

SD社区的I2V-Adapter:无需配置,即插即用,完美兼容图生视频插件

图像到视频生成(I2V)任务是计算机视觉领域的一项挑战,旨在将静态图像转化为动态视频。这个任务的难点在于从单张图像中提取并生成时间维度的动态信息,同时保持图像内容的真实性和视觉上的连贯性。现有的I2V方法通常需要复杂的模型架构和大量的训练数据来实现这一目标。
近期,快手主导的一项新研究成果《I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models》发布。该研究引入了一种创新的图像到视频转换方法,提出了一种轻量级适配器模块,即I2V-Adapter。该适配器模块能够在不改变现有文本到视频生成(T2V)模型原始结构和预训练参数的情况下,将静态图像转换成动态视频。这一方法在图像到视频转换领域具有广泛的应用前景,能够为视频创作、媒体传播等领域带来更多可能性。该研究结果的发布对于推动图像和视频技术的发展具有重要意义,为相关领域的研究者提供了一种有效的工具和方法。

- 论文地址:https://arxiv.org/pdf/2312.16693.pdf
- 项目主页:https://i2v-adapter.github.io/index.html
- 代码地址:https://github.com/I2V-Adapter/I2V-Adapter-repo
相对于现有方法而言,I2V-Adapter在可训练参数方面取得了巨大的改进,其参数数量最低可达到22M,仅为主流方案Stable Video Diffusion的1%。同时,该适配器还具备与Stable Diffusion社区开发的定制化T2I模型(如DreamBooth、Lora)和控制工具(如ControlNet)的兼容性。通过实验,研究者证明了I2V-Adapter在生成高质量视频内容方面的有效性,为I2V领域的创意应用开辟了新的可能性。

方法介绍
Temporal modeling with Stable Diffusion
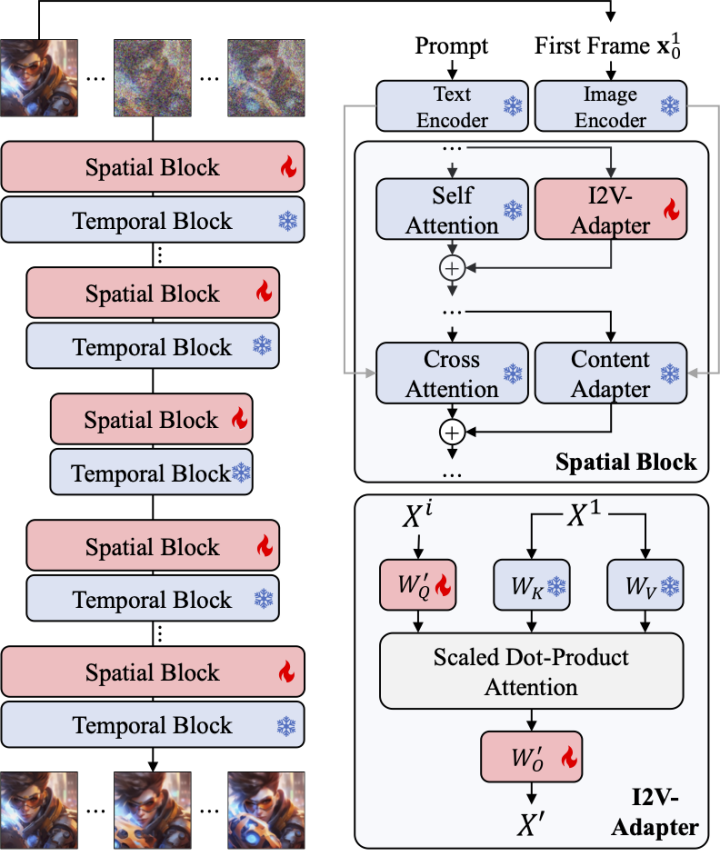
