

清华大学新方法成功定位精确视频片段!SOTA被超越且已开源

只需一句话描述,就能在一大段视频中定位到对应片段!
比如描述“一个人一边下楼梯一边喝水”,通过视频画面和脚步声的匹配,新方法一下子就能揪出对应起止时间戳:

就连“大笑”这种语义难理解型的,也能准确定位:

方法名为自适应双分支促进网络(ADPN),由清华大学研究团队提出。
具体来说,ADPN是用来完成一个叫做视频片段定位(Temporal Sentence Grounding,TSG)的视觉-语言跨模态任务,也就是根据查询文本从视频中定位到相关片段。
ADPN的特点在于能够高效利用视频中视觉和音频模态的一致性与互补性来增强视频片段定位性能。
相较其他利用音频的TSG工作PMI-LOC、UMT,ADPN方法从音频模态获取了更显着地性能提升,多项测试拿下新SOTA。
目前该工作已经被ACM Multimedia 2023接收,且已完全开源。

一起来看看ADPN究竟是个啥~
一句话定位视频片段
视频片段定位(Temporal Sentence Grounding,TSG)是一项重要的视觉-语言跨模态任务。
它的目的是根据自然语言查询,在一个未剪辑的视频中找到与之语义匹配的片段的起止时间戳,它要求方法具备较强的时序跨模态推理能力。
然而,大多数现有的TSG方法只考虑了视频中的视觉信息,如RGB、光流(optical flows)、深度(depth)等,而忽略了视频中天然伴随的音频信息。
音频信息往往包含丰富的语义,并且与视觉信息存在一致性和互补性,如下图所示,这些性质会有助于TSG任务。
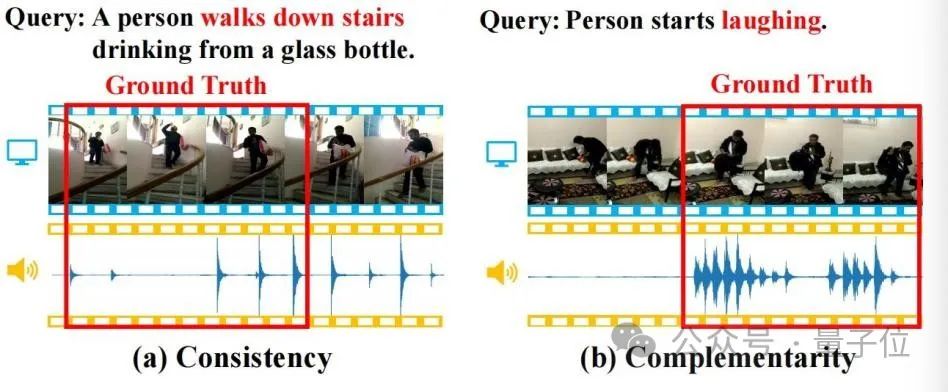
△图1
(a)一致性:视频画面和脚步声一致地匹配了查询中的“走下楼梯”的语义;(b)互补性:视频画面难以识别出特定行为来定位查询中的“笑”的语义,但是笑声的出现提供了强有力的互补定位线索。
因此研究人员深入研究了音频增强的视频片段定位任务(Audio-enhanced Temporal Sentence Grounding,ATSG),旨在更优地从视觉与音频两种模态中捕获定位线索,然而音频模态的引入也带来了如下挑战:
- 音频和视觉模态的一致性和互补性是与查询文本相关联的,因此捕获视听一致性与互补性需要建模文本-视觉-音频三模态的交互。
- 音频和视觉间存在显着的模态差异,两者的信息密度和噪声强度不同,这会影响视听学习的性能。
为了解决上述挑战,研究人员提出了一种新颖的ATSG方法“自适应双分支促进网络”(Adaptive Dual-branch Prompted Network,ADPN)。
通过一种双分支的模型结构设计,该方法能够自适应地建模音频和视觉之间的一致性和互补性,并利用一种基于课程学习的去噪优化策略进一步消除音频模态噪声的干扰,揭示了音频信号对于视频检索的重要性。
ADPN的总体结构如下图所示:
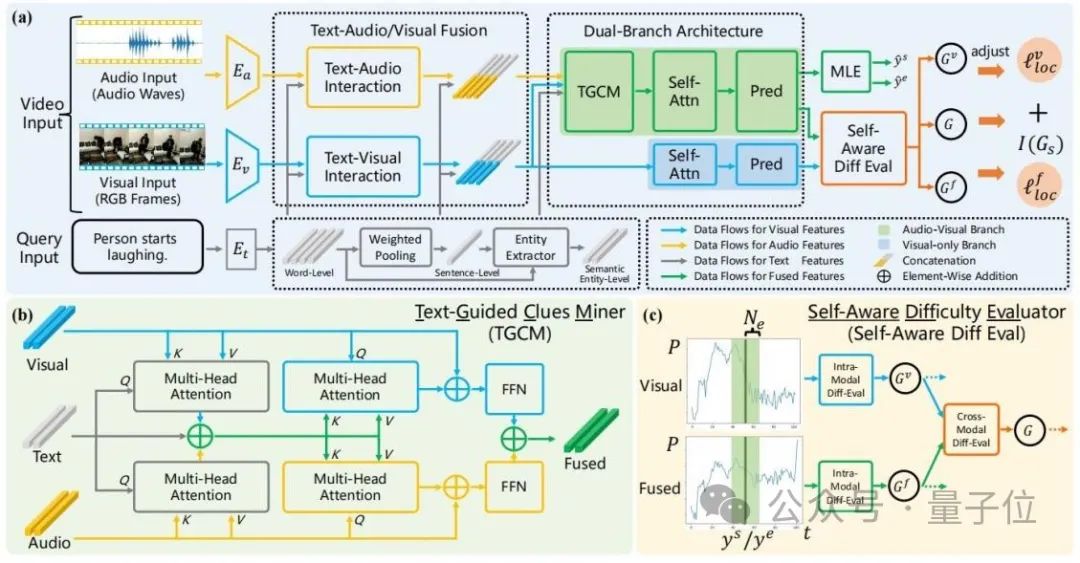
△图2:自适应双分支促进网络(ADPN)总体示意图
