
OpenAI GPT-4V 和 Google Gemini 都展现了非常强的多模态理解能力,推动了多模态大模型(MLLM)快速发展,MLLM 成为了现在业界最热的研究方向。
MLLM 在多种视觉-语言开放任务中取得了出色的指令跟随能力。尽管以往多模态学习的研究表明不同模态之间能够相互协同和促进,但是现有的 MLLM 的研究主要关注提升多模态任务的能力,如何平衡模态协作的收益与模态干扰的影响仍然是一个亟待解决的重要问题。

请点击以下链接查看论文:https://arxiv.org/pdf/2311.04257.pdf
请查看以下代码地址:https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl2
ModelScope 体验地址:https://modelscope.cn/studios/damo/mPLUG-Owl2/summary
HuggingFace 体验地址链接:https://huggingface.co/spaces/MAGAer13/mPLUG-Owl2
针对这个问题,阿里巴巴的多模态大模型mPLUG-Owl迎来了一次大升级。通过模态协同的方式,它同时提升了纯文本和多模态的性能,超过了LLaVA1.5、MiniGPT4、Qwen-VL等模型,在多种任务中取得了最佳性能。具体来说,mPLUG-Owl2利用共享的功能模块促进了不同模态之间的协作,并引入了模态自适应模块来保留各个模态的特征。通过简洁而有效的设计,mPLUG-Owl2在包括纯文本和多模态任务在内的多个领域取得了最佳性能。对模态协作现象的研究也为未来多模态大模型的发展提供了启示
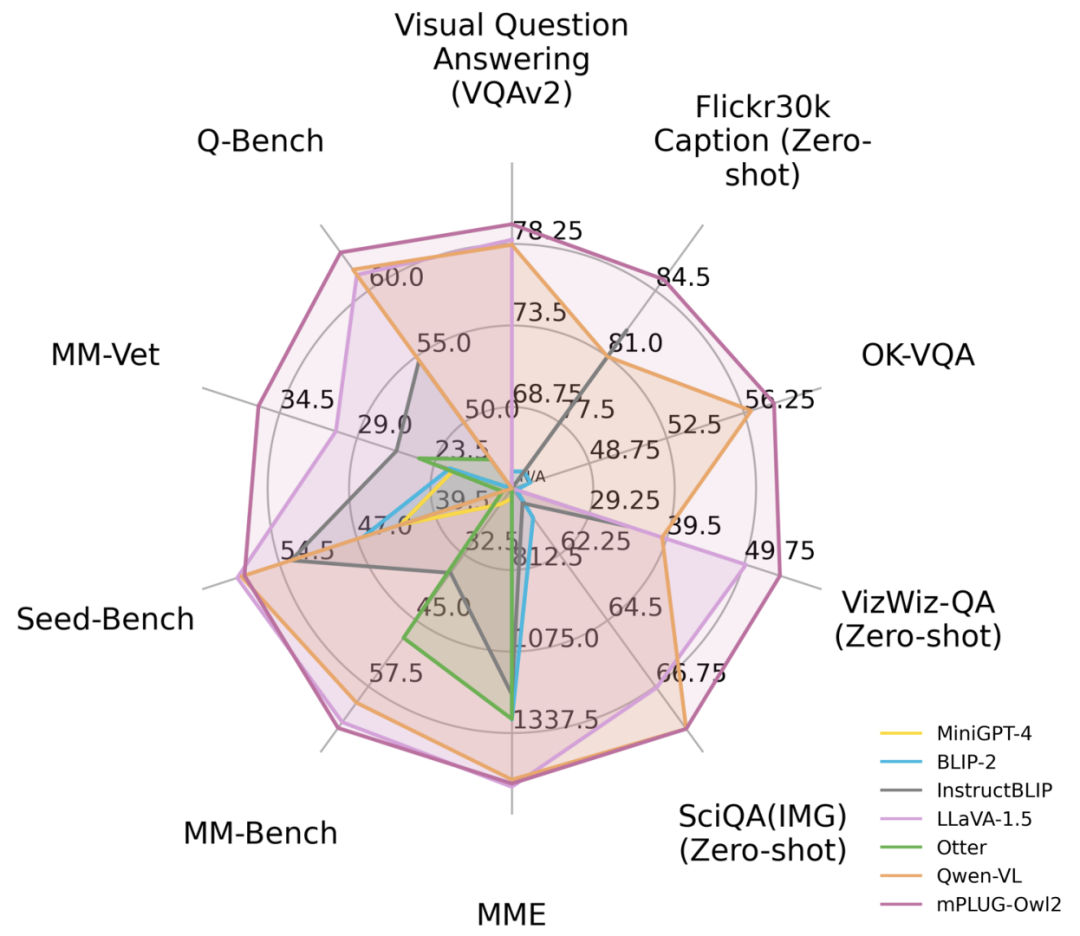
图 1 与现有 MLLM 模型性能对比
方法介绍 为了达到不改变原始意思的目的,需要将内容重新写成中文
mPLUG-Owl2 模型主要包含三个部分:
Visual Encoder:以 ViT-L/14 作为视觉编码器,将输入的分辨率为 H x W 的图像,转换为 H/14 x W/14 的视觉 tokens 序列,输入到 Visual Abstractor 中。
