

比较Java爬虫框架:哪个是最佳选择?


比较Java爬虫框架:哪个是最佳选择?
在当今信息时代,大量的数据在互联网中不断产生和更新。为了从海量数据中提取有用的信息,爬虫技术应运而生。而在爬虫技术中,Java作为一种强大且广泛应用的编程语言,拥有许多优秀的爬虫框架可供选择。本文将探寻几个常见的Java爬虫框架,并分析它们的特点和适用场景,最终找到最佳的一种。
- Jsoup
Jsoup是一种非常受欢迎的Java爬虫框架,它可以简单、灵活地处理HTML文档。Jsoup提供了一套简洁而强大的API,使得解析、遍历和操作HTML变得非常容易。以下是一个基本的Jsoup示例:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupExample {
public static void main(String[] args) throws Exception {
// 发送HTTP请求获取HTML文档
String url = "http://example.com";
Document doc = Jsoup.connect(url).get();
// 解析并遍历HTML文档
Elements links = doc.select("a[href]");
for (Element link : links) {
System.out.println(link.attr("href"));
}
}
}- Apache Nutch
Apache Nutch是一个开源的网页抓取和搜索引擎软件。它基于Java开发,提供了丰富的功能和灵活的扩展性。Apache Nutch支持大规模的分布式爬取,能够高效地处理大量的网页数据。以下是一个简单的Apache Nutch示例:
import org.apache.nutch.crawl.CrawlDatum;
import org.apache.nutch.crawl.Inlinks;
import org.apache.nutch.fetcher.Fetcher;
import org.apache.nutch.parse.ParseResult;
import org.apache.nutch.protocol.Content;
import org.apache.nutch.util.NutchConfiguration;
public class NutchExample {
public static void main(String[] args) throws Exception {
String url = "http://example.com";
// 创建Fetcher对象
Fetcher fetcher = new Fetcher(NutchConfiguration.create());
// 抓取网页内容
Content content = fetcher.fetch(new CrawlDatum(url));
// 处理网页内容
ParseResult parseResult = fetcher.parse(content);
Inlinks inlinks = parseResult.getInlinks();
// 输出入链的数量
System.out.println("Inlinks count: " + inlinks.getInlinks().size());
}
}- WebMagic
WebMagic是一个开源的Java爬虫框架,它基于Jsoup和HttpClient,并提供了简单易用的API。WebMagic支持多线程并发爬取,可以方便地定义抓取规则和处理抓取结果。以下是一个简单的WebMagic示例:
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
public class WebMagicExample implements PageProcessor {
public void process(Page page) {
// 解析HTML页面
String title = page.getHtml().$("title").get();
// 获取链接并添加新的抓取任务
page.addTargetRequests(page.getHtml().links().regex("http://example.com/.*").all());
// 输出结果
page.putField("title", title);
}
public Site getSite() {
return Site.me().setRetryTimes(3).setSleepTime(1000);
}
public static void main(String[] args) {
Spider.create(new WebMagicExample())
.addUrl("http://example.com")
.addPipeline(new ConsolePipeline())
.run();
}
}综合比较以上几种爬虫框架,它们都有各自的优点和适用场景。Jsoup适用于对HTML解析和操作相对简单的场景;Apache Nutch适用于大规模分布式数据的抓取和搜索;WebMagic则提供了简单易用的API和多线程并发抓取的特性。根据具体的需求和项目特点,选择最适合的框架是关键。
以上是比较Java爬虫框架:哪个是最佳选择?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 小米14 Pro怎么开启nfc功能?
Mar 19, 2024 pm 02:28 PM
小米14 Pro怎么开启nfc功能?
Mar 19, 2024 pm 02:28 PM
如今手机的性能和功能越来越强大,几乎所有手机都配备了便捷的NFC功能,方便用户进行移动支付和身份认证。然而,有些小米14Pro的用户可能不清楚如何启用NFC功能。接下来,让我详细向大家介绍一下。小米14Pro怎么开启nfc功能?步骤一:打开手机的设置菜单。步骤二:找到并点击“连接和共享”或“无线和网络”选项。步骤三:在连接和共享或无线和网络菜单中,找到并点击“NFC和支付”。步骤四:找到并点击“NFC开关”。一般情况下,默认是关闭的状态。步骤五:在NFC开关页面上,点击开关按钮,将其切换为开启状
 华为 Pocket2怎么隔空刷抖音?
Mar 18, 2024 pm 03:00 PM
华为 Pocket2怎么隔空刷抖音?
