

提升Pandas代码效率的两个绝妙技巧

如果你曾经使用过Pandas处理表格数据,你可能会熟悉导入数据、清洗和转换的过程,然后将其用作模型的输入。然而,当你需要扩展和将代码投入生产时,你的Pandas管道很可能开始崩溃并运行缓慢。在这篇文章中,我将分享2个技巧,帮助你提升Pandas代码的执行速度,提高数据处理效率并避免常见的陷阱。

技巧1:矢量化操作
在Pandas中,矢量化操作是一种高效的工具,能够以更简洁的方式处理整个数据框的列,而无需逐行循环。
它是如何工作的?
广播是矢量化操作的一个关键要素,它允许您直观地操作具有不同形状的对象。
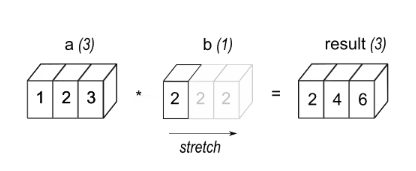
eg1: 具有3个元素的数组a与标量b相乘,得到与Source形状相同的数组。
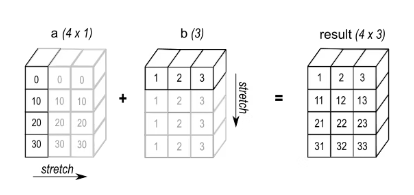
eg2: 在进行加法运算时,将形状为(4,1)的数组a与形状为(3,)的数组b相加,结果会得到一个形状为(4,3)的数组。
已有很多文章讨论了这一点,特别是在深度学习中,大规模矩阵乘法很常见。本文将以两个简短例子进行讨论。
首先,假设您想要计算给定整数在列中出现的次数。以下是 2 种可能的方法。
"""计算DataFrame X 中 "column_1" 列中等于目标值 target 的元素个数。参数:X: DataFrame,包含要计算的列 "column_1"。target: int,目标值。返回值:int,等于目标值 target 的元素个数。"""# 使用循环计数def count_loop(X, target: int) -> int:return sum(x == target for x in X["column_1"])# 使用矢量化操作计数def count_vectorized(X, target: int) -> int:return (X["column_1"] == target).sum()
现在假设有一个DataFrame带有日期列并希望将其偏移给定的天数。使用矢量化操作计算如下:
def offset_loop(X, days: int) -> pd.DataFrame:d = pd.Timedelta(days=days)X["column_const"] = [x + d for x in X["column_10"]]return Xdef offset_vectorized(X, days: int) -> pd.DataFrame:X["column_const"] = X["column_10"] + pd.Timedelta(days=days)return X
技巧2:迭代
「for循环」
第一个也是最直观的迭代方法是使用Python for循环。
def loop(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:res = []i_remove_col = df.columns.get_loc(remove_col)i_words_to_remove_col = df.columns.get_loc(words_to_remove_col)for i_row in range(df.shape[0]):res.append(remove_words(df.iat[i_row, i_remove_col], df.iat[i_row, i_words_to_remove_col]))return result
「apply」
def apply(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df.apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1).tolist()
在 df.apply 的每次迭代中,提供的可调用函数获取一个 Series,其索引为 df.columns,其值是行的。这意味着 pandas 必须在每个循环中生成该序列,这是昂贵的。为了降低成本,最好对您知道将使用的 df 子集调用 apply,如下所示:
def apply_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df[[remove_col, words_to_remove_col]].apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1)
「列表组合+itertuples」
使用itertuples与列表相结合进行迭代肯定会更好。itertuples生成带有行数据的(命名)元组。
def itertuples_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x[0], x[1])for x in df[[remove_col, words_to_remove_col]].itertuples(index=False, name=None)]
「列表组合+zip」
zip接受可迭代对象并生成元组,其中第i个元组按顺序包含所有给定可迭代对象的第i个元素。
def zip_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
「列表组合+to_dict」
def to_dict_only_used_columns(df: pd.DataFrame) -> list[str]:return [remove_words(row[remove_col], row[words_to_remove_col])for row in df[[remove_col, words_to_remove_col]].to_dict(orient="records")]
「缓存」
除了我们讨论的迭代技术之外,另外两种方法可以帮助提高代码的性能:缓存和并行化。如果使用相同的参数多次调用 pandas 函数,缓存会特别有用。例如,如果remove_words应用于具有许多重复值的数据集,您可以使用它functools.lru_cache来存储函数的结果并避免每次都重新计算它们。要使用lru_cache,只需将@lru_cache装饰器添加到 的声明中remove_words,然后使用您首选的迭代方法将该函数应用于您的数据集。这可以显着提高代码的速度和效率。以下面的代码为例:
@lru_cachedef remove_words(...):... # Same implementation as beforedef zip_only_used_cols_cached(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
添加此装饰器会生成一个函数,该函数会“记住”之前遇到的输入的输出,从而无需再次运行所有代码。
「并行化」