它主要包含三个设计:
1、双分支网络结构设计
考虑到音频的噪声更加明显,且对于TSG任务而言,音频通常存在更多冗余信息,因此音频和视觉模态的学习过程需要赋予不同的重要性,因此本文涉及了一个双分支的网络结构,在利用音频和视觉进行多模态学习的同时,对视觉信息进行强化。
具体地,参见图2(a),ADPN同时训练一个只使用视觉信息的分支(视觉分支)和一个同时使用视觉信息和音频信息的分支(联合分支)。
两个分支拥有相似的结构,其中联合分支增加了一个文本引导的线索挖掘单元(TGCM)建模文本-视觉-音频模态交互。训练过程两个分支同时更新参数,推理阶段使用联合分支的结果作为模型预测结果。
2、文本引导的线索挖掘单元(Text-Guided Clues Miner,TGCM)
考虑到音频与视觉模态的一致性与互补性是以给定的文本查询作为条件的,因此研究人员设计了TGCM单元建模文本-视觉-音频三模态间的交互。
参考图2(b),TGCM分为”提取“和”传播“两个步骤。
首先以文本作为查询条件,从视觉和音频两种模态中提取关联的信息并集成;然后再以视觉与音频各自模态作为查询条件,将集成的信息通过注意力传播到视觉与音频各自的模态,最终再通过FFN进行特征融合。
3、课程学习优化策略
研究人员观察到音频中含有噪声,这会影响多模态学习的效果,于是他们将噪声的强度作为样本难度的参考,引入课程学习(Curriculum Learning,CL)对优化过程进行去噪,参考图2(c)。
他们根据两个分支的预测输出差异来评估样本的难度,认为过于难的样本大概率表示其音频含有过多的噪声而不适于TSG任务,于是根据样本难度的评估分数对训练过程的损失函数项进行重加权,旨在丢弃音频的噪声引起的不良梯度。
(其余的模型结构与训练细节请参考原文。)
多项测试新SOTA
研究人员在TSG任务的benchmark数据集Charades-STA和ActivityNet Captions上进行实验评估,与baseline方法的比较如表1所示。
ADPN方法能够取得SOTA性能;特别地,相较其他利用音频的TSG工作PMI-LOC、UMT,ADPN方法从音频模态获取了更显著地性能提升,说明了ADPN方法利用音频模态促进TSG的优越性。
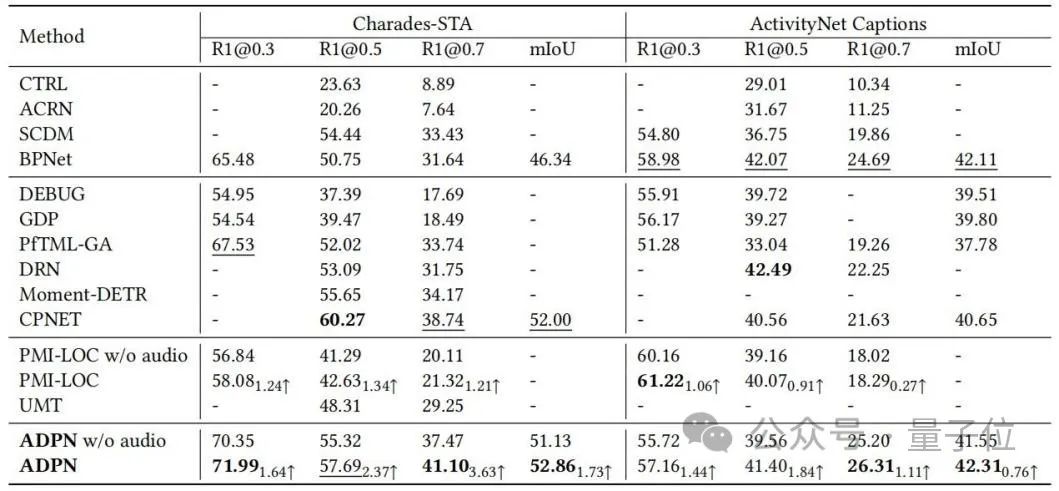
△表1:Charades-STA与ActivityNet Captions上实验结果
研究人员进一步通过消融实验展示了ADPN中不同的设计单元的有效性,如表2所示。
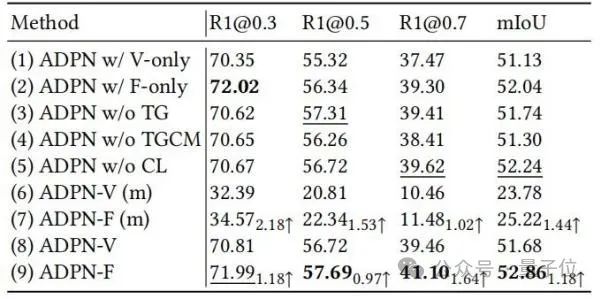
△表2:Charades-STA上消融实验
研究人员选取了一些样本的预测结果进行了可视化,并且绘制了TGCM中”提取“步骤中的”文本 to 视觉“(T→V)和”文本 to 音频“(T→A)注意力权重分布,如图3所示。
可以观察到音频模态的引入改善了预测结果。从“Person laughs at it”的案例中,可以看到T→A的注意力权重分布更接近Ground Truth,纠正了T→V的权重分布对模型预测的错误引导。