相较于图像生成,视频生成面临着独特的挑战,即建模视频帧之间的时序连贯性。目前的大多数方法都是基于预训练的T2I模型,例如Stable Diffusion和SDXL,通过引入时序模块对视频中的时序信息进行建模。受到AnimateDiff的启发,这是一个最初设计用于定制化T2V任务的模型,它通过引入与T2I模型解耦的时序模块来建模时序信息,并保留了原始T2I模型的能力,能够生成流畅的视频。因此,研究者认为预训练的时序模块可以被视为通用的时序表征,并可以应用于其他视频生成场景,如I2V生成,而无需进行任何微调。因此,研究者直接使用预训练的AnimateDiff时序模块,并保持其参数固定。
Adapter for attention layers
I2V任务中的另一个挑战是保持输入图像的ID信息。目前的解决方案主要有两种:一种是使用预训练的图像编码器对输入图像进行编码,并通过交叉关注机制将编码后的特征注入到模型中以指导去噪过程;另一种是将图像与有噪声的输入在通道维度上进行拼接,然后一起输入到后续的网络中。然而,前一种方法由于图像编码器难以捕捉底层信息,可能导致生成的视频ID发生变化;而后一种方法往往需要改变T2I模型的结构和参数,训练代价高且兼容性较差。
为了解决上述问题,研究者提出了 I2V-Adapter。具体来说,研究者将输入图像与 noised input 并行输入给网络,在模型的 spatial block 中,所有帧都会额外查询一次首帧信息,即 key,value 特征都来自于不加噪的首帧,输出结果与原始模型的 self attention 相加。此模块中的输出映射矩阵使用零初始化并且只训练输出映射矩阵与 query 映射矩阵。为了进一步加强模型对输入图像语义信息的理解,研究者引入了预训练的 content adapter(本文使用的是 IP-Adapter [8])注入图像的语义特征。
Frame Similarity Prior
为了进一步增强生成结果的稳定性,研究者提出了帧间相似性先验,用于在生成视频的稳定性和运动强度之间取得平衡。其关键假设是,在相对较低的高斯噪声水平上,带噪声的第一帧和带噪声的后续帧足够接近,如下图所示:
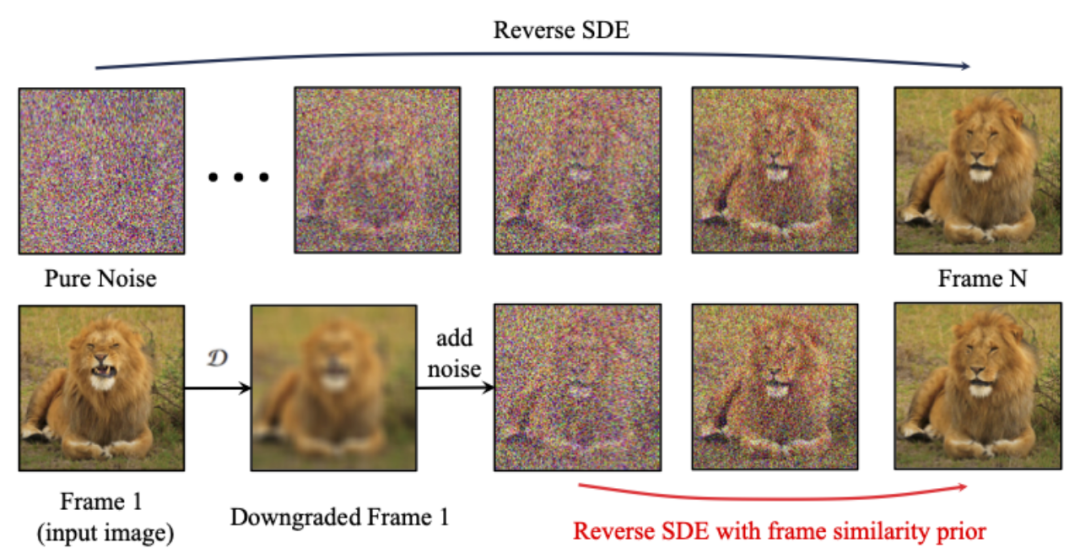
