

NeRF在BEV泛化性能方面的突破:首个跨域开源代码成功实现Sim2Real

写在前面&笔者的个人总结
鸟瞰图(Bird eye's view, BEV)检测是一种通过融合多个环视摄像头来进行检测的方法。目前算法大部分算法都是在相同数据集训练并且评测,这导致了这些算法过拟合于不变的相机内参(相机类型)和外参(相机摆放方式)。本文提出了一种基于隐式渲染的BEV检测框架,能够解决未知域的物体检测问题。该框架通隐式渲染来建立物体3D位置和单个视图的透视位置关系,这可以用来纠正透视偏差。此方法在领域泛化(DG)和无监督领域适应(UDA)方面取得了显着的性能提升。该方法首次尝试了只用虚拟数据集上进行训练在真实场景下进行评测BEV检测,可以打破虚实之间的壁垒完成闭环测试。
- 论文链接:https://arxiv.org/pdf/2310.11346.pdf
- 代码链接:https://github.com/EnVision-Research/Generalizable-BEV

BEV检测域泛化问题背景
多相机检测是指利用多台摄像机对三维空间中的物体进行检测和定位的任务。通过结合来自不同视点的信息,多摄像头3D目标检测可以提供更准确和鲁棒的目标检测结果,特别是在某些视点的目标可能被遮挡或部分可见的情况下。近年来,鸟瞰图检测(Bird eye's view, BEV)方法在多相机检测任务中得到了极大的关注。尽管这些方法在多相机信息融合方面具有优势,但当测试环境与训练环境存在显着差异时,这些方法的性能可能会严重下降。
目前,大多数BEV检测算法都是在相同的数据集上进行训练和评估,这导致这些算法对相机内外参数和城市道路条件的变化过于敏感,过拟合问题严重。然而,在实际应用中,BEV检测算法常常需要适应不同的新车型和新摄像头,这导致这些算法失效。因此,研究BEV检测的泛化性非常重要。 此外,闭环仿真对于无人驾驶也非常重要,但目前只能在虚拟引擎(如Carla)中进行评估。因此,有必要解决虚拟引擎和真实场景之间的域差异问题
域泛化(domain generalization, DG)和无监督域自适应(unsupervised domain adaptation, UDA)是缓解分布偏移的两个有前途的方向。 DG方法经常解耦和消除特定于领域的特征,从而提高不可见领域的泛化性能。对于UDA,最近的方法通过生成伪标签或潜在特征分布对齐来缓解域偏移。然而,如果不使用来自不同视点、相机参数和环境的数据,纯视觉感知学习与视角和环境无关的特征是非常具有挑战性的。
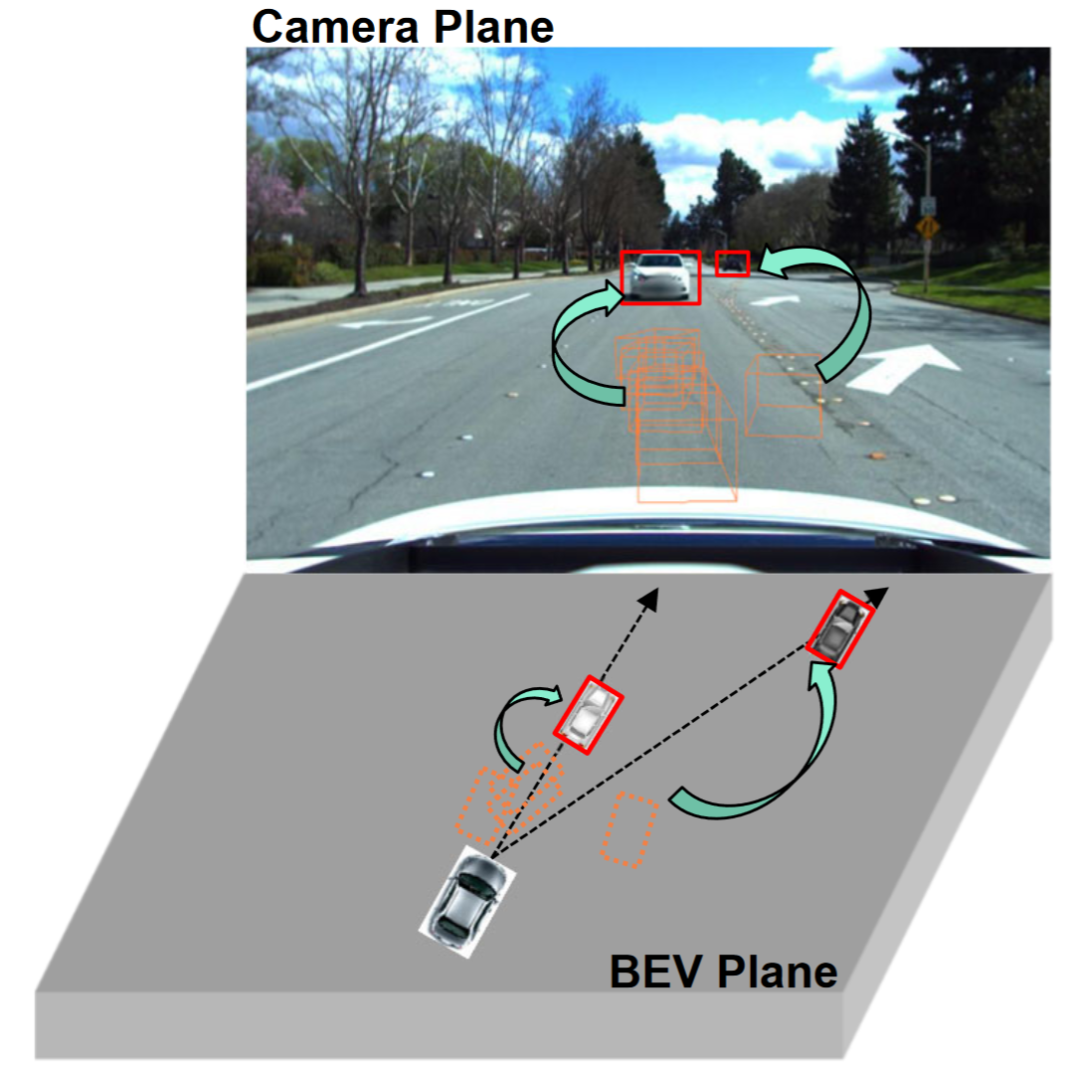
观察表明单视角(相机平面)的2D检测往往比多视角的3D目标检测具有更强的泛化能力,如图所示。一些研究已经探索了将2D检测整合到BEV检测中,例如将2D信息融合到3D检测器中或建立2D-3D一致性。二维信息融合是一种基于学习的方法,而不是一种机制建模方法,并且仍然受到域迁移的严重影响。现有的2D-3D一致性方法是将3D结果投影到二维平面上并建立一致性。这种约束可能损害目标域中的语义信息,而不是修改目标域的几何信息。此外,这种2D-3D一致性方法使得所有检测头的统一方法具有挑战性。
