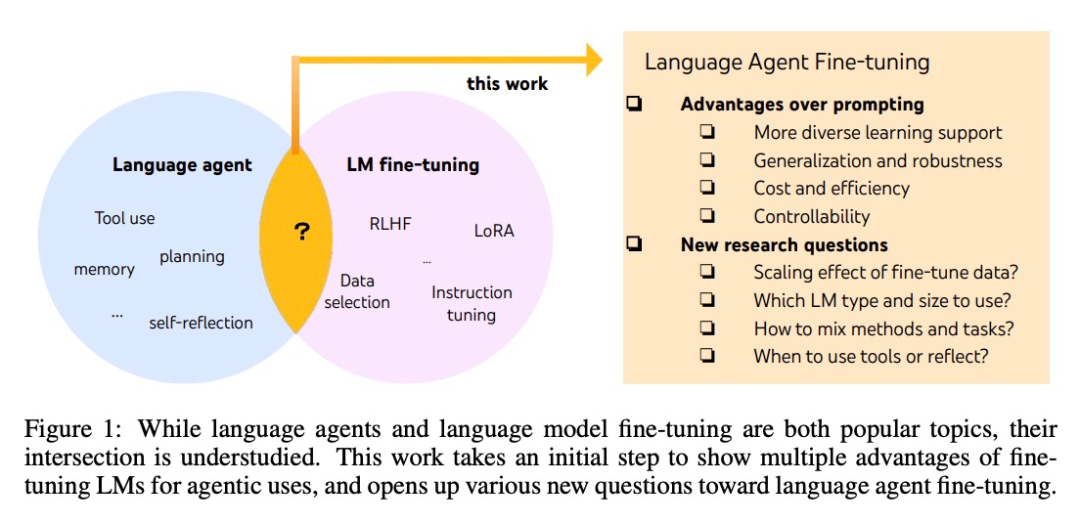
虽然智能体和微调大模型都是最热门的 AI 话题,但它们之间具体有何联系还不清楚。System2 Research、剑桥大学等的多位研究者对这片鲜有人涉足的「学术蓝海」进行了发掘。
AI 智能体的开发通常基于现成的语言模型,但由于语言模型不是作为智能体而开发的,因此,延伸出智能体后,大多数语言模型的性能和稳健性较差。最聪明的智能体只能由 GPT-4 支持,它们也无法避免高成本和延迟,以及可控性低、重复性高等问题。
微调可以用来解决上面的这些问题。也是在这篇文章中,研究者们迈出了更加系统研究语言智能体的第一步。他们提出了 FireAct ,它能够利用多个任务和提示方法生成的智能体「行动轨迹」来微调语言模型,让模型更好地适应不同的任务和情况,提高其整体性能和适用性。
方法简介
该研究主要基于一种流行的 AI 智能体方法:ReAct。一个 ReAct 任务解决轨迹由多个「思考 - 行动 - 观察」回合组成。具体来说,让 AI 智能体完成一个任务,语言模型在其中扮演的角色类似于「大脑」。它为 AI 智能体提供解决问题的「思考」和结构化的动作指示,并根据上下文与不同的工具交互,在这个过程中接收观察到的反馈。
在 ReAct 的基础上,作者提出了 FireAct,如图 2 所示,FireAct 运用强大的语言模型的少样本提示来生成多样化的 ReAct 轨迹,用以微调较小规模的语言模型。与此前类似研究不同的是,FireAct 能够混合多个训练任务和提示方法,大大促进了数据的多样性。
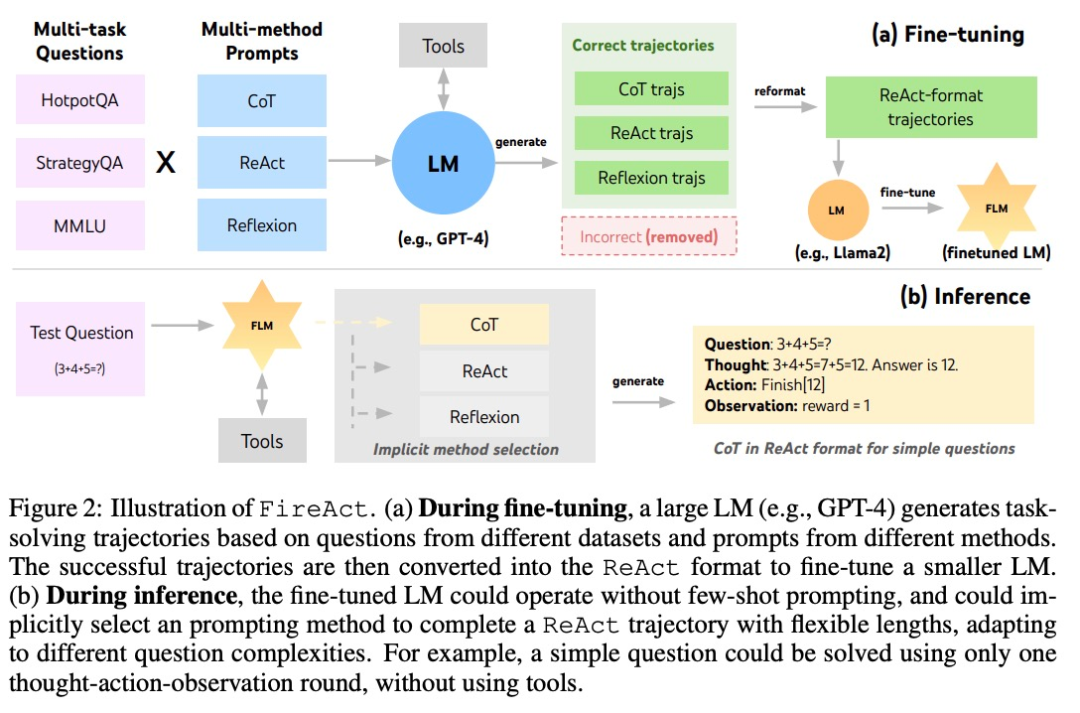
作者还参考了两种与 ReAct 兼容的方法:
- 思维链(CoT)是生成连接问题和答案的中间推理的有效方法。每个 CoT 轨迹可以简化为一个单轮 ReAct 轨迹,其中「思维」代表中间推理,「行动」代表返回答案。在不需要与应用工具交互的情况下,CoT 尤其有用。
- Reflexion 主要遵循 ReAct 轨迹,但加入了额外的反馈和自我反思。该研究中,仅在 ReAct 的第 6 轮和第 10 轮提示进行反思。这样一来,长的 ReAct 轨迹就能为解决当前任务提供策略「支点」,能够帮助模型解决或调整策略。例如搜索「电影名」得不到答案时,应该把搜索的关键词换成「导演」。
在推理过程中,FireAct 框架下的 AI 智能体显著减少了提示词的样本数量需求,推理也更加高效和简便。它能够根据任务的复杂度隐式地选择合适的方法。由于 FireAct 具备更广泛和多样化的学习支持,与传统的提示词微调方法相比,它展现出更强的泛化能力和稳健性。
实验及结果
热点问题回答(HotpotQA)数据集是一个广泛用于自然语言处理研究的数据集,其中包含了一系列与热门话题相关的问题和答案。Bamboogle是一个搜索引擎优化(SEO)游戏,玩家需要通过搜索引擎来解决一系列难题。StrategyQA是一个策略问题回答数据集,其中包含了各种与策略制定和执行相关的问题和答案。MMLU是一个多模态学习数据集,用于研究如何将多种感知模态(如图像、语音等)结合起来进行学习和推理。