于是,研究者假设所有帧结构相似,并在加入一定量的高斯噪声后变得难以区分,因此可以把加噪后的输入图像作为后续帧的先验输入。为了排除高频信息的误导,研究者还使用了高斯模糊算子和随机掩码混合。具体来说,运算由下式给出:

实验结果
定量结果
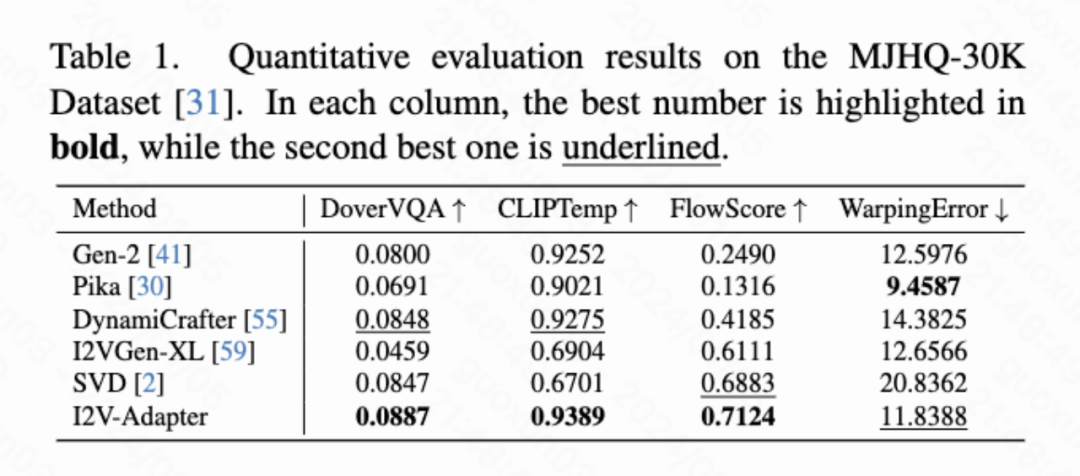
本文计算了四种定量指标分别是 DoverVQA (美学评分)、CLIPTemp (首帧一致性)、FlowScore (运动幅度) 以及 WarppingError (运动误差) 用于评价生成视频的质量。表 1 显示 I2V-Adapter 得到了最高的美学评分,在首帧一致性上也超过了所有对比方案。此外,I2V-Adapter 生成的视频有着最大的运动幅度,并且相对较低的运动误差,表明此模型的能够生成更加动态的视频并且同时保持时序运动的准确性。
定性结果
Image Animation(左为输入,右为输出):



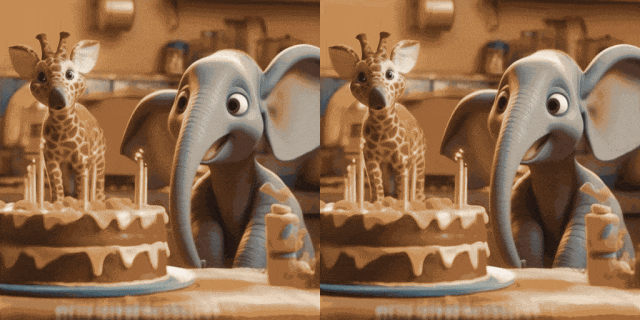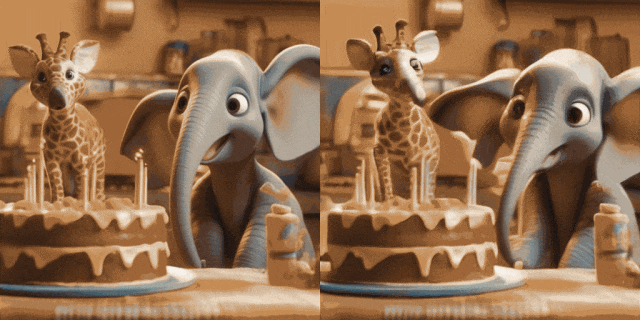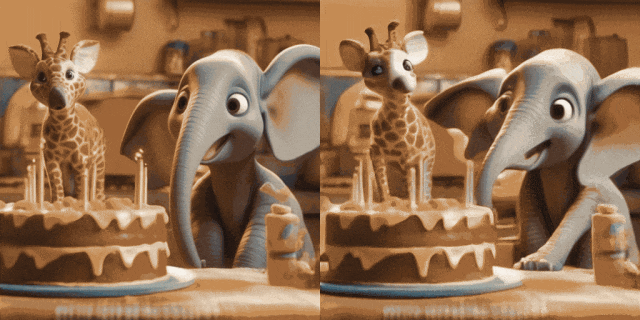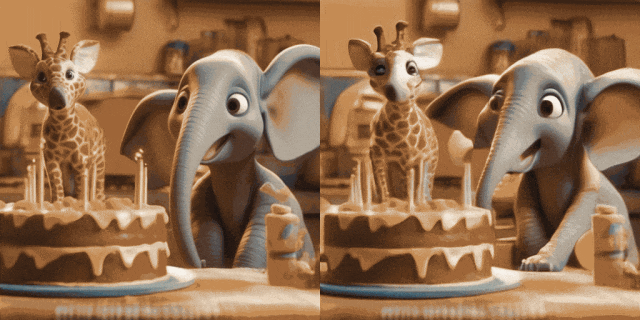
w/ Personalized T2Is(左为输入,右为输出):




w/ ControlNet(左为输入,右为输出):



总结
本文提出了 I2V-Adapter,一种即插即用的轻量级模块,用于图像到视频生成任务。该方法保留原始 T2V 模型的 spatial block 与 motion block 结构与参数固定,并行输入不加噪的第一帧与加噪的后续帧,通过注意力机制允许所有帧与无噪声的第一帧交互,从而产生时序连贯且与首帧一致的视频。研究者们通过定量与定性实验证明了该方法在 I2V 任务上的有效性。此外,其解耦设计使得该方案能够直接结合 DreamBooth、Lora 与 ControlNet 等模块,证明了该方案的兼容性,也促进了定制化与可控图像到视频生成的研究。
以上是SD社区的I2V-Adapter:无需配置,即插即用,完美兼容图生视频插件的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 视频文件存储在浏览器缓存中的位置在哪里?
