

因果纠偏方法在蚂蚁营销推荐场景中的应用

一、因果纠偏的背景
1、偏差的产生
在推荐系统中,通过收集数据来训练推荐模型,以向用户推荐合适的物品。当用户与推荐的物品互动时,收集的数据又会用于进一步训练模型,形成一个闭环循环。然而,这个闭环中可能存在各种影响因素,从而导致误差的产生。主要的误差原因在于训练模型所使用的数据大多是观测数据,而非理想的训练数据,受到曝光策略和用户选择等因素的影响。这种偏差的本质在于经验风险估计的期望和真实理想风险估计的期望之间的差异。

2、常见的偏差
推荐营销系统里面比较常见的偏差主要有以下三种:
- 选择性偏差:是由于用户根据自己的偏好主动选择交互的 item 造成的。
- 曝光性偏差:推荐的 item 通常只是整体 item 候选池里的一个子集,用户选择时只能与系统推荐的 item 进行交互,导致了观测数据产生偏差。
- 流行性偏差:一些热门的 item 在训练数据中的占比高导致模型会学到这个表现,就会更多推荐热门的 item,造成马太效应。
还有其它一些偏差,例如位置偏差、一致性偏差等。
3、因果纠偏
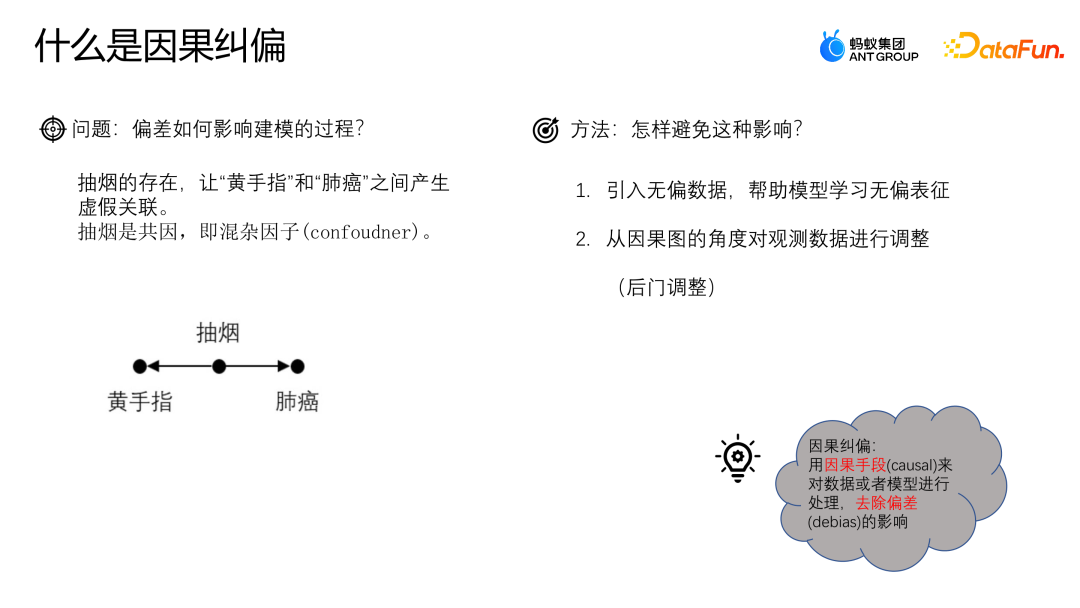
下面通过一个例子来理解偏差对建模过程造成的影响。假设我们想研究咖啡饮用与心脏病之间的关系。我们发现咖啡饮用者更容易患心脏病,因此可能会得出结论咖啡饮用与心脏病有直接的因果关系。 然而,我们需要注意混杂因子的存在。例如,假设咖啡饮用者更可能也是吸烟者。吸烟本身就与心脏病有关联。因此,我们不能简单地将咖啡饮用与心脏病之间的关系归因于因果关系,而是可能是由于吸烟这个混杂因子的存在所导致的。 为了更准确地研究咖啡饮用与心脏病之间的关系,我们需要控制吸烟的影响。一种方法是进行配对研究,即将吸烟者和非吸烟者进行配对,然后比较他们在咖啡饮用和心脏病之间的关系。这样可以消除吸烟对结果的混杂影响。 因果关系是一个what if的问题,即在其他条件不变的情况下,改变咖啡饮用会不会导致心脏病发生的改变。只有在控制了混杂因子的影响后,才能更准确地判断咖啡饮用与心脏病之间是否存在因果关系。
如何避免这种问题呢? 一种比较常见的方法就是引入无偏的数据,通过使用无偏的数据来帮助模型学习无偏的表征;另外一种方法是从因果图的角度出发,通过后期对观测数据进行调整来进行纠偏。因果纠偏就是通过因果的手段对数据或者模型进行处理,去除偏差的影响。
4、因果图
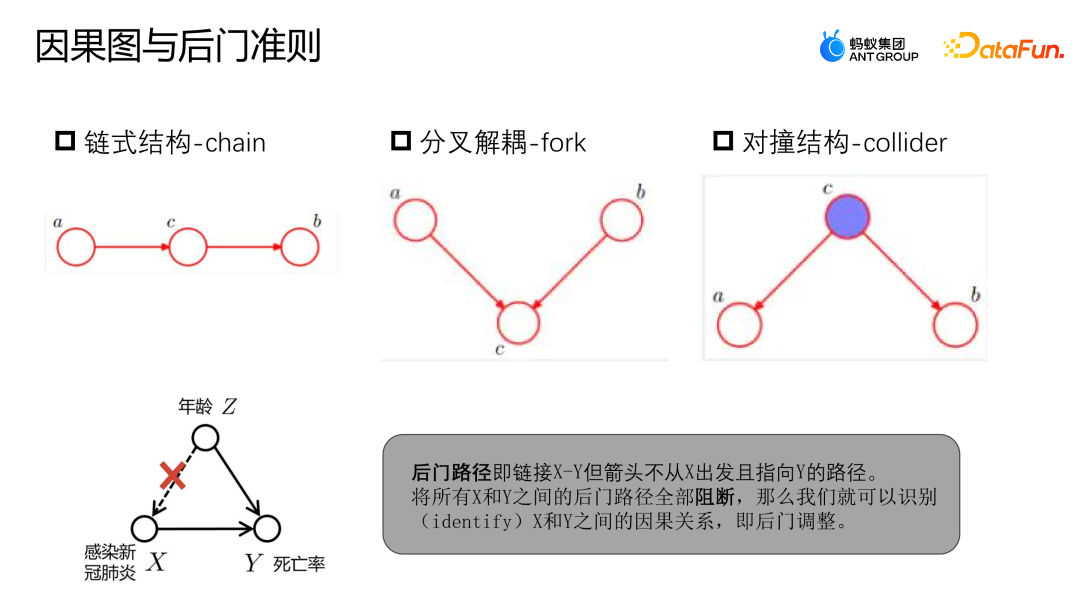
因果图是一个有向无环图,用于描述场景中节点之间的因果关系。它由链式结构、分叉结构和对撞结构三个组成。
- 链式结构:给定 C,A、B 是独立的。