最后一张王牌是使用 pandarallel 跨多个独立的 df 块并行化我们的函数调用。该工具易于使用:您只需导入并初始化它,然后将所有 .applys 更改为 .parallel_applys。
from pandarallel import pandarallelpandarallel.initialize(nb_workers=min(os.cpu_count(), 12))def parapply_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df[[remove_col, words_to_remove_col]].parallel_apply(lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1)
以上是提升Pandas代码效率的两个绝妙技巧的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 解决常见的pandas安装问题:安装错误的解读和解决方法
Feb 19, 2024 am 09:19 AM
解决常见的pandas安装问题:安装错误的解读和解决方法
Feb 19, 2024 am 09:19 AM
pandas安装教程:解析常见安装错误及其解决方法,需要具体代码示例引言:Pandas是一个强大的数据分析工具,广泛应用于数据清洗、数据处理和数据可视化等方面,因此在数据科学领域备受推崇。然而,由于环境配置和依赖问题,安装pandas可能会遇到一些困难和错误。本文将为大家提供一份pandas安装教程,并解析一些常见的安装错误及其解决方法。一、安装pandas
 超越ORB-SLAM3!SL-SLAM:低光、严重抖动和弱纹理场景全搞定
May 30, 2024 am 09:35 AM
超越ORB-SLAM3!SL-SLAM:低光、严重抖动和弱纹理场景全搞定
May 30, 2024 am 09:35 AM
写在前面今天我们探讨下深度学习技术如何改善在复杂环境中基于视觉的SLAM(同时定位与地图构建)性能。通过将深度特征提取和深度匹配方法相结合,这里介绍了一种多功能的混合视觉SLAM系统,旨在提高在诸如低光条件、动态光照、弱纹理区域和严重抖动等挑战性场景中的适应性。我们的系统支持多种模式,包括拓展单目、立体、单目-惯性以及立体-惯性配置。除此之外,还分析了如何将视觉SLAM与深度学习方法相结合,以启发其他研究。通过在公共数据集和自采样数据上的广泛实验,展示了SL-SLAM在定位精度和跟踪鲁棒性方面优
 蓝屏代码0x0000001怎么办
Feb 23, 2024 am 08:09 AM
蓝屏代码0x0000001怎么办
Feb 23, 2024 am 08:09 AM
蓝屏代码0x0000001怎么办蓝屏错误是电脑系统或硬件出现问题时的一种警告机制,代码0x0000001通常表示出现了硬件或驱动程序故障。当用户在使用电脑时突然遇到蓝屏错误,可能会感到惊慌和无措。幸运的是,大多数蓝屏错误都可以通过一些简单的步骤进行排除和处理。本文将为读者介绍一些解决蓝屏错误代码0x0000001的方法。首先,当遇到蓝屏错误时,我们可以尝试重
 超强!深度学习Top10算法!
Mar 15, 2024 pm 03:46 PM
超强!深度学习Top10算法!
Mar 15, 2024 pm 03:46 PM
自2006年深度学习概念被提出以来,20年快过去了,深度学习作为人工智能领域的一场革命,已经催生了许多具有影响力的算法。那么,你所认为深度学习的top10算法有哪些呢?以下是我心目中深度学习的顶尖算法,它们在创新性、应用价值和影响力方面都占据重要地位。1、深度神经网络(DNN)背景:深度神经网络(DNN)也叫多层感知机,是最普遍的深度学习算法,发明之初由于算力瓶颈而饱受质疑,直到近些年算力、数据的爆发才迎来突破。DNN是一种神经网络模型,它包含多个隐藏层。在该模型中,每一层将输入传递给下一层,并
 一文搞懂:AI、机器学习与深度学习的联系与区别
Mar 02, 2024 am 11:19 AM
一文搞懂:AI、机器学习与深度学习的联系与区别
Mar 02, 2024 am 11:19 AM
在当今科技日新月异的浪潮中,人工智能(ArtificialIntelligence,AI)、机器学习(MachineLearning,ML)与深度学习(DeepLearning,DL)如同璀璨星辰,引领着信息技术的新浪潮。这三个词汇频繁出现在各种前沿讨论和实际应用中,但对于许多初涉此领域的探索者来说,它们的具体含义及相互之间的内在联系可能仍笼罩着一层神秘面纱。那让我们先来看看这张图。可以看出,深度学习、机器学习和人工智能之间存在着紧密的关联和递进关系。深度学习是机器学习的一个特定领域,而机器学习
 GE通用远程代码可在任何设备上编程
Mar 02, 2024 pm 01:58 PM
GE通用远程代码可在任何设备上编程
Mar 02, 2024 pm 01:58 PM
如果您需要远程编程任何设备,这篇文章会给您带来帮助。我们将分享编程任何设备的顶级GE通用远程代码。通用电气的遥控器是什么?GEUniversalRemote是一款遥控器,可用于控制多个设备,如智能电视、LG、Vizio、索尼、蓝光、DVD、DVR、Roku、AppleTV、流媒体播放器等。GEUniversal遥控器有各种型号,具有不同的功能和功能。GEUniversalRemote最多可以控制四台设备。顶级通用遥控器代码,可在任何设备上编程GE遥控器配备一组代码,使其能够与不同设备相配合。您可
 如何使用Copilot生成代码
Mar 23, 2024 am 10:41 AM
如何使用Copilot生成代码
Mar 23, 2024 am 10:41 AM
作为一名程序员,对于能够简化编码体验的工具,我感到非常兴奋。借助人工智能工具的帮助,我们可以生成演示代码,并根据需求进行必要的修改。在VisualStudioCode中新引入的Copilot工具让我们能够创建具有自然语言聊天交互的AI生成代码。通过解释功能,我们可以更好地理解现有代码的含义。如何使用Copilot生成代码?要开始,我们首先需要获得最新的PowerPlatformTools扩展。要实现这一点,你需要进入扩展页面,搜索“PowerPlatformTool”,然后点击Install按钮
 解决代码0xc000007b错误
Feb 18, 2024 pm 07:34 PM
解决代码0xc000007b错误
Feb 18, 2024 pm 07:34 PM
终止代码0xc000007b在使用电脑时,有时会遇到各种各样的问题和错误代码。其中,终止代码最为令人困扰,尤其是终止代码0xc000007b。这个代码表示某个应用程序无法正常启动,给用户带来了不便。首先,我们来了解一下终止代码0xc000007b的含义。这个代码是Windows操作系统的错误代码,通常发生在32位应用程序尝试在64位操作系统上运行时。它表示应