视觉提取器:通过学习一组可用的查询,提取高层次的语义特征,同时减少输入语言模型的视觉序列长度
语言模型:使用了 LLaMA-2-7B 作为文本解码器,并设计了如图 3 所示的模态自适应模块。
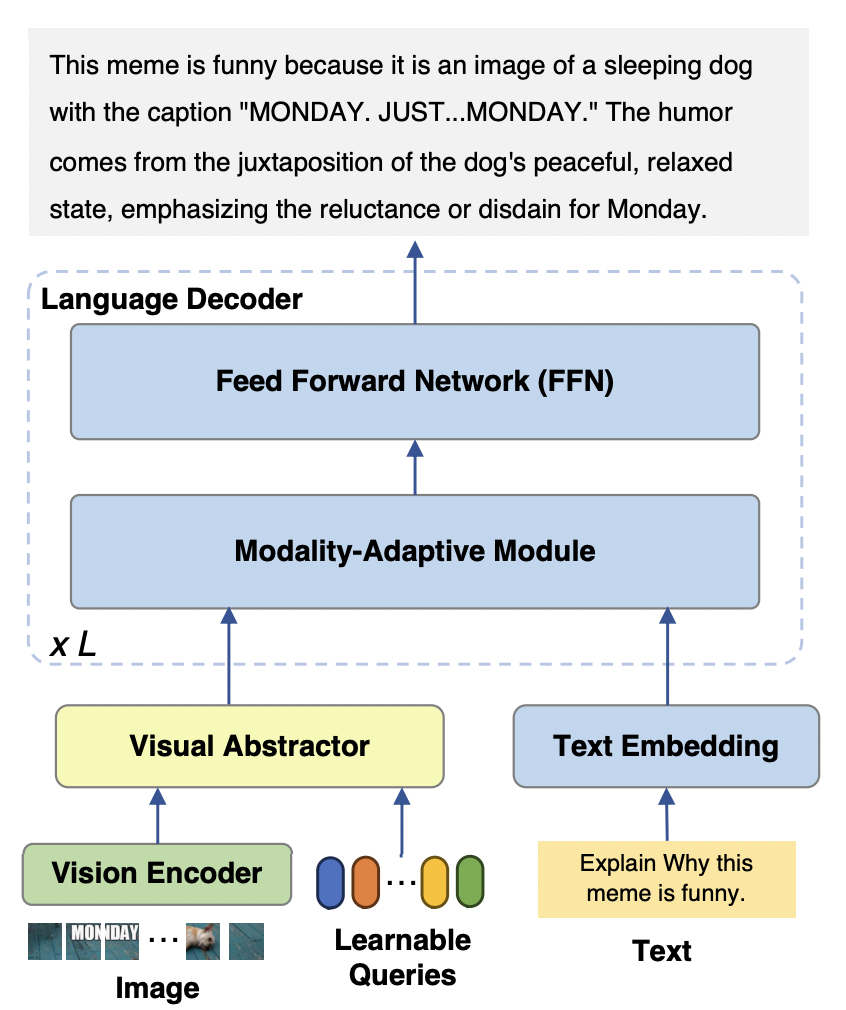
图 2 mPLUG-Owl2 模型结构
为了对齐视觉和语言模态,现有的工作通常是将视觉特征映射到文本的语义空间中,然而这样的做法忽视了视觉和文本信息各自的特性,可能由于语义粒度的不匹配影响模型的性能。为了解决这一问题,本文提出模态自适应模块 (Modality-adaptive Module, MAM),来将视觉和文本特征映射到共享的语义空间,同时解耦视觉 - 语言表征以保留模态各自的独特属性。
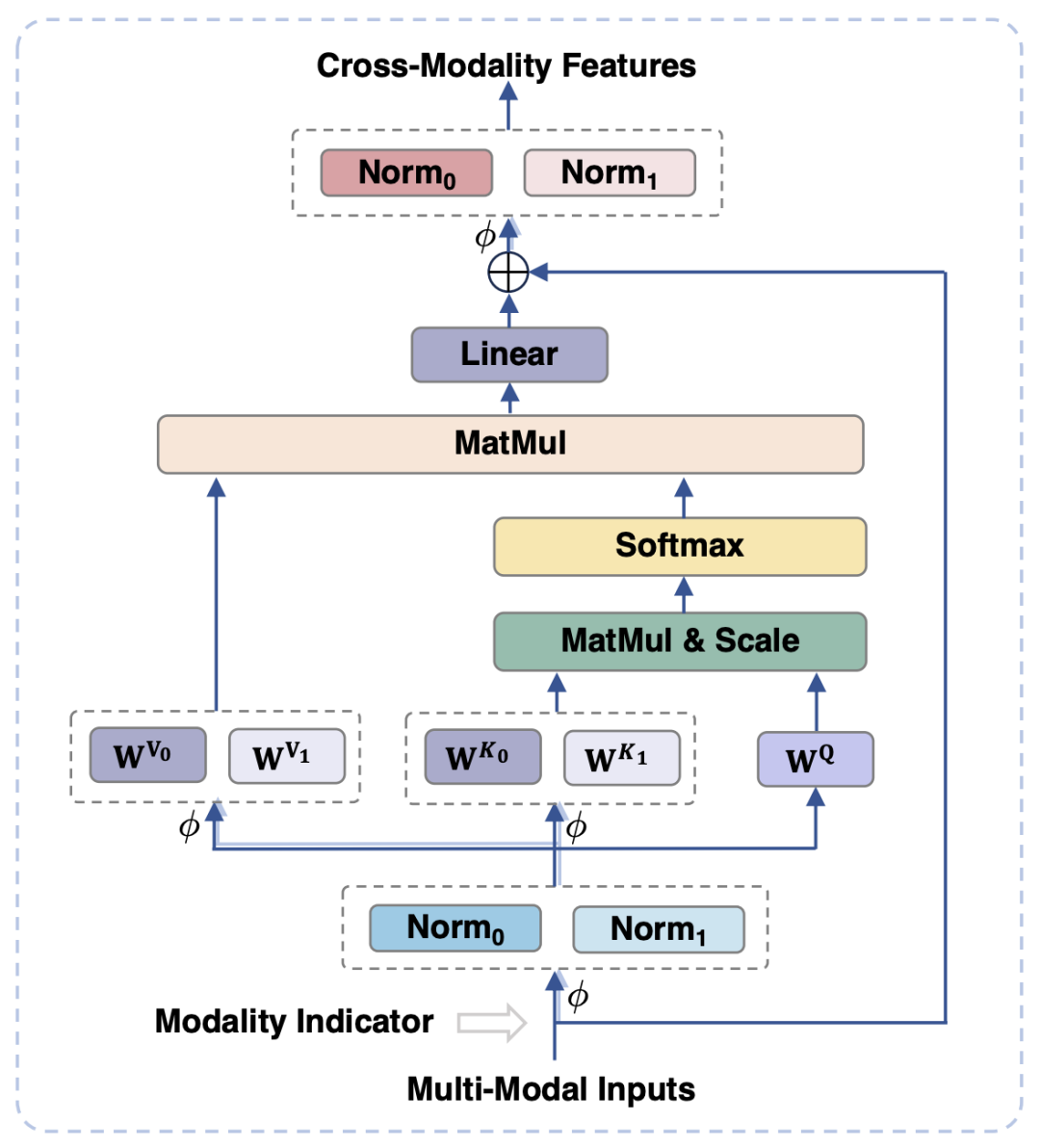
图3 展示了模态自适应模块的示意图