- 分叉结构:给定 C,A 变化,B 不会随之变化。
- 对撞结构:在没有 C 的情况下,不能观察到 A、B 是独立的;但是观察到 C 后,A 跟 B 是不独立的。
可以参考上图的例子来确定后门路径和后门准则。后门路径是指链接X到Y的路径,但是从Z出发最终指向了Y。与之前的例子类似,感染新冠肺炎与死亡率之间并不是一个纯粹的因果关系。感染新冠肺炎受到年龄的影响,老龄人群感染新冠肺炎的概率更高,而老龄人群的死亡率也更高。然而,如果我们有足够多的数据,能够将X和Y之间的后门路径全部阻断,即给定了Z,那么X和Y就可以被建模为独立的关系,这样就可以得到真正的因果关系。
二、基于数据融合的纠偏
1、数据融合纠偏模型介绍
下面介绍蚂蚁团队基于数据融合纠偏的工作,目前已经发表在 SIGIR2023 的 Industry Track 上。工作的思路是通过无偏数据来做数据增广,指导模型的纠偏。

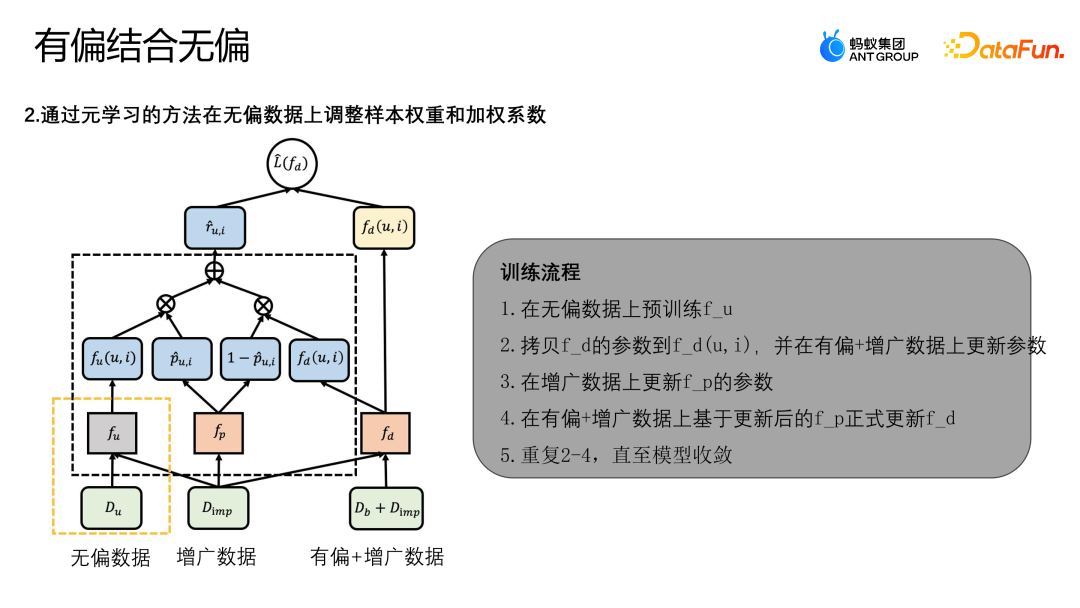
无偏数据整体跟有偏数据的分布不相同,有偏数据会集中在整个样本空间的某部分区域,缺失的样本会集中在有偏数据相对较少的部分区域,所以增广的样本如果是靠近无偏区域比较多的区域,那无偏数据会发挥更多的作用;如果增广样本靠近有偏数据的区域,那有偏数据就会发挥更多的作用。对此这篇论文设计了 MDI 的模型,可以更好地利用无偏和有偏数据来做数据增广。

上图中展示了算法的框架图,MDI 模型是通过元学习的方法,在无偏数据上调整样本的权重以及加权的系数。首先,MDI 模型训练有两个阶段:
- 阶段一:利用无偏数据训练无偏的 teacher 模型 fu。
- 阶段二:使用原学习的方法来更新示意图里的其它结构。
通过优化 L(fd) 的经营损失来训练融合去偏模型 fd,最终的 Lose 损失主要有两项,一个是 L-IPS,一个是 L-IMP。L-IPS 是我们利用原始样本来进行优化的一个 IPS 模块;R-UI 是利用任意模型来求导倾向性分数(判断样本属于无偏样本的概率或属于有偏样本的概率);第二项的 L-IMP 是预设的增广模块的权重,R-UI 是预设的增广模块生成的尾标;P-UI 与 1—P-UI 是无偏的 Teacher 模型和融合模型在当前样本的倾向分数;fp 就是用来学倾向性分数的一个函数,通过学习 fp 自适应结合无偏数据的 Teacher 模型与当前的有偏数据训练的模型,共同为增广样本生成伪标记;通过这种方法来学习更复杂的 pattern 信息,fp 通过 Meta learning 的方式求解。
下面是算法完整的训练流程:
- 在无偏数据上预训练 fu。
- 拷贝 fd 的参数到 fd(u,i),并在有偏+增广数据上更新参数。