本论文的的贡献总结
- 本论文提出了一种基于视角去偏的广义BEV检测框架,该框架不仅可以帮助模型学习源域中的视角和上下文不变特征,还可以利用二维检测器进一步纠正目标域中的虚假几何特征。
- 本文首次尝试在BEV检测上研究无监督域自适应,并建立了一个基准。在UDA和DG协议上都取得了最先进的结果。
- 本文首次探索了在没有真实场景注释的虚拟引擎上进行训练,以实现真实世界的BEV检测任务。
BEV检测域泛化问题定义
问题定义
研究主要围绕增强BEV检测的泛化。为了实现这一目标,本文探索了两个广泛具有实际应用价值的协议,即域泛化(domain generalization, DG)和无监督域自适应(unsupervised domain adaptation, UDA):
BEV检测的域泛化(DG):在已有的数据集(源域)训练一个BEV检测算法,提升在具有在未知数据集(目标域)的检测性能。例如,在特定车辆或者场景下训练一个BEV检测模型,能够直接泛化到各种不同的车辆和场景。
BEV检测的无监督域自适应(UDA):在已有的数据集(源域)训练一个BEV检测算法,并且利用目标域的无标签数据来提高检测性能。例如,在一个新的车辆或者城市,只需要采集一些无监督数据就可以提高模型在新车和新环境的性能。值得一提的是DG和UDA的唯一区别是是否可以利用目标域的未标记数据。
视角偏差定义
为了检测物体的未知L=[x,y,z],大部分BEV检测会有关键的两部(1)获取不同视角的图像特征;(2)融合这些图像特征到BEV空间并且得到最后的预测结果:
上面公式描述,域偏差可能来源于特征提取阶段或者BEV融合阶段。然后本文进行了在附录进行了推到,得到了最后3D预测结果投影到2D结果的视角偏差为:
其中k_u, b_u, k_v和b_v与BEV编码器的域偏置有关,d(u,v)为模型的最终预测深度信息。c_u和c_v表示相机光学中心在uv图像平面上的坐标。上面等式提供了几个重要的推论:(1)最终位置偏移的存在会导致视角偏差,这表明优化视角偏差有助于缓解域偏移。(2)即使是相机光心射线上的点在单个视角成像平面上的位置也会发生移位。
直观地说,域偏移改变了BEV特征的位置,这是由于训练数据视点和相机参数有限而产生的过拟合。为了缓解这个问题,从BEV特征中重新渲染新的视图图像是至关重要的,从而使网络能够学习与视角和环境无关的特征。鉴于此,本研究旨在解决不同渲染视点相关的视角偏差,以提高模型的泛化能力
详解PD-BEV算法
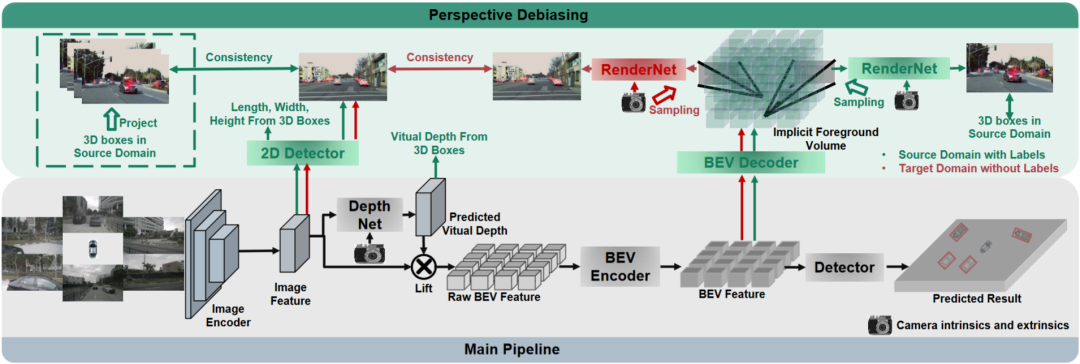