Feb 19, 2024 pm 05:09 PM
视频文件存储在浏览器缓存中的位置在哪里?
Feb 19, 2024 pm 05:09 PM
浏览器缓存视频在哪个文件夹在日常使用互联网浏览器时,我们经常会观看各种在线视频,比如在YouTube上看音乐视频或在Netflix上观看电影等。而这些视频在加载过程中会被浏览器缓存下来,以便日后再次播放时能够快速加载。那么问题来了,这些缓存的视频实际上存储在哪个文件夹中呢?不同浏览器的缓存视频文件夹保存位置是不同的。下面我们将分别介绍几种常见的浏览器以及它们
 抖音发布他人视频侵权吗?它怎样剪辑视频不算侵权?
Mar 21, 2024 pm 05:57 PM
抖音发布他人视频侵权吗?它怎样剪辑视频不算侵权?
Mar 21, 2024 pm 05:57 PM
随着短视频平台的兴起,抖音成为了大家日常生活中不可或缺的一部分。在抖音上,我们可以看到来自世界各地的有趣视频。有些人喜欢发布他人的视频,这就引发了一个问题:抖音发布他人视频侵权吗?本文将围绕这个问题展开讨论,告诉大家怎样剪辑视频不算侵权,以及如何避免侵权问题。一、抖音发布他人视频侵权吗?根据我国《著作权法》的规定,未经著作权人许可,擅自使用其作品,属于侵权行为。因此,在抖音上发布他人视频,如果未经原作者或著作权人许可,就属于侵权行为。二、怎样剪辑视频不算侵权?1.使用公共领域或已授权的内容:公共
 Wink如何去视频水印
Feb 23, 2024 pm 07:22 PM
Wink如何去视频水印
Feb 23, 2024 pm 07:22 PM
Wink如何去视频水印?winkAPP中是有去除掉视频水印的工具,但是多数的小伙伴不知道wink中如何去除掉视频中的水印,接下来就是小编为玩家带来的Wink视频去水印方法图文教程,感兴趣的用户快来一起看看吧!Wink如何去视频水印1、首先打开winkAPP,在首页面专区中选择【去水印】功能;2、然后在相册中选择你需要去除水印的视频;3、接着选择视频之后,剪辑视频之后点击右上角【√】;4、最后点击如下图所示的【一键去印】之后点击【处理】即可。
 抖音发布视频如何赚收益?新手小白怎么在抖音上赚钱啊?