- 在增广数据上更新 fp 的参数。
- 在有偏+增广数据上基于更新后的 fp 正式更新 fd。
- 重复 2-4,直至模型收敛。
2、数据融合纠偏模型的实验
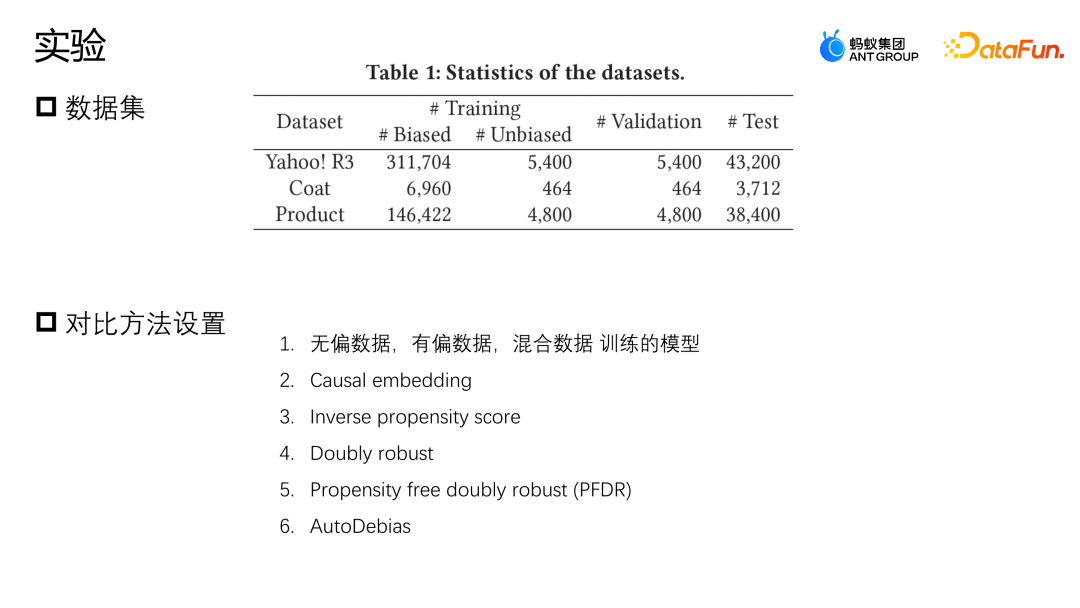
我们在 Yahoo R3 和 Coat 这两个公开数据集上进行了评估。Yahoo R3 通过收集 15000+ 用户对 1000 首歌曲的打分,一共收集了 31 万+有偏数据以及 5400 条无偏数据。Coat 数据集是通过 290 个用户对三百件衣服的打分收集了 6900+ 条有偏数据和 4600+ 条无偏数据。两个数据集用户的打分都在 1 到 5 之间,有偏的数据来自于平台的数据用户,无偏的样本通过随机给用户选择打分的形式来收集。
除了两个公开的数据集,蚂蚁还使用了来自业界实际场景的一个数据集,为了模拟无偏数据样本非常少的情况,我们把全部的有偏数据和 10% 的无偏数据用来训练,保留 10% 的无偏数据作为验证,剩下 80% 作为测试集。
我们使用的 Baseline 对比的方法主要是以下几种:第一个方法是分别利用无偏数据、单有偏数据和直接数据融合训练的模型;第二个方法是通过少部分无偏数据,设计了一个正则性的表征约束有偏数据、无偏数据表征的相似度来进行纠偏的操作;第三个方法是逆概率权重的方法,倾向性分数的一个逆概率。Double robust 也是一个比较常见的纠偏的方法;Propensity free double robust 是一个数据增广的方法,它先用无偏的样本学习一个增广的模型,然后通过增广的样本帮助整个模型进行纠偏;Auto debias 也会用到一些无偏的数据做增广来帮助模型纠偏。
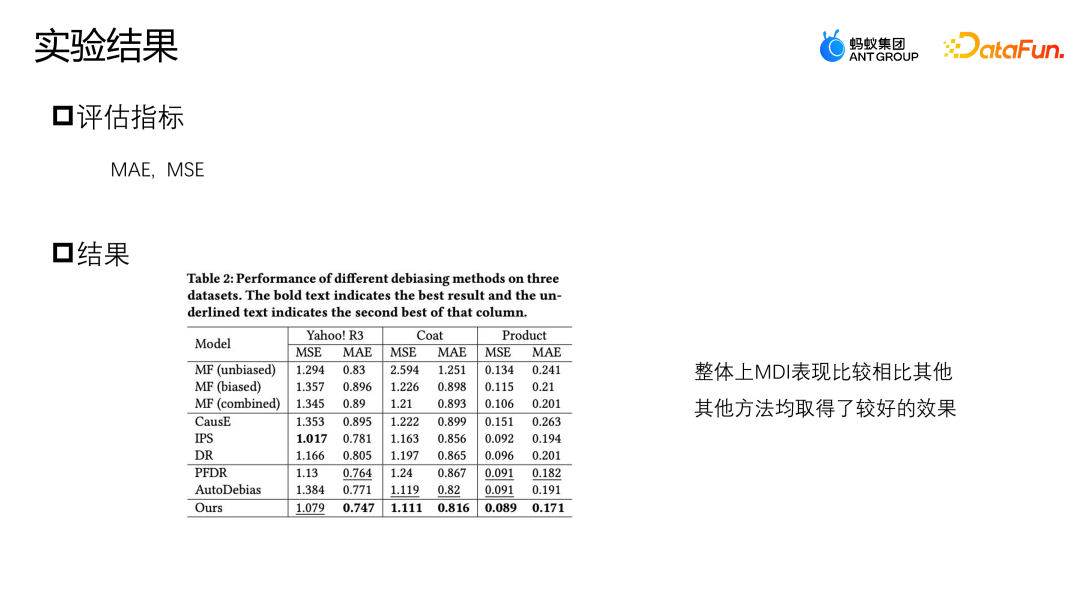
我们使用了 MSE 和 MAE 这两个指标来评估表现。如图所示,我们提出的 MDI 方法,在 Coat 以及 Product 两个数据集上,两个指标都有比较好的表现。
在 Yahoo R3 数据集上,我们提出的方法在 MAE 上的表现指标最好,在 MSE 除了 IPS 以外的方法表现是最好的。三种数据增广的方法,PFDR、Auto Debias 以及我们提出的 MDI,在多数情况下表现的都会更好,但是由于 PFDR 是提前利用无偏数据训练增广模型,会严重依赖于无偏数据的质量,因此它在 Coat 模型上就只有 464 条无偏训练数据样本,当无偏样本比较少的时候,它的增广模块就会比较差,数据表现也会相对差一些。
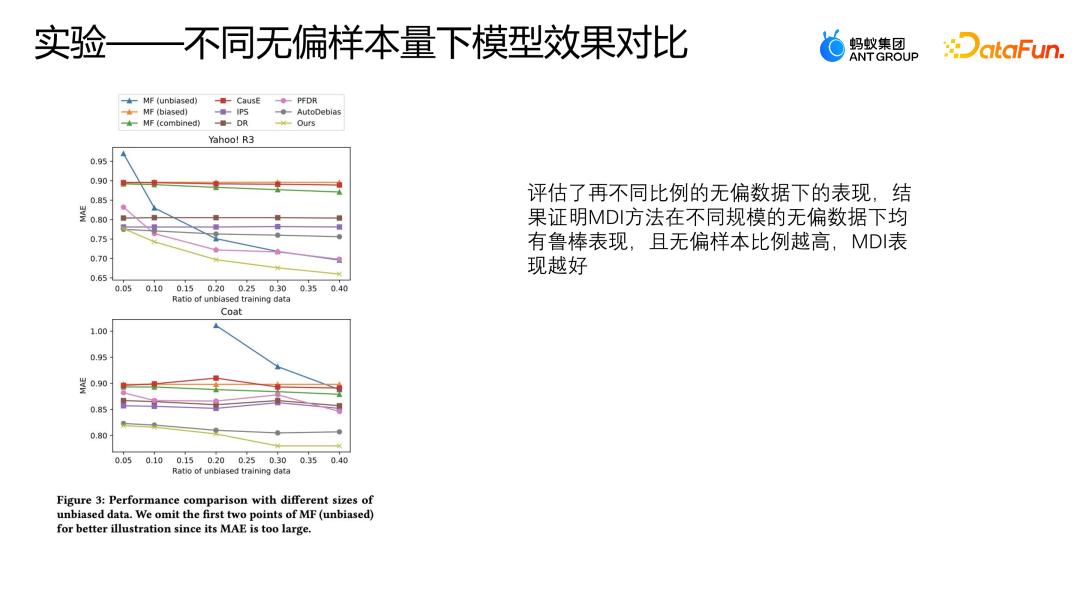