- HotpotQA 是一个 QA 数据集,对多步骤推理和知识检索有着更具挑战性的考验。研究者使用 2,000 个随机训练问题进行微调数据整理,并使用 500 个随机 dev 问题进行评估。
- Bamboogle 是一个由 125 个多跳问题组成的测试集,其格式与 HotpotQA 相似,但经过精心设计,以避免直接用谷歌搜索解决问题。
- StrategyQA 是一个需要隐式推理步骤的是 / 否 QA 数据集。
- MMLU 涵盖初等数学、历史和计算机科学等不同领域的 57 个多选 QA 任务。
工具:研究者使用 SerpAPI1 构建了一个谷歌搜索工具,该工具会从「答案框」、「答案片段」、「高亮单词」或「第一个结果片段」中返回第一个存在的条目,从而确保回复简短且相关。他们发现,这样一个简单的工具足以满足不同任务的基本质量保证需求,并提高了微调模型的易用性和通用性。
研究者研究了三个 LM 系列:OpenAI GPT、Llama-2 以及 CodeLlama。
微调方法:研究者在大多数微调实验中使用了低秩自适应(Low-Rank Adaptation,LoRA),但在某些比较中也使用了全模型微调。考虑到语言代理微调的各种基本因素,他们将实验分为三个部分,复杂程度依次增加:
- 在单一任务中使用单一提示方法进行微调;
- 在单一任务中使用多种方法进行微调;
- 在多个任务中使用多种方法进行微调。
1.在单一任务中使用单一提示方法进行微调
研究者探讨了使用来自单一任务(HotpotQA)和单一提示方法(ReAct)的数据进行微调的问题。通过这种简单而可控的设置,他们证实了微调相对于提示的各种优势(性能、效率、稳健性、泛化),并研究了不同 LM、数据大小和微调方法的效果。
如表 2 所示,微调能持续、显着地改善 HotpotQA EM 的提示效果。虽然较弱的LM 从微调中获益更多(例如,Llama-2-7B 提高了77%),但即使是像GPT-3.5 这样强大的LM 也能通过微调将性能提高25%,这清楚地表明了从更多样本中学习的好处。与表 1 中的强提示基线相比,研究者发现经过微调的 Llama-2-13B 优于所有 GPT-3.5 提示方法。这表明对小型开源 LM 进行微调的效果可能优于对更强大的商用 LM 进行提示的效果。
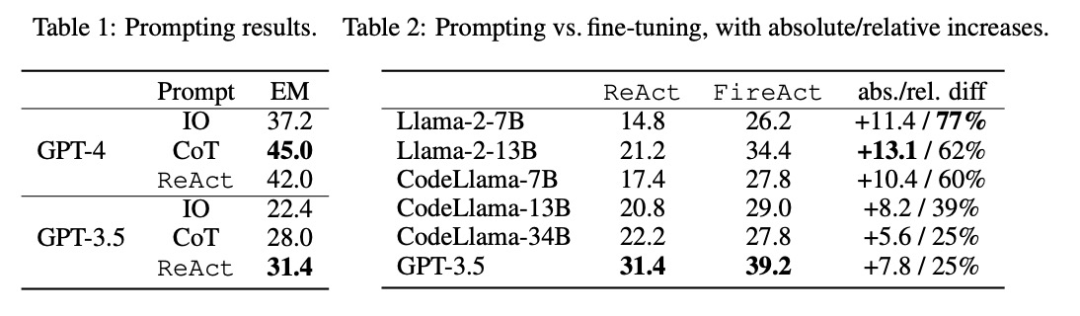
在智能体推理过程中,微调的成本更低,速度更快。由于微调 LM 不需要少量的上下文示例,因此其推理效率更高。例如,表 3 的第一部分比较了微调推理与 shiyongtishideGPT-3.5 推理的成本,发现推理时间减少了 70%,总体推理成本也有所降低。

研究人员对于一种简化且无害的设置进行了考虑,即在搜索API中,有50%的概率返回"None"或者随机的搜索响应,并且询问语言智能体是否仍能够稳健地回答问题。根据表格3第二部分的数据显示,设置为"None"更具有挑战性,它导致ReAct EM下降了33.8%,而FireAct EM只下降了14.2%。这些初步结果表明,多样化的学习支持对于提高稳健性非常重要。