在图3中显示的是,与传统的Transformer相比,模态自适应模块的主要设计在于:
在模块的输入、输出阶段,分别对视觉和语言模态进行 LayerNorm 操作,以适应两种模态各自的特征分布。
在自注意力操作中,对视觉和语言模态采用分离的 key 和 value 投影矩阵,但采用共享的 query 投影矩阵,通过这样解耦 key 和 value 投影矩阵,能够在语义粒度不匹配的情况下,避免两种模态之间的干扰。
通过共享相同的FFN,两种模态可以促进彼此之间的协作
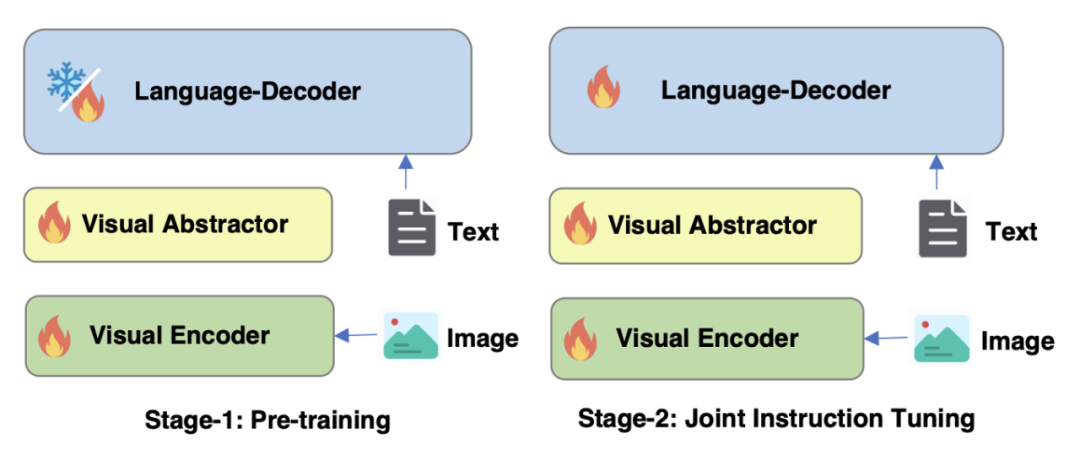
对于图4 mPLUG-Owl2的训练策略进行优化
如图 4 所示,mPLUG-Owl2 的训练包含预训练和指令微调两个阶段。预训练阶段主要是为了实现视觉编码器和语言模型的对齐,在这一阶段,Visual Encoder、Visual Abstractor 都是可训练的,语言模型中则只对 Modality Adaptive Module 新增的视觉相关的模型权重进行更新。在指令微调阶段,结合文本和多模态指令数据(如图 5 所示)对模型的全部参数进行微调,以提升模型的指令跟随能力。