AutoDebias 在不同数据上的表现与 PFDR 正好相反。由于 MDI 设计了同时利用无偏数据以及有偏数据的增广方法,所以具有更强的数据增广模块,因此它在无偏数据比较少或者无偏数据比较充足这两种情况下都可以获得比较好的效果。
我们在两个公开数据集上也评估了这些模型在不同比例的无偏数据下的表现,分别使用了 50% 到 40% 的无偏数据以及全部的有偏数据来用于训练,其它逻辑与前面 10% 的无偏数据做验证,剩下的数据做测试,这个设定与前面的实验一样。
上图展示了采用不同方法在不同比例的无偏数据下的 MAE 的表现,横坐标表示无偏数据的比例,纵坐标表示各个方法在无偏数据上的效果,可以看到随着无偏数据比例的增加 AutoDebias、IPS 以及 DoubleRubus 的 MAE 没有明显的下降过程。但是不按 Debias 的方式,直接利用原始数据融合来学习的方法则会有比较明显的下降,这是因为无偏数据的样本比例越高,我们整体的数据质量就越好,所以模型可以学到更好的表现。
当 Yahoo R3 的数据使用超过 30% 的无偏数据来训练的时候,这种方式甚至超过了除 MDI 以外其它所有的纠偏方法。但 MDI 的方式相对来说可以获得更好的表现,这也可以证明 MDI 方法在不同规模的无偏数据下都有比较鲁棒的结果。
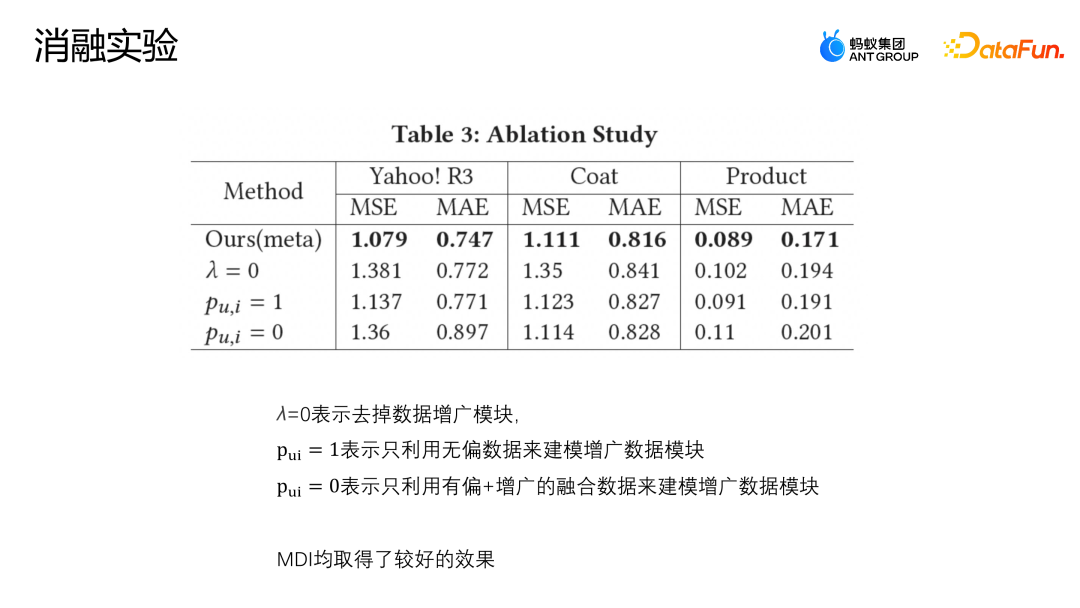
同时我们也进行了消融实验,在三个数据集上分别验证增广模块当中各个部分的设置是否有效。
λ=0 的设置表示直接去除了增广模块;Pu,i = 1 表示只利用无偏数据建模增广数据模块;Pu,i = 0 表示只利用有偏以及增广的融合数据建模增广数据模块。
上图中展示了消融实验的结果,可以看到 MDI 方法在三个数据集上都取得了比较好的效果,说明增广模块是有必要的。
无论是在公开数据集上,还是实际业务场景的数据集上,我们提出的融合无偏和有偏数据的增广方法相比之前已有的数据融合方案都有着更好的效果,同时通过参数敏感性实验以及消融实验也验证了 MDI 的鲁棒性。
三、基于后门调整的纠偏
下面来介绍下团队的另外一个工作:基于后门调整纠偏。这一工作也已发表在了 SIGIR2023 的 Industry Track 上。后门调整纠偏应用的场景就是营销推荐的场景,如下图所示,用户与优惠券或者用户与任意广告、item 的交互是不受任何干预的,有均等的可能去任意交互,每张券也有均等的可能会曝光给任意用户。

但在实际的业务场景当中,为了保护或者帮助一些小商户提升流量,以及保证全局的用户参与体验,通常会设置一系列的策略约束,这种情况就会导致一部分用户会更多的曝光某些优惠券,另一部分用户会更多的曝光另外一张优惠券,这种干预就是前文中提到的 confounder。