表 3 的第三部分显示了经过微调的和使用提示的 GPT-3.5 在 Bamboogle 上的 EM 结果。虽然经过 HotpotQA 微调或使用提示的 GPT-3.5 都能合理地泛化到 Bamboogle,但前者(44.0 EM)仍然优于后者(40.8 EM),这表明微调具有泛化优势。
2.在单一任务中使用多种方法进行微调
作者将 CoT 和 Reflexion 与 ReAct 集成,测试了对于在单一任务(HotpotQA)中使用多种方法进行微调的性能。对比 FireAct 和既有方法的在各数据集中的得分,他们有以下发现:
首先,研究者通过多种方法对智能体进行微调,以提高其灵活性。在第五张图中,除了定量结果外,研究者还展示了两个示例问题,以说明多方法微调的好处。第一个问题相对简单,但仅使用ReAct微调的智能体搜索了一个过于复杂的查询,导致分散注意力并提供了错误的答案。相比之下,同时使用CoT和ReAct微调的智能体选择依靠内部知识,自信地在一轮内完成了任务。第二个问题更具挑战性,仅使用ReAct微调的智能体未能找到有用的信息。相比之下,同时使用Reflexion和ReAct微调的智能体在遇到困境时进行了反思,并改变了搜索策略,最终得到了正确的答案。选择灵活的解决方案来应对不同的问题,是FireAct相较于其他微调方法的关键优势。

其次,使用多方法微调不同的语言模型将产生不同的影响。如表 4 所示,综合使用多种智能体进行微调并不总是能带来提升,最优的方法组合取决于基础语言模型。例如,对于 GPT-3.5 和 Llama-2 模型,ReAct+CoT 优于 ReAct,但对于 CodeLlama 模型则不同。对于 CodeLlama7/13B,ReAct+CoT+Reflexion 的效果最差,但 CodeLlama-34B 却能取得最好的效果。这些结果表明,还需进一步研究基础语言模型和微调数据之间的相互作用。
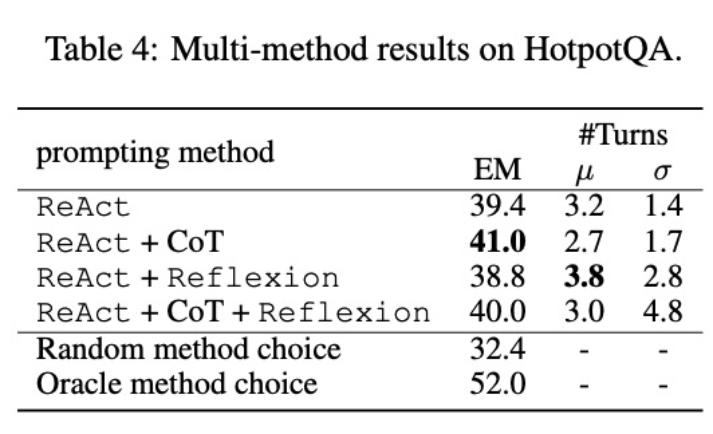
为了进一步了解组合了多种方法的智能体是否能够根据任务选择恰当的解决方案,研究者计算了在推理过程中随机选择方法的得分。该得分(32.4)远低于所有组合了多种方法的智能体,这表明选择解决方案并非易事。然而,每个实例的最佳方案的得分也仅为 52.0,这表明在提示方法选择方面仍有提升空间。
3.在多个任务中使用多种方法进行微调
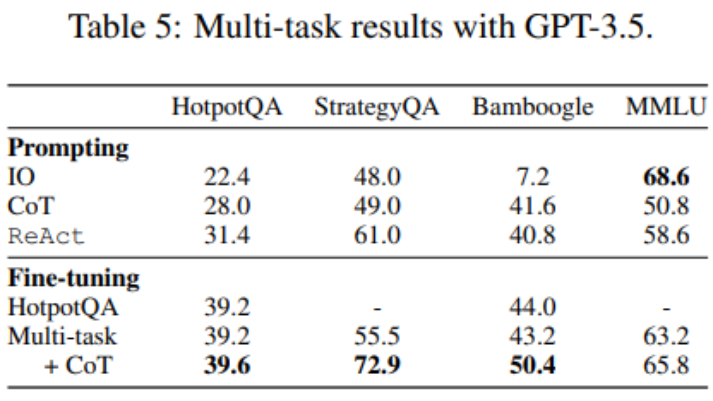
到这里,微调只使用了 HotpotQA 数据,但有关 LM 微调的实证研究表明,混合使用不同的任务会有益处。研究者使用来自三个数据集的混合训练数据对 GPT-3.5 进行微调:HotpotQA(500 个 ReAct 样本,277 个 CoT 样本)、StrategyQA(388 个 ReAct 样本,380 个 CoT 样本)和 MMLU(456 个 ReAct 样本,469 个 CoT 样本)。