PD-BEV一共分为三个部分:语义渲染,源域去偏见和目标域去偏见如图1所示。语义渲染是阐述如如何通过BEV特征建立2D和3D的透视关系。源域去偏见是描述在源域如何通过语义渲染来提高模型泛化能力。目标域去偏见是描述在目标域利用无标住的数据通过语义渲染来提高模型泛化能力。
语义渲染
由于许多算法会将BEV体积压缩成二维特征,因此我们首先使用BEV解码器将BEV特征转化为一个体积:
上面的公式其实就是对BEV平面进行了提升,增加了一个高度维度。然后通过相机的内外参数就可以在这个Volume采样成为一个2D的特征图,然后这个2D特征图和相机内外参数送到一个RenderNet里面来预测对应视角的heatmap和物体的属性。通过这样的类似于Nerf的操作就可以建立起2D和3D的桥梁。
源域去偏见
要提高模型的泛化性能,有几个关键点需要在源域进行改进。首先,可以利用源域的3D框来监控新渲染视图的热图和属性,以减少视角偏差。其次,可以利用归一化深度信息来帮助图像编码器更好地学习几何信息。这些改进措施将有助于提高模型的泛化性能
视角语义监督:基于语义渲染,热图和属性从不同的角度渲染(RenderNet的输出)。同时,随机采样一个相机内外参数,将物体的方框从3D坐标利用这些内外参数投射到二维相机平面内。然后对投影后的2Dbox与渲染的结果使用Focal loss和L1 loss进行约束:
通过这项操作,可以减少对相机内外参数的过度拟合,并提高对新视角的鲁棒性。值得一提的是,此论文将监督学习从RGB图像转换为物体中心的热图,以避免在无人驾驶领域中缺乏新视角RGB监督的缺点
几何监督:提供明确的深度信息可以有效地提高多相机3D目标检测的性能。然而,网络预测的深度倾向于过拟合内在参数。因此,这个论文借鉴了一种虚拟深度的方式:
其中BCE()表示二进制交叉熵损失,D_{pre}表示DepthNet的预测深度。f_u和f_v分别为像平面的u和v焦距,U为常数。值得注意的是,这里的深度是使用3D框而不是点云提供的前景深度信息。通过这样做,DepthNet更有可能专注于前景物体的深度。最后,当使用实际深度信息将语义特征提升到BEV平面时,将虚拟深度转换回实际深度。
目标域去偏见
在目标域就没有标注了,所以就不能用3D box监督来提高模型的泛化能力了。所以这个论文阐述说,2D检测的结果比起3D结果更加鲁棒。所以这个论文利用在源域中的2D预训练的检测器作为渲染后的视角的的监督,并且还利用了伪标签的机制:
这个操作可以有效地利用精确的二维检测来校正BEV空间中的前景目标位置,这是一种目标域的无监督正则化。为了进一步增强二维预测的校正能力,采用伪方法增强预测热图的置信度。这个论文在3.2和补充材料里给出了数学证明说明了3D结果在2D投影误差的原因。以及阐述了为什么通过这种方式可以去偏见,详细的可以参考原论文。
总体的监督
尽管在本文中添加了一些网络以帮助训练,但这些网络在推理过程中是不必要的。换句话说,本文的方法适用于大多数BEV检测方法学习透视不变特征的情况。为了测试我们的框架有效性,我们选择使用BEVDepth进行评估。在源域上使用BEVDepth的原始损失作为主要的三维检测监督。总之,算法的最终损失是:
跨域实验结果
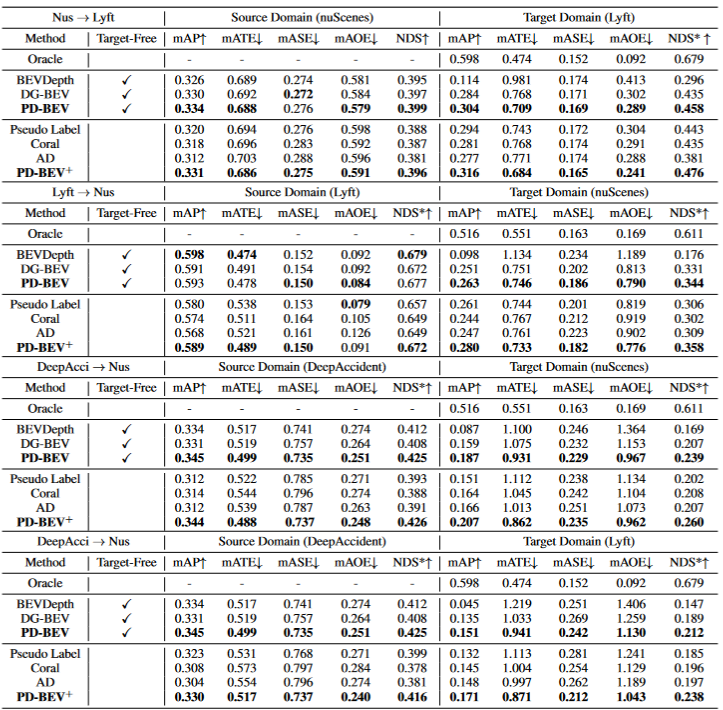
表格1展示了不同方法在领域泛化(DG)和无监督领域适应(UDA)协议下的效果比较。其中,Target-Free表示DG协议,Pseudo Label、Coral和AD是一些常见的UDA方法。从图表中可以看出,这些方法在目标域上都取得了显著的改进。这表明语义渲染作为一个桥梁可以帮助学习针对域移位的透视不变特征。此外,这些方法并没有牺牲源域的性能,甚至在大多数情况下还有一些改进。需要特别提到的是,DeepAccident是基于Carla虚拟引擎开发的,经过在DeepAccident上的训练后,该算法取得了令人满意的泛化能力。此外,还测试了其他BEV检测方法,但在没有特殊设计的情况下,它们的泛化性能非常差。为了进一步验证利用目标域无监督数据集的能力,还建立了一个UDA基准,并在DG-BEV上应用了UDA方法(包括Pseudo Label、Coral和AD)。实验证明,这些方法在性能上有显著的提升。隐式渲染充分利用具有更好泛化性能的二维探测器来校正三维探测器的虚假几何信息。此外,发现大多数算法倾向于降低源域的性能,而本文方法相对温和。值得一提的是,AD和Coral在从虚拟数据集转移到真实数据集时表现出显着的改进,但在真实测试中却表现出性能下降。这是因为这两种算法是为解决风格变化而设计的,但在样式变化很小的场景中,它们可能会破坏语义信息。至于Pseudo Label算法,它可以通过在一些相对较好的目标域中增加置信度来提高模型的泛化性能,但盲目地增加目标域中的置信度实际上会使模型变得更差。实验结果证明了本文算法在DG和UDA方面取得了显著的性能提升
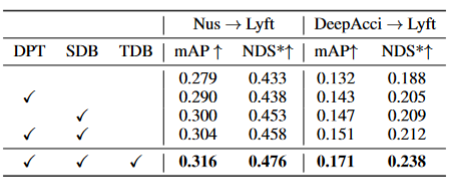
在三个关键组件上的消融实验结果展示在表格2中:2D检测器预训练(DPT)、源域去偏(SDB)和目标域去偏(TDB)。实验结果表明,每个组件都取得了改进,其中SDB和TDB表现出相对显著的效果
表格3展示了算法算法可以迁移到BEVFormer和FB-OCC算法上。因为这个算法是只需要对图像特征和BEV特征加上额外的操作,所以可以对有BEV特征的算法都有提升作用。
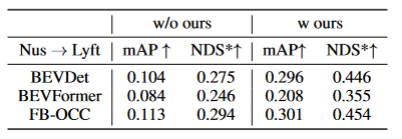
图5展示了检测到的未标记物体。第一行是标签的3D框,第二行是算法的检测结果。蓝色框表示算法可以检测到一些未标记的框。这表明方法在目标域甚至可以检测到没有标记的样本,例如过远或者街道两侧建筑内的车辆。

总结