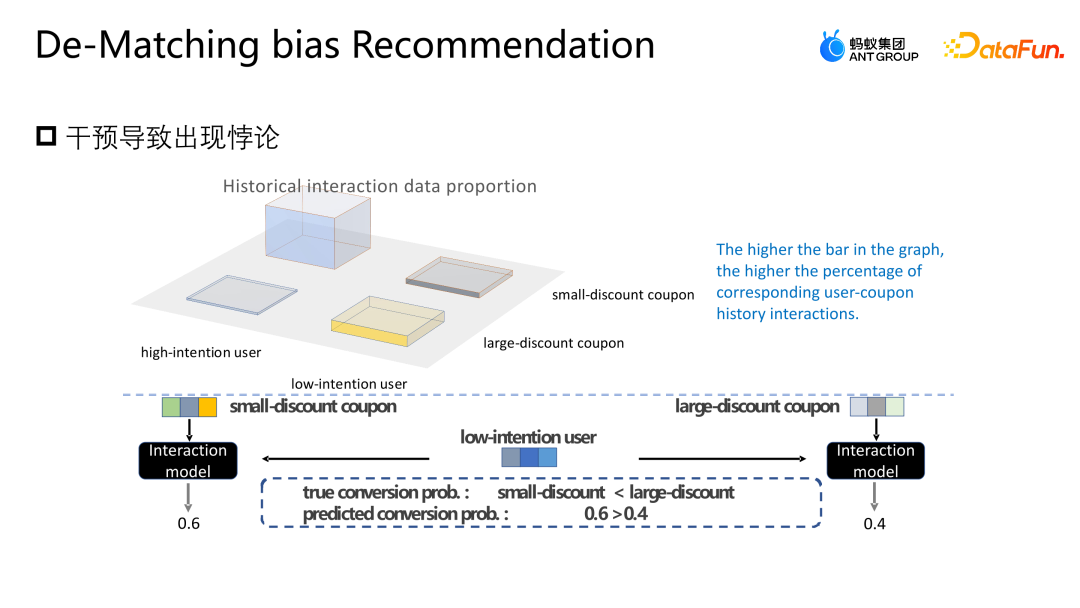
这种干预在电商营销场景里会产生什么问题呢?如上图所示,为了简化,我们将用户简单地分为高参与意愿和低参与意愿两类,将优惠券简单地分为大折扣和小折扣两类。图中柱状图的高低表示了对应样本的全局占比,柱状图越高,说明对应样本在整体训练数据当中占比越多。图中所展示的小折扣的优惠券以及高参与意愿用户样本占据了大多数,会导致模型学到图中所示的分布,模型会认为高参与意愿用户更喜欢小折扣的优惠券。但实际上面对同样的使用门槛,用户肯定会倾向于折扣更高的优惠券,这样才会更省钱。图中模型对于实际的转化概率是小折扣优惠券低于大折扣优惠券的,但是模型对于某一个样本的预估反而会认为小折扣优惠券核销概率更高,所以模型也会推荐这个打分对应的优惠券,这就形成了一个悖论。
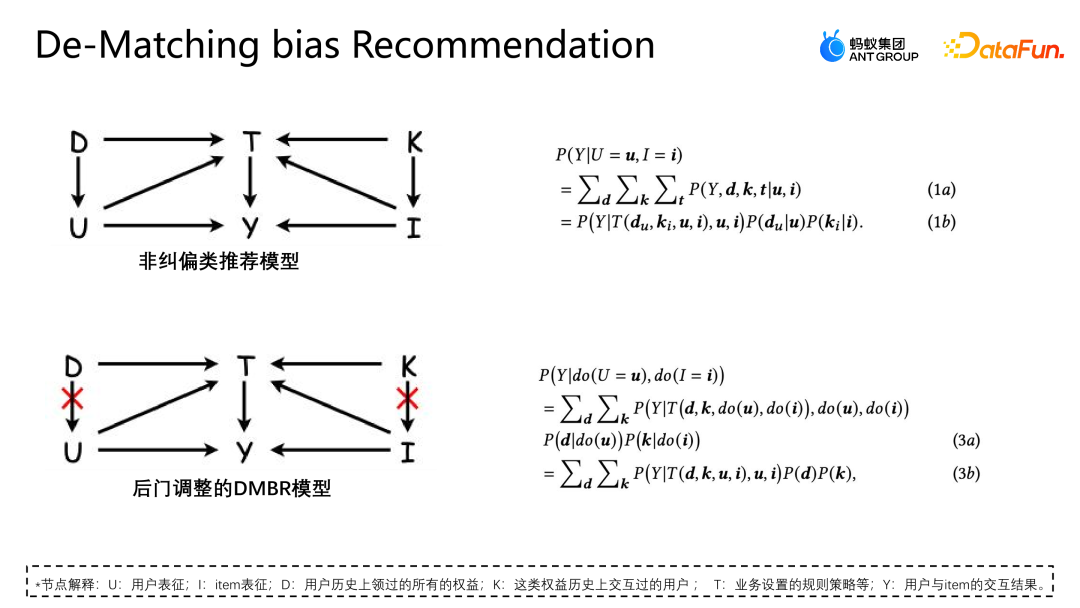
从因果图的视角分析这个悖论产生的原因,在当前的场景下应用非纠偏的推荐模型,其因果图构造如上图所示,U 表示用户的表征,I 表示 item 的表征。D 和 K 分别是用户视角与权益视角的历史交互情况,T 表示当前业务设置的一些规则约束,T 是没办法直接量化的,但是我们可以通过 D 和 K 来间接地看出它对用户和 item 的影响。y 表示用户与 item 的交互,结果就是 item 是否被点击、被核销等。
因果图所代表的条件概率公式如图右上所示,公式推导遵循贝叶斯概率公式。在给定 U 和 I 的条件下,最终求导 P|Y ui 并不是只与 U 和 I 相关,因为 U 会受到 du 的影响,也就是 p 给定 u 的时候 p(du)的概率也是存在的。给定 I 的时候同理,I 也会受到 ki 的影响,这个情况产生的原因是因为 D 和 K 的存在导致了场景当中存在后门路径。也就是不从 U 出发,但是最终指向 y 的路径(U-D-T-Y 或者 I-K-T-Y 路径)这种后门路径会表示一个虚假观念,也就是 U 不仅可以通过 T 影响 y,也可以通过 D 影响 y。
调整的方法是将 D 到 U 的路径人为切断,这样 U 只能通过 U-T-Y 跟 U-Y直接影响y,这种方式可以去除虚假关联,从而建模真正的因果关系。后门调整是对观测数据做do-calculus,然后使用do算子聚合所有D以及所有K的情况表现,避免U和I受到D和K的影响。通过这种方式建模一个真正的因果关系。这个公式的推导近似估计形式如下图所示。

4a 和前面 3b 形式是一样的,而 4b 是做了样本空间的近似。因为理论上来讲 D 和 K 的样本空间是无限的,只能通过收集到的数据(样本空间的 D 和 K 取一个大小)来做近似。4c 和 4d 都是期望的近似的推导,通过这种方式最终只需额外建模一个无偏表征 T。T 是通过遍历所有情况下用户跟 item 的表征概率分布和,额外建模无偏表征 T,来帮助模型得到最终的无偏数据估计。