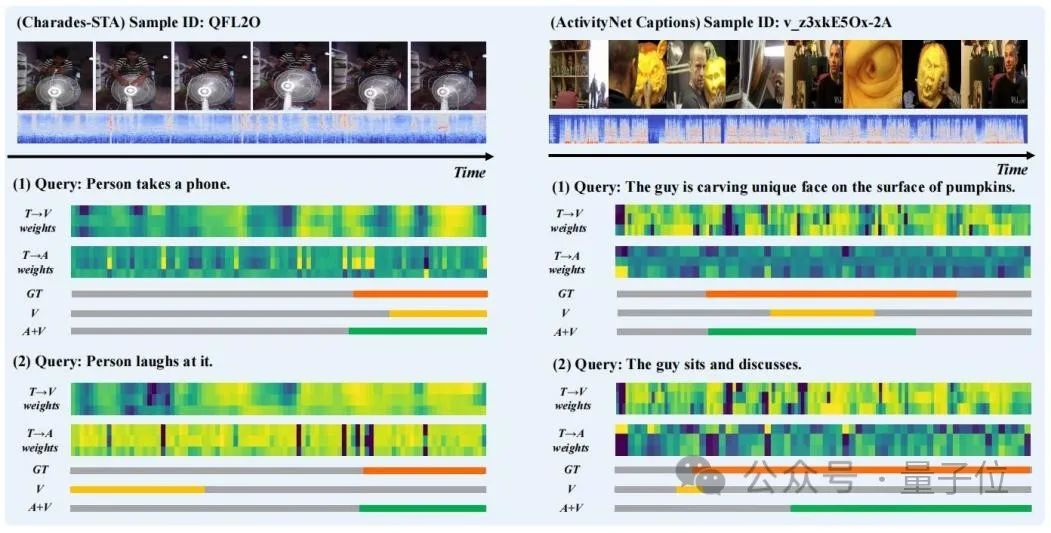
△图3:案例展示
总的来说,本文研究人员提出了一种新颖的自适应双分支促进网络(ADPN)来解决音频增强的视频片段定位(ATSG)问题。
他们设计了一个双分支的模型结构,联合训练视觉分支和视听联合分支,以解决音频和视觉模态之间的信息差异。
他们还提出了一种文本引导的线索挖掘单元(TGCM),用文本语义作为指导来建模文本-音频-视觉交互。
最后,研究人员设计了一种基于课程学习的优化策略来进一步消除音频噪音,以自感知的方式评估样本难度作为噪音强度的度量,并自适应地调整优化过程。
他们首先在ATSG中深入研究了音频的特性,更好地提升了音频模态对性能的提升作用。
未来,他们希望为ATSG构建更合适的评估基准,以鼓励在这一领域进行更深入的研究。
论文链接:https://dl.acm.org/doi/pdf/10.1145/3581783.3612504
仓库链接:https://github.com/hlchen23/ADPN-MM
以上是清华大学新方法成功定位精确视频片段!SOTA被超越且已开源的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
MySQL启动失败的原因有多种,可以通过检查错误日志进行诊断。常见原因包括端口冲突(检查端口占用情况并修改配置)、权限问题(检查服务运行用户权限)、配置文件错误(检查参数设置)、数据目录损坏(恢复数据或重建表空间)、InnoDB表空间问题(检查ibdata1文件)、插件加载失败(检查错误日志)。解决问题时应根据错误日志进行分析,找到问题的根源,并养成定期备份数据的习惯,以预防和解决问题。
 mysql 能返回 json 吗
Apr 08, 2025 pm 03:09 PM
mysql 能返回 json 吗
Apr 08, 2025 pm 03:09 PM
MySQL 可返回 JSON 数据。JSON_EXTRACT 函数可提取字段值。对于复杂查询,可考虑使用 WHERE 子句过滤 JSON 数据,但需注意其性能影响。MySQL 对 JSON 的支持在不断增强,建议关注最新版本及功能。
 了解 ACID 属性:可靠数据库的支柱
Apr 08, 2025 pm 06:33 PM
了解 ACID 属性:可靠数据库的支柱
Apr 08, 2025 pm 06:33 PM
数据库ACID属性详解ACID属性是确保数据库事务可靠性和一致性的一组规则。它们规定了数据库系统处理事务的方式,即使在系统崩溃、电源中断或多用户并发访问的情况下,也能保证数据的完整性和准确性。ACID属性概述原子性(Atomicity):事务被视为一个不可分割的单元。任何部分失败,整个事务回滚,数据库不保留任何更改。例如,银行转账,如果从一个账户扣款但未向另一个账户加款,则整个操作撤销。begintransaction;updateaccountssetbalance=balance-100wh