本文提出了一种基于透视去偏的通用多摄像头3D物体检测框架,能够解决未知领域的物体检测问题。该框架通过将3D检测结果投影到2D相机平面,并纠正透视偏差,实现一致和准确的检测。此外,该框架还引入了透视去偏策略,通过渲染不同视角的图像来增强模型的鲁棒性。实验结果表明,该方法在领域泛化和无监督领域适应方面取得了显着的性能提升。此外,该方法还可以在虚拟数据集上进行训练,无需真实场景标注,为实时应用和大规模部署提供了便利。这些亮点展示了该方法在解决多摄像头3D物体检测中的挑战和潜力。这篇论文尝试利用Nerf的思路来提高BEV的泛化能力,同时可以利用有标签的源域数据和无标签的目标域数据。此外,尝试了Sim2Real的实验范式,这对于无人驾驶闭环具有潜在价值。从定性和定量结果都有很好的结果,并且开源了代码值得看一看

原文链接:https://mp.weixin.qq.com/s/GRLu_JW6qZ_nQ9sLiE0p2g
以上是NeRF在BEV泛化性能方面的突破:首个跨域开源代码成功实现Sim2Real的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 MIT最新力作:用GPT-3.5解决时间序列异常检测问题
Jun 08, 2024 pm 06:09 PM
MIT最新力作:用GPT-3.5解决时间序列异常检测问题
Jun 08, 2024 pm 06:09 PM
今天给大家介绍一篇MIT上周发表的文章,使用GPT-3.5-turbo解决时间序列异常检测问题,初步验证了LLM在时间序列异常检测中的有效性。整个过程没有进行finetune,直接使用GPT-3.5-turbo进行异常检测,文中的核心是如何将时间序列转换成GPT-3.5-turbo可识别的输入,以及如何设计prompt或者pipeline让LLM解决异常检测任务。下面给大家详细介绍一下这篇工作。图片论文标题:Largelanguagemodelscanbezero-shotanomalydete
 改进的检测算法:用于高分辨率光学遥感图像目标检测
Jun 06, 2024 pm 12:33 PM
改进的检测算法:用于高分辨率光学遥感图像目标检测
Jun 06, 2024 pm 12:33 PM
01前景概要目前,难以在检测效率和检测结果之间取得适当的平衡。我们就研究出了一种用于高分辨率光学遥感图像中目标检测的增强YOLOv5算法,利用多层特征金字塔、多检测头策略和混合注意力模块来提高光学遥感图像的目标检测网络的效果。根据SIMD数据集,新算法的mAP比YOLOv5好2.2%,比YOLOX好8.48%,在检测结果和速度之间实现了更好的平衡。02背景&动机随着远感技术的快速发展,高分辨率光学远感图像已被用于描述地球表面的许多物体,包括飞机、汽车、建筑物等。目标检测在远感图像的解释中
 如何评估Java框架商业支持的性价比
Jun 05, 2024 pm 05:25 PM
如何评估Java框架商业支持的性价比
Jun 05, 2024 pm 05:25 PM
评估Java框架商业支持的性价比涉及以下步骤:确定所需的保障级别和服务水平协议(SLA)保证。研究支持团队的经验和专业知识。考虑附加服务,如升级、故障排除和性能优化。权衡商业支持成本与风险缓解和提高效率。