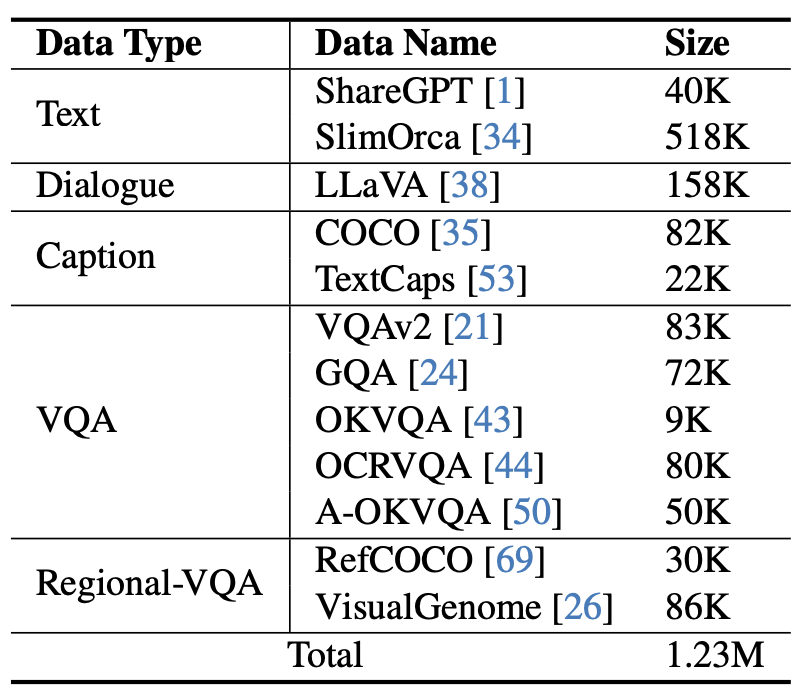
图 5 mPLUG-Owl2 使用的指令微调数据
实验及结果
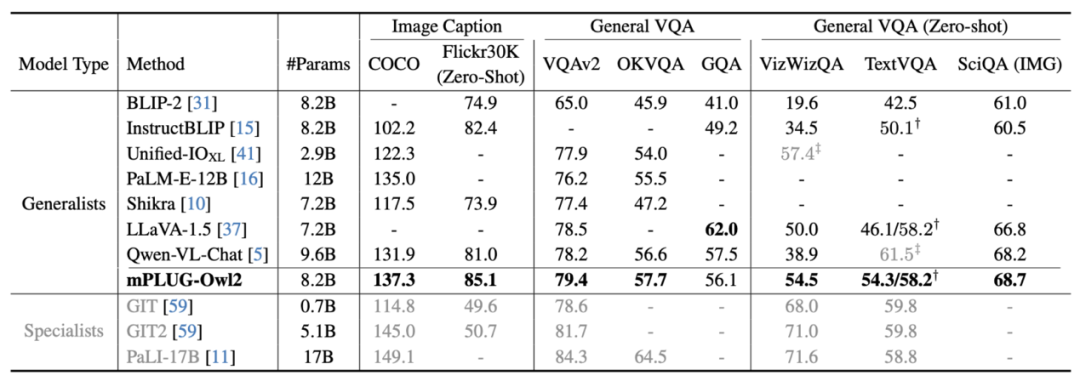
图 6 图像描述和 VQA 任务性能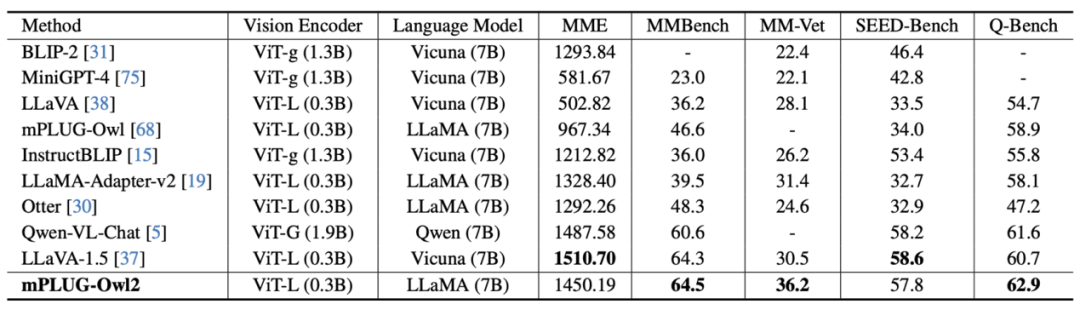
图 7 MLLM 基准测试性能
如图 6、图 7 所示,无论是传统的图像描述、VQA 等视觉 - 语言任务,还是 MMBench、Q-Bench 等面向多模态大模型的基准数据集上,mPLUG-Owl2 都取得了优于现有工作的性能。
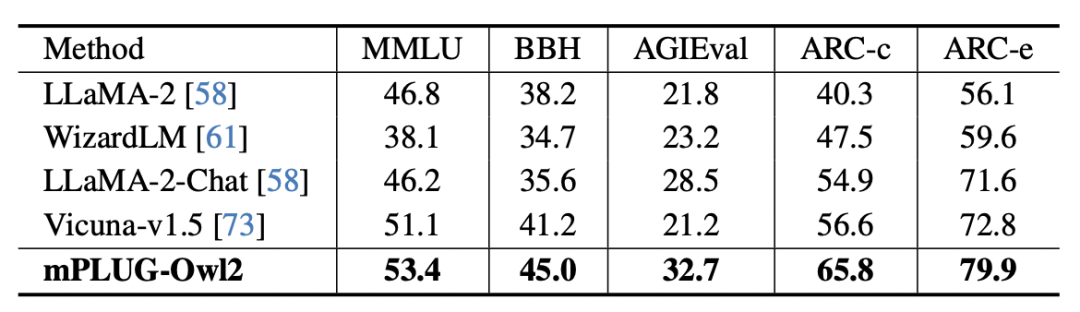
图 8 纯文本基准测试性能
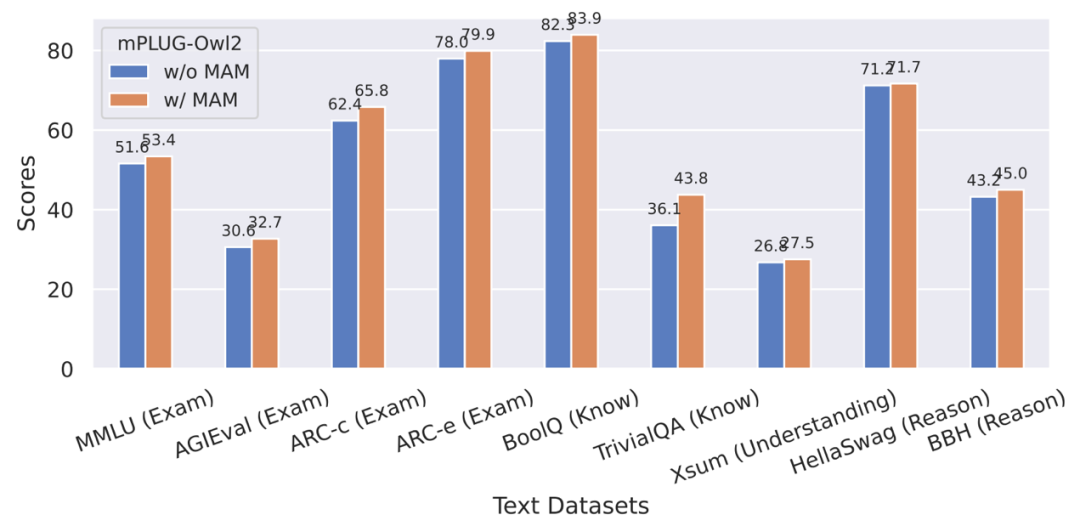
图 9 模态自适应模块对纯文本任务性能的影响
此外,为了评估模态协同对纯文本任务的影响,作者还测试了 mPLUG-Owl2 在自然语言理解和生成方面的表现。如图 8 所示,与其他指令微调的 LLM 相比,mPLUG-Owl2 取得了更好的性能。图 9 展示的纯文本任务上的性能可以看出,由于模态自适应模块促进了模态协作,模型的考试和知识能力都得到了显著提高。作者分析,这是由于多模态协作使得模型能够利用视觉信息来理解语言难以描述的概念,并通过图像中丰富的信息增强模型的推理能力,并间接强化文本的推理能力。


mPLUG-Owl2 展示了出色的多模态理解能力,成功地缓解了多模态幻觉。这种多模态技术已经被应用于通义星尘、通义智文等核心通义产品,并且已经在 ModelScope、HuggingFace 开放 Demo 中得到了验证
以上是阿里mPLUG-Owl新升级,鱼与熊掌兼得,模态协同实现MLLM新SOTA的详细内容。更多信息请关注PHP中文网其他相关文章!





