如表 5 所示,加入 StrategyQA/MMLU 数据后,HotpotQA/Bamboogle 的性能几乎保持不变。一方面,StrategyQA/MMLU 轨迹包含的问题和工具使用策略大不相同,这使得迁移变得困难。另一方面,尽管分布发生了变化,但加入 StrategyQA/MMLU 并没有影响 HotpotQA/Bamboogle 的性能,这表明微调一个多任务代理以取代多个单任务代理是未来可以发展的方向。当研究者从多任务、单一方法微调切换到多任务、多方法微调时,他们发现所有任务的性能都有所提高,这再次明确了多方法代理微调的价值。
想要了解更多技术细节,请阅读原文。
参考链接:
- https://twitter.com/Tisoga/status/1739813471246786823
- https://www.zhihu.com/people/eyew3g
以上是AI重生:夺回网文界的霸权的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
配置Debian邮件服务器的防火墙是确保服务器安全性的重要步骤。以下是几种常用的防火墙配置方法,包括iptables和firewalld的使用。使用iptables配置防火墙安装iptables(如果尚未安装):sudoapt-getupdatesudoapt-getinstalliptables查看当前iptables规则:sudoiptables-L配置
 Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
在Debian邮件服务器上安装SSL证书的步骤如下:1.安装OpenSSL工具包首先,确保你的系统上已经安装了OpenSSL工具包。如果没有安装,可以使用以下命令进行安装:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私钥和证书请求接下来,使用OpenSSL生成一个2048位的RSA私钥和一个证书请求(CSR):openss
 centos关机命令行
Apr 14, 2025 pm 09:12 PM
centos关机命令行
Apr 14, 2025 pm 09:12 PM
CentOS 关机命令为 shutdown,语法为 shutdown [选项] 时间 [信息]。选项包括:-h 立即停止系统;-P 关机后关电源;-r 重新启动;-t 等待时间。时间可指定为立即 (now)、分钟数 ( minutes) 或特定时间 (hh:mm)。可添加信息在系统消息中显示。
 索尼证实PS5 Pro使用特制GPU 与AMD合作研发AI可能性
Apr 13, 2025 pm 11:45 PM
索尼证实PS5 Pro使用特制GPU 与AMD合作研发AI可能性
Apr 13, 2025 pm 11:45 PM
SonyInteractiveEntertainment(SIE,索尼互动娱乐)首席架构师MarkCerny公开更多次世代主机PlayStation5Pro(PS5Pro)硬体细节,包括性能升级的AMDRDNA2.x架构GPU,以及与AMD合作代号「Amethyst」的机器学习/人工智慧计划。 PS5Pro性能提升的重点仍集中在更强大的GPU、先进的光线追踪与AI驱动的PSSR超解析度功能等3大支柱上。 GPU采用客制化的AMDRDNA2架构,索尼将其命名为RDNA2.x,它拥有部分RDNA3架构才
 CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系统下GitLab的备份与恢复策略为了保障数据安全和可恢复性,CentOS上的GitLab提供了多种备份方法。本文将详细介绍几种常见的备份方法、配置参数以及恢复流程,帮助您建立完善的GitLab备份与恢复策略。一、手动备份利用gitlab-rakegitlab:backup:create命令即可执行手动备份。此命令会备份GitLab仓库、数据库、用户、用户组、密钥和权限等关键信息。默认备份文件存储于/var/opt/gitlab/backups目录,您可通过修改/etc/gitlab
 CentOS上Zookeeper性能调优有哪些方法
Apr 14, 2025 pm 03:18 PM
CentOS上Zookeeper性能调优有哪些方法
Apr 14, 2025 pm 03:18 PM
在CentOS上对Zookeeper进行性能调优,可以从多个方面入手,包括硬件配置、操作系统优化、配置参数调整以及监控与维护等。以下是一些具体的调优方法:硬件配置建议使用SSD硬盘:由于Zookeeper的数据写入磁盘,强烈建议使用SSD以提高I/O性能。足够的内存:为Zookeeper分配足够的内存资源,避免频繁的磁盘读写。多核CPU:使用多核CPU,确保Zookeeper可以并行处理请
 终于改了!微软Windows搜索功能将迎来全新更新
Apr 13, 2025 pm 11:42 PM
终于改了!微软Windows搜索功能将迎来全新更新
Apr 13, 2025 pm 11:42 PM
微软针对Windows搜索功能的改进,目前已在欧盟地区部分WindowsInsider频道展开测试。此前,整合后的Windows搜索功能饱受用户诟病,体验欠佳。此次更新将搜索功能拆分为本地搜索和基于Bing的网络搜索两部分,以提升用户体验。新版搜索界面默认进行本地文件搜索,如需进行网络搜索,需点击“MicrosoftBingWebSearch”标签进行切换。切换后,搜索栏将显示“MicrosoftBingWebSearch:”,用户可在此输入关键词。此举有效避免了本地搜索结果与Bing搜索结果混
 CentOS上如何进行PyTorch模型训练
Apr 14, 2025 pm 03:03 PM
CentOS上如何进行PyTorch模型训练
Apr 14, 2025 pm 03:03 PM
在CentOS系统上高效训练PyTorch模型,需要分步骤进行,本文将提供详细指南。一、环境准备:Python及依赖项安装:CentOS系统通常预装Python,但版本可能较旧。建议使用yum或dnf安装Python3并升级pip:sudoyumupdatepython3(或sudodnfupdatepython3),pip3install--upgradepip。CUDA与cuDNN(GPU加速):如果使用NVIDIAGPU,需安装CUDATool