 PHP 框架的学习曲线与其他语言框架相比如何?
Jun 06, 2024 pm 12:41 PM
PHP 框架的学习曲线与其他语言框架相比如何?
Jun 06, 2024 pm 12:41 PM
PHP框架的学习曲线取决于语言熟练度、框架复杂性、文档质量和社区支持。与Python框架相比,PHP框架的学习曲线更高,而与Ruby框架相比,则较低。与Java框架相比,PHP框架的学习曲线中等,但入门时间较短。
 PHP 框架的轻量级选项如何影响应用程序性能?
Jun 06, 2024 am 10:53 AM
PHP 框架的轻量级选项如何影响应用程序性能?
Jun 06, 2024 am 10:53 AM
轻量级PHP框架通过小体积和低资源消耗提升应用程序性能。其特点包括:体积小,启动快,内存占用低提升响应速度和吞吐量,降低资源消耗实战案例:SlimFramework创建RESTAPI,仅500KB,高响应性、高吞吐量
 RedMagic Tablet 3D Explorer Edition 配备裸眼 3D 显示屏
Sep 06, 2024 am 06:45 AM
RedMagic Tablet 3D Explorer Edition 配备裸眼 3D 显示屏
Sep 06, 2024 am 06:45 AM
RedMagic Tablet 3D Explorer Edition 与 Gaming Tablet Pro 一起推出。然而,后者更适合游戏玩家,而前者则更适合娱乐。新款 Android 平板电脑具有该公司所谓的“裸眼 3D”功能
 golang框架文档最佳实践
Jun 04, 2024 pm 05:00 PM
golang框架文档最佳实践
Jun 04, 2024 pm 05:00 PM
编写清晰全面的文档对于Golang框架至关重要。最佳实践包括:遵循既定文档风格,例如Google的Go编码风格指南。使用清晰的组织结构,包括标题、子标题和列表,并提供导航。提供全面准确的信息,包括入门指南、API参考和概念。使用代码示例说明概念和使用方法。保持文档更新,跟踪更改并记录新功能。提供支持和社区资源,例如GitHub问题和论坛。创建实际案例,如API文档。
 如何为不同的应用场景选择最佳的golang框架
Jun 05, 2024 pm 04:05 PM
如何为不同的应用场景选择最佳的golang框架
Jun 05, 2024 pm 04:05 PM
根据应用场景选择最佳Go框架:考虑应用类型、语言特性、性能需求、生态系统。常见Go框架:Gin(Web应用)、Echo(Web服务)、Fiber(高吞吐量)、gorm(ORM)、fasthttp(速度)。实战案例:构建RESTAPI(Fiber),与数据库交互(gorm)。选择框架:性能关键选fasthttp,灵活Web应用选Gin/Echo,数据库交互选gorm。