Mar 18, 2024 pm 03:00 PM
隔空滑动屏幕是华为的一项功能,在华为mate60系列中可以说是备受好评,这个功能是通过利用手机上的激光感应器和前置摄像头的3D深感摄像头,来完成一系列不需要触碰屏幕的功能,比如说隔空刷抖音,但是华为Pocket2应该要怎么隔空刷抖音呢?华为Pocket2怎么隔空截图?1、打开华为Pocket2的设置2、然后选择【辅助功能】。3、点击打开【智慧感知】。4、打开【隔空滑动屏幕】、【隔空截屏】、【隔空按压】开关就可以了。5、在使用的时候,需要再距离屏幕20~40CM处,张开手掌,待屏幕上出现手掌图标,
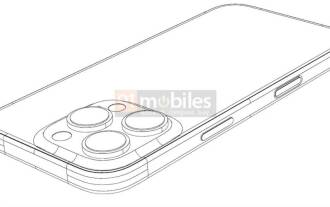 iPhone 16 Pro CAD 图曝光 加入第二个新按键
Mar 09, 2024 pm 09:07 PM
iPhone 16 Pro CAD 图曝光 加入第二个新按键
Mar 09, 2024 pm 09:07 PM
iPhone16Pro的CAD文件已经曝光,设计与先前的传闻一致。去年秋天,iPhone15Pro新增了Action按钮,而今年秋天,Apple似乎计划对这款硬件的尺寸进行微小的调整。加入Capture按钮据传言,iPhone16Pro可能会新增第二个新按钮,这将是继去年之后连续第二年增加新按钮。传闻称新的Capture按钮将被设置在iPhone16Pro的右下侧,这一设计有望让相机控制更加便捷,同时还能让Action按钮用于其他功能。这个按钮将不再仅仅是一个普通的快门按钮。关于相机,从目前iP
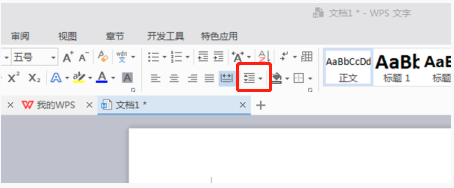 WPS Word怎么设置行距让文档更工整
Mar 20, 2024 pm 04:30 PM
WPS Word怎么设置行距让文档更工整
Mar 20, 2024 pm 04:30 PM
WPS是我们常用的办公软件,在进行长篇文章的编辑时,经常会因为字体太小而看不清楚,所以会对字体和整个文档进行调整。例如:把文档进行行距的调整,会让整个文档变得非常清晰,我建议各位小伙伴们都要学会这个操作步骤,今天就分享给大家,具体的操作步骤如下,快来看一看!打开要调整的WPS文本文件,在【开始】菜单中找到段落设置工具栏,你会看到行距设置小图标(如图中红色线圈所示)。2、点击行距设置右下角的小倒三角形,会出现相应的行距数值,可以选择1~3倍行距(如图箭头所示)。3、或者点击鼠标右键点击段落,就会出
 microsoft teams怎么切换语言
Feb 23, 2024 pm 09:00 PM
microsoft teams怎么切换语言
Feb 23, 2024 pm 09:00 PM
microsoftteams中有很多语言可以选择,那么怎么切换语言呢?用户们需要点击菜单,然后找到设置,在里面选择通用,然后点击语言,选择语言后保存就可以了,这篇切换语言方法介绍就能够告诉大家具体的内容,下面就是详细的介绍,赶紧看看吧!microsoftteams怎么切换语言答:在设置-通用-语言中选择具体过程:1、首先点击头像边上的三个点进入设置。2、之后点击里面的通用选项。3、之后点击语言,在里面下拉可以看到更多语言。4、最后点击保存和重启就可以了。
 红米Redmi K70E如何设置自定义来电铃声?
Feb 24, 2024 am 10:00 AM
红米Redmi K70E如何设置自定义来电铃声?
Feb 24, 2024 am 10:00 AM
红米RedmiK70E无疑是非常出色的,作为一款价格刚刚达到两千元的手机,红米RedmiK70E可以说是同档位性价比最高的手机之一了。很多追求性价比的用户都购买了这款手机,体验红米RedmiK70E上的各种功能。那么红米RedmiK70E如何设置自定义来电铃声呢?红米RedmiK70E怎么设置自定义来电铃声?要设置红米RedmiK70E的自定义来电铃声,可以按照以下步骤操作:打开手机的设置应用,在设置应用中找到“声音和震动”或“声音”选项,点击其中的“来电铃声”或“电话铃声”选项。在来电铃声设置
 TrendX 研究院:Merlin Chain 项目分析及生态盘点
Mar 24, 2024 am 09:01 AM
TrendX 研究院:Merlin Chain 项目分析及生态盘点
Mar 24, 2024 am 09:01 AM
根据3月2日数据统计,比特币二层网络MerlinChain总TVL已达30亿美元。其中比特币生态资产占比达90.83%,包括价值15.96亿美元的BTC以及4.04亿美元的BRC-20资产等。上一个月,MerlinChain在开启质押活动14天内,其TVL总额就已经达到了19.7亿美元,超过了去年11月份上线也是最近同样引人注目的Blast。2月26日,MerlinChain生态内的NFT总价值超过了4.2亿美元,成为除以太坊以外NFT市值最高的公链项目。项目简介MerlinChain是OKX支
 PHP7.2和5版本对比及优劣势分析
Feb 27, 2024 am 10:51 AM
PHP7.2和5版本对比及优劣势分析
Feb 27, 2024 am 10:51 AM
PHP7.2和5版本对比及优劣势分析PHP是一种极其流行的服务器端脚本语言,被广泛应用于Web开发中。然而,PHP不断在不同的版本中进行更新和改进,以满足不断变化的需求。目前,PHP7.2是最新版本,它和之前的PHP5版本相比有许多值得关注的差异和改进。在本文中,我们将对PHP7.2和PHP5版本进行对比,分析它们的优劣势,并提供具体的代码示例。一、性能PH