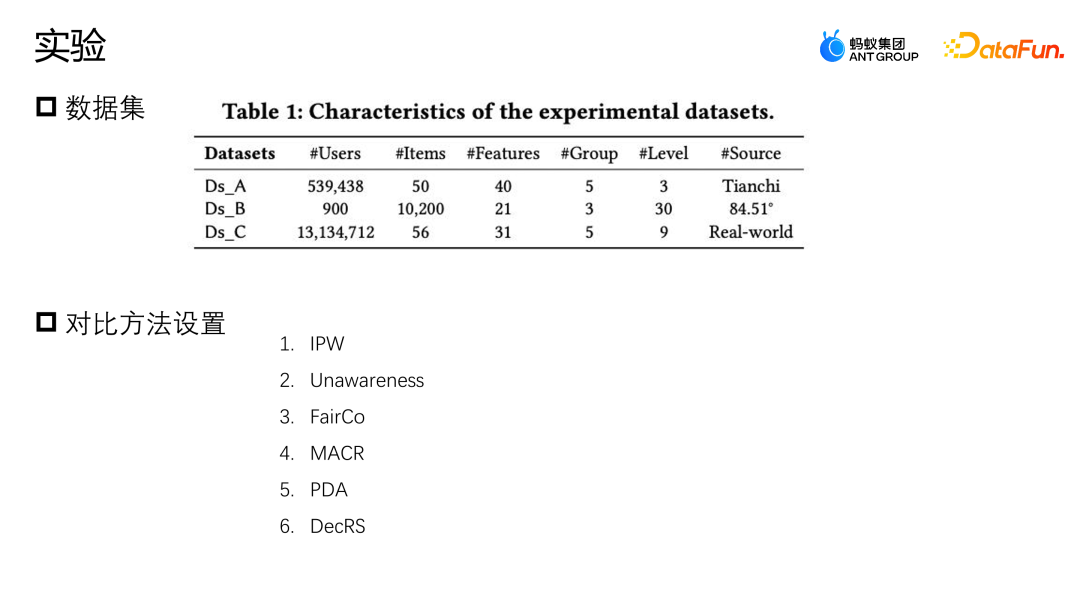
实验采用了两个开源的数据集,天池和 84.51(优惠券)数据集。通过采样的方式模拟这种规则策略对整体数据的影响。同时,使用了某个真实的电商营销活动场景所产生的数据,共同评测算法的好坏。对比了一些主流的纠偏方法,比如 IPW 是通过逆概率加权做纠偏;Unawareness 是通过去除偏差特征来缓解偏差的影响;FairCo 是通过引入误差项约束表征来获得相对无偏的估计;MACR 是通过多任务的框架分别估计用户的一致性以及 item 的流行程度,在预测阶段减去一致性跟流行度这种方式来实现无偏估计;PDA 是通过因果干预,对损失项做调整的方式去除流行性偏差的影响;DecRS 也是借助后门调整去除信息偏差,但是它只针对用户视角的偏差进行纠正。

实验的评估指标是 AUC,因为营销推进场景对于推荐优惠券或者推荐候选的商品只有一个,所以本质上是二分类的问题,因此采用 AUC 来评估比较合适。对比了 DNN 和 MMOE 不同架构下的表现,可以看出,我们提出的 DMBR 模型相比于原始无纠偏方式以及其它纠偏方式都有着更好的效果。同时 Ds_A 跟 Ds_B 在模拟数据集上比真实的业务数据集上得到了更高的提升效果,这是因为真实业务数据集的数据会更复杂,不仅会受到规则策略的影响,还可能会受到其它因素的影响。
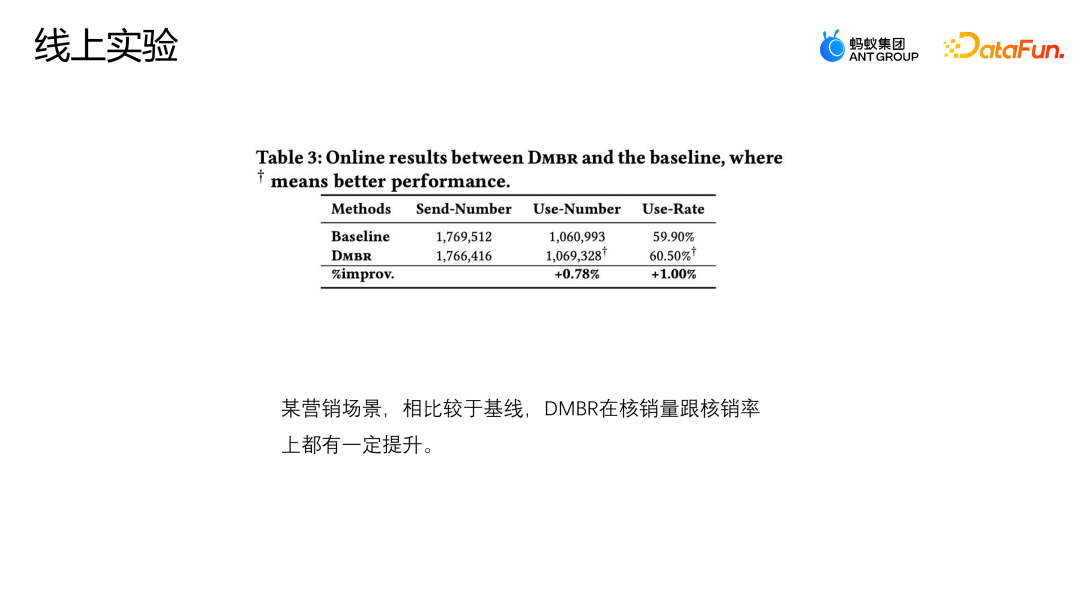
目前模型已在某电商营销活动场景上线,上图展示了线上的效果,对比基线模型,DMBR 模型在核销率以及核销量上都有一定的提升。
四、在蚂蚁的应用
因果纠偏的方法,在蚂蚁主要应用在存在规则或者存在策略约束的场景,比如广告场景,可能会设置约束不同广告的投放人群,一些针对宠物的广告,会更多地投放给有宠物的用户。电商营销的场景,会设置一些策略来保证小商家的流量,避免所有流量都被大商家消耗。以及保证用户活动参与体验,因为活动的整体预算有限,有一些薅羊毛的用户反复参与活动,就会占用掉大量的资源,导致其他用户的活动参与体验较差。诸如此类的场景中,都有对因果纠偏的应用。
以上是因果纠偏方法在蚂蚁营销推荐场景中的应用的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何使用Go语言和Redis实现推荐系统
Oct 27, 2023 pm 12:54 PM
如何使用Go语言和Redis实现推荐系统