Mar 21, 2024 pm 08:17 PM
抖音发布视频如何赚收益?新手小白怎么在抖音上赚钱啊?
Mar 21, 2024 pm 08:17 PM
抖音,这个全民短视频平台,不仅让我们在闲暇时间享受到各种有趣、新奇的短视频,同时也给了我们一个展示自我、实现价值的舞台。那么,如何在抖音发布视频赚取收益呢?本文将详细解答这个问题,帮助你在抖音上赚取更多的收益。一、抖音发布视频如何赚收益?发布视频在抖音上获得一定的播放量后,可以有机会参与广告分成计划。这一收益方式是抖音用户最为熟悉的之一,也是许多创作者主要的收入来源。抖音根据账号权重、视频内容以及观众反馈等多种因素来决定是否提供广告分成的机会。抖音平台允许观众通过发送礼物来支持自己喜欢的创作者,
 微博发视频怎么不压缩画质_微博发视频不压缩画质方法
Mar 30, 2024 pm 12:26 PM
微博发视频怎么不压缩画质_微博发视频不压缩画质方法
Mar 30, 2024 pm 12:26 PM
1、首先打开手机微博,点击右下角【我】(如图所示)。2、接着点击右上角【齿轮】打开设置(如图所示)。3、然后找到并打开【通用设置】(如图所示)。4、随后进入【视频随着】选项(如图所示)。5、再打开【视频上传清晰度】设置(如图所示)。6、最后选择【原画质】就能不压缩了(如图所示)。
 从 iPhone 上的视频中删除慢动作的 2 种方法
Mar 04, 2024 am 10:46 AM
从 iPhone 上的视频中删除慢动作的 2 种方法
Mar 04, 2024 am 10:46 AM
在iOS设备上,“相机”应用程序允许您拍摄慢动作视频,如果您使用的是最新款的iPhone,甚至可以以每秒240帧的速度录制视频。这种功能让您能够捕捉到丰富细节的高速动作。但有时候,您可能希望将慢动作视频以正常速度播放,这样可以更好地欣赏视频中的细节和动作。在这篇文章中,我们将解释从iPhone上的现有视频中删除慢动作的所有方法。如何从iPhone上的视频中删除慢动作[2种方法]您可以使用“照片”App或iMovie剪辑App从设备上的视频中删除慢动作。方法1:使用“照片”应用在iPhone上打开
 如何发布小红书视频作品?发视频要注意什么?
Mar 23, 2024 pm 08:50 PM
如何发布小红书视频作品?发视频要注意什么?
Mar 23, 2024 pm 08:50 PM
随着短视频平台的兴起,小红书成为了许多人分享生活、表达自我、获取流量的平台。在这个平台上,发布视频作品是一种非常受欢迎的互动方式。那么,如何发布小红书视频作品呢?一、如何发布小红书视频作品?首先,确保准备好一段适合分享的视频内容。你可以利用手机或其他摄像设备进行拍摄,需要注意画质和声音的清晰度。2.剪辑视频:为了让作品更具吸引力,可以对视频进行剪辑。可以使用专业的视频剪辑软件,如抖音、快手等,添加滤镜、音乐、字幕等元素。3.选择封面:封面是吸引用户点击的关键,选择一张清晰、有趣的图片作为封面,让
 uc浏览器下载的视频怎么变成本地视频
Feb 29, 2024 pm 10:19 PM
uc浏览器下载的视频怎么变成本地视频
Feb 29, 2024 pm 10:19 PM
uc浏览器下载的视频怎么变成本地视频?许多手机用户都喜欢使用UC浏览器,不仅可用它进行网页浏览,还可在线观看各种视频和电视节目,并将喜爱的视频下载至手机。实际上,我们可以将下载的视频转换为本地视频,但很多人不清楚如何操作。因此,小编特地为大家带来了将uc浏览器缓存的视频转为本地视频方法,希望可以帮助到各位。将uc浏览器缓存的视频转为本地视频方法1、打开uc浏览器,点击“菜单”选项。2、点击“下载/视频”。3、点击“已缓存视频”。4、长按任意一个视频,弹出选项后,点击“打开目录”。5、勾选要下载的