 掌握SQL LIMIT子句:控制查询中的行数
Apr 08, 2025 pm 07:00 PM
掌握SQL LIMIT子句:控制查询中的行数
Apr 08, 2025 pm 07:00 PM
SQLLIMIT子句:控制查询结果行数SQL中的LIMIT子句用于限制查询返回的行数,这在处理大型数据集、分页显示和测试数据时非常有用,能有效提升查询效率。语法基本语法:SELECTcolumn1,column2,...FROMtable_nameLIMITnumber_of_rows;number_of_rows:指定返回的行数。带偏移量的语法:SELECTcolumn1,column2,...FROMtable_nameLIMIToffset,number_of_rows;offset:跳过
 如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL数据库性能优化指南在资源密集型应用中,MySQL数据库扮演着至关重要的角色,负责管理海量事务。然而,随着应用规模的扩大,数据库性能瓶颈往往成为制约因素。本文将探讨一系列行之有效的MySQL性能优化策略,确保您的应用在高负载下依然保持高效响应。我们将结合实际案例,深入讲解索引、查询优化、数据库设计以及缓存等关键技术。1.数据库架构设计优化合理的数据库架构是MySQL性能优化的基石。以下是一些核心原则:选择合适的数据类型选择最小的、符合需求的数据类型,既能节省存储空间,又能提升数据处理速度
 mysql 主键可以为 null
Apr 08, 2025 pm 03:03 PM
mysql 主键可以为 null
Apr 08, 2025 pm 03:03 PM
MySQL 主键不可以为空,因为主键是唯一标识数据库中每一行的关键属性,如果主键可以为空,则无法唯一标识记录,将会导致数据混乱。使用自增整型列或 UUID 作为主键时,应考虑效率和空间占用等因素,选择合适的方案。
 Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
直接通过 Navicat 查看 MongoDB 密码是不可能的,因为它以哈希值形式存储。取回丢失密码的方法:1. 重置密码;2. 检查配置文件(可能包含哈希值);3. 检查代码(可能硬编码密码)。
 使用 Prometheus MySQL Exporter 监控 MySQL 和 MariaDB Droplet
Apr 08, 2025 pm 02:42 PM
使用 Prometheus MySQL Exporter 监控 MySQL 和 MariaDB Droplet
Apr 08, 2025 pm 02:42 PM
有效监控 MySQL 和 MariaDB 数据库对于保持最佳性能、识别潜在瓶颈以及确保整体系统可靠性至关重要。 Prometheus MySQL Exporter 是一款强大的工具,可提供对数据库指标的详细洞察,这对于主动管理和故障排除至关重要。