Oct 27, 2023 pm 12:54 PM
如何使用Go语言和Redis实现推荐系统推荐系统是现代互联网平台中重要的一环,它帮助用户发现和获取感兴趣的信息。而Go语言和Redis是两个非常流行的工具,它们在实现推荐系统的过程中能够发挥重要作用。本文将介绍如何使用Go语言和Redis来实现一个简单的推荐系统,并提供具体的代码示例。Redis是一个开源的内存数据库,它提供了键值对的存储接口,并支持多种数据
 利用Java实现的推荐系统算法和应用
Jun 19, 2023 am 09:06 AM
利用Java实现的推荐系统算法和应用
Jun 19, 2023 am 09:06 AM
随着互联网技术的不断发展和普及,推荐系统作为一种重要的信息过滤技术,越来越受到广泛的应用和关注。在实现推荐系统算法方面,Java作为一种快速、可靠的编程语言,已被广泛应用。本文将介绍利用Java实现的推荐系统算法和应用,并着重介绍三种常见的推荐系统算法:基于用户的协同过滤算法、基于物品的协同过滤算法和基于内容的推荐算法。基于用户的协同过滤算法基于用户的协同过
 应用实例:使用go-micro 构建微服务推荐系统
Jun 18, 2023 pm 12:43 PM
应用实例:使用go-micro 构建微服务推荐系统
Jun 18, 2023 pm 12:43 PM
随着互联网应用的普及,微服务架构已成为目前比较流行的一种架构方式。其中,微服务架构的关键就是将应用拆分为不同的服务,通过RPC方式进行通信,实现松散耦合的服务架构。在本文中,我们将结合实际案例,介绍如何使用go-micro构建一款微服务推荐系统。一、什么是微服务推荐系统微服务推荐系统是一种基于微服务架构的推荐系统,它将推荐系统中的不同模块(如特征工程、分类
 精准推荐的秘术:阿里解耦域适应无偏召回模型详解
Jun 05, 2023 am 08:55 AM
精准推荐的秘术:阿里解耦域适应无偏召回模型详解
Jun 05, 2023 am 08:55 AM
一、场景介绍首先来介绍一下本文涉及的场景——“有好货”场景。它的位置是在淘宝首页的四宫格,分为一跳精选页和二跳承接页。承接页主要有两种形式,一种是图文的承接页,另一种是短视频的承接页。这个场景的目标主要是为用户提供满意的好货,带动GMV的增长,从而进一步撬动达人的供给。二、流行度偏差是什么,为什么接下来进入本文的重点,流行度偏差。流行度偏差是什么?为什么会产生流行度偏差?1、流行度偏差是什么流行度偏差有很多别名,比如马太效应、信息茧房,直观来讲它是高爆品的狂欢,越热门的商品,越容易曝光。这会导致
 Go语言如何实现云上搜索和推荐系统?
May 16, 2023 pm 11:21 PM
Go语言如何实现云上搜索和推荐系统?
May 16, 2023 pm 11:21 PM
随着云计算技术的不断发展和普及,云上搜索和推荐系统也越来越得到了人们的青睐。而针对这一需求,Go语言也提供了很好的解决方案。在Go语言中,我们可以利用其高速的并发处理能力和丰富的标准库实现一个高效的云上搜索和推荐系统。下面将介绍Go语言如何实现这样的系统。一、云上搜索首先,我们需要对搜索的姿势和原理进行了解。搜索姿势指的是搜索引擎根据用户输入的关键字匹配页面
 关于网易云音乐冷启动技术的推荐系统
Nov 14, 2023 am 08:14 AM
关于网易云音乐冷启动技术的推荐系统
Nov 14, 2023 am 08:14 AM
一、问题背景:冷启动建模的必要性和重要性作为一个内容平台,云音乐每天都会有大量的新内容上线。虽然相较于短视频等其他平台,云音乐平台的新内容数量相对较少,但实际数量可能远远超出大家的想象。同时,音乐内容与短视频、新闻、商品推荐又有着显着的不同。音乐的生命周期跨度极长,通常会以年为单位。有些歌曲可能在沉寂几个月、几年之后爆发,经典歌曲甚至可能经过十几年仍然有着极强的生命力。因此,对于音乐平台的推荐系统来说,发掘冷门、长尾的优质内容,并把它们推荐给合适的用户,相比其他类目的推荐显得更加重要冷门、长尾的
 因果纠偏方法在蚂蚁营销推荐场景中的应用
Jan 13, 2024 pm 12:15 PM
因果纠偏方法在蚂蚁营销推荐场景中的应用
Jan 13, 2024 pm 12:15 PM
一、因果纠偏的背景1、偏差的产生在推荐系统中,通过收集数据来训练推荐模型,以向用户推荐合适的物品。当用户与推荐的物品互动时,收集的数据又会用于进一步训练模型,形成一个闭环循环。然而,这个闭环中可能存在各种影响因素,从而导致误差的产生。主要的误差原因在于训练模型所使用的数据大多是观测数据,而非理想的训练数据,受到曝光策略和用户选择等因素的影响。这种偏差的本质在于经验风险估计的期望和真实理想风险估计的期望之间的差异。2、常见的偏差推荐营销系统里面比较常见的偏差主要有以下三种:选择性偏差:是由于用户根
 PHP中的推荐系统和协同过滤技术
May 11, 2023 pm 12:21 PM
PHP中的推荐系统和协同过滤技术
May 11, 2023 pm 12:21 PM
随着互联网的迅速发展,推荐系统变得越来越重要。推荐系统是一种用于预测用户感兴趣的物品的算法。在互联网应用程序中,推荐系统可以提供个性化建议和推荐,从而提高用户满意度和转化率。PHP是一种被广泛应用于Web开发的编程语言。本文将探讨PHP中的推荐系统和协同过滤技术。推荐系统的原理推荐系统依赖于机器学习算法和数据分析,它通过对用户历史行为进行分析,预测
